一,散列表查找定義
? ?散列技術是在記錄的存儲位置和它的關鍵字之間建立一個確定的對應關系f,使得每個關鍵字key對應一個存儲位置f(key)。查找時,根據這個確定的對應關系找到給定值key的映射f(key),若查找集中存在這個記錄,則必定在f(key)的位置。
這里我們把這種對應關系f稱為散列函數,又稱為哈希(Hash)函數。
采用散列技術將記錄存儲在一塊連續的存儲空間中,這塊連續存儲空間稱為散列表或哈希表(Hash table)。
那么關鍵字對應的記錄存儲位置稱為散列地址。
二、核心組成部分
-
哈希函數(Hash Function)
-
作用:將任意大小的鍵(Key)轉換為固定范圍的整數(通常作為數組索引)。
-
設計要求:
-
確定性:同一鍵的哈希值必須相同。
-
均勻性:鍵的哈希值應盡可能均勻分布,減少沖突。
-
高效性:計算速度快。
-
-
常見哈希函數:
-
取模運算:
hash(key) = key % size(需注意size通常為質數)。 -
乘法哈希:利用浮點數運算和取模。
-
加密哈希(如MD5、SHA-1):用于分布式系統或安全性場景。
-
-
-
沖突解決(Collision Resolution)
-
沖突原因:不同鍵可能生成相同的哈希值。
-
解決方法:
-
開放尋址法(Open Addressing)
-
當沖突發生時,按某種規則尋找下一個可用位置。
-
探測方式:
-
線性探測:依次檢查下一個位置(
index = (hash(key) + i) % size)。 -
二次探測:按平方跳躍(
index = (hash(key) + i2) % size)。 -
雙重哈希:使用第二個哈希函數計算步長(
index = (hash1(key) + i * hash2(key)) % size)。
-
-
缺點:易產生聚集效應,刪除操作需標記為“已刪除”。
-
-
鏈地址法(Separate Chaining)
-
每個桶(Bucket)存儲一個鏈表(或樹),沖突元素追加到鏈表中。
-
優化:鏈表長度過長時轉換為紅黑樹(如Java 8的
HashMap)。 -
優點:實現簡單,適合頻繁插入/刪除的場景。
-
-
-
三、哈希表操作
-
插入(Insert)
-
計算鍵的哈希值,找到對應位置。
-
若位置為空,直接插入;若沖突,按沖突解決策略處理。
-
-
查找(Search)
-
計算哈希值定位桶,遍歷鏈表(鏈地址法)或探測后續位置(開放尋址法),直到找到鍵或確認不存在。
-
-
刪除(Delete)
-
類似查找操作,找到元素后標記刪除(開放尋址法需特殊標記)或從鏈表中移除。
-
四,散列函數的構造方法
1.直接定址法
核心思想為:直接使用鍵的值作為哈希表的存儲位置,無需復雜的哈希計算,因此可以完全避免沖突。
1.1 直接定址法的定義
-
基本思想:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?hash(key)=key
當鍵的取值范圍較小且連續時(例如鍵是整數,范圍在?[0, N-1]),可以直接使用鍵本身作為數組的索引。此時,哈希函數為:即直接將鍵映射到數組的對應位置。
-
適用條件:
鍵的取值必須滿足以下兩個條件:-
范圍有限:鍵的取值范圍不能過大,否則需要極大數組,浪費內存。
-
連續分布:鍵的取值是連續的(或接近連續),避免數組中出現大量未使用的空洞。
-
1.2 工作原理
-
初始化:創建一個大小為?𝑁N?的數組(𝑁N?為鍵的最大值加1)。
-
插入操作:將鍵?𝑘k?對應的值存儲在數組的第?𝑘k?個位置。
array[key] = value -
查找操作:直接訪問數組的第?𝑘k?個位置獲取值。
value = array[key] -
刪除操作:將數組的第?𝑘k?個位置標記為空或賦予特定值(如?
None)。
1.3 適用場景
-
鍵為小范圍整數:
-
如學號、員工編號、IP地址的最后8位(0-255)等。
-
-
內存充足且追求極致性能:
-
如實時系統中的關鍵數據查詢。
-
-
無沖突要求的場景:
-
如某些硬件設計或嵌入式系統,需嚴格避免哈希沖突。
-
1.4 示例代碼
#include <stdio.h>
#include <stdlib.h>typedef struct {int max_key;int* table;
} DirectAddressTable;DirectAddressTable* createTable(int max_key) {DirectAddressTable* da_table = (DirectAddressTable*)malloc(sizeof(DirectAddressTable));if (!da_table) return NULL;da_table->max_key = max_key;da_table->table = (int*)malloc(sizeof(int) * (max_key + 1));if (!da_table->table) {free(da_table);return NULL;}for (int i = 0; i <= max_key; i++) {da_table->table[i] = -1;}return da_table;
}void insert(DirectAddressTable* da_table, int key, int value) {if (key < 0 || key > da_table->max_key) {printf("Error: Key %d out of range [0, %d]\n", key, da_table->max_key);return;}da_table->table[key] = value;
}int search(DirectAddressTable* da_table, int key) {if (key < 0 || key > da_table->max_key) {printf("Error: Key %d out of range [0, %d]\n", key, da_table->max_key);return -1;}return da_table->table[key];
}// 修改函數名為 deleteKey
void deleteKey(DirectAddressTable* da_table, int key) {if (key < 0 || key > da_table->max_key) {printf("Error: Key %d out of range [0, %d]\n", key, da_table->max_key);return;}da_table->table[key] = -1;
}void destroyTable(DirectAddressTable* da_table) {if (da_table) {free(da_table->table);free(da_table);}
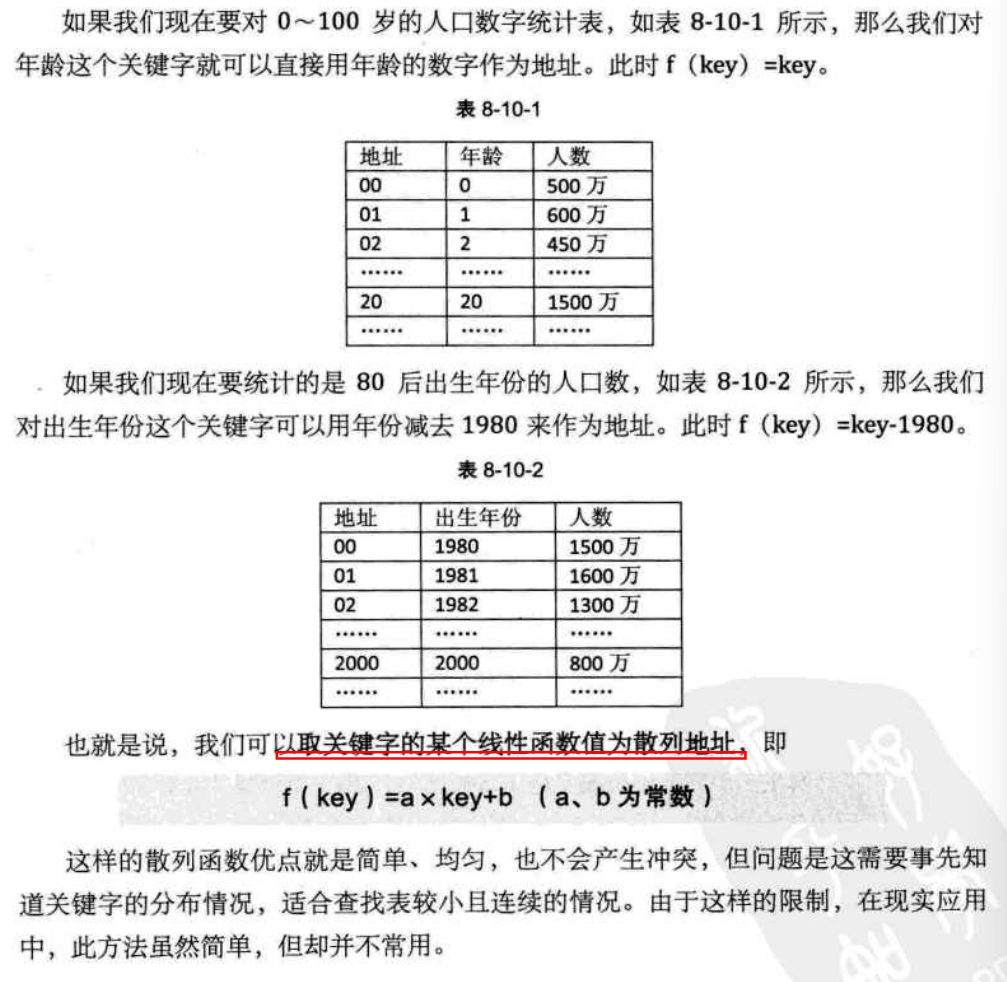
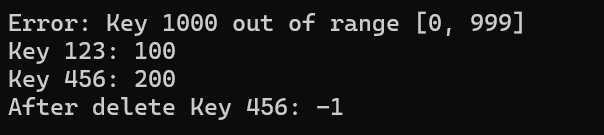
}int main() {DirectAddressTable* table = createTable(999);if (!table) {printf("Failed to create table!\n");return 1;}insert(table, 123, 100);insert(table, 456, 200);insert(table, 999, 300);insert(table, 1000, 400); // 觸發越界錯誤printf("Key 123: %d\n", search(table, 123)); // 100printf("Key 456: %d\n", search(table, 456)); // 200deleteKey(table, 456); // 修改為 deleteKeyprintf("After delete Key 456: %d\n", search(table, 456)); // -1destroyTable(table);return 0;
}?
2.開放定址法
? 所謂的開放定址法就是一旦發生了沖突,就去尋找下一個空的散列地址,只要散列表組足夠大,空的散列表地址總能找到,并將記錄存入
2.1 核心思想
-
基本規則
-
當插入或查找時,若目標位置已被占用(發生沖突),則按預定的探測序列依次檢查后續位置,直到找到空槽或目標鍵。
-
所有操作(插入、查找、刪除)必須遵循相同的探測規則。
-
-
關鍵特點
-
內存緊湊:所有數據存儲在數組中,無額外指針開銷。
-
探測序列設計:探測方式直接影響性能,需避免聚集(Clustering)現象。
-
刪除需標記:直接刪除元素會導致探測鏈斷裂,需用特殊標記(如
TOMBSTONE)占位。
-
2.2 探測方法
探測序列的設計是開放定址法的核心。以下是三種常見探測方式:
1. 線性探測(Linear Probing)
-
規則:
若位置?hash(key)?沖突,則依次檢查?(hash(key) + i) % size(i=1,2,3...)。 -
示例:
-
插入鍵?
k1(哈希到位置 3),沖突后存入位置 4。 -
插入鍵?
k2(哈希到位置 3),沖突后存入位置 5。
-
-
優點:
-
實現簡單,緩存友好(連續內存訪問)。
-
-
缺點:
-
易產生聚集(Clustering):連續沖突形成長鏈,降低效率。
-
2. 二次探測(Quadratic Probing)
-
規則:
沖突后檢查?(hash(key) + c1*i + c2*i2) % size(i=1,2,3...,通常取?c1=1,?c2=1)。 -
示例:
-
插入鍵?
k1(哈希到位置 3),沖突后依次檢查位置 4(3+1)、6(3+1+12)、...
-
-
優點:
-
減少聚集現象,分布更均勻。
-
-
缺點:
-
探測序列可能無法覆蓋所有槽位(需哈希表大小為質數且負載因子≤0.5)。
-
3. 雙重哈希(Double Hashing)
-
規則:
index=(hash1(𝑘𝑒𝑦)+𝑖×hash2(𝑘𝑒𝑦))?%?sizeindex=(hash1(key)+i×hash2(key))?%?size
使用第二個哈希函數計算步長:-
hash2(key)?不能為0,通常設計為?hash2(key) = R - (key % R)(R?為小于表大小的質數)。
-
-
示例:
-
hash1(k)=3,hash2(k)=5,沖突后探測位置 8, 13, 18...
-
-
優點:
-
最接近理想均勻分布,沖突率最低。
-
-
缺點:
-
計算成本略高,需設計兩個哈希函數。
-


?2.3 代碼示例
#include <stdio.h>
#include <stdlib.h>#define SIZE 10
#define TOMBSTONE -2typedef struct {int key;int value;
} Entry;typedef struct {Entry* table;int size;int count; // 有效元素數(不含TOMBSTONE)
} OpenAddressHashTable;OpenAddressHashTable* createHashTable() {OpenAddressHashTable* ht = (OpenAddressHashTable*)malloc(sizeof(OpenAddressHashTable));ht->size = SIZE;ht->count = 0;ht->table = (Entry*)malloc(sizeof(Entry) * SIZE);for (int i = 0; i < SIZE; i++) {ht->table[i].key = -1; // -1表示空位}return ht;
}int hash1(int key) {return key % SIZE;
}int hash2(int key) {return 7 - (key % 7); // 7為小于SIZE的質數
}int probe(int key, int i) {return (hash1(key) + i * hash2(key)) % SIZE;
}void insert(OpenAddressHashTable* ht, int key, int value) {if (ht->count >= ht->size * 0.7) {printf("Warning: Load factor exceeds 0.7, consider rehashing.\n");}for (int i = 0; i < ht->size; i++) {int index = probe(key, i);if (ht->table[index].key == -1 || ht->table[index].key == TOMBSTONE) {ht->table[index].key = key;ht->table[index].value = value;ht->count++;return;} else if (ht->table[index].key == key) {ht->table[index].value = value; // 更新現有鍵return;}}printf("Error: Hash table is full!\n");
}int search(OpenAddressHashTable* ht, int key) {for (int i = 0; i < ht->size; i++) {int index = probe(key, i);if (ht->table[index].key == key) {return ht->table[index].value;} else if (ht->table[index].key == -1) {return -1; // 未找到}}return -1;
}// 修改函數名為 deleteKey
void deleteKey(OpenAddressHashTable* ht, int key) {for (int i = 0; i < ht->size; i++) {int index = probe(key, i);if (ht->table[index].key == key) {ht->table[index].key = TOMBSTONE;ht->count--;return;} else if (ht->table[index].key == -1) {return; // 未找到}}
}void destroyHashTable(OpenAddressHashTable* ht) {free(ht->table);free(ht);
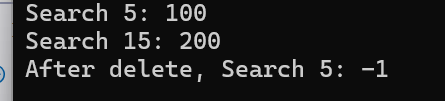
}int main() {OpenAddressHashTable* ht = createHashTable();insert(ht, 5, 100);insert(ht, 15, 200); // 沖突,使用雙重哈希探測printf("Search 5: %d\n", search(ht, 5)); // 100printf("Search 15: %d\n", search(ht, 15)); // 200deleteKey(ht, 5); // 原 delete(ht, 5)printf("After delete, Search 5: %d\n", search(ht, 5)); // -1destroyHashTable(ht);return 0;
}
3.再散列函數法(Rehashing/雙散列法)
核心思想
當哈希沖突發生時,通過第二個(或更多)哈希函數重新計算存儲位置,直到找到空閑的槽位。屬于開放定址法的一種。
工作流程
-
首次哈希:用第一個哈希函數??1(𝑘𝑒𝑦)h1?(key)?計算初始位置。
-
沖突處理:若沖突,用第二個哈希函數??2(𝑘𝑒𝑦)h2?(key)?計算偏移量,按公式?(?1+𝑖×?2)%表大小(h1?+i×h2?)%表大小?探測(𝑖i?為嘗試次數)。
-
重復探測:直到找到空位或遍歷全表。
示例
假設??1(𝑘)=𝑘%7h1?(k)=k%7,?2(𝑘)=5?(𝑘%5)h2?(k)=5?(k%5),插入鍵 23 和 30:
-
23 →?23%7=223%7=2(直接插入位置2)
-
30 →?30%7=230%7=2(沖突),計算偏移??2(30)=5?0=5h2?(30)=5?0=5,新位置?(2+1×5)%7=0(2+1×5)%7=0
優缺點
-
優點:減少聚集現象,探測序列分布均勻。
-
缺點:多次計算可能耗時,需合理設計哈希函數避免循環。
應用場景
-
內存受限環境(無需額外指針)。
-
預期沖突率較低的場景(如數據庫索引)。
4.鏈地址法(拉鏈法/Separate Chaining)
4.1核心思想
每個哈希桶維護一個鏈表(或樹),沖突元素直接追加到鏈表中。哈希表退化為“鏈表數組”。
4.2 工作流程
-
哈希計算:用??(𝑘𝑒𝑦)h(key)?找到桶位置。
-
鏈表操作:
-
插入:將新元素插入鏈表頭部或尾部。
-
查找:遍歷鏈表比對鍵值。
-
刪除:找到節點后斷開鏈接。
-
4.3 示例
哈希函數??(𝑘)=𝑘%3h(k)=k%3,插入 3, 6, 9:
-
桶0:3 → 9(插入到鏈表)
-
桶1:空
-
桶2:6
4.4 優化策略
-
鏈表轉紅黑樹:當鏈表長度超過閾值(如Java HashMap的閾值8),轉為樹結構提升查詢效率。
4.5 優缺點
-
優點:處理高沖突高效,實現簡單,適合動態數據。
-
缺點:指針占用額外內存,鏈表過長影響性能。
4.6 應用場景
-
Java HashMap、C++ unordered_map。
-
頻繁插入刪除的場景。
5.公共溢出區法
5.1 核心思想
將哈希表分為主表和溢出區,沖突元素統一存放到獨立的溢出區域。
5.2 工作流程
-
主表插入:通過??(𝑘𝑒𝑦)h(key)?找到主表位置。
-
溢出處理:若主表位置已占用,將元素存入溢出區(順序存儲或鏈表結構)。
-
查找邏輯:先查主表,未命中則遍歷溢出區。
5.3 示例
主表大小5,溢出區大小3。插入鍵 5, 10, 15(假設??(𝑘)=𝑘%5h(k)=k%5):
-
主表位置0:5
-
主表位置0沖突,10和15存入溢出區。
5.4 管理策略
-
溢出區結構:可采用順序表(簡單但查詢慢)或鏈表(需額外指針)。
-
合并整理:定期將溢出區數據遷移回主表(需重新哈希)。
5.5 優缺點
-
優點:實現簡單,主表結構穩定。
-
缺點:溢出區可能成為性能瓶頸,需合理設計大小。
5.6 應用場景
-
嵌入式系統等內存布局固定的場景。
-
沖突較少或數據規模可預估的情況。
五,散列表查找實現
1.散列表查找算法實現
無論采用何種沖突解決方法,查找的核心步驟均為:
-
計算哈希值:用哈希函數計算鍵的初始位置。
-
定位元素:
-
若當前位置的鍵匹配 → 返回數據。
-
若位置為空 → 表示不存在該鍵。
-
若位置被占用但鍵不匹配 → 按沖突策略繼續查找。
-
-
處理沖突:根據沖突解決策略(如開放定址法、鏈地址法)繼續探測。
示例代碼:
#include <stdio.h>
#include <stdlib.h>#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12 // 散列表長度
#define NULLKEY -32768 // 空標記
#define OK 1
#define ERROR 0typedef int Status;typedef struct {int *elem; // 數據存儲基址int count; // 元素個數
} HashTable;int m = 0; // 全局表長/* 初始化散列表 */
Status InitHashTable(HashTable *H) {m = HASHSIZE;H->count = m;H->elem = (int *)malloc(m * sizeof(int));for (int i = 0; i < m; i++) {H->elem[i] = NULLKEY;}return OK;
}/* 散列函數(除留余數法) */
int Hash(int key) {return key % m;
}/* 插入關鍵字 */
void InsertHash(HashTable *H, int key) {int addr = Hash(key);// 線性探測解決沖突while (H->elem[addr] != NULLKEY) {addr = (addr + 1) % m;}H->elem[addr] = key;
}/* 查找關鍵字 */
Status SearchHash(HashTable H, int key, int *addr) {*addr = Hash(key);// 記錄初始探測位置int startAddr = *addr;while (H.elem[*addr] != key) {*addr = (*addr + 1) % m;// 遇到空位或回到起點說明不存在if (H.elem[*addr] == NULLKEY || *addr == startAddr) {return UNSUCCESS;}}return SUCCESS;
}int main() {HashTable H;int keys[] = {12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34};int n = sizeof(keys)/sizeof(keys[0]);// 初始化散列表if (InitHashTable(&H) != OK) {printf("初始化失敗!\n");return 1;}// 插入數據for (int i = 0; i < n; i++) {InsertHash(&H, keys[i]);}// 驗證插入結果printf("散列表內容:");for (int i = 0; i < m; i++) {printf("%d ", H.elem[i]);}printf("\n");// 查找測試int target = 37;int addr;if (SearchHash(H, target, &addr) {printf("找到%d,位置:%d\n", target, addr);} else {printf("未找到%d\n", target);}free(H.elem);return 0;
}六、優缺點分析
-
優點:
-
平均時間復雜度O(1),適合高頻查詢場景。
-
靈活支持動態數據。
-
-
缺點:
-
哈希函數設計不當會導致沖突頻繁,性能退化至O(n)。
-
內存預分配可能浪費空間。
-
無法保證元素順序(有序哈希表需額外設計)。
-
七、應用場景
-
字典(Dictionary):如Python的
dict、C++的unordered_map。 -
緩存系統:如Redis、Memcached。
-
數據庫索引:加速數據檢索。
-
唯一性檢查:快速判斷元素是否存在(如布隆過濾器)。
八、優化與變種
-
完美哈希(Perfect Hashing):無沖突的哈希函數,適用于靜態數據集。
-
一致性哈希(Consistent Hashing):用于分布式系統,減少節點增減時的數據遷移。
-
布隆過濾器(Bloom Filter):基于哈希的概率數據結構,用于高效判斷元素是否存在。
九、代碼實現示例(Python)
class HashTable:def __init__(self, size=10):self.size = sizeself.table = [[] for _ in range(size)] # 鏈地址法def _hash(self, key):return hash(key) % self.size # 使用內置哈希函數取模def insert(self, key, value):idx = self._hash(key)for item in self.table[idx]:if item[0] == key:item[1] = value # 更新現有鍵returnself.table[idx].append([key, value]) # 插入新鍵def get(self, key):idx = self._hash(key)for item in self.table[idx]:if item[0] == key:return item[1]raise KeyError(f"Key {key} not found")def delete(self, key):idx = self._hash(key)for i, item in enumerate(self.table[idx]):if item[0] == key:del self.table[idx][i]returnraise KeyError(f"Key {key} not found")十、總結
哈希表通過巧妙的哈希函數和沖突解決策略,在時間與空間之間實現高效平衡。理解其原理和實現細節,有助于在開發中選擇合適的優化策略(如動態擴容、鏈與樹的轉換),應對不同場景的需求。




深度解析:國產分布式數據庫的旗艦之作)
)


![【洛谷P9303題解】AC- [CCC 2023 J5] CCC Word Hunt](http://pic.xiahunao.cn/【洛谷P9303題解】AC- [CCC 2023 J5] CCC Word Hunt)






)



