目錄
一、MapReduce概述
1.1 MapReduce 定義
1.2?MapReduce優缺點
1.3?MapReduce 核心思想
1.4?MapReduce 進程
1.5?常用數據序列化類型
1.6?MapReduce 編程規范
二、WordCound 案例
2.1 環境準備
2.2?編寫程序
三、MapReduce?工作流程
一、MapReduce概述
1.1 MapReduce 定義
MapReduce是一個 分布式運算程序 的編程框架,是用戶開發“基于 Hadoop的數據分析
應用”的核心框架。
MapReduce核心功能是將 用戶編寫的業務邏輯代碼 和 自帶默認組件 整合成一個完整的
分布式運算程序 ,并發運行在一個 Hadoop集群上。
1.2?MapReduce優缺點
優點分析:
1. MapReduce易于編程:它簡單的實現一些接口,就可以完成一個分布式程序,這個分布式程序可以分布到大量廉價的 PC機器上運行。也就是說你寫一個分布式程序,跟寫一個簡單的串行程序是一模一樣的。就是因為這個特點使得 MapReduce編程變得非常流行。
2.?良好的擴展性:當你的計算資源不能得到滿足的時候,你可以通過簡單的增加機器 來擴展它的計算能力。
3.?高容錯性:MapReduce設計的初衷就是使程序能夠部署在廉價的 PC機器上,這就要求它具有很高的容錯性。比如 其中一臺機器掛了,它可以把上面的計算任務轉移到另外一個節點上運行,不至于這個任務運行失敗 ,而且這個過程不需要人工參與,而完全是由 Hadoop內部完成的。
4. 適合 PB級以上海量數據的離線處理:可以實現上千臺服務器集群并發工作,提供數據處理能力。
缺點分析:
1.?不擅長實時計算:MapReduce 無法像MySQL 一樣,在毫秒或者秒級內返回結果。
2.?不擅長流式計算:流式計算的輸入數據是動態的,而MapReduce 的輸入數據集是靜態的,不能動態變化。這是因為MapReduce 自身的設計特點決定了數據源必須是靜態的。
3.?不擅長DAG(有向無環圖)計算:多個應用程序存在依賴關系,后一個應用程序的輸入為前一個的輸出。在這種情況下,MapReduce 并不是不能做,而是使用后,每個MapReduce 作業的輸出結果都會寫入到磁盤,會造成大量的磁盤IO,導致性能非常的低下。
1.3?MapReduce 核心思想
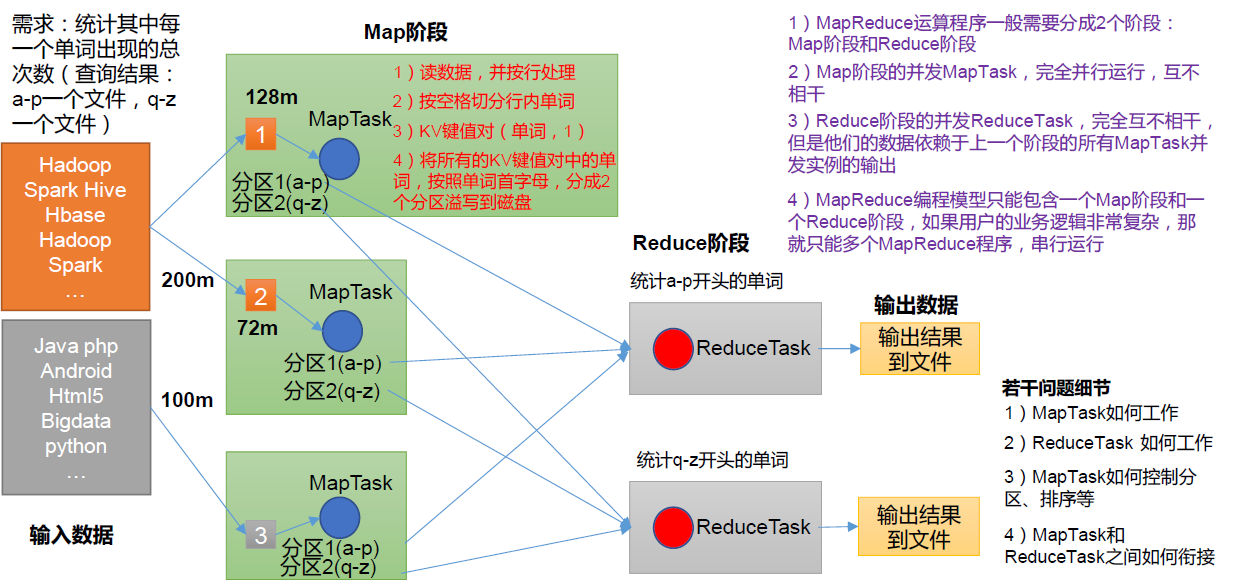
(1)分布式的運算程序往往需要分成至少2 個階段。
(2)第一個階段的MapTask 并發實例,完全并行運行,互不相干。
(3)第二個階段的ReduceTask 并發實例互不相干,但是他們的數據依賴于上一個階段的所有MapTask 并發實例的輸出。
(4)MapReduce 編程模型只能包含一個Map 階段和一個Reduce 階段,如果用戶的業
務邏輯非常復雜,那就只能多個MapReduce 程序,串行運行。
1.4?MapReduce 進程
一個完整的MapReduce 程序在分布式運行時有三類實例進程:
(1)MrAppMaster:負責整個程序的過程調度及狀態協調。
(2)MapTask:負責Map 階段的整個數據處理流程。
(3)ReduceTask:負責Reduce 階段的整個數據處理流程。
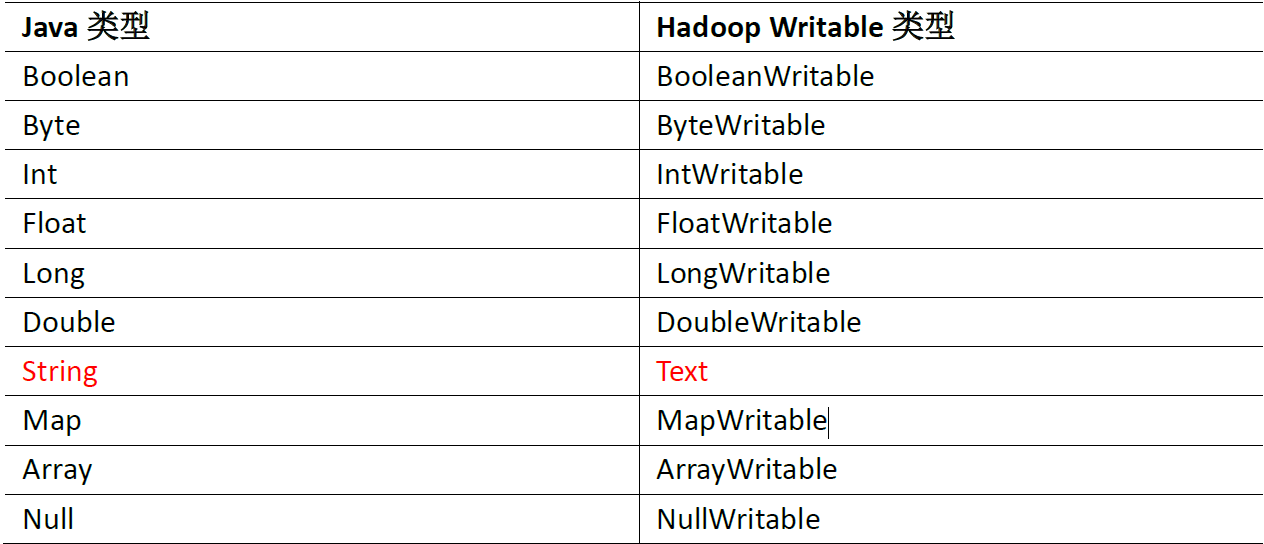
1.5?常用數據序列化類型
1.6?MapReduce 編程規范
用戶編寫的程序分成三個部分:Mapper、Reducer 和Driver。
1.Mapper階段
(1)用戶自定義的Mapper要繼承自己的父類
(2)Mapper的輸入數據是KV對的形式(KV的類型可自定義)
(3)Mapper中的業務邏輯寫在map()方法中
(4)Mapper的輸出數據是KV對的形式(KV的類型可自定義)
(5)map()方法(MapTask進程)對每一個<K,V>調用一次
2.Reducer階段
(1)用戶自定義的Reducer要繼承自己的父類
(2)Reducer的輸入數據類型對應Mapper的輸出數據類型,也是KV
(3)Reducer的業務邏輯寫在reduce()方法中
(4)ReduceTask進程對每一組相同k的<k,v>組調用一次reduce()方法
3.Driver階段
相當于YARN集群的客戶端,用于提交我們整個程序到YARN集群,提交的是封裝了MapReduce程序相關運行參數的job對象
二、WordCound 案例
需求分析:在給定的文本文件中統計輸出每一個單詞出現的總次數。按照MapReduce 編程規范,分別編寫Mapper,Reducer,Driver。

2.1 環境準備
第一步:創建maven 工程,MapReduceDemo
第二步:在pom.xml 文件中添加如下依賴
<dependencies><dependency><groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency><groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency><groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>第三步:在項目的src/main/resources 目錄下,新建一個文件,命名為“log4j.properties”,在
文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n2.2?編寫程序
第一步:編寫 Mapper類
public class Word C ountMapper extends Mapper < LongWritable, Text, Text,IntWritable > {Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException,InterruptedException {// 1 獲取一行String line = value.toString();// 2 切割String[] words = line.spli t(" ");// 3 輸出for (String word: words) {k.set(word);context.write(k, v);}}}第二步:編寫 Reducer類
public class WordCountReducer extends Reducer < Text, IntWritable, Text,IntWritable > {int sum;IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable < IntWritable > values, Context context) throws IOException,InterruptedException {// 1 累加求和sum = 0;for (IntWritable count: values) {sum += count.get();// 2 輸出v.set(sum);context.write(key, v);}}第三步:編寫 Driver驅動類
public static void main(String[] args) throws I OException,ClassNotFoundException, InterruptedException {// 1 獲取配置信息以及 獲取 job 對象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 關聯本 Driver 程序的 jarjob.setJarByClass(Word C ountDriver.class);// 3 關聯 Mapper 和 Reducer 的 jarjob.setMapperClass(Word C ountMapper.class);job.setReducerClass(Word C ountReducer.class);// 4 設置 Mapper 輸出的 kv 類型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 設置最終輸出 kv 類型job.setOutputKeyCl ass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 設置輸入和輸出路徑FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交 jobboolean result = job.waitForCompletion(tru e);System.exit(result ? 0 : 1);}
}三、MapReduce?工作流程
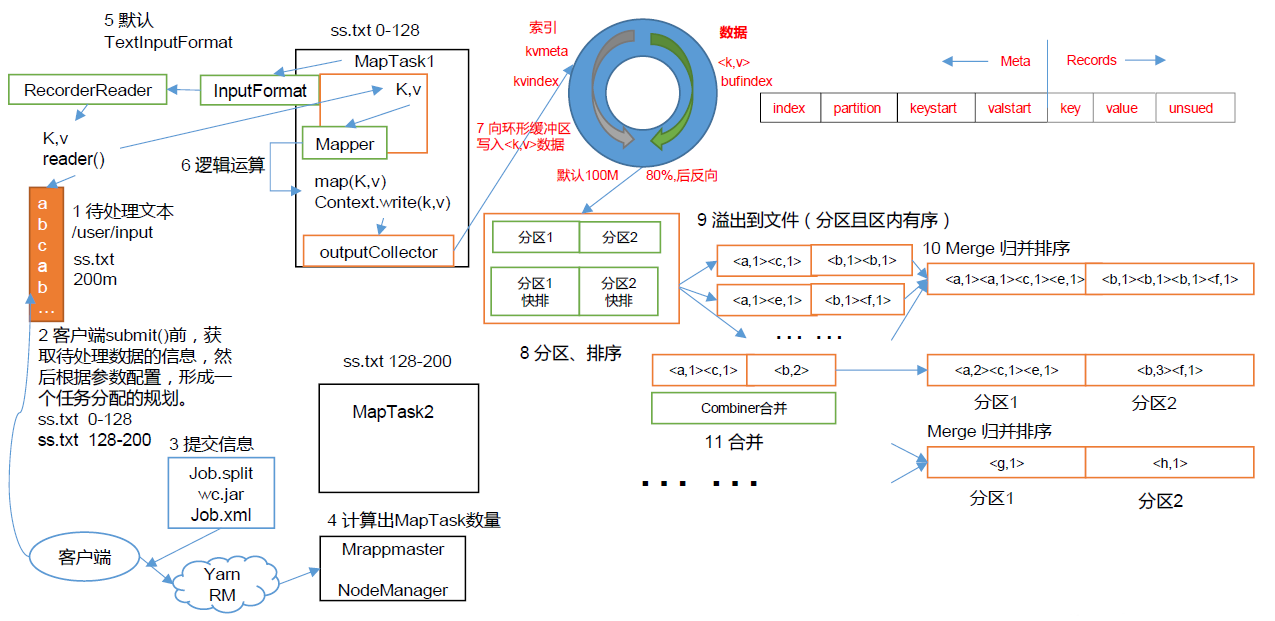
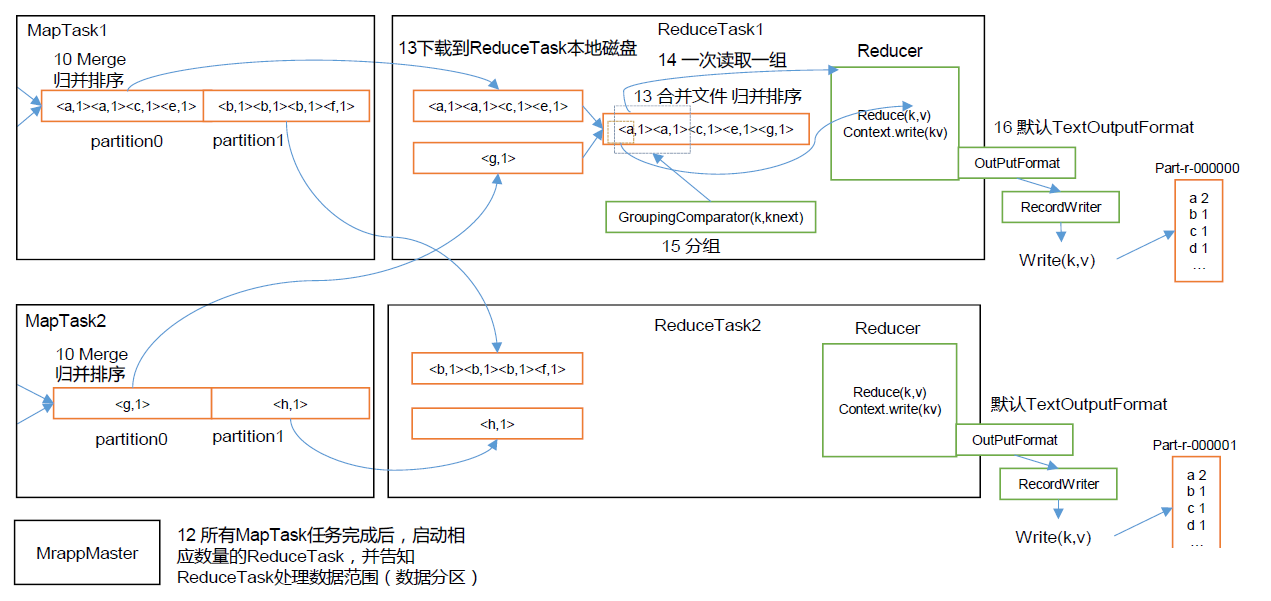
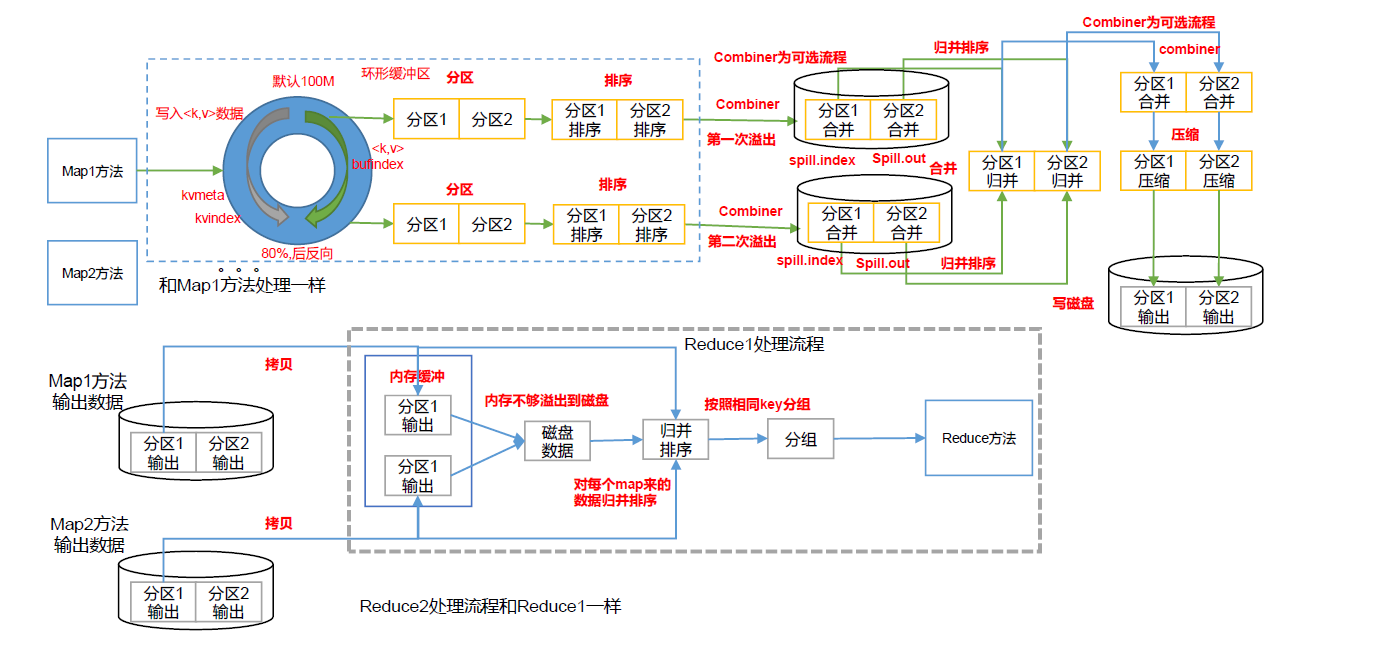
(1)MapTask 收集我們的map()方法輸出的kv 對,放到內存緩沖區中
(2)從內存緩沖區不斷溢出本地磁盤文件,可能會溢出多個文件
(3)多個溢出文件會被合并成大的溢出文件
(4)在溢出過程及合并的過程中,都要調用Partitioner 進行分區和針對key 進行排序
(5)ReduceTask 根據自己的分區號,去各個MapTask 機器上取相應的結果分區數據
(6)ReduceTask 會抓取到同一個分區的來自不同MapTask 的結果文件,ReduceTask 會將這些文件再進行合并(歸并排序)
(7)合并成大文件后,Shuffle 的過程也就結束了,后面進入ReduceTask 的邏輯運算過程(從文件中取出一個一個的鍵值對Group,調用用戶自定義的reduce()方法)
Shuffle 機制:Map 方法之后,Reduce 方法之前的數據處理過程稱之為Shuffle。


安裝教程詳解:第二篇)


![[原創]X86C++反匯編01.IDA和提取簽名](http://pic.xiahunao.cn/[原創]X86C++反匯編01.IDA和提取簽名)

三種算法逐個擊破)











