1.C++引用
1.1引用的概念和定義
引用不是新定義?個變量,而是給已存在變量取了?個別名,編譯器不會為引用變量開辟內存空間,它和它引用的變量共用同?塊內存空間。比如四大名著中林沖,他有一個外號叫豹子頭,類比到C++里就像變量a,有一個別名叫b,它們所代表的其實都是一個東西,只是名稱不同。
類型& 引用別名 = 引用對象
C++中為了避免引入太多的運算符,會復用C語言的?些符號,這里引用和取地址使用了同?個符號&,大家要注意區分。
我們來看一段代碼:
#include<iostream>
using namespace std;int main()
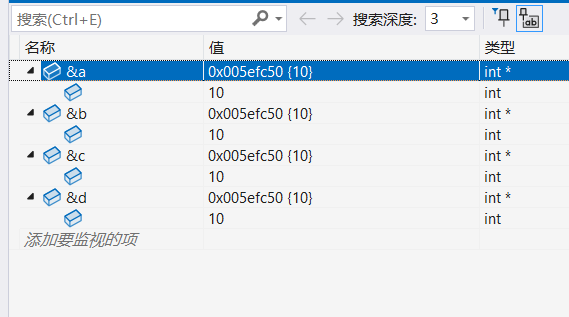
{int a = 10;int& b = a;int& c = a;int& d = b;//引用不僅能給變量取別名,還能給變量的別名取別名cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;
}
根據代碼調試結果和運行結果都可以看到,a,b,c,d共用的是一塊內存空間。
1.2引用的特性
? 引用在定義時必須初始化
int main()
{int a = 10;//如果引用沒有被初始化,會報下面這個錯誤// error C2530: “b”: 必須初始化引用//int& b;int& b = a;return 0;
}
? ?個變量可以有多個引用
這個特性在之前代碼中已經有所體現。
? 引用一旦引用一個實體,再不能引用其他實體
int main()
{int a = 10;int b = 20;int& ra = a;ra = b;cout << &a << endl;cout << &b << endl;cout << &ra << endl;return 0;
}
上面這個代碼我們要格外注意的是ra = b并不是讓ra引用b,而是將b賦值給ra,這將導致ra連帶著a的值發生改變,地址卻不會有變化,如果真是引用,那么ra和b的地址打印結果應該相同。調試結果如下:
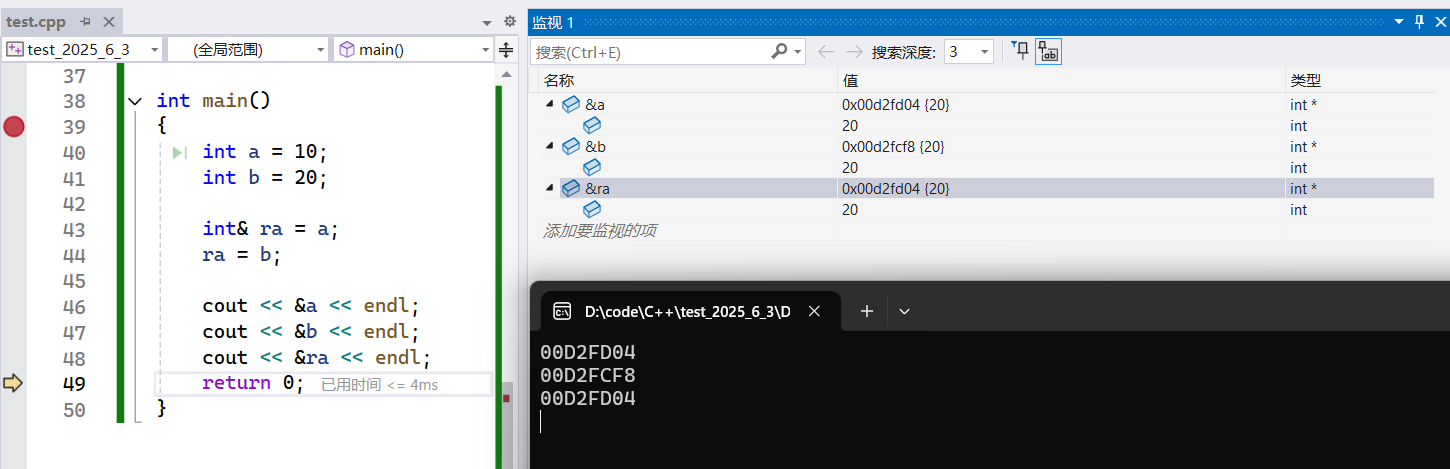
在C++中引用不能改變指向,一旦確定,就無法指向其他變量。
1.3引用的使用
引用在實踐中主要是用于引用傳參和引用做返回值時減少拷貝提高效率和改變引用對象時同時改變被引用對象。
引用傳參舉個最簡單的Swap函數例子:
void Swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}int main()
{int a = 10, b = 20;Swap(a, b);cout << a << endl;//20cout << b << endl;//10return 0;
}
之前寫Swap函數傳參我們要借助指針傳參,因為直接傳參傳的是形參,形參的改變不會改變實參,我們現在可以用引用來代替指針的寫法更便捷,因為引用傳參不需要顯式解引用(*)或取地址(&)操作。引用必須初始化且不能重新綁定,減少了空指針風險。
引用傳參跟指針傳參功能是類似的,引用傳參相對更方便?些。
引用和指針在實踐中相輔相成,功能有重疊性,但是各有特點,互相不可替代。C++的引用跟其他語言的引用(如Java)是有很大的區別的,除了用法,最大的點,C++引用定義后不能改變指向,Java的引用可以改變指向。
引用做返回值相比傳參要復雜一點,我們這里也看一個例子:
int& getElement(int arr[], int index) {return arr[index];
}int main() {int data[3] = { 10, 20, 30 };getElement(data, 1) = 200; for (int i = 0; i < 3; ++i) {cout << data[i] << " ";}return 0;
}
在這段代碼中,getElement 函數使用 引用返回值(int&) 的核心作用是:允許通過函數返回值直接修改原始數組中的元素。
普通值返回(int)的局限性:
如果函數返回值類型為 int(值返回),getElement(data, 1) 會返回 data[1] 的拷貝值(20)。此時執行 getElement(data, 1) = 200; 會報錯,因為 無法對臨時拷貝值進行賦值(臨時值是右值,不能作為賦值的左值)。
引用返回的優勢:
返回引用時,getElement(data, 1) 等價于 data[1] 的別名。對返回值的賦值操作會直接作用于原始數組元素,就像直接操作 data[1] 一樣。
在后面的博文中我們會進一步對引用返回值進行探究。
1.4 const引用
const修飾變量我們在之前的博文中有所提及,大家可以去看指針(一)這篇博文。
在這里我們要用const修飾引用,看下面的例子:
int main()
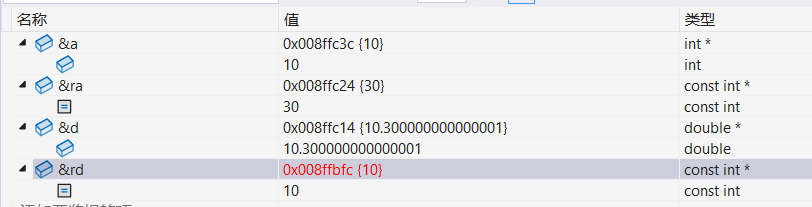
{const int a = 10;//error C2440 : “初始化”: 無法從“const int”轉換為“int& ”//int& ra = a;const int& ra = a;//rightint b = 20;const int& rb = b;//error C3892 : “rb”: 不能給常量賦值//rb++;b++;//rightreturn 0;
}
C++ 中引用初始化的重要規則:非 const 引用不能綁定到 const 對象,但 const 引用可以綁定到非 const 對象。const引用增加了只讀限制,編譯器禁止通過該引用修改內存。因為對象的訪問權限在引用過程中可以縮小,但是不能放大。
int main()
{int a = 10;//error C2440 : “初始化”: 無法從“int”轉換為“int& ”//int& ra = a * 3;const int& ra = a * 3;double d = 10.3;//error C2440: “初始化”: 無法從“double”轉換為“int &”//int& rd = d;const int& rd = d;return 0;
}
需要注意的是類似 int& rb = a*3; double d = 12.34; int& rd = d; 這樣?些場景下a*3的結果保存在?個臨時對象中, int& rd = d 也是類似,在類型轉換中會產生臨時對象存儲中間值,也就是說,rb和rd引用的都是臨時對象,而C++規定臨時對象具有常性,所以這里就觸發了權限放大,必須要用常引用才可以。
所謂臨時對象就是編譯器需要?個空間暫存表達式的求值結果時臨時創建的?個未命名的對象,C++中把這個未命名對象叫做臨時對象。
其實這里編譯器的報錯也不是很對,并不是無法轉換,而是C++規定臨時對象具有常性,權限要匹配的上。
還要注意的是,這里ra和rd的地址空間并不與a和d的地址空間相同,看調試信息:
1.5引用與指針的關系
C++中指針和引用就像兩個性格迥異的親兄弟,指針是哥哥,引用是弟弟,在實踐中他們相輔相成,功能有重疊性,但是各有自己的特點,互相不可替代。
? 語法概念上引用是?個變量的取別名不開空間,指針是存儲?個變量地址,要開空間。
? 引用在定義時必須初始化,指針建議初始化,但是語法上不是必須的。
? 引用在初始化時引用?個對象后,就不能再引用其他對象;而指針可以在不斷地改變指向對象。
? 引用可以直接訪問指向對象,指針需要解引用才是訪問指向對象。
? sizeof中含義不同,引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位平臺下占4個字節,64位下是8byte)
? 指針很容易出現空指針和野指針的問題,引用很少出現,引用使用起來相對更安全?些。
2.缺省參數
? 在 C++ 中,缺省參數(Default Arguments) 是指函數聲明時為參數指定一個默認值,當函數調用時未傳遞該參數時,編譯器會自動使用默認值。這可以簡化函數調用,減少函數重載的數量。(有些地方把缺省參數也叫默認參數)
? 缺省參數分為全缺省和半缺省參數,全缺省就是全部形參給缺省值,半缺省就是部分形參給缺省值。C++規定半缺省參數必須從右往左依次連續缺省,不能間隔跳躍給缺省值。
? 帶缺省參數的函數調用,C++規定必須從左到右依次給實參,不能跳躍給實參。
//C++規定半缺省參數必須從右往左依次連續缺省,不能間隔跳躍給缺省值。
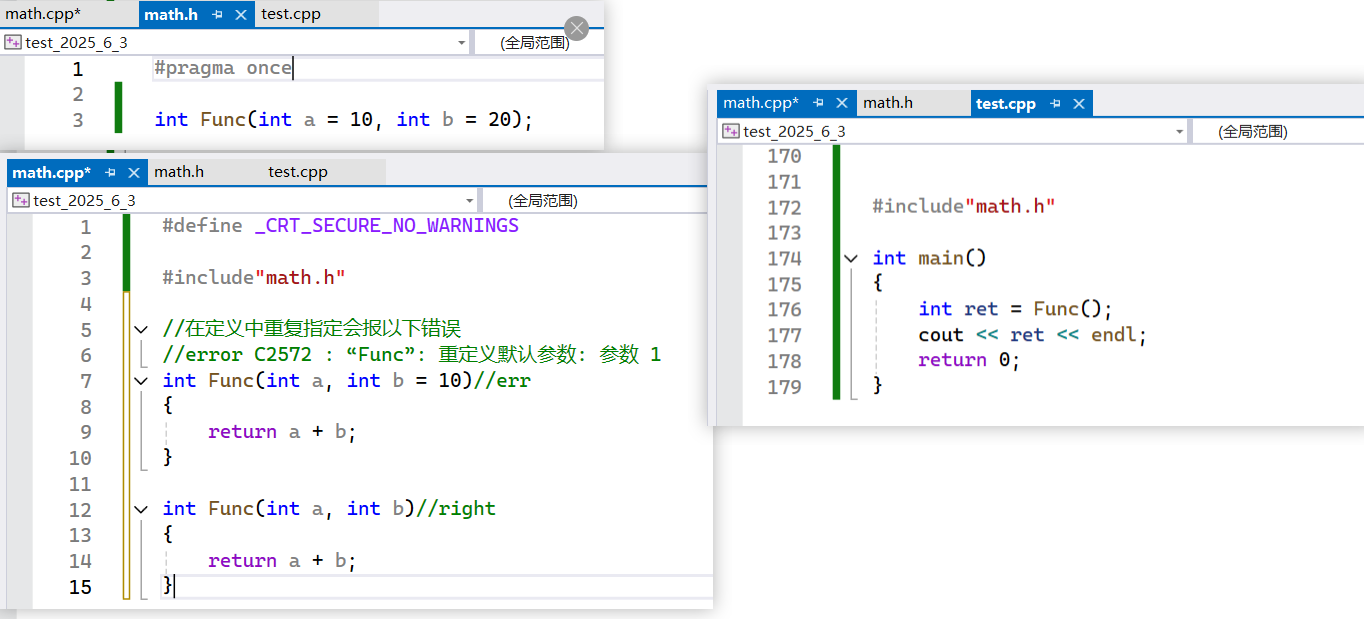
void Func1(int a = 10, int b, int c = 30)//err
void Func1(int a, int b = 20, int c)//err
void Func1(int a = 10, int b, int c)//err//全缺省
void Func1(int a = 10, int b = 20, int c = 30)//right
{cout << a << endl;cout << b << endl;cout << c << endl;
}int main()
{//帶缺省參數的函數調用,C++規定必須從左到右依次給實參,不能跳躍給實參。Func1(, 2, 3);//errfunc1(, , 3);//errFunc1(1, , 3);//errFunc1();Func1(1);Func1(1,2);Func1(1,2,3);return 0;
}
函數聲明和定義分離時,缺省參數只能在函數聲明中指定,不能在函數定義中重復指定
3.函數重載
C++支持在同?作用域中出現同名函數,但是要求這些同名函數的形參不同,可以是參數個數不同或者類型不同。這樣C++函數調用就表現出了多態行為,使用更靈活。C語言是不支持同?作用域中出現同名函數的。
// 1、參數類型不同
void Swap(int& a, int& b)
{int temp = a;a = b;b = temp;
}void Swap(double& a, double& b)
{double temp = a;a = b;b = temp;
}// 2、參數個數不同
void f()
{cout << "f()" << endl;
}void f(int a)
{cout << "f(int a)" << endl;
}// 3、參數類型順序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}// 返回值不同不能作為重載條件,因為調?時也?法區分
//error C2556 : “int fxx(void)” : 重載函數與“void fxx(void)”只是在返回類型上不同
//error C2371: “fxx”: 重定義;不同的基類型
void fxx()
{}int fxx()
{return 0;
}int main()
{fxx();return 0;
}
我們要注意一種情況,當函數重載與缺省參數在同一作用域中結合時,極有可能引發二義性(Ambiguity)問題,導致編譯器無法確定該調用哪個函數。
void f()
{cout << "f()" << endl;
}
void f(int a = 10)
{cout << "f(int a)" << endl;
}
int main()
{f();// error C2668: “f”: 對重載函數的調用不明確return 0;
}
4.inline
在 C++ 中,inline 關鍵字用于定義內聯函數,其核心目的是通過將函數體直接嵌入調用處來減少函數調用的開銷,提高程序運行效率。
4.1 內聯函數的作用
- 減少函數調用開銷常規函數調用需要保存寄存器、跳轉指令、恢復現場等操作,存在固定開銷。
- 內聯函數會在編譯階段將函數體直接替換到調用處,避免了這些開銷,尤其適合短小、高頻調用的函數。
inline int add(int a, int b)
{ return a + b;
}int main()
{int c = add(1, 2);// 編譯后等價于 int c = 1 + 2;return 0;
}
內聯函數具有函數的所有優點(類型檢查、作用域規則),同時具備宏的展開特性。
4.2語法與規則
在函數聲明或定義前加 inline 關鍵字(通常放在定義處)。
inline void func(); // 聲明(可選)
inline void func() { /* 函數體 */ } // 定義(必須標記 inline)
內聯函數的限制
- 函數體應簡潔:復雜函數(如循環、遞歸、switch)可能被編譯器忽略 inline 請求。
- 必須在調用前可見:內聯函數的定義需在調用點之前(通常放在頭文件中),否則編譯器無法展開。
- 與 static 結合:static inline 函數具有文件作用域,避免鏈接沖突。
編譯器的自主性
inline 是對編譯器的建議,而非強制命令。編譯器會根據函數復雜度、優化級別等決定是否真正內聯。
4.3內聯函數與宏的對比
我們之前學過的宏其實有很多隱患,不說隱患,你現在寫一個Add宏,你能正確寫出來嗎?
// 實現?個ADD宏函數的常?問題
//#define ADD(int a, int b) return a + b;
//#define ADD(a, b) a + b;
//#define ADD(a, b) (a + b)// 正確的宏實現
#define ADD(a, b) ((a) + (b))
// 為什么不能加分號?
// 為什么要加外?的括號?
// 為什么要加??的括號?int main()
{int ret = ADD(1, 2);cout << ADD(1, 2) << endl;cout << ADD(1, 2)*5 << endl;int x = 1, y = 2;ADD(x & y, x | y); // -> (x&y+x|y)return 0;
}
我們可以發現宏定義是有非常多坑的,但是用內聯函數就沒有以上問題了,特別簡單。
inline int Add(int a, int b)
{return a + b;
}
| 特性 | 內聯函數 | 宏 |
|---|---|---|
| 類型安全 | 有(編譯時類型檢查) | 無(僅文本替換) |
| 作用域 | 遵循函數作用域規則 | 全局有效 |
| 參數計算 | 僅計算一次(按值傳遞) | 可能多次計算(如 ADD(x++, y++)) |
| 調試支持 | 可調試(保留函數名等信息) | 調試困難(展開后無原始名稱) |
| 語法錯誤檢查 | 有 | 無(替換后由編譯器檢查) |
4.4何時使用inline
推薦場景:
- 高頻調用的小函數
- 替代簡單宏:避免宏的副作用,同時保持效率。
- 模板函數:結合內聯減少編譯期開銷。
不推薦場景:
- 函數體復雜(如包含循環、遞歸):編譯器可能拒絕內聯,甚至導致代碼膨脹。
- 大函數:內聯會導致目標代碼體積增大,可能降低緩存效率。
- 遞歸函數:遞歸深度可能導致棧溢出,且難以有效內聯。

)

)


:設計哲學是什么?)



)

:原理及源碼解析)

![[Linux] MySQL源碼編譯安裝](http://pic.xiahunao.cn/[Linux] MySQL源碼編譯安裝)




