有五種通用技術用于限制數據的掃描量,正如圖3 - 4所示。第一種技術是掃描那些被打上時戳的數據。當一個應用對記錄的最近一次變化或更改打上時戳時,數據倉庫掃描就能夠很有效地進行,因為日期不相符的數據就接觸不到了。然而,目前的數據被打上時戳的很少。
數據倉庫抽取中限制數據掃描量的第二種技術是掃描增量文件。增量文件由應用程序生成,僅僅記錄應用中所發生的改變。有了增量文件,掃描的過程就會變得高效,因為不在候選掃描集中的數據永遠不會涉及到。但是,許多應用程序并沒有創建增量文件。
第三種技術是掃描審計文件或日志文件。審計文件或日志文件記錄的內容,本質上同增量文件一樣。不過,這里還是有一些重要的區別。由于恢復過程需要日志文件,所以各種操作都要保護日志文件。把日志文件用于其他目的,對計算機的操作也無大礙。利用日志文件的另一個困難是它內部格式是針對系統的用途而構造的,而不是針對應用程序的。這就需要一種技術手段作為日志文件內容的接口。日志文件的另一個缺點是其中所包含的內容超出了據倉庫開發人員所需要的。審計文件有許多與日志文件相同的缺點。
當數據倉庫抽取數據時,控制掃描數據量的第四種技術是修改應用程序代碼。這并不常用,因為很多應用程序的代碼陳舊而且不易修改。
最后一個選擇(很多情況下,是一個可怕的選擇,其目的是使人們相信一定有更好的辦法)是將一個“前”映象文件和一個“后”映象文件進行比較。使用這種方法,一開始抽取就對數據庫進行快照( s n a p s h o t )。進行另一個抽取時,就進行另一個快照。這兩個快照逐次比較,以確定哪個活動發生了。這種方法很麻煩、復雜,還需要各種各樣的資源。這只不過是最后的手段。但是,集成和性能并不是僅有的兩個使得簡單的抽取過程無法用于構造數據倉庫的主要問題。
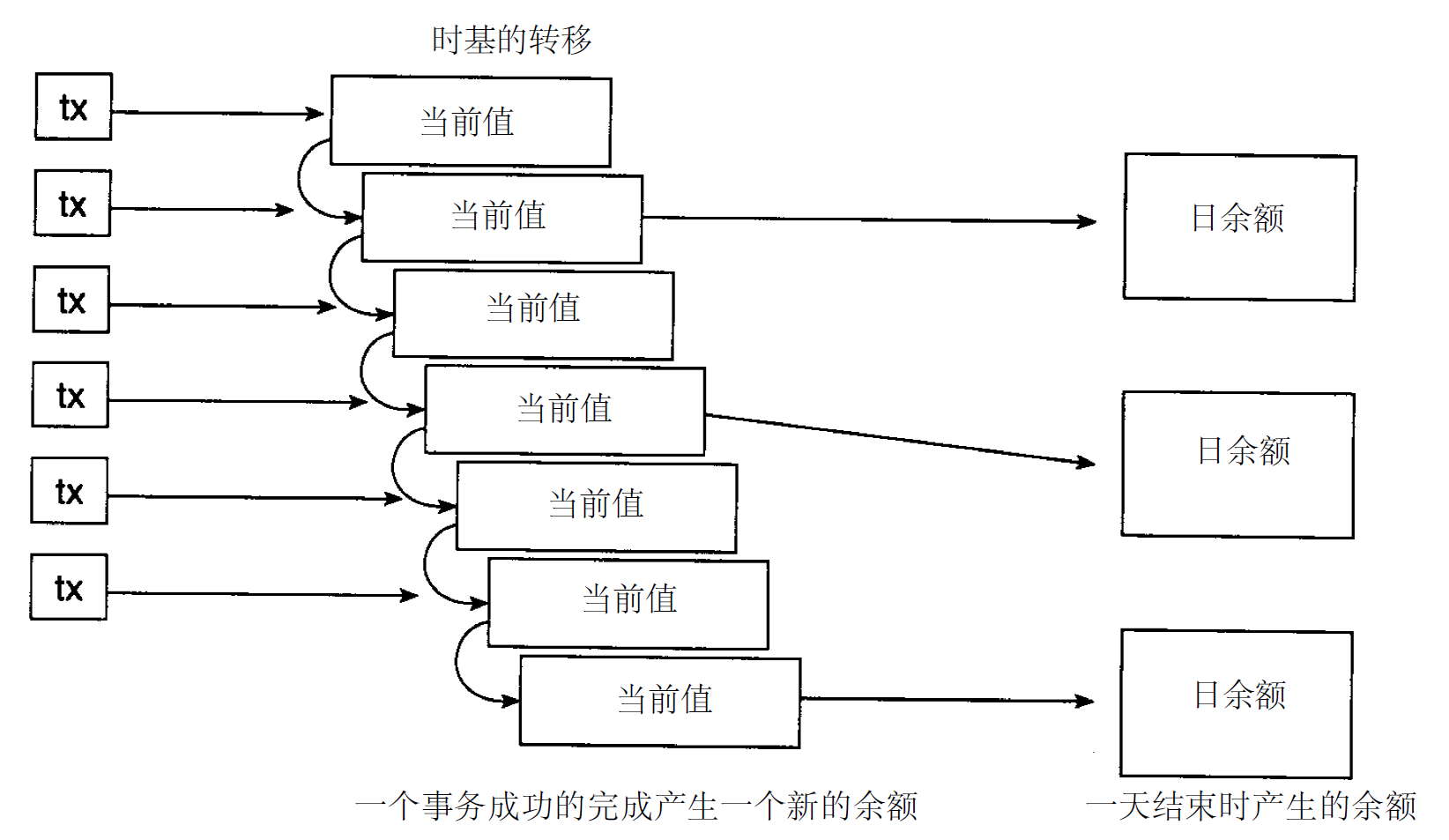
第三個主要困難是時基變化,如圖3 - 5所示。現存的操作型數據通常是當值數據。當前值數據在被訪問的時刻其精度是有效的,而且是可更新的。但是數據倉庫中的數據是不能更新的。這些數據必須附有時間元素。當數據從操作型系統傳送到數據倉庫時,必需在數據中進行較大范圍的改變。
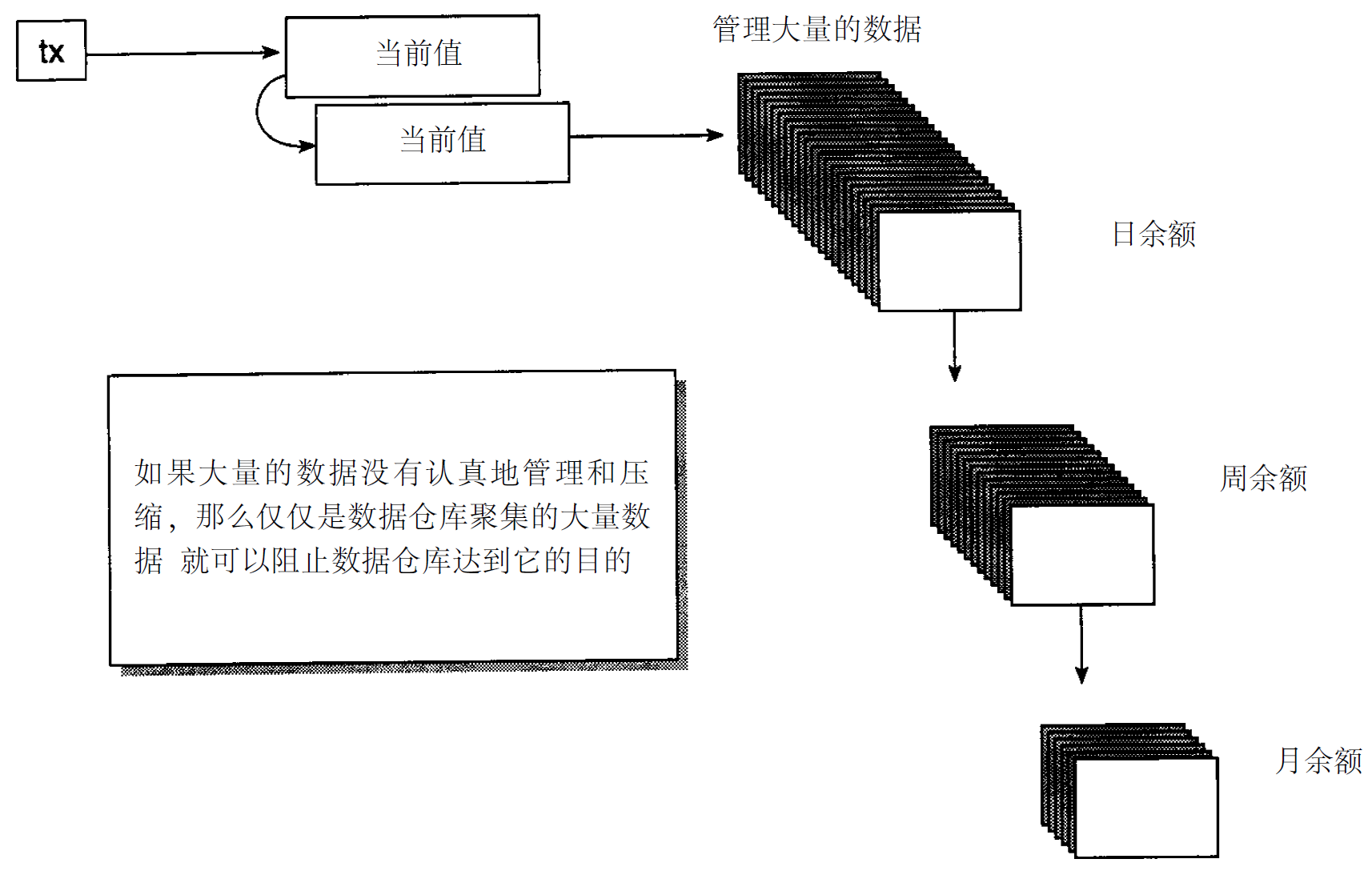
當數據從現存操作型環境傳送到數據倉庫時,要考慮的另一個問題是需要對數據的量進行管理。數據要濃縮,否則數據倉庫的數據量很快就會失控。在數據抽取一開始就要進行數據濃縮。圖3 - 6表示數據倉庫數據濃縮的一個簡單形式。
?




)
“ 報 errCode: 10008 的解決方案)




)








