機器學習概述
- 機器學習與人工智能、深度學習關系
- 什么是機器學習
- 數據集
- 算法
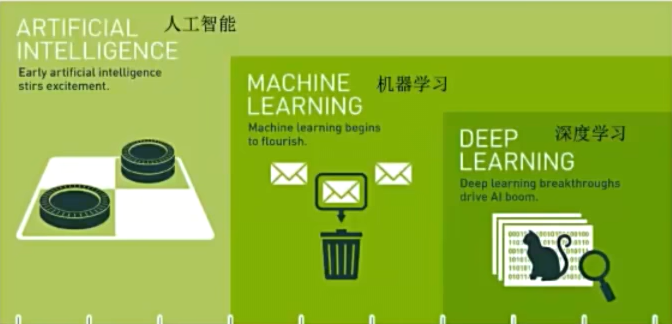
機器學習與人工智能、深度學習關系
什么是機器學習
機器學習是從數據中自動分析獲取模型,并利用模型對未知數據進行預測。
直觀理解:
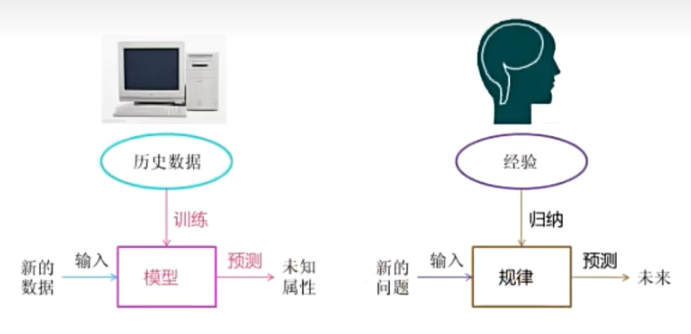
所以是從歷史數據中獲取規律,那么這些歷史數據是怎么構成的呢?
數據集
結構:特征值+目標值
正式定義:
特征值與目標值
特征值(Features):
描述數據的屬性(通常是多列),用X表示。
例如:房價預測中的面積、地段、房齡。
目標值(Target):
模型要預測的結果(通常是單列),用y表示。
例如:最終的房價。
case:用“相親”比喻機器學習
假設你是一個相親網站的AI,任務是預測兩個人是否適合結婚。你需要收集數據并讓模型學習規律:
特征值(Features):
就是模型的“輸入線索”,比如:
年齡、身高、收入、興趣愛好、學歷
相當于你作為媒人時,會問對方的“條件”。
目標值(Target):
是模型要“猜”的結果,比如:
是否成功結婚(是/否)
相當于你最終看到的“相親結果”。
算法
一、監督學習(Supervised Learning)
核心思想:像老師教學生,給算法“標準答案”(即目標值y)去學習規律。
- 典型案例:
分類問題 → 預測類別
例:垃圾郵件識別(是/否)、癌癥診斷(惡性/良性)
回歸問題 → 預測數值
例:房價預測、股票價格
- 常用算法:
算法名稱 比喻 適用場景
線性回歸 用尺子畫最擬合的直線 房價趨勢預測
決策樹 連環問答式判斷 貸款審批
隨機森林 多個專家投票決策 電商用戶流失預警
SVM(支持向量機) 找最大間隔的分界線 圖像分類 - 關鍵特點:
必須有已標注的數據(即既有X也有y)
模型訓練后可以預測新數據的y值
二、無監督學習(Unsupervised Learning)
核心思想:像讓孩子自己整理玩具,沒有標準答案,算法自行發現數據中的模式。
- 典型案例:
-
聚類(Clustering) → 自動分組
例:用戶分群、新聞話題歸類 -
降維(Dimensionality Reduction) → 壓縮數據
例:3D數據可視化展示到2D
- 常用算法:
算法名稱 比喻 適用場景
K-Means 按距離劃分小組 市場客戶細分
PCA 提取最關鍵特征 人臉識別預處理
Apriori 找頻繁出現的組合 超市商品關聯推薦 - 關鍵特點:
只有特征值X,沒有目標值y
結果通常需要人工解讀意義
三、強化學習(Reinforcement Learning)
核心思想:像訓練小狗,通過“獎勵/懲罰”讓算法自己摸索最佳策略。
- 典型案例:
游戲AI(如AlphaGo)
自動駕駛決策
機器人控制
- 核心概念:
Agent(智能體):學習的AI
Environment(環境):交互的世界
Reward(獎勵):行為的反饋信號
四、算法選擇流程圖
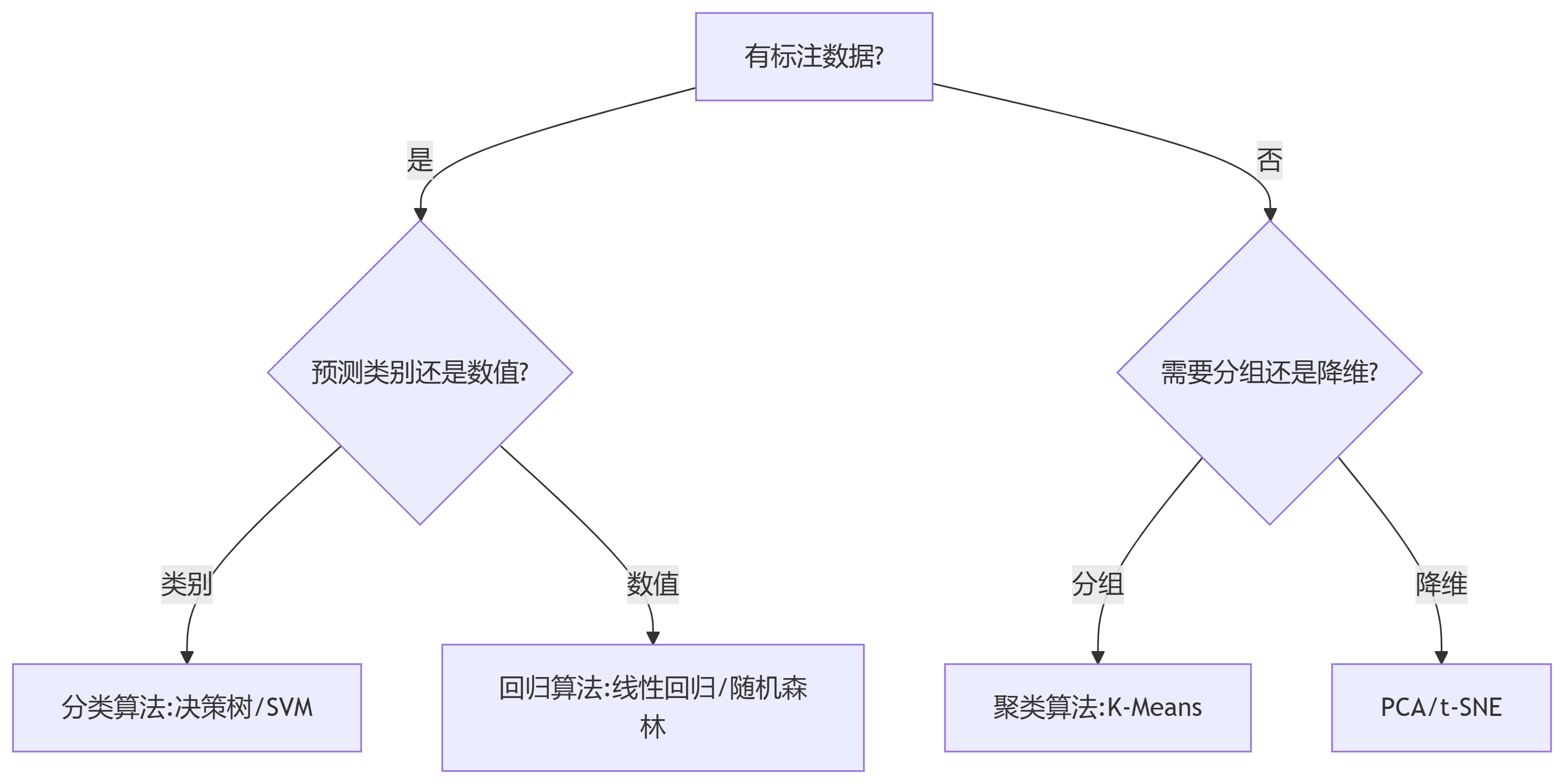


)
“ 報 errCode: 10008 的解決方案)




)









)
)