陽性(Positive)和陰性(Negative)
陽性(Positive)=正類:通常指的是我們關注的類別或事件;陰性(Negative)=負類: 指的是與陽性相反的類別或事件。
如果對貓類別感興趣,那么貓就是正類,而其他事物(例如狗,牛,人類)都是負類。
如果目標是檢測/識別行人,那么行人就是正類,而其余的則是負類。
陽性和陰性完全是一個相對的概念,取決于任務中關注的對象。
混淆矩陣(Confusion Matrix)
混淆矩陣 = 可能性矩陣 = 錯誤矩陣,它是一種用于評估機器學習分類模型表現的工具,它將模型的預測結果分為四類,以預測垃圾郵件為例子:
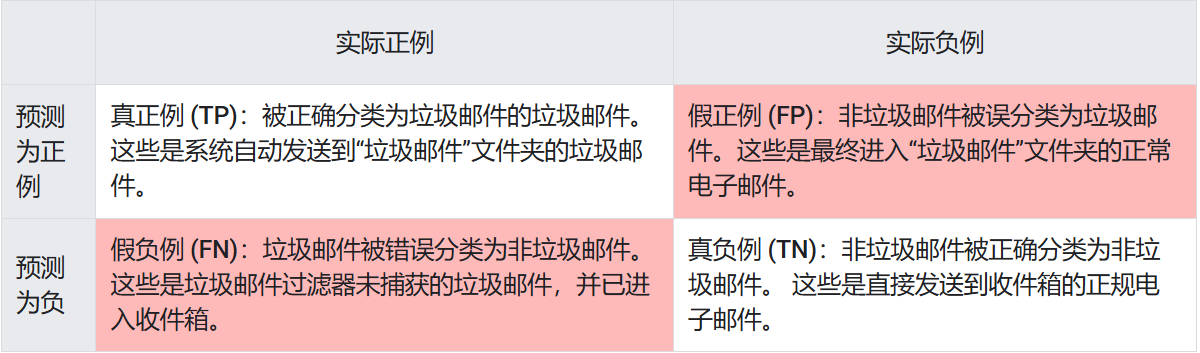
真陽性(True Positive, TP):實際為陽性,預測也為陽性。垃圾郵件,模型分類為垃圾郵件
真陰性(True Negative, TN):實際為陰性,預測也為陰性。普通郵件,模型分類為普通郵件
假陽性(False Positive, FP) = 第一類錯誤(Type I Error) = 誤報 :實際為陰性,預測為陽性。普通郵件,模型分類為垃圾郵件。
假陰性(False Negative, FN) = 第二類錯誤(Type II Error) = 漏報:實際為陽性,預測為陰性。垃圾郵件,模型分類為普通郵件
閾值 Threshold
通過設置閾值,我們可以直接指示模型以何種置信度(Confident Level)來區分正類和負類
假設有一個用于垃圾郵件檢測的邏輯回歸模型,該模型預測一個介于 0 到 1 之間的值,表示給定電子郵件是垃圾郵件的概率。預測結果為 0.50 表示電子郵件為垃圾郵件的可能性為 50%,預測為 0.75 表示電子郵件為垃圾郵件的可能性為 75%,依此類推。
您想在電子郵件應用中部署此模型,以將垃圾郵件過濾到單獨的郵件文件夾中。不過,為此,您需要轉換模型的原始數值輸出(例如 0.75)分為“垃圾郵件”或“非垃圾郵件”這兩類。
如需進行此轉換,您需要選擇一個閾值概率,稱為分類閾值(Classification Threshold)。然后,概率高于閾值的樣本會被分配到正類別(即要測試的類,此處為 spam)。概率較低的樣本會被分配到負類別(即備選類別,此處為 not spam)。
雖然 0.5 看起來像是一個直觀的閾值,但如果一種錯誤分類的代價高于另一種類型,例如將非常重要的正常郵件錯誤歸類為垃圾郵件(這就是后面會提到的假陽性/第一類錯誤/誤報 ),應顯著提高閾值避免誤判。
先給結論
- 降低閾值,會提高真正例、假正例(誤報),降低真負例、假負例(漏報);
- 提高閾值,會提高真負例、假負例(漏報),降低真正例、假正例(誤報)
- 原因顯而易見,閾值更高,模型需要更高的信心才會歸類為正例,因此不管實際正負,模型預測為正的樣本都會變少,而結果是二元化,不預測為正就會預測為負,因此模型預測為負的樣本都會變多。
舉個例子,假設在數據集中,實際正例和實際負例分別為 50,合計 100
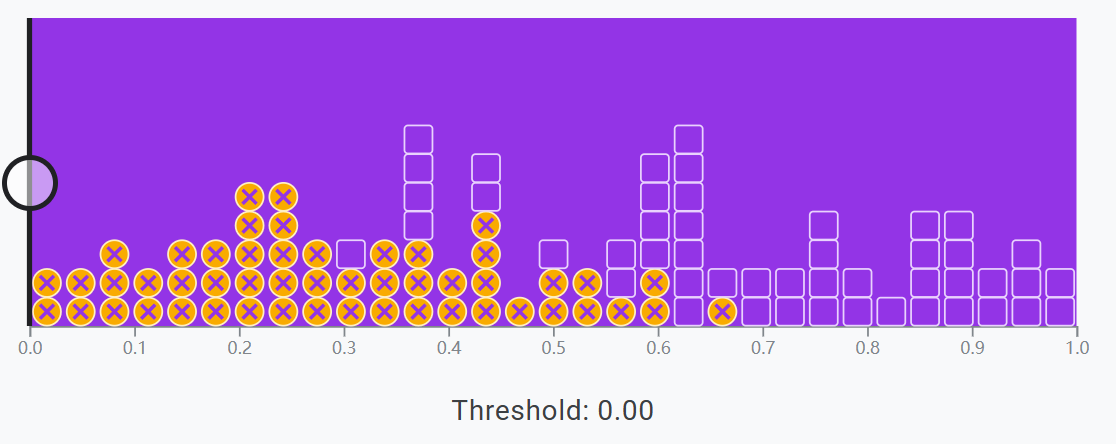

當閾值設為 0 時,代表著指示模型,將可能性大于 0 的例子歸類為正例,實質就是將所有例子歸類為正例
這樣做的優點是能找出所有正例,但相對的,會引入很多誤報。
以垃圾郵件為例,即雖然能準確找到所有垃圾郵件,但也會把所有普通郵件都當成垃圾郵件誤報。
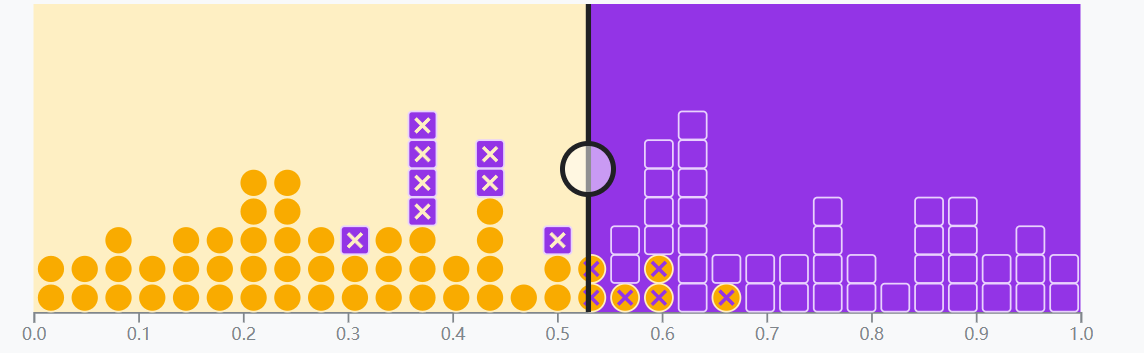

當閾值設為 0.53 時,代表著指示模型,將可能性大于 0.53 的例子歸類為正例
這樣做,我們可以極大減少誤報,但相應地也會引入一些漏報。
以垃圾郵件為例,雖然此時有 8 封垃圾郵件沒有被正確分類,但至少,有 47 封普通郵件被正確分類,顯然,在郵件分類中,我們多看幾封垃圾郵件,也不愿意遺漏任何一封普通郵件,因此可以說,0.53 的閾值比 0 的閾值更合理。


當閾值設為 0.68 時,代表著指示模型,將可能性大于 0.68 的例子歸類為正例
這樣做,我們可以將誤報完全消除,但相應地引入了大量的漏報。
以垃圾郵件為例,雖然此時所有普通郵件都沒有被誤傷(FP = 0),但相應的,漏網之魚垃圾郵件大大增加到 22。
在做深度學習預測分類時,有些任務絕對不能出現漏報,為此就算帶來了很多誤報,也可以接受;有些任務,可以容忍出現一些漏報,只要將漏報和誤報控制在一個較低的水平就可以。
- 癌癥篩查:漏診癌癥(FN)可能導致患者錯過最佳治療時機,危及生命。此時采取的策略應是召回率優先(將閾值降低),即使將許多良性腫瘤誤判為惡性(FP),也需確保盡可能檢出所有癌癥病例。
- 電商商品推薦:??誤推不相關商品(FP)降低用戶體驗;漏推潛在喜歡商品(FN)損失部分轉化率。此時采取的策略應是平衡精確率和召回率,即將閾值調整到合理地步,類似上面的 0.52 。
數據集不平衡
作為訓練模型的一部分,我們希望提供給模型的數據集中,每個類別包含的實際個例數,應當大致相當。如果實際正例的總數與實際負例的總數不接近,則表示數據集不平衡。以預測垃圾郵件為例,數據集中可能數千條普通郵件,而垃圾郵件只有幾例。
評價模型的指標
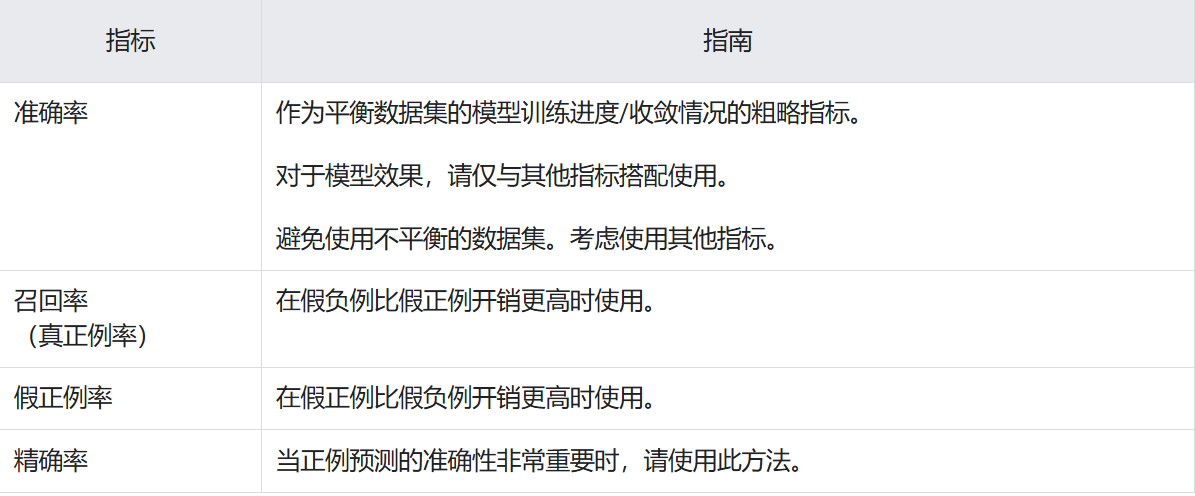
真正例、假正例和假負例是用于計算評估模型的幾個實用指標。哪些評估指標最有意義,取決于具體模型和具體任務、不同錯誤分類的代價,以及數據集是平衡的還是不平衡的。
本部分中的所有指標均基于單個固定閾值計算得出,并且會隨閾值的變化而變化。很多時候,用戶會調整閾值以優化其中某個指標。
-
準確率(Accuracy):準確率用于衡量一個分類模型的效果。它表示模型預測對的次數占總預測次數的百分比。- 由于精度包含混淆矩陣中的所有四種結果(TP、FP、TN、FN),因此,在執行通用或未指定任務的通用或未指定模型、數據集平衡、兩個類別中的示例數量相近的情況下,精度可以用作衡量模型質量的粗略指標。
- 例如,模型測試了 100 張圖片,其中有 90 張預測正確(TP + TN = 90),那么準確率就是 90%。
- 對于嚴重不均衡的數據集(例如普通郵件占比非常低為1%,垃圾郵件占比為 90%),如果我們將閾值調到最高,模型 100% 都預測為負類(普通郵件),則準確率得分為 99%。盡管得分很高,這個模型實質毫無用處
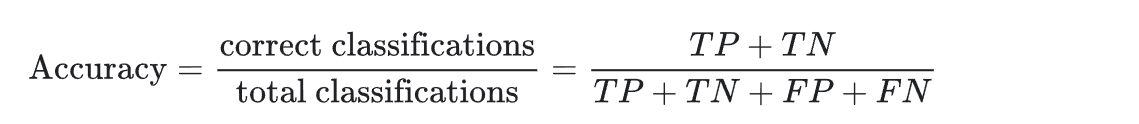
-
精確率(Precision):所有被預測為正類的樣本中,實際為正類的比例。

-
召回率(Recall)=靈敏度(Sensitivity)=真正例率(TPR):所有實際為正類的樣本中,被預測為正類的比例,衡量模型正確識別正類的能力。召回率。- 在實際正例數量非常少的不均衡數據集中,召回率作為指標的意義不大。

- 在實際正例數量非常少的不均衡數據集中,召回率作為指標的意義不大。
-
準確率會在一個合適的閾值達到最高;但精確率和召回率通常呈反函數關系,其中一個提高會反過另一個,無法同時提高二者。
-
F1 Score:是精確率和召回率的調和平均數(一種平均值)。該指標在精確率和召回率的重要性之間進行了平衡,對于類別不平衡的數據集,該指標優于準確率。更廣泛地說,當精確率和召回率的值接近時,F1 也會接近它們的值。當精確率和召回率相差很大時,F1 將與較差的指標相似。
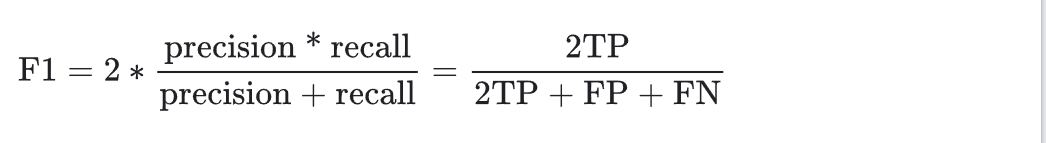
假正例率(False Positive Rate, FPR)=誤報概率:所有實際為負類的樣本中,(錯誤地)被預測為正例的比例。
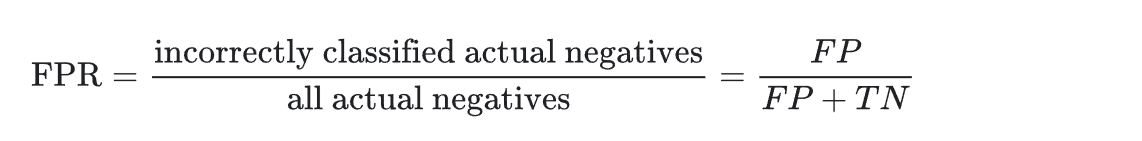
- 特異性(Specificity):所有實際為負類的樣本中,(正確地)被預測為負類的比例,衡量模型正確識別負類的能力。特異性 = 真正負類率,

例題:構建一個二元分類器,用于檢查昆蟲捕獲器的照片,以確定是否存在危險的入侵物種。在該系統中,誤報(假正例)很容易處理:昆蟲學家發現照片被錯誤分類,并將其標記為誤報即可。假設準確率水平在可接受的范圍內,此模型應該針對哪個指標進行優化?
誤報 (FP) 的成本較低,而假負例的成本非常高,因此,最大限度地提高召回率(即檢測概率)是明智之舉。
ROC 曲線(ROC, Receiver Operating Characteristic Curve)
上一部分介紹了一組模型指標,這些指標均以固定的閾值來計算,一旦更換閾值,每個指標都會變化。
如果想評估所有可能的閾值下模型的表現,則需要 ROC、AUC。
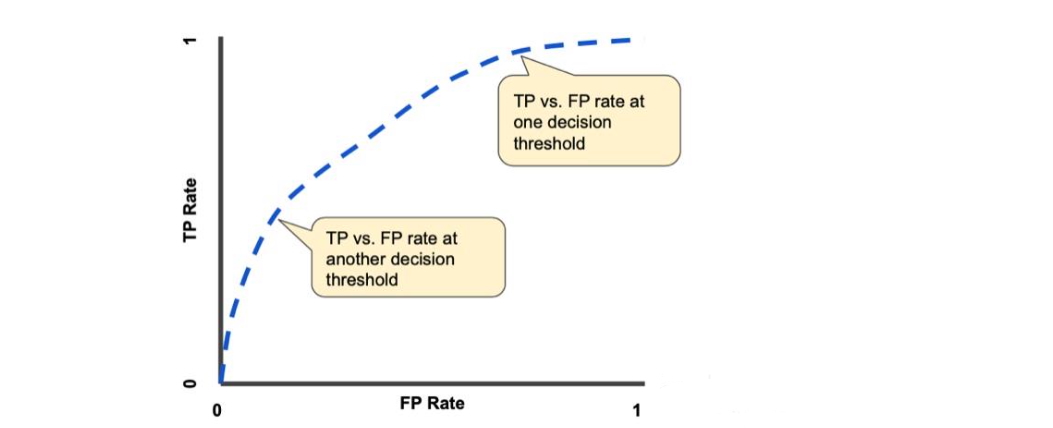
ROC 曲線是模型在所有閾值上的表現的可視化表示。
ROC 曲線的繪制步驟:
- 將 0-1 之間的閾值按照固定間隔分類,例如十等分。
- 對于每個閾值,計算對應的 TPR 和 FPR。
- 繪制 ROC 曲線:將所有閾值對應的 TPR 和 FPR 繪制在圖上,FPR 為 x 軸,TPR 為 y 軸。
- 計算 AUC:ROC 曲線下的面積(AUC)表示模型的整體性能。AUC 值越高,模型的分類性能越好。
舉個例子,假設有一個醫療檢測模型,用于判斷患者是否患有某種疾病(正樣本)或沒有疾病(負樣本)。我們將繪制 ROC 曲線來評估模型性能。
- 收集預測概率:預測結果可能是每個患者的概率值,比如 [0.1, 0.4, 0.35, 0.8]。
- 選擇不同閾值:選擇閾值 0.2, 0.4, 0.6, 0.8 等。
- 計算 TPR 和 FPR:對于閾值 0.2,將所有預測概率大于等于 0.2 的樣本標記為正類。計算 TPR 和 FPR。
- 重復上述步驟,計算其他閾值下的 TPR 和 FPR。
- 繪制 ROC 曲線:在圖中,x 軸是 FPR,y 軸是 TPR,繪制 ROC 曲線。
- 計算 AUC:計算 ROC 曲線下的面積。AUC 越接近 1,模型性能越好。
曲線下方面積 (Area under the curve,AUC)
曲線下面積的數學意義是,代表模型在隨機選擇一個正例和一個負例時,將正例的排序高于負例的概率,表示模型在所有可能的閾值下的總體表現。
以垃圾郵件為例子,AUC 為 1.0 的垃圾郵件分類器始終會給隨機選取的垃圾郵件賦予比隨機選取的正常郵件更高的垃圾郵件概率。
更為人話的說法就是,AUC 越高,表示模型在打分階段更能準確地區分正例和負例:它通常會給正例更高的得分,給負例更低的得分,從而具備更強的區分能力。
AUC反映了二分類模型對正負樣本的區分能力,取值范圍從 0 到 1:
- AUC = 1:模型能夠完美地區分所有正樣本和負樣本。
- AUC = 0.5:模型的性能相當于隨機猜測,沒有實際區分能力。
- AUC < 0.5:模型的預測性能差于隨機猜測,通常需要重新訓練或調整模型。
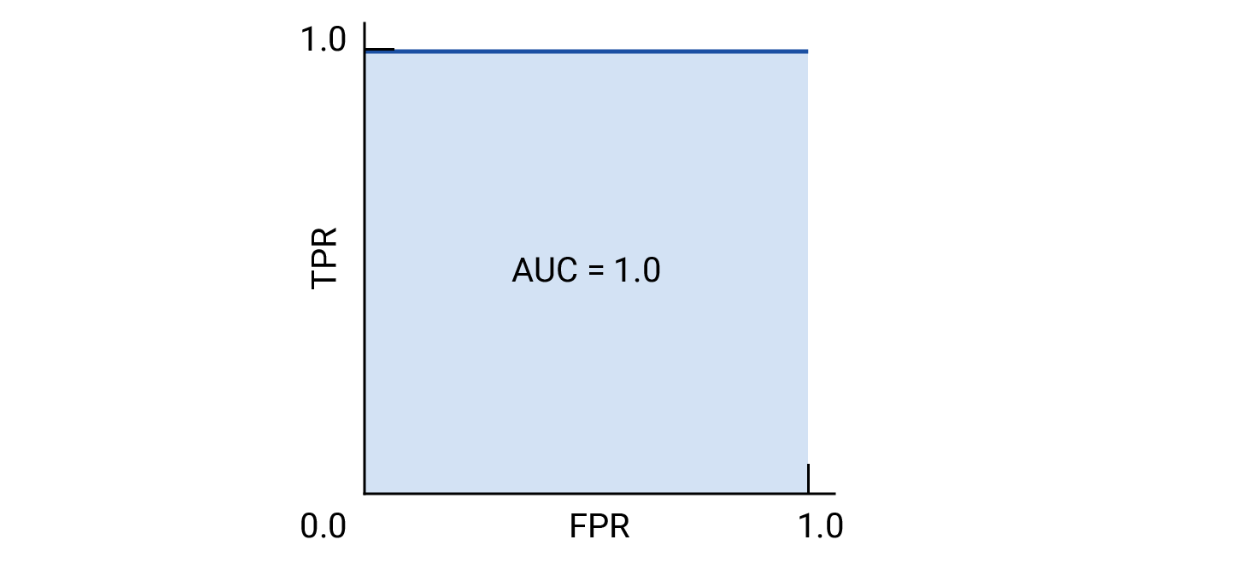
完美模型的 ROC 和 AUC,由于在任何閾值下均不存在誤報和漏報,且 TP、TN 均為 1,因此 TPR、FPR 均為恒定常數 1。
隨著閾值從1逐步減小到0(或從高到低),模型會“更寬松”地判為正類,導致:
- TPR 上升(找到了更多正類)
- FPR 也上升(錯判的負類也變多)
標注(Annotation)
標注就是給數據打標簽的過程。在機器學習中,標注數據是為了讓模型能夠學習如何將輸入數據映射到正確的輸出。標注的過程通常包括以下幾個步驟:
- 選擇數據:選擇需要標注的數據,例如圖片、文本或視頻。
- 添加標簽:為每個數據樣本添加標簽。例如,我們有一組圖片,我們會給每張圖片加上標簽,標明這張圖片是“狗”還是“貓”。
- 檢查和驗證:確保標注的準確性,以便模型可以學習到正確的信息。






:健康飲食(附代碼))




)


)

的圖像生成與編輯:原理、應用與實踐)
和backward())

