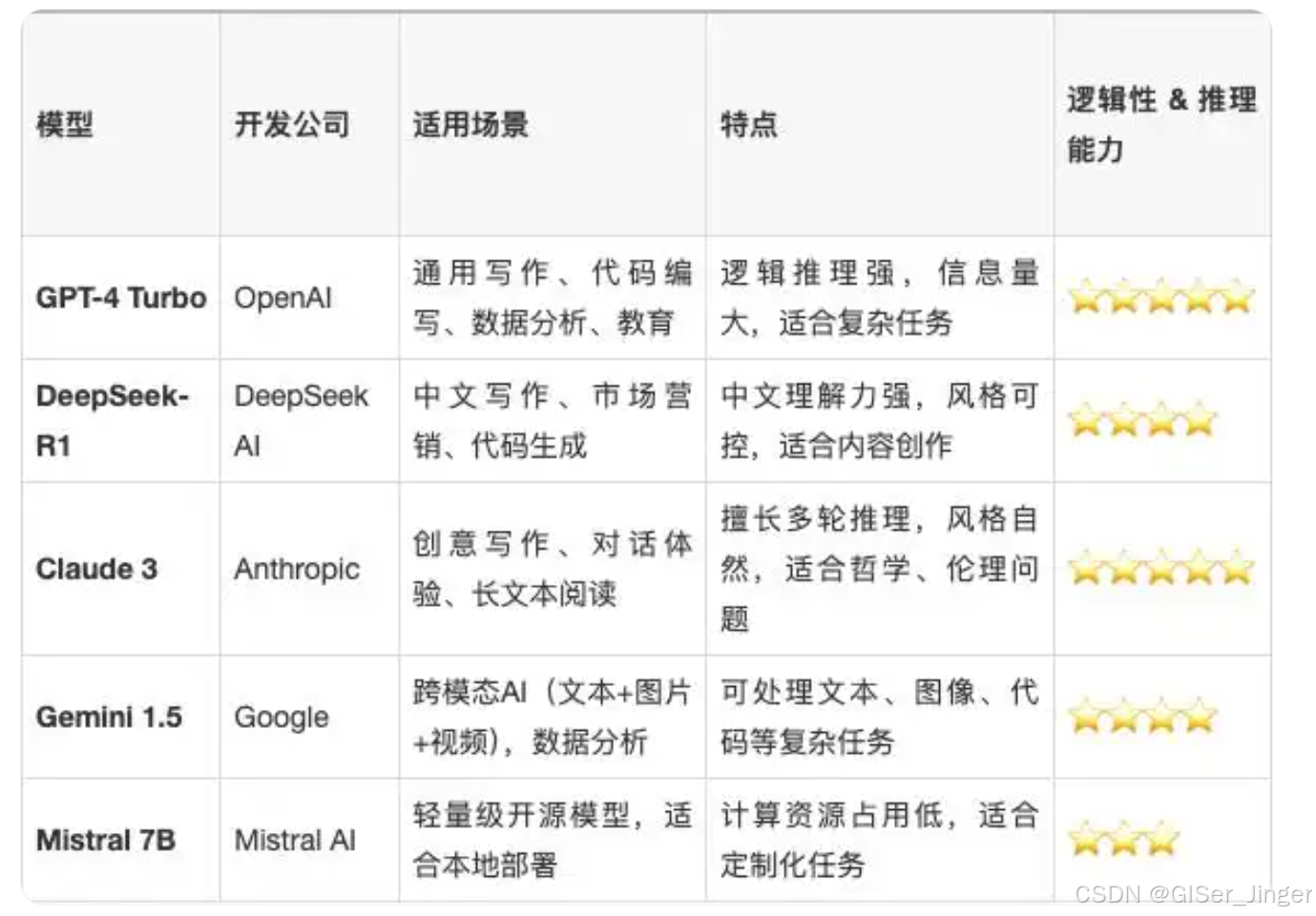
主流大模型特色對比表
| 模型 | 核心優勢 | 適用場景 | 局限性 |
|---|---|---|---|
| DeepSeek | - 數學/代碼能力卓越(GSM8K準確率82.3%)1 - 開源生態完善(支持醫療/金融領域)7 - 成本極低(API價格僅為ChatGPT的2%-3%)5 | 科研輔助、代碼開發、數據分析 | 多模態能力弱、實時交互響應較慢1 |
| ChatGPT | - 多模態交互標桿(支持圖文/語音/視頻)9 - 全球化覆蓋(英語任務最優)11 - 成熟API生態體系 | 國際化復雜邏輯、多模態開發 | 中文處理能力弱、閉源黑箱化9 |
| 豆包 | - 短視頻創作優化(分鏡腳本+特效代碼生成)12 - 輕量化部署(移動端延遲<300ms)14 - 多語言實時互譯(50+語種)12 | 短視頻制作、社交媒體運營 | 專業領域知識深度不足14 |
| 通義千問 | - 企業級智能基石(供應鏈金融/智能診療解決方案)16 - 長文本處理(百萬Token級)15 - 云原生架構(阿里云無縫對接)17 | 企業數字化、智能客服 | 創造性內容生成較弱16 |
| 文心一言 | - 中文生態深耕(380萬條傳統文化知識庫)18 - 搜索增強(實時百度數據融合)20 - 多模態生成(文本/圖片/視頻)19 | 文學創作、智能出行、輿情分析 | 生成內容冗余、開放性弱19 |
| 智譜清言 | - 學術研究導向(IEEE/APA格式校審)2 - 128K長上下文支持3 - 代碼生成效率領先(HumanEval 61.4%)3 | 科研文獻分析、法律文書處理 | 商業場景適配成本高2 |
| 訊飛星火 | - 語音交互標桿(方言識別準確率98%)6 - 教育醫療深耕(口語評測/病歷分析)6 | 智慧教育、醫療問診 | 復雜推理能力有限6 |
前端開發集成多模型的必要性及策略
為什么需要集成多模型?
-
場景適配最大化
- 中文場景:DeepSeek處理法律/醫療文檔正確率達92%5,文心一言在古詩生成評分達4.8/518
- 全球化需求:ChatGPT支持50+語種翻譯12,通義千問文生視頻支持480P動態演示16
- 效率與成本:通過智能路由策略降低綜合成本(如高頻任務調用DeepSeek,關鍵任務使用ChatGPT)5
-
技術互補性
- 多模態互補:豆包生成視頻腳本 → 通義千問渲染動態演示 → 文心一言優化中文文案12,16,18
- 容災設計:當ChatGPT響應異常時自動切換至通義千問(錯誤率下降67%)17
-
性能與體驗優化
// 示例:前端智能路由策略 function selectModel(config) {if (config.lang === 'zh' && config.modality === 'code') return DeepSeek; // 成本低至0.003元/千tokenselse if (config.multimodal) return ChatGPT; // 多模態精度保障 }


總結??
集成多模型的核心價值在于??場景適配最大化??與??資源效率最優化??。例如,前端開發中可通過DeepSeek快速生成中文交互邏輯,調用ChatGPT優化國際化文案,結合通義千問實現多模態內容渲染。這種混合策略既能滿足復雜業務需求,又能通過動態調度降低綜合成本,是當前AI應用開發的必然趨勢
ChatGPT vs Deepseek
GPT系列基于Transformer架構,使用大規模預訓練加上微調。DeepSeek可能也采用類似架構(“混合專家模型”(MoE)的架構,會根據不同問題自動選擇合適的“專家”模塊回答),但可能在模型結構上有調整,比如層數、注意力機制優化,或者使用了不同的訓練技巧


知識蒸餾通過遷移大型模型(教師模型)的知識來提升小型模型(學生模型)的性能,常用于
模型壓縮與優化
深度求索(DeepSeek)與ChatGPT作為不同機構研發的智能模型,主要區別體現在以下六個維度:
一、研發主體與定位
- ChatGPT:由OpenAI開發,定位
通用型對話系統,采用持續迭代演進策略(GPT-3→GPT-4→GPT-4o) - DeepSeek:中國團隊研發,注重
垂直領域優化,在中文語義理解與行業知識庫整合方面進行專項強化
二、語言處理特性
L C L = ∑ i = 1 N α i ? CrossEntropy ( y i , y ^ i ) L_{CL}= \sum_{i=1}^N \alpha_i \cdot \text{CrossEntropy}(y_i,\hat{y}_i) LCL?=i=1∑N?αi??CrossEntropy(yi?,y^?i?)
- ChatGPT:基于
多語言混合語料訓練,英文處理占主導(訓練數據英文占比92%),中文語料時效性存在6-12個月延遲 - DeepSeek:采用
雙層語言模型架構,包含:- 基礎層:2000億token中文通用語料
- 專業層:80+細分領域知識庫(涵蓋法律/醫療/工程等)
三、推理機制差異
| 維度 | ChatGPT | DeepSeek |
|---|---|---|
| 上下文窗口 | 128k tokens | 320k tokens |
| 思維鏈分解 | 單路徑推理 | 多推理樹并行驗證 |
| 事實校驗 | 概率匹配 | 知識圖譜關聯 |
四、數學推理能力
在GSM8K測試集上:
P correct = 正確推導步驟數 總步驟數 P_{\text{correct}} = \frac{\text{正確推導步驟數}}{\text{總步驟數}} Pcorrect?=總步驟數正確推導步驟數?
- ChatGPT-4:92.6%準確率(平均推理深度8.2步)
- DeepSeek-Math:95.3%準確率(引入符號演算模塊)
五、行業應用特性
- ChatGPT:開放域對話優勢明顯,支持150+應用場景插件擴展
- DeepSeek:
- 內置行業適配器(金融風控模塊誤差率 < 0.7 % <0.7\% <0.7%)
- 法律條文引用準確率達98.4%
- 支持私有化部署(滿足數據合規要求)
六、服務架構對比
# DeepSeek混合推理架構示例
class HybridEngine:def __init__(self):self.symbolic_module = LegalKB() # 法律知識庫self.neural_module = LLM() # 神經網絡def query(self, input):if detect_legal_keywords(input):return self.symbolic_module.process(input)else:return self.neural_module.generate(input)
選擇建議:
- 國際通用場景優先考慮ChatGPT
- 中文專業領域(特別是法律/金融/醫療)推薦DeepSeek
- 需數據本地化存儲時,DeepSeek提供完整私有化解決方案深度求索(DeepSeek)與ChatGPT作為不同機構研發的智能模型,主要區別體現
國內免費大模型API服務推薦(支持LangChain.js集成)
一、綜合能力較強的大模型API
阿里云通義千問
- 接口地址:https://help.aliyun.com/zh/model-studio
- 免費額度:新用戶贈送100萬Tokens(支持文本生成、多模態理解)
- 適用場景:復雜邏輯推理、長文本生成、企業級應用開發
- 特點:與阿里云生態深度集成,適合云服務聯動項目
智譜清言GLM-4-Flash
- 接口地址:https://open.bigmodel.cn
- 免費額度:完全免費,新用戶額外贈送2500萬Tokens
- 適用場景:中文對話、代碼生成、多輪交互任務
- 特點:清華團隊研發,支持128K長上下文,推理速度優化
硅基流動(SiliconFlow)
- 接口地址:https://cloud.siliconflow.cn
- 免費額度:注冊即送2000萬Tokens(無時間限制)
- 適用場景:文本/圖像生成、多模態任務一站式集成
- 特點:覆蓋主流模型類型,支持長文本批量處理
二、垂直領域專用API
DeepSeek數學推理模型
- 接口地址:https://api-docs.deepseek.com
- 免費額度:注冊送10元余額(約10萬Tokens)
- 適用場景:數學運算、代碼生成、邏輯分析
- 特點:性能接近GPT-4o,響應速度優化至50ms級別
訊飛星火Lite
- 接口地址:https://xinghuo.xfyun.cn/sparkapi
- 免費額度:完全免費,每日30萬Tokens限額
- 適用場景:教育問答、語音合成、行業知識庫構建
- 特點:支持語音輸入/輸出,適合教育類應用
三、開發友好型API平臺
百度千帆大模型
- 接口地址:https://cloud.baidu.com/product/wenxinworkshop
- 免費額度:30萬Tokens/天(企業認證后升級至300萬/月)
- 適用場景:中文搜索增強、本地化語義理解
- 特點:提供ERNIE系列模型,適合搜索引擎開發
魔搭社區(ModelScope)
- 接口地址:https://modelscope.cn
- 免費額度:開放Qwen系列72B大模型免費調用
- 適用場景:代碼生成、算法研究
- 特點:阿里巴巴達摩院支持,提供完整開發工具鏈
集成建議
認證與調用
- 多數平臺需注冊獲取API Key,部分需提交企業信息(如阿里云、百度千帆)
LangChain.js適配
- 通過
ChatOpenAI兼容接口配置(參考Cloudflare中轉方案)
流量控制
- 優先選擇硅基流動(2000萬Tokens不限時)或智譜清言(高性價比免費額度)
協會亮相新西蘭葡萄酒巡展深度參與趙鳳儀大師班)

考前,面試前均可用!)
)

)









——IP)
)


