現在我們主要完成AI-RAG服務的擴展,利用ES的向量檢索能力完成歷史聊天記錄的存儲和向量檢索,讓ai聊天有記憶。
主要做法是在首次聊天完成后將對話內容寫出日志到D:\dev\dev2025\EC0601\logs\chat-his.log

寫出日志同時嵌入向量
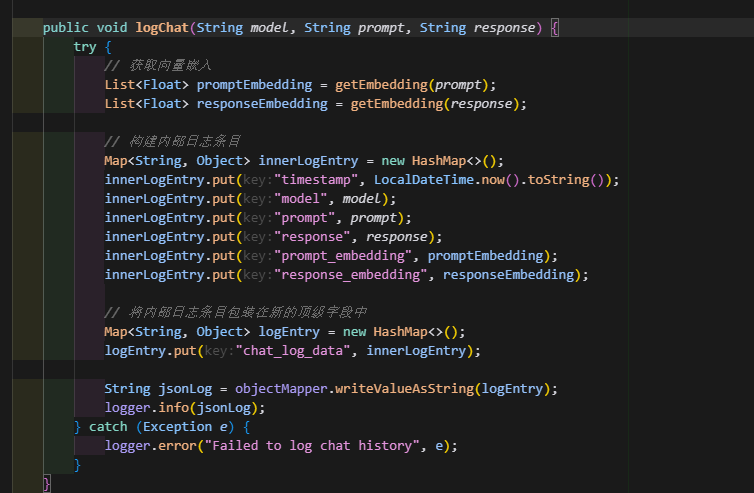
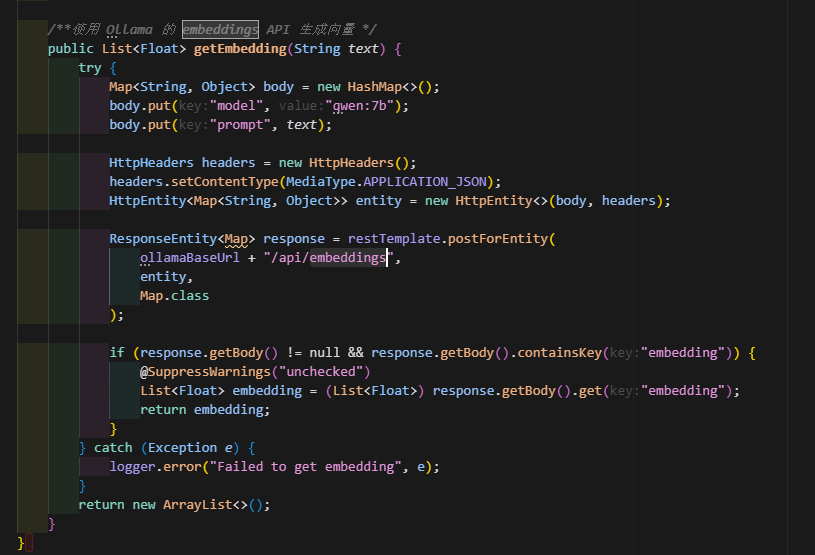
向量可以從ollama的端點:/api/embeddings獲取,不同的模型獲取到的維度不一樣,我的是4096,這個維度很重要,向量檢索必須要使用相同的維度去相互匹配,所以要記錄這個值,后續創建es模板需要用到。
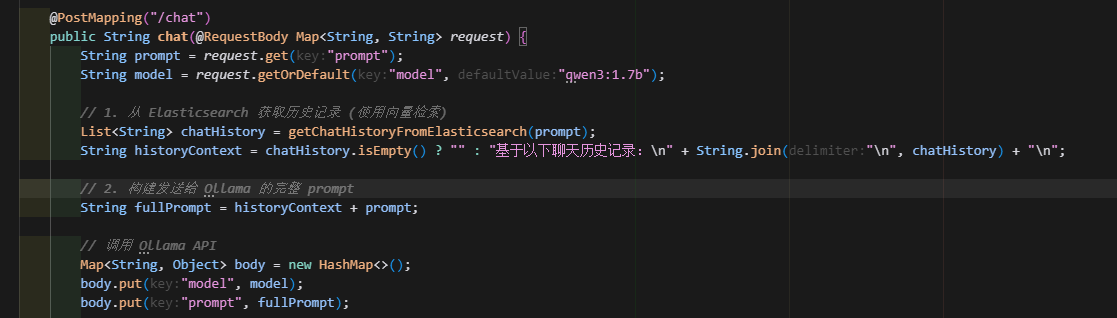
然后在第二次以及后續的對話中,就可以從es中基于相似度獲取聊天記錄從而讓聊天模型有記憶

這里解釋一下:Elasticsearch 的 k-NN
Elasticsearch 的 k-NN(k-Nearest Neighbors,k 最近鄰)查詢是一種用于執行**向量相似度搜索**的功能。在您的場景中,它被用來根據查詢的嵌入向量找到最相似的歷史聊天記錄。### 什么是 Elasticsearch k-NN 查詢?Elasticsearch 的 k-NN 查詢允許您在 `dense_vector` 字段上執行相似度搜索。它會找到在向量空間中與給定查詢向量距離最近的 `k` 個文檔。這對于實現語義搜索、推薦系統、重復檢測等場景非常有用。### k-NN 查詢的目的在您的聊天歷史記錄場景中,k-NN 查詢的主要目的是:* **語義搜索**:通過比較查詢的文本嵌入向量與存儲在 Elasticsearch 中的聊天記錄的 `prompt_embedding` 或 `response_embedding` 向量,找到語義上最相關的歷史對話,即使它們不包含完全相同的關鍵詞。
* **上下文檢索**:為 AI 模型的響應提供相關的歷史上下文,從而生成更準確和連貫的回復(RAG - Retrieval Augmented Generation)。### Elasticsearch k-NN 查詢的關鍵組件一個基本的 k-NN 查詢通常包含以下幾個部分:1. **`knn` 對象**:這是 k-NN 查詢的主體。
2. **`field`**:* 指定要執行相似度搜索的 `dense_vector` 字段。在您的案例中,這通常是 `prompt_embedding` 或 `response_embedding`。
3. **`query_vector`**:* 這是您要用來查找相似文檔的查詢向量。它是一個浮點數數組,其維度必須與目標 `dense_vector` 字段的 `dims`(維度)相匹配。在您的場景中,這就是 `getEmbedding(queryPrompt)` 生成的向量。
4. **`k`**:* 指定您希望返回的最相似結果的數量。例如,`k: 5` 會返回 5 個最相似的文檔。
5. **`num_candidates`**:* 這是一個性能參數。它指定了 Elasticsearch 在內部需要檢查的候選文檔的數量,以找到 `k` 個最近鄰。通常,`num_candidates` 應該大于 `k`(例如,`k` 的幾倍),因為它會影響搜索的準確性和性能。更大的 `num_candidates` 可能會提高準確性,但會增加計算開銷。### 示例 (Kibana Dev Tools)假設您的 `chat-history-*` 索引中存儲了聊天記錄的 `response_embedding` 字段,并且它們的維度是 `4096`。如果您想查詢與某個特定向量最相似的聊天記錄,可以在 Kibana Dev Tools 中這樣構建查詢:```
GET chat-history-*/_search
{"knn": {"field": "response_embedding","query_vector": [0.1, 0.2, -0.3, ..., 0.05, 0.99, -0.7 // 這里需要是實際的4096維查詢向量],"k": 5,"num_candidates": 100}
}
```**注意事項:*** `query_vector` 必須是一個完整的向量,其長度要與 Elasticsearch 映射中 `dense_vector` 字段的 `dims` 參數(在您的情況下是 `4096`)嚴格一致。
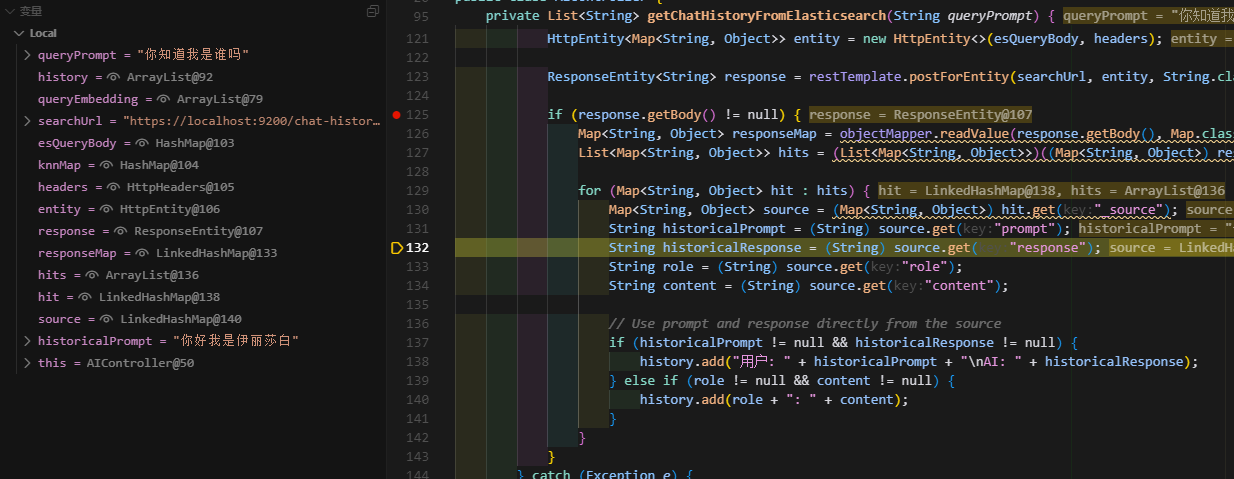
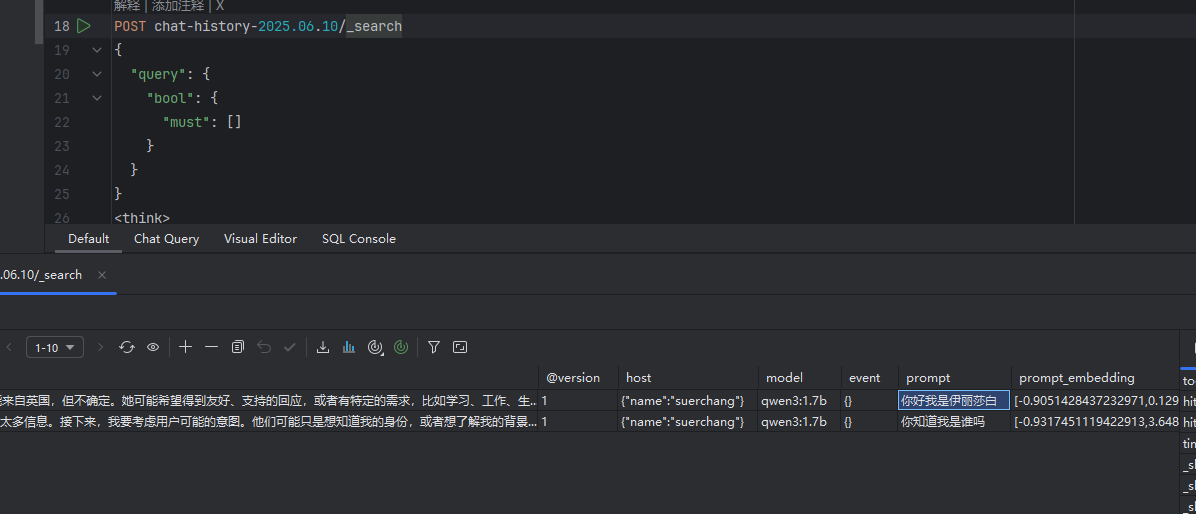
* `num_candidates` 是一個調優參數。根據您的數據量和對準確性/性能的需求進行調整。您的 Spring Boot 應用程序中的 `AIController.java` 代碼正是構建了這樣一個 k-NN 查詢體,并通過 `restTemplate.postForEntity` 發送給 Elasticsearch。現在的關鍵是確保應用程序生成的 `query_vector` (由 `getEmbedding(queryPrompt)` 返回)的維度是正確的 `4096`。這是調試效果:可以看到檢索是成功了,本輪對話問題:"你知道我是誰嗎"
它已經拿到了上一輪對話的內容:“你好我是伊麗薩白?”。
當然1.7b它智商不在線,沒能把我想要的回答組織起來,這通常需要調整提示語:"基于以下聊天歷史記錄" 讓它更好理解。
接下來就是通過配置實現log寫入es
- es:elasticsearch需要手動創建處理管道和模板用用于存儲chat-his.log
PUT _ingest/pipeline/chat-history
{"description": "處理聊天歷史數據的管道","processors": [{"date": {"field": "@timestamp","target_field": "timestamp","formats": ["ISO8601"]}},{"remove": {"field": "@timestamp"}},{"set": {"field": "metadata.processed","value": true}},{"set": {"field": "metadata.processed_at","value": "{{_ingest.timestamp}}"}}]
}PUT _index_template/chat_history_template
{"index_patterns": ["chat-history-*"],"template": {"mappings": {"properties": {"timestamp": {"type": "date","format": "strict_date_optional_time_nanos"},"model": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"prompt": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"response": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"prompt_embedding": {"type": "dense_vector","dims": 4096 //注意這個4096,ollama對應模型的向量維度},"response_embedding": {"type": "dense_vector","dims": 4096 //注意這個4096,ollama對應模型的向量維度}}}}
}- logstash:在原來的基礎上添加了if [log_type] == "chat-history" 的輸入和輸出,這個解析過程一定程度決定于filebeat的輸出格式
# Sample Logstash configuration for creating a complete
# Beats -> Logstash -> Elasticsearch pipeline with log parsinginput {beats {port => 5044}
}# Filter to parse logs using grok and date plugins
filter {if [log_type] == "springboot-app" {grok {match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{DATA:thread}\] %{LOGLEVEL:level} %{DATA:logger} - %{GREEDYDATA:message}" }}}if [log_type] == "chat-history" {# Step 1: 使用 grok 去除三引號(""") 包裹grok {match => {"[event][original]" => "^\"\"\"%{GREEDYDATA:json_content}\"\"\""}tag_on_failure => ["_grok_chat_history_failure"]}# Step 2: 如果提取成功,則嘗試解析 json_contentif [json_content] and [json_content] != "" {json {source => "json_content"target => "parsed_chat_history"remove_field => ["json_content"]}}else {# 如果沒有匹配到三引號,嘗試直接解析 event.original 為 JSONjson {source => "[event][original]"target => "parsed_chat_history"remove_field => ["[event][original]"]}}# Step 3: 提升 chat_log_data 中的字段到頂層if [parsed_chat_history][chat_log_data] {mutate {rename => {"[parsed_chat_history][chat_log_data][timestamp]" => "timestamp""[parsed_chat_history][chat_log_data][model]" => "model""[parsed_chat_history][chat_log_data][prompt]" => "prompt""[parsed_chat_history][chat_log_data][response]" => "response""[parsed_chat_history][chat_log_data][prompt_embedding]" => "prompt_embedding""[parsed_chat_history][chat_log_data][response_embedding]" => "response_embedding"}}# 刪除中間字段mutate {remove_field => ["parsed_chat_history"]}}}}output {if [log_type] == "springboot-app" {elasticsearch {hosts => ["https://localhost:9200"]index => "springboot-logs-%{+YYYY.MM.dd}"ssl_enabled => truessl_verification_mode => "full"ssl_certificate_authorities => ["D:/dev/dev2025/EC0601/elasticsearch-9.0.1/config/certs/http_ca.crt"]api_key => "V6VUSpcBUPesLBBNVAlH:O7l1zeyOwQFfy9w5Af_JTA"}}if [log_type] == "chat-history" {elasticsearch {hosts => ["https://localhost:9200"]index => "chat-history-%{+YYYY.MM.dd}" //匹配es模板自動創建按天分片的索引pipeline => "chat-history" //es管道,對接收的字段做進一步處理,比如日期格式轉換等ssl_enabled => truessl_verification_mode => "full"ssl_certificate_authorities => ["D:/dev/dev2025/EC0601/elasticsearch-9.0.1/config/certs/http_ca.crt"]api_key => "V6VUSpcBUPesLBBNVAlH:O7l1zeyOwQFfy9w5Af_JTA"}}stdout {codec => rubydebug}
}
具體做法在解析前可以要看這里(event字段內容的原始格式)樣式進行解析
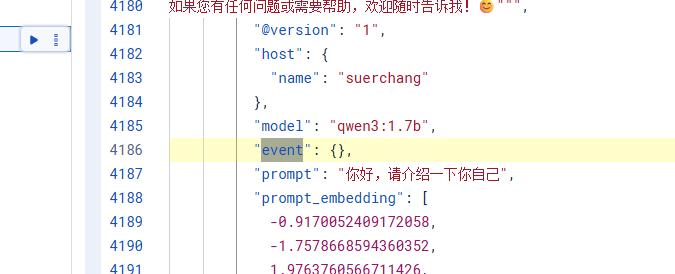
- filebeat:這里加入log_type: chat-history的日志收集
filebeat.inputs:- type: filestreamid: springboot-logspaths:- D:/dev/dev2025/EC0601/logs/springboot-ai-rag-demo.logenabled: truefields:log_type: springboot-appapp_name: springboot-ai-rag-demofields_under_root: truemultiline:pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'negate: truematch: after- type: filestreamid: chat-historypaths:- D:/dev/dev2025/EC0601/logs/chat-his.logenabled: truefields:log_type: chat-historyapp_name: springboot-ai-rag-demofields_under_root: trueoutput.logstash:hosts: ["localhost:5044"]enabled: true# 啟用 HTTP 狀態接口
http.enabled: true
http.port: 5066
logging.level: debug
logging.selectors: ["*"]- JDK:最后是JDK,應為es需要安全證書(https://localhost:9200/),所以java程序在訪問es時,需要把es證書導入證書到jdk目錄? :/lib/security/cacerts
? - 提示輸入密碼時,默認密碼通常是?changeit。
- 當它問“是否信任此證書? [否]:”時,輸入?y?并按回車。
keytool -import -trustcacerts -alias elasticsearch_ca -file "D:/dev/dev2025/EC0601/elasticsearch-9.0.1/config/certs/http_ca.crt" -keystore "C:/Program Files/Java/jdk-17/lib/security/cacerts"- springboot項目:需要修改之前log配置,現在通過logback配置將控制臺日志和聊天日志分析寫入到指定目錄
<?xml version="1.0" encoding="UTF-8"?>
<configuration><property name="LOG_PATH" value="D:/dev/dev2025/EC0601/logs"/><!-- 控制臺輸出 --><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 主應用日志文件 --><appender name="SPRINGBOOT_APP_LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_PATH}/springboot-ai-rag-demo.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_PATH}/springboot-ai-rag-demo.%d{yyyy-MM-dd}.log</fileNamePattern><maxHistory>30</maxHistory></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 聊天歷史記錄文件 --><appender name="CHAT_HISTORY" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_PATH}/chat-his.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_PATH}/chat-his.%d{yyyy-MM-dd}.log</fileNamePattern><maxHistory>30</maxHistory></rollingPolicy><encoder><pattern>%msg%n</pattern></encoder></appender><!-- 聊天歷史記錄日志 --><logger name="com.example.demo.logging.ChatHistoryLogger" level="INFO" additivity="false"><appender-ref ref="CHAT_HISTORY"/></logger><root level="INFO"><appender-ref ref="CONSOLE"/><appender-ref ref="SPRINGBOOT_APP_LOG"/></root>
</configuration> 最后貼一下AIController,和ChatHistoryLogger
package com.example.demo.controller;import com.example.demo.logging.ChatHistoryLogger;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.*;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.client.RestTemplate;import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@RestController
@RequestMapping("/api/ai")
public class AIController {@Value("${ollama.base-url:http://localhost:11434}")private String ollamaBaseUrl;@Value("${spring.elasticsearch.rest.uris:https://localhost:9200}")private String elasticsearchBaseUrl;private final RestTemplate restTemplate = new RestTemplate();private final ObjectMapper objectMapper = new ObjectMapper();@Autowiredprivate ChatHistoryLogger chatHistoryLogger;@PostMapping("/chat")public String chat(@RequestBody Map<String, String> request) {String prompt = request.get("prompt");String model = request.getOrDefault("model", "qwen3:1.7b");// 1. 從 Elasticsearch 獲取歷史記錄 (使用向量檢索)List<String> chatHistory = getChatHistoryFromElasticsearch(prompt);String historyContext = chatHistory.isEmpty() ? "" : "基于以下聊天歷史記錄:\n" + String.join("\n", chatHistory) + "\n";// 2. 構建發送給 Ollama 的完整 promptString fullPrompt = historyContext + prompt;// 調用 Ollama APIMap<String, Object> body = new HashMap<>();body.put("model", model);body.put("prompt", fullPrompt);HttpHeaders headers = new HttpHeaders();headers.setContentType(MediaType.APPLICATION_JSON);HttpEntity<Map<String, Object>> entity = new HttpEntity<>(body, headers);StringBuilder aiResponseBuilder = new StringBuilder();try {restTemplate.execute(ollamaBaseUrl + "/api/generate",HttpMethod.POST,req -> {new ObjectMapper().writeValue(req.getBody(), body);req.getHeaders().setContentType(MediaType.APPLICATION_JSON);},resp -> {try (BufferedReader reader = new BufferedReader(new InputStreamReader(resp.getBody()))) {String line;while ((line = reader.readLine()) != null) {if (!line.trim().isEmpty()) {Map<String, Object> json = objectMapper.readValue(line, Map.class);Object part = json.get("response");if (part != null) {aiResponseBuilder.append(part.toString());}}}}return null;});} catch (Exception e) {aiResponseBuilder.append("與Ollama交互失敗: ").append(e.getMessage());// Optionally log the full stack trace for debugging// logger.error("Error interacting with Ollama", e);}String aiResponse = aiResponseBuilder.length() > 0 ? aiResponseBuilder.toString() : "無響應";// 記錄聊天歷史(包含向量嵌入)chatHistoryLogger.logChat(model, prompt, aiResponse);return aiResponse;}private List<String> getChatHistoryFromElasticsearch(String queryPrompt) {List<String> history = new ArrayList<>();try {// 1. 生成查詢向量List<Float> queryEmbedding = chatHistoryLogger.getEmbedding(queryPrompt);if (queryEmbedding.isEmpty()) {System.err.println("無法為查詢生成嵌入,跳過向量檢索。");return history;}String searchUrl = elasticsearchBaseUrl + "/chat-history-*/_search";// 2. 構建 Elasticsearch k-NN 查詢體Map<String, Object> esQueryBody = new HashMap<>();Map<String, Object> knnMap = new HashMap<>();knnMap.put("field", "response_embedding"); // 用于向量嵌入的字段knnMap.put("query_vector", queryEmbedding);knnMap.put("k", 5); // 返回最相似的 5 個結果knnMap.put("num_candidates", 10); // 搜索候選數量,通常 k 的幾倍esQueryBody.put("knn", knnMap);HttpHeaders headers = new HttpHeaders();headers.setContentType(MediaType.APPLICATION_JSON);headers.setBasicAuth("elastic", "elastic"); // 請替換為您的實際用戶名和密碼HttpEntity<Map<String, Object>> entity = new HttpEntity<>(esQueryBody, headers);ResponseEntity<String> response = restTemplate.postForEntity(searchUrl, entity, String.class);if (response.getBody() != null) {Map<String, Object> responseMap = objectMapper.readValue(response.getBody(), Map.class);List<Map<String, Object>> hits = (List<Map<String, Object>>)((Map<String, Object>) responseMap.get("hits")).get("hits");for (Map<String, Object> hit : hits) {Map<String, Object> source = (Map<String, Object>) hit.get("_source");String historicalPrompt = (String) source.get("prompt");String historicalResponse = (String) source.get("response");String role = (String) source.get("role");String content = (String) source.get("content");// Use prompt and response directly from the sourceif (historicalPrompt != null && historicalResponse != null) {history.add("用戶: " + historicalPrompt + "\nAI: " + historicalResponse);} else if (role != null && content != null) {history.add(role + ": " + content);}}}} catch (Exception e) {System.err.println("從Elasticsearch獲取歷史記錄失敗: " + e.getMessage());}return history;}
} package com.example.demo.logging;import com.fasterxml.jackson.databind.ObjectMapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.*;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Component
public class ChatHistoryLogger {private static final Logger logger = LoggerFactory.getLogger(ChatHistoryLogger.class);private final ObjectMapper objectMapper = new ObjectMapper();private final RestTemplate restTemplate = new RestTemplate();@Value("${ollama.base-url:http://localhost:11434}")private String ollamaBaseUrl;public void logChat(String model, String prompt, String response) {try {// 獲取向量嵌入List<Float> promptEmbedding = getEmbedding(prompt);List<Float> responseEmbedding = getEmbedding(response);// 構建內部日志條目Map<String, Object> innerLogEntry = new HashMap<>();innerLogEntry.put("timestamp", LocalDateTime.now().toString());innerLogEntry.put("model", model);innerLogEntry.put("prompt", prompt);innerLogEntry.put("response", response);innerLogEntry.put("prompt_embedding", promptEmbedding);innerLogEntry.put("response_embedding", responseEmbedding);// 將內部日志條目包裝在新的頂級字段中Map<String, Object> logEntry = new HashMap<>();logEntry.put("chat_log_data", innerLogEntry);String jsonLog = objectMapper.writeValueAsString(logEntry);logger.info(jsonLog);} catch (Exception e) {logger.error("Failed to log chat history", e);}}/**使用 Ollama 的 embeddings API 生成向量 */public List<Float> getEmbedding(String text) {try {Map<String, Object> body = new HashMap<>();body.put("model", "qwen:7b");body.put("prompt", text);HttpHeaders headers = new HttpHeaders();headers.setContentType(MediaType.APPLICATION_JSON);HttpEntity<Map<String, Object>> entity = new HttpEntity<>(body, headers);ResponseEntity<Map> response = restTemplate.postForEntity(ollamaBaseUrl + "/api/embeddings",entity,Map.class);if (response.getBody() != null && response.getBody().containsKey("embedding")) {@SuppressWarnings("unchecked")List<Float> embedding = (List<Float>) response.getBody().get("embedding");return embedding;}} catch (Exception e) {logger.error("Failed to get embedding", e);}return new ArrayList<>();}
} 下面時工作空間結構,由于文件太大,這里就不貼源碼了,后面會上傳到csdn,從csdn下載,謝謝大家的支持。
路由)
)










)


:排序算法與優化分析)



