注:本文為“CUDA 性能優化”相關文章合輯。
圖片清晰度受引文原圖所限。
重傳部分 CSDN 轉儲失敗圖片。
略作重排,未整理去重。
如有內容異常,請看原文。
Shared Memory 上的廣播機制和 Bank Conflict 到底是怎么回事?
發表于 2023 年 12 月 26 日
- 🔥2024.03.24 添加了關于對 128 Bit 下的 Bank Conflict 的討論
- 🔥2024.04.01 修正了 128 Bit 下第五個例子的錯誤代碼,感謝知乎用戶 @Alan小分享 . 指證~
NVIDIA GPU 上的內存結構從慢到快分為 Global Memory、L2 緩存、L1TEX 緩存/Shared Memory 和寄存器,從 Volta/Turning 開始其中 L1TEX 緩存和 Shared Memory 在物理上放在了同一塊芯片上,擁有相似的延時和帶寬[1],因此如何掌握 Shared Memory 對性能而言就變得尤為重要。可惜的是,NVIDIA 官方的 CUDA 編程手冊中介紹 Shared Memory 的教程其實只介紹了在每個線程訪問一個 4 字節(32 位寬)的元素時 Bank Conflict 和廣播機制,但對使用常用的向量化訪存指令如 LDS.64 或 LDS.128 這種一次能訪問 8 個字節(64 位寬)或 16 個字節(128 位寬)元素的情況卻鮮有資料討論。這篇文章大概就是想結合網絡上的一些討論以及通過 Microbenchmark 對這些細節來一探究竟。需要注意的是這篇文章的結論僅在 Turing 架構的 GPU 上驗證過,其他架構的 GPU 可能會產生變化(歡迎評論區交流)。
Shared Memory 模型
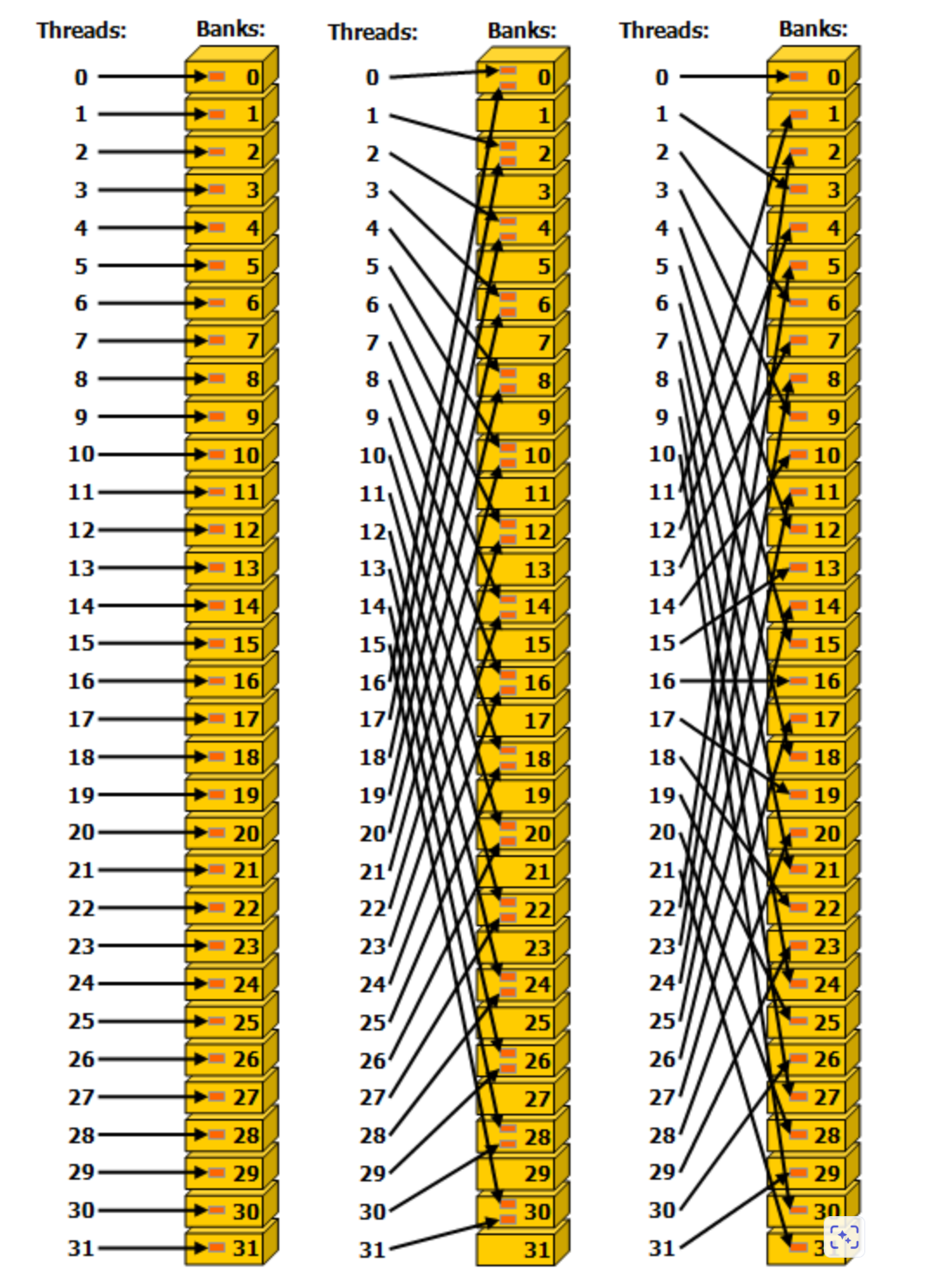
我們可以把 Shared Memory 它看作是一個長度為 NN 的數組,每個數組元素的大小是 4 字節(比如可以是一個 int 或 float),這個數組對于同一個 Thread Block 中的所有線程都是可見的,但不同 Thread Block 之間的 Shared Memory 不能互相訪問。其中 Shared Memory 最值得注意的點機制是其本身被劃分稱了 32 個 Bank,其中數組中第 ii 個元素存儲在了第 i \bmod 32imod32 個 Bank 上。Shared Memory 訪存機制可以總結為如下兩條:
- 如果一個 Warp 中的兩個不同的線程同時訪問了同一個元素,那么就會觸發廣播機制,即可以合并成對 Shared Memory 的一次訪問;
- 如果一個 Warp 中兩個不同的線程同時訪問了同一個 Bank 中的不同元素,那么就會產生Bank Conflict,可以理解成一個 Bank 同一時間只能產生吞吐一個元素,因此這兩個線程的訪存請求會被串行,因而會影響性能;
在 Nsight Compute 上,我們可以通過 Shared Memory 上的 Wavefront 數目來理解 Shared Memory 訪存性能,Wavefront 越多說明訪存需要的時間越長。
下面幾張圖片舉了幾個例子方便理解:
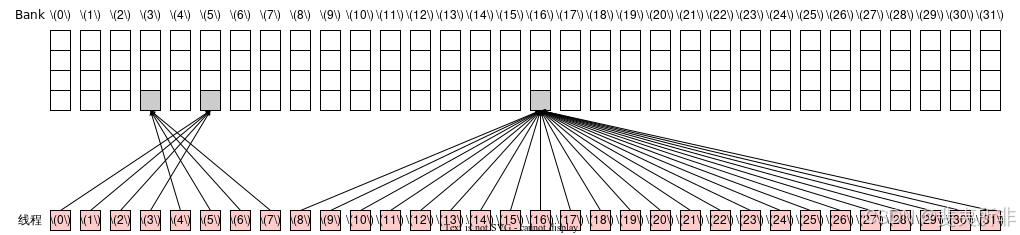
只會觸發廣播機制,沒有 Bank Conflict,需要 1 個 Wavefront
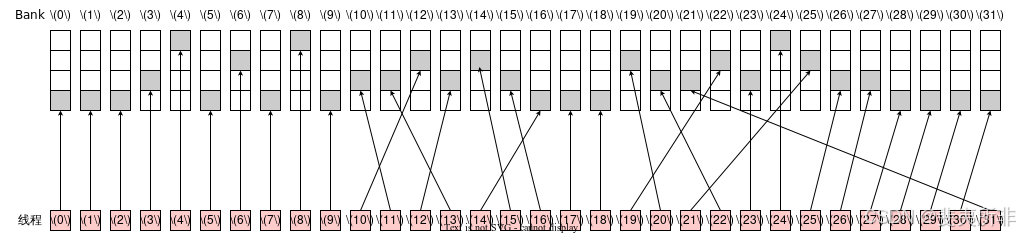
不會觸發廣播機制,沒有 Bank Conflict,需要 1 個 Wavefront
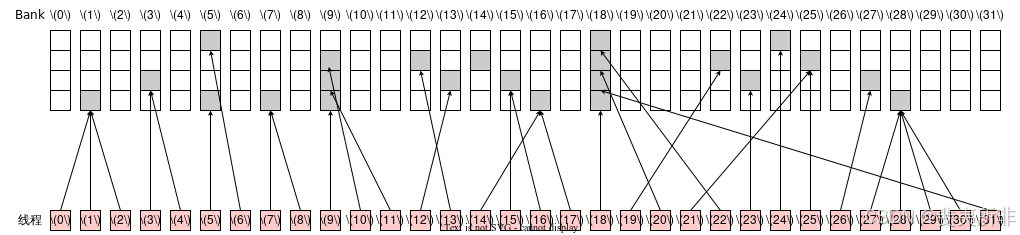
既會觸發廣播機制,也有 Bank Conflict,需要 4 個 Wavefront(注意第 18 個 Bank)
向量化訪存指令
前面在討論 Shared Memory 上的訪存時,我們的 Shared Memory 模型只討論了一個 Warp 內每個線程所訪問的元素。在涉及到向量化訪存時這樣的模型就不起效果了,因為通過一個 LDS.64 或 LDS.128 指令就可以讓一個線程一次性訪問 8 個或 16 個字節(相當于 2 個或 4 個元素)。
正確的做法應該是就每個 Wrap 內所產生的每個 Memory Transaction而非每個 Warp 或每條指令來討論(參考這里)。那么一個在 Shared Memory 上的向量化指令 LDS.64 或 LDS.128 指令到底對應多少個 Memory Transaction?我并沒有找到 NVIDIA 給出的官方答案,通過一些網絡上的討論和我自己的 Microbenchmark,我對結合了向量化指令的 Shared Memory 的訪存機制的推測如下。
首先一個原則是一個 Warp 中所有線程在同時執行一條 Shared Memory 訪存指令時會對應到 1 個或多個 Memory Transaction,一個 Memory Transaction 最長是 128 字節。如果一個 Warp 內在同一時刻所需要的訪存超過了 128 字節,那么會則被拆成多個 Transaction 進行。因為一個 Warp 同一時刻執行的訪存指令的位寬應該是一樣的(即例如不存在線程 0 執行 LDS.32 而線程 1 執行 LDS.128),因此我們只需要對 64 位寬和 128 位寬的訪存指令分別討論即可。
64 位寬的訪存指令
對于 64 位寬的訪存指令而言,除非觸發廣播機制,否則一個 Warp 中有多少個活躍的 Half-Warp 就需要多少個 Memory Transaction,一個 Half-Warp 活躍的定義是這個 Half-Warp 內有任意一個線程活躍。觸發廣播機制只需滿足以下條件中的至少一個:
- 對于 Warp 內所有活躍的第 ii 號線程,第 i\mathrm{xor}1i xor 1 號線程不活躍或者訪存地址和其一致;
- 對于 Warp 內所有活躍的第 ii 號線程,第 i\mathrm{xor}2i xor 2 號線程不活躍或者訪存地址和其一致;
如果觸發了廣播機制,那么兩個 Half-Warp 內的 Memory Transaction 可以合并成一個。
我們看幾個例子:
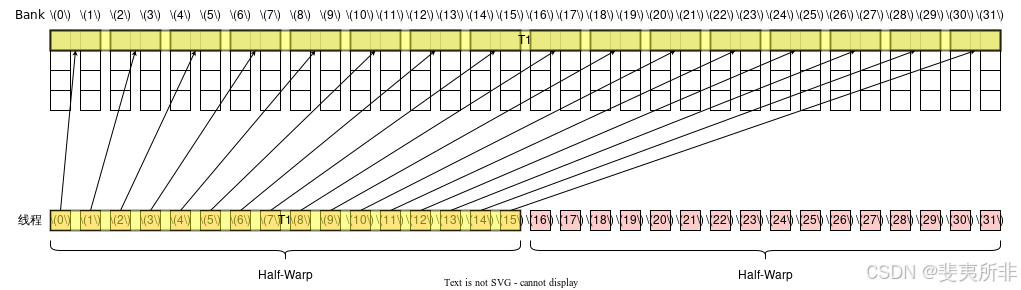
Case 1: 活躍線程全部在第 1 個 Half-Warp 內,需要 1 個 Memory Transaction,沒有 Bank Conflict,需要 1 個 Wavefront
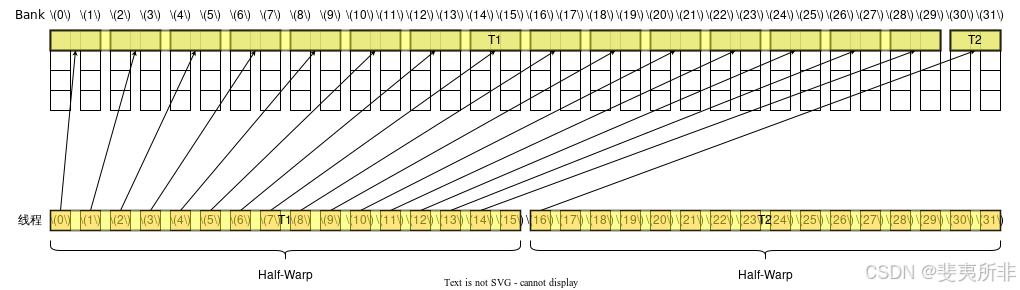
Case 2: 活躍線程分散在了 2 個 Half-Warp 內,需要 2 個 Memory Transaction,沒有 Bank Conflict,需要 2 個 Wavefront(注意第 15 號和第 16 號線程)
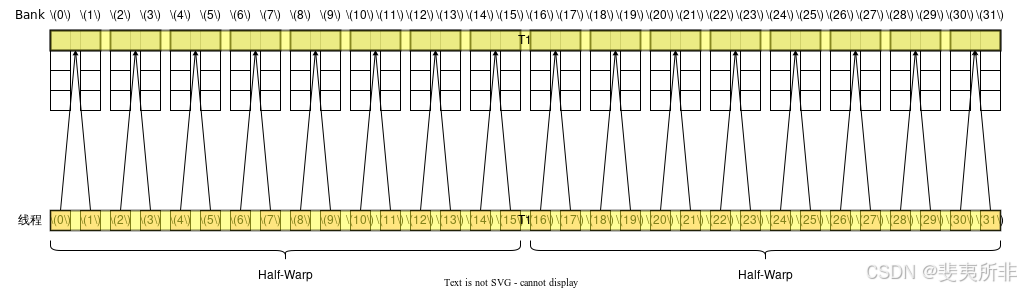
Case 3: 活躍線程分散在了 2 個 Half-Warp 內,但因為觸發了廣播機制中的第一條,因此仍然只需要 1 個 Memory Transaction,沒有 Bank Conflict,需要 1 個 Wavefront
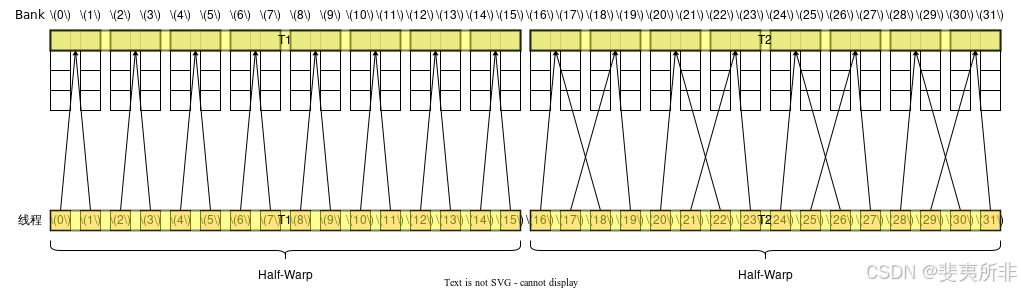
Case 4: 活躍線程分散在了 2 個 Half-Warp 內,看似好像觸發了廣播機制,但其實并沒有,因為第一個 Half-Warp 觸發的是第一條,第二個 Half-Warp 觸發的是第二條,因此仍然需要 2 個 Memory Transaction,沒有 Bank Conflict,需要 2 個 Wavefront
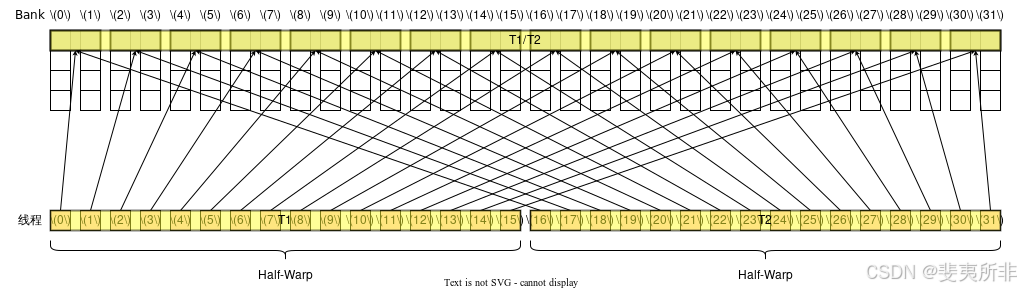
Case 5: 活躍線程分散在了 2 個 Half-Warp 內,沒有觸發廣播機制,需要 2 個 Memory Transaction,沒有 Bank Conflict,需要 2 個 Wavefront
可以通過 Nsight Compute 跑一跑下面的代碼并觀察和 Shared Memory 的相關 Metric 來驗證上面這五個例子:
smem_64bit.cu
#include <cstdint>__global__ void smem_1(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();if (tid < 16) {reinterpret_cast<uint2 *>(a)[tid] =reinterpret_cast<const uint2 *>(smem)[tid];}
}__global__ void smem_2(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();if (tid < 15 || tid == 16) {reinterpret_cast<uint2 *>(a)[tid] =reinterpret_cast<const uint2 *>(smem)[tid == 16 ? 15 : tid];}
}__global__ void smem_3(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();reinterpret_cast<uint2 *>(a)[tid] =reinterpret_cast<const uint2 *>(smem)[tid / 2];
}__global__ void smem_4(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();uint32_t addr;if (tid < 16) {addr = tid / 2;} else {addr = (tid / 4) * 4 + (tid % 4) % 2;}reinterpret_cast<uint2 *>(a)[tid] =reinterpret_cast<const uint2 *>(smem)[addr];
}__global__ void smem_5(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();reinterpret_cast<uint2 *>(a)[tid] =reinterpret_cast<const uint2 *>(smem)[tid % 16];
}int main() {uint32_t *d_a;cudaMalloc(&d_a, sizeof(uint32_t) * 128);smem_1<<<1, 32>>>(d_a);smem_2<<<1, 32>>>(d_a);smem_3<<<1, 32>>>(d_a);smem_4<<<1, 32>>>(d_a);smem_5<<<1, 32>>>(d_a);cudaFree(d_a);cudaDeviceSynchronize();return 0;
}
上面的例子中并沒有列舉出有 Bank Conflict 的情況,那么 Bank Conflict 在這種情況下應該如何考慮呢?正如前面提到的那樣,我們只需要計算每個 Memory Transaction 中的 Bank Conflict 數目然后加起來就好了(因為 Memory Transaction 是串行的)。
128 位寬的訪存指令
128 位寬的訪存指令和 64 位寬的訪存指令是類似的,不同的是需要以 Half-Warp 為單位來計算,對于每個 Half-Warp 而言,除非觸發廣播機制,這個 Half-Warp 中有多少個活躍的 Quarter-Warp 就需要多少個 Memory Transaction,一個 Quarter-Warp 活躍的定義是這個 Quarter-Warp 內有任意一個線程活躍。類似地,如果觸發廣播機制那么兩個 Quarter-Warp 中的 Transaction 就可以被合并成一個。 觸發廣播機制的條件和 64 位寬的訪存指令是一樣的(注意廣播機制是以整個 Warp 為單位考慮)。這也就意味著假設一個 Warp 中 32 個線程都活躍,即使它們的訪存地址都一樣,也需要 2 個 Memory Transaction。
同樣來看幾個例子:
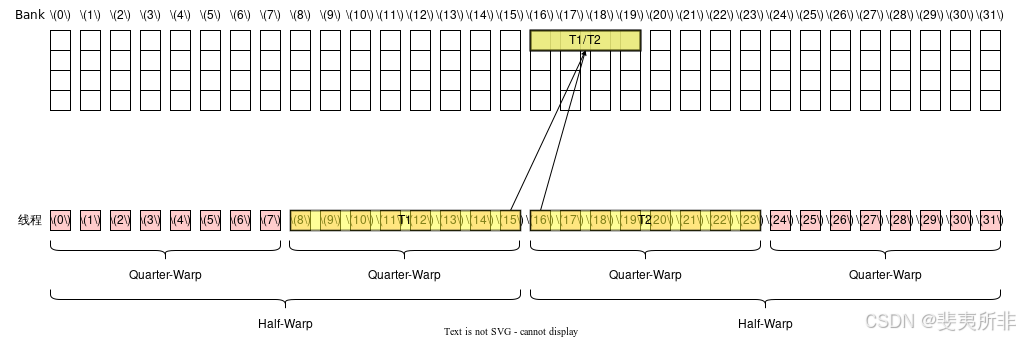
Case 1: 活躍線程分散在了 2 個 Half-Warp 和 2 個 Quarter-Warp 內,每個 Half-Warp 需要 1 個 Memory Transaction,總共需要 2 個 Memory Transaction,沒有 Bank Conflict,需要 2 個 Wavefront
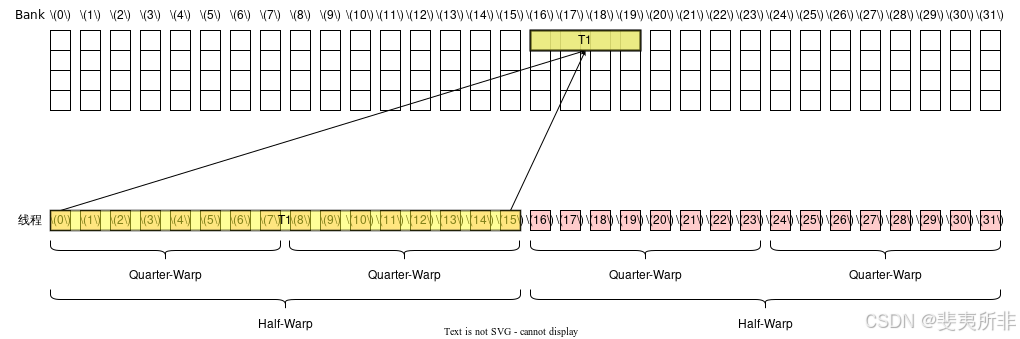
Case 2: 活躍線程分散在了 1 個 Half-Warp 和 2 個 Quarter-Warp 內,需要 1 個 Memory Transaction,沒有 Bank Conflict,需要 1 個 Wavefront
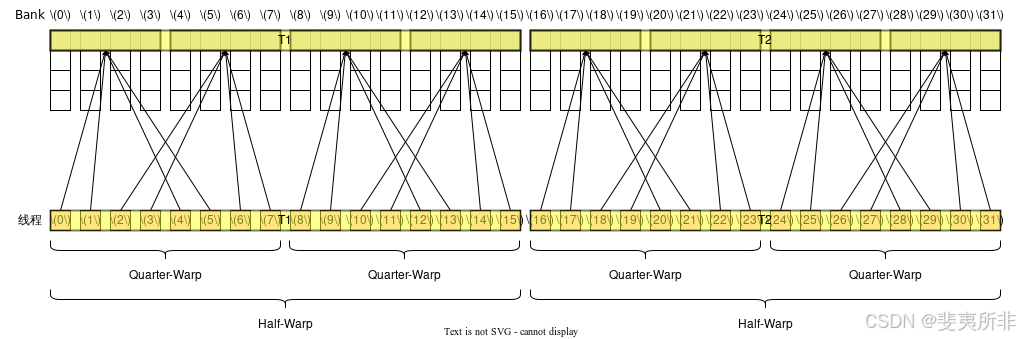
Case 3: 活躍線程分散在了 2 個 Half-Warp 和 4 個 Quarter-Warp 內,但觸發了廣播機制(第一條),每個 Half-Warp 需要 1 個 Memory Transaction,總共需要 2 個 Memory Transaction,沒有 Bank Conflict,需要 2 個 Wavefront
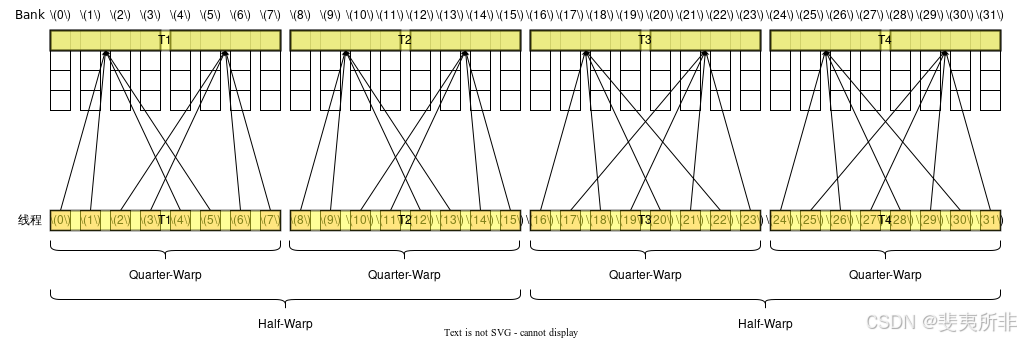
Case 4: 活躍線程分散在了 2 個 Half-Warp 和 4 個 Quarter-Warp 內,沒有觸發廣播機制,每個 Half-Warp 需要 2 個 Memory Transaction,總共需要 4 個 Memory Transaction,沒有 Bank Conflict,需要 4 個 Wavefront
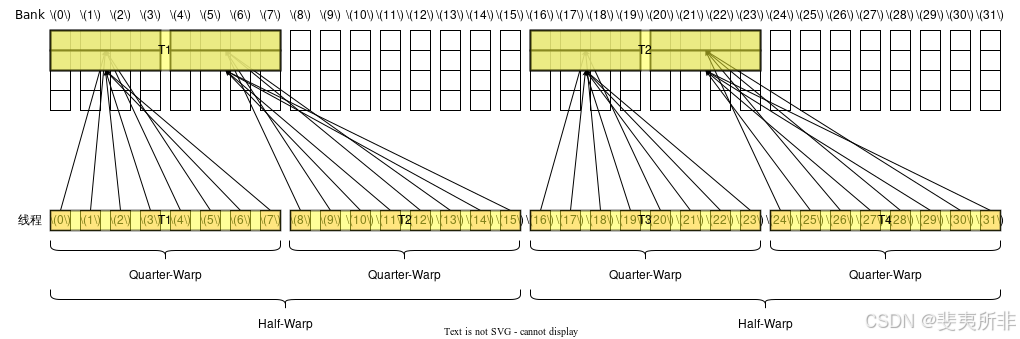
Case 5: 活躍線程分散在了 2 個 Half-Warp 和 4 個 Quarter-Warp 內,但觸發了廣播機制(第一條和第二條),每個 Half-Warp 需要 1 個 Memory Transaction,總共需要 2 個 Memory Transaction,但因為每個 Memory Transaction 中有 1 個 Bank Conflict,因此會拆分成 4 個 Memory Transaction,對應需要 4 個 Wavefront
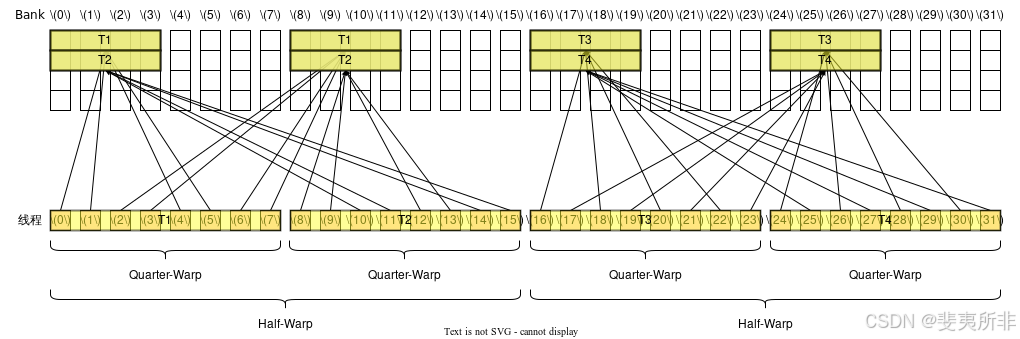
Case 6: 活躍線程分散在了 2 個 Half-Warp 和 4 個 Quarter-Warp 內,沒有觸發廣播機制,每個 Half-Warp 需要 2 個 Memory Transaction,總共需要 4 個 Memory Transaction,沒有 Bank Conflict,需要 4 個 Wavefront
同樣可以通過 Nsight Compute 跑一跑下面的代碼并觀察和 Shared Memory 的相關 Metric 來驗證上面這幾個例子:
smem_128bit.cu
#include <cstdint>__global__ void smem_1(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();if (tid == 15 || tid == 16) {reinterpret_cast<uint4 *>(a)[tid] =reinterpret_cast<const uint4 *>(smem)[4];}
}__global__ void smem_2(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();if (tid == 0 || tid == 15) {reinterpret_cast<uint4 *>(a)[tid] =reinterpret_cast<const uint4 *>(smem)[4];}
}__global__ void smem_3(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();reinterpret_cast<uint4 *>(a)[tid] = reinterpret_cast<const uint4 *>(smem)[(tid / 8) * 2 + ((tid % 8) / 2) % 2];
}__global__ void smem_4(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();uint32_t addr;if (tid < 16) {addr = (tid / 8) * 2 + ((tid % 8) / 2) % 2;} else {addr = (tid / 8) * 2 + ((tid % 8) % 2);}reinterpret_cast<uint4 *>(a)[tid] =reinterpret_cast<const uint4 *>(smem)[addr];
}__global__ void smem_5(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();reinterpret_cast<uint4 *>(a)[tid] =reinterpret_cast<const uint4 *>(smem)[(tid / 16) * 4 + (tid % 16) / 8 + (tid % 8) / 4 * 8];
}__global__ void smem_6(uint32_t *a) {__shared__ uint32_t smem[128];uint32_t tid = threadIdx.x;for (int i = 0; i < 4; i++) {smem[i * 32 + tid] = tid;}__syncthreads();uint32_t addr = (tid / 16) * 4 + (tid % 16 / 8) * 8;if (tid < 16) {addr += (tid % 4 / 2) * 2;} else {addr += (tid % 4 % 2) * 2;}reinterpret_cast<uint4 *>(a)[tid] =reinterpret_cast<const uint4 *>(smem)[addr];
}int main() {uint32_t *d_a;cudaMalloc(&d_a, sizeof(uint32_t) * 128);smem_1<<<1, 32>>>(d_a);smem_2<<<1, 32>>>(d_a);smem_3<<<1, 32>>>(d_a);smem_4<<<1, 32>>>(d_a);smem_5<<<1, 32>>>(d_a);smem_6<<<1, 32>>>(d_a);cudaFree(d_a);cudaDeviceSynchronize();return 0;
}
總結
可以看到實際上 32 位寬的訪存指令和 64/128 位寬的訪存指令的廣播機制以及 Bank Conflict 的計算都有很大的不同,但是官方文檔中沒有出現相關的描述(或者我沒看到😵?💫)。這篇文章通過 Microbenchmark 以及前人的一些討論總結了幾套規則,但需要注意的是這些規則有一定的局限性,其一是我只評測了以上圖片中的例子,因此是不清楚更加復雜的訪存情況是不是仍然符合這些規則的,其二是這些規則不是官方記錄的,因此很有可能在將來被新發布的 GPU 架構所改寫。
參考
-
How to understand the bank conflict of shared_mem
-
Unexpected shared memory bank conflict
-
Volta GPU 白皮書
-
Turing GPU 白皮書
-
volta-architecture-whitepaper.pdf
-
NVIDIA-Turing-Architecture-Whitepaper.pdf
本文允許以 CC BY-NC-SA 4.0 的方式授權轉載,背景圖片來源于 KARL EGGER
最后更新于 2024 年 4 月 1 日 22 時 58 分
CUDA 程序優化
1. 基礎介紹
簡介
本合集主要介紹我在開發分布式異構訓練框架時的 CUDA 編程實踐和性能優化的相關內容。主要包含以下幾個部分:
- 介紹 CUDA 的基本概念和架構,幫助讀者建立對 CUDA 的初步認識,包括硬件架構 / CUDA 基礎等內容
- 介紹一些性能優化技巧和工具,幫助讀者優化 CUDA 程序的執行效率
- 結合具體的代碼示例來說明一個 cuda 程序的優化思路和結果,幫助讀者更好地理解和掌握 CUDA 編程和性能優化的實踐方法
希望通過本文檔,能夠幫助大家寫出更高效的 CUDA 程序。下面我們就開始吧~
硬件架構
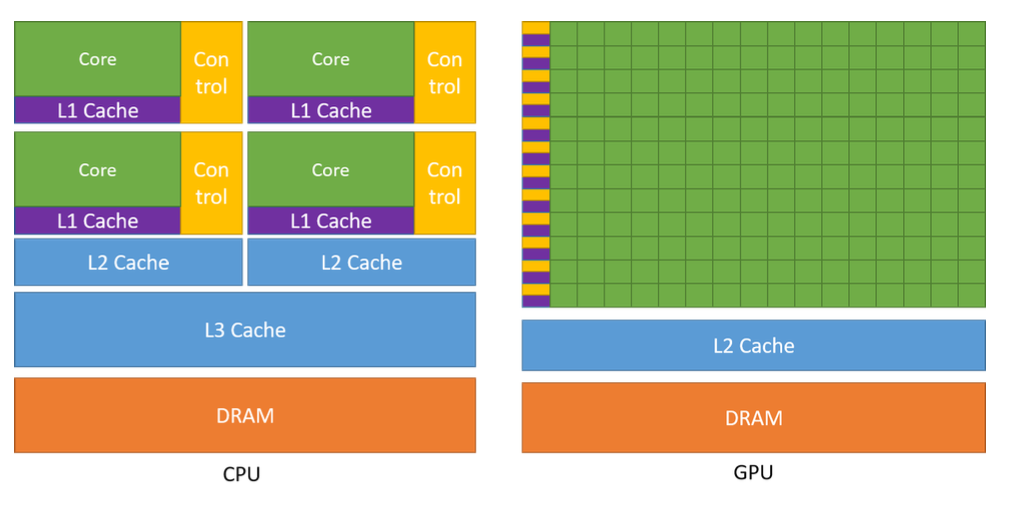
要說清楚為什么 GPU 比 CPU 更適合大規模并行計算,要從硬件層面開始說起
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240606194543448-637778562.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240606194543448-637778562.png =700x)
以當前較主流的硬件 i9-14900k 和 A100 為例:
i9-14900k: 24 核心,32 線程 (只能在 16 個能效核上進行超線程), L2: 32MB, L3: 36MB, 內存通信帶寬 89.6GB/s
A100: 108 SM, 6912 CUDA core, 192KB L1, 60MB L2, 40GB DRAM.
我個人的理解,GPU 的運算核心之所以遠多于 CPU, 是因為遠少于 CPU 的控制邏輯. GPU 每個 core 內不需要考慮線程調度的情況,不需要保證嚴格一致的運算順序,另外每個 sm 都有自己獨立的寄存器和 L1, 對線程的切換重入非常友好,所以更適合大規模數據的并行運算。而這種設計方式也會對程序員提出更高的要求,純 CPU 程序可能寫的最好的代碼和最差的情況有個 2/3 倍的性能差距就很大了,而 CUDA kernel 可能會相差幾十倍甚至幾百倍.
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240606194556694-1290930234.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240606194556694-1290930234.png =700x)
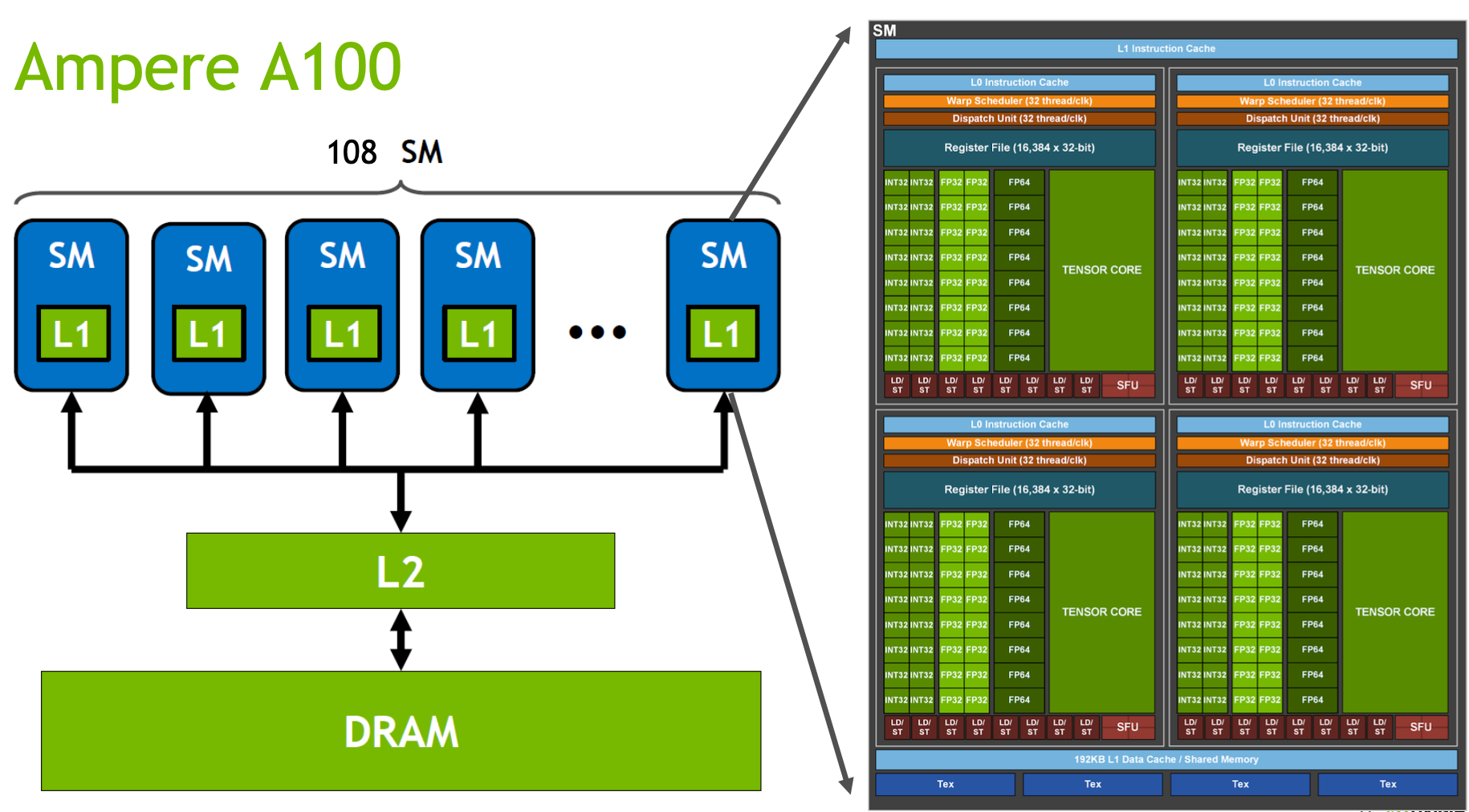
HBM(High-Bandwidth Memory) :HBM 是高帶寬內存,也就是常說的顯存,這張圖里的 DRAM。 帶寬: 1.5TB/s
L2 Cache:L2 Cache 是 GPU 中更大容量的高速緩存層,可以被多個 SM 訪問。L2 Cache 還可以用于協調 SM 之間的數據共享和通信。 帶寬: 4TB/s
SM (Streaming Multiprocessor) :GPU 的主要計算單元,負責執行并行計算任務。每個 SM 都包含多個 CUDA core,也就是 CUDA 里 Block 執行的地方,關于 block_size 如何設置可以參考 block_size 設置, 跟隨硬件不同而改變,通常為 128/256
L1 Cache/SMEM:, 也叫 shared_memory, 每個 SM 獨享一個 L1 Cache,CUDA 里常用于單個 Block 內部的臨時計算結果的存儲,比如 cub 里的 Block 系列方法就經常使用,帶寬: 19TB/s
SMP (SM partition): A100 中有 4 個。每個有自己的 warp 調度器,寄存器等.
CUDA Core: 圖里綠色的 FP32/FP64/INT32 等就是,是 thread 執行的基本單位
Tensor Core: Volta 架構之后新增的單元,主要用于矩陣運算的加速
WARP (Wavefront Parallelism) :WARP 指的是一組同時執行的 Thread,固定 32 個,不夠 32 時也會按 32 分配. warp 一個線程對內存操作后,其他 warp 內的線程是可見的.
Dispatch Unit: 從指令隊列中獲取和解碼指令,協調指令的執行和調度
Register File: 寄存器用于存儲臨時數據、計算中間結果和變量。GPU 的寄存器比 CPU 要多很多
2. cuda 基礎
cuda 基礎語法上和 c/c++ 是一致的。引入了 host/device 定義,host 指的是 cpu 端,device 指的是 gpu 端
個人感覺最難的部分在于并行的編程思想和 cpu 編程的思想差異比較大。我們以一個向量相加的 demo 程序舉例:
__global__ void add_kernel(int *a, int *b, int *c, int n) {int index = threadIdx.x + blockIdx.x * blockDim.x;if (index < n) {c[index] = a[index] + b[index];}
}int main() {int *a, *b, *c;int *d_a, *d_b, *d_c;int n = 10000;int size = n * sizeof(int);cudaMalloc((void**)&d_a, size);cudaMalloc((void**)&d_b, size);cudaMalloc((void**)&d_c, size);a = (int*)malloc(size);random_ints(a, n);b = (int*)malloc(size);random_ints(b, n);c = (int*)malloc(size);cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);//cuda kerneladd_kernel<<<(n + threads_per_block - 1)/threads_per_block, threads_per_block>>>(d_a, d_b, d_c, n);cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);cudaFree(d_a);cudaFree(d_b);cudaFree(d_c);return 0;
}
描述符
cuda 新增了三個描述符:
__global__: 在 device 上運行,可以從 host/device 上調用,返回值必須是 void, 異步執行.
__device__: 在 device 上運行和調用
__host__: 只能在 host 上執行和調用
CUDA Kernel
cuda_kernel 是由 <<<>>> 圍起來的,里面主要有 4 個參數用來配置這個 kernel <<<grid_size, block_size, shared_mem_size, stream>>>
grid_size: 以一維 block 為例,grid_size 計算以 (thread_num + block_size - 1) /block_size 計算大小
block_size: 見上面 SM 部分介紹
shared_mem_size: 如果按 __shared__ int a [] 方法聲明共享內存,需要在這里填需要分配的共享內存大小。注意不能超過硬件限制,比如 A100 192KB
stream: 異步多流執行時的 cuda 操作隊列,在這個流上的所有 kernel 是串行執行的,多個流之間是異步執行的。后續會在異步章節里詳細介紹
整個過程如下圖,先通過 cudaMemcpy 把輸入數據 copy 到顯存 ->cpu 提交 kernel->gpu kernel_launch-> 結果寫回線程 ->DeviceToHost copy 回內存.
[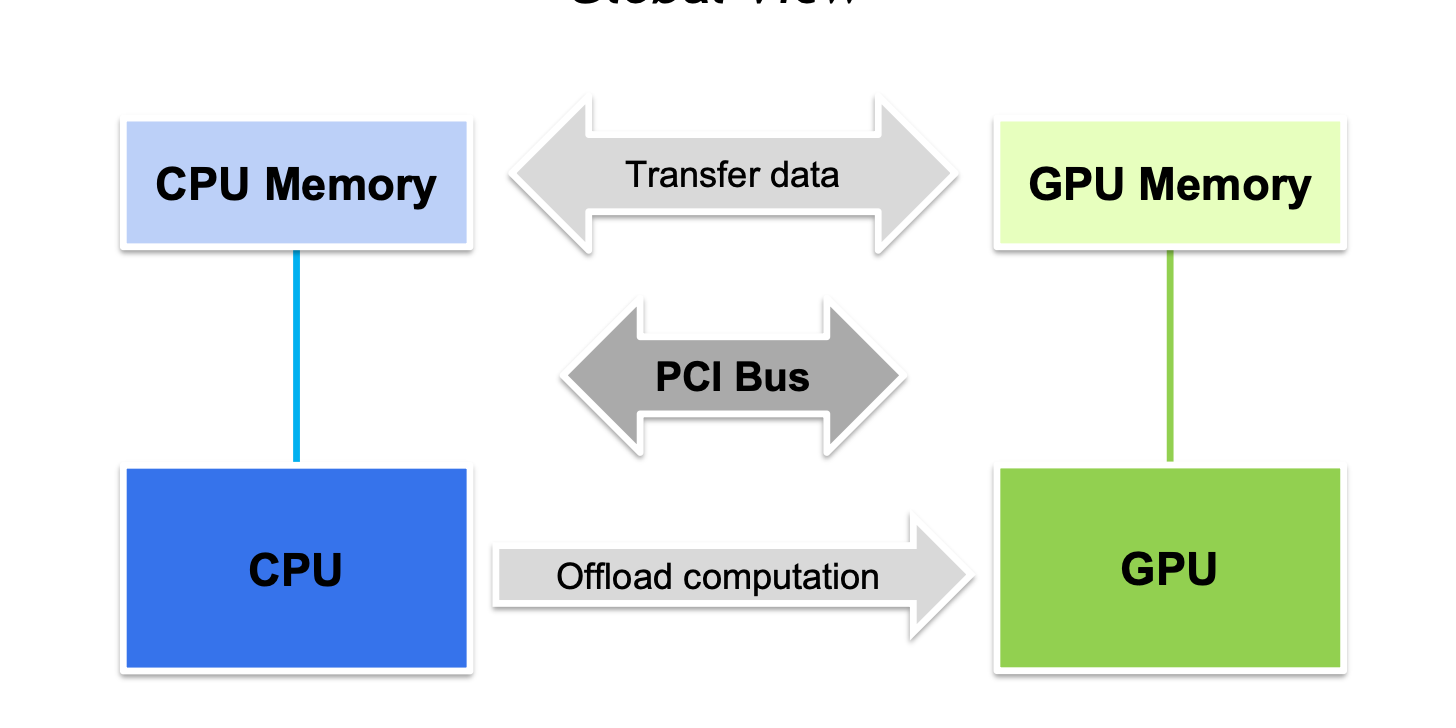 ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240606194617352-1175795907.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240606194617352-1175795907.png =700x)
add_kernel 相當于我們將 for 循環拆分為了每個線程只處理一個元素的相加的并行執行。通過 nvcc 編譯后就完成了第一個 kernel 的編寫。下一篇會以一個具體的例子來講如何進行 kernel 的性能分析和調優.
常用庫
thrust: cuda 中類似于 c++ STL 的定位,一些類似于 STL 的常見算法可以在這里找到現成的實現,比如 sort/reduce/unique/random 等。文檔: https://nvidia.github.io/cccl/thrust/api/namespace_thrust.html
cudnn: 神經網絡加速的常用庫。包含卷積 /pooling/softmax/normalization 等常見 op 的優化實現.
cuBlas: 線性代數相關的庫。進行矩陣運算時可以考慮使用,比如非常經典的矩陣乘法實現 cublasSgemm
Cub: warp/block/device 級的編程組件,非常常用。文檔: https://nvidia.github.io/cccl/cub/
nccl: 集合通信庫。用于卡間通信 / 多機通信
相關資料
cuda 編程指導手冊: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#programming-model
性能分析工具 Nsight-System & Nsight-Compute: https://docs.nvidia.com/nsight-systems/index.html
2. 訪存優化
簡介
在 CUDA 程序中,訪存優化個人認為是最重要的優化項。往往 kernel 會卡在數據傳輸而不是計算上,為了最大限度利用 GPU 的計算能力,我們需要根據 GPU 硬件架構對 kernel 訪存進行合理的編寫.
這章主要以計算一個 tensor 的模為例,來看具體如何優化訪存從而提升并行效率。以下代碼都只列舉了 kernel 部分,省略了 host 提交 kernel 的部分. Block_size 均為 256, 代碼均在 A100 上評估性能.
∥ v ? ∥ = v 1 2 + v 2 2 + ? + v n 2 \| \vec{v} \| = \sqrt{v_1^2 + v_2^2 + \cdots + v_n^2} ∥v∥=v12?+v22?+?+vn2??
CPU 代碼
void cpu_tensor_norm(float* tensor, float* result, size_t len) {double sum = 0.0;for (auto i = 0; i < len; ++i) {sum += tensor[i] * tensor[i];}*result = sqrt(sum);
}
是一個非常簡單的函數,當然這里針對 CPU 程序也有優化方法,當前實現并不是最優解。此處忽略不表
GPU 實現 1 - 基于 CPU 并行思想
在傳統的多線程 CPU 任務中,如果想處理一個超大數組的求和,很自然的會想到起 N 個線程,每個線程算 1/N 的和,最后再把這 N 個和加到一塊求 sqrt. 根據這個思路實現了 kernel1, 使用 1 個 block, block 中每個線程計算 1/N 連續存儲的數據.
__global__ void norm_kernel1(float* tensor, float* result, size_t len) {auto tid = threadIdx.x;auto size = len / blockDim.x;double sum = 0;for (auto i = tid * size; i < (tid + 1) * size; i++) {sum += tensor[i] * tensor[i];}result[tid] = float(sum);
}
//norm_kernel1<<<1, block_size>>>(d_tensor, d_result1, len);
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152246087-1253896473.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152246087-1253896473.png =700x)
接下來我們使用 nsight-compute 來分析下第一個 kernel 實現哪些地方不合理。具體使用方法可以從官方文檔獲取,這里舉個命令例子: nv-nsight-cu-cli -f --target-processes all -o profile --set full --devices 0 ./output/norm_kernel_bench
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152307166-1642995465.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152307166-1642995465.png =700x)
ncu 分析給出了 2 個主要問題:
grid 太小
因為我們只使用了 256 個線程。而 A100 光 CUDA core 就 7000 個。在 GPU 中不像 CPU 中線程上下文切換具有很高的成本,如果想充分利用算力,就要用盡量多的線程來提升并發度。同時線程數也不能無限制增加,因為如果每個線程使用了 32 個寄存器,而 SM 中最多 16384 的寄存器空間的話,多于 16384/32=512 個線程后,這些多出來的線程就需要把數據存到顯存里,反而會降低運行效率.
讀顯存瓶頸
下面打開 detail 后也給出了問題日志: Uncoalesced global access, expected 262144 transactions, got 2097152 (8.00x) at PC
coalesced 指的是顯存讀取需要是連續的,這里也許你會有疑問,在 kernel1 里就是按照連續的顯存讀的呀。這里涉及到 GPU 的實際執行方式,當一個 thread 在等讀顯存數據完成的時候,GPU 會切換到下一個 thread, 也就是說是需要讓 thread1 讀顯存的數據和 thread2 的數據是連續的才會提升顯存的讀取效率,在 kernel1 中明顯不連續。同時參考 ProgrammingGuide 中的描述,每個 warp 對顯存的訪問是需要對齊 32/64/128 bytes (一次數據傳輸的數據量在默認情況下是 32 字節), 如果所有數據傳輸處理的數據都是該 warp 所需要的,那么合并度為 100%,即合并訪問
GPU 實現 2 - 優化 coalesced
__global__ void norm_kernel2(float* tensor, float* result, size_t len) {auto tid = threadIdx.x;double sum = 0.0;while (tid < len) {sum += tensor[tid] * tensor[tid];tid += blockDim.x;}result[threadIdx.x] = float(sum);
}
//norm_kernel2<<<1, block_size>>>(d_tensor, d_result1, len);
依然還是 1 個 block256 個線程,kernel2 將每個 thread 讀取方式改成了每隔 256 個 float 讀一個,這樣 uncoalesced 的報錯就不見了。但是!一跑 bench 卻發現為啥反而還變慢了呢?
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152401330-978761037.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152401330-978761037.png =700x)
此時可以點開 memory WorkLoad Analysis
[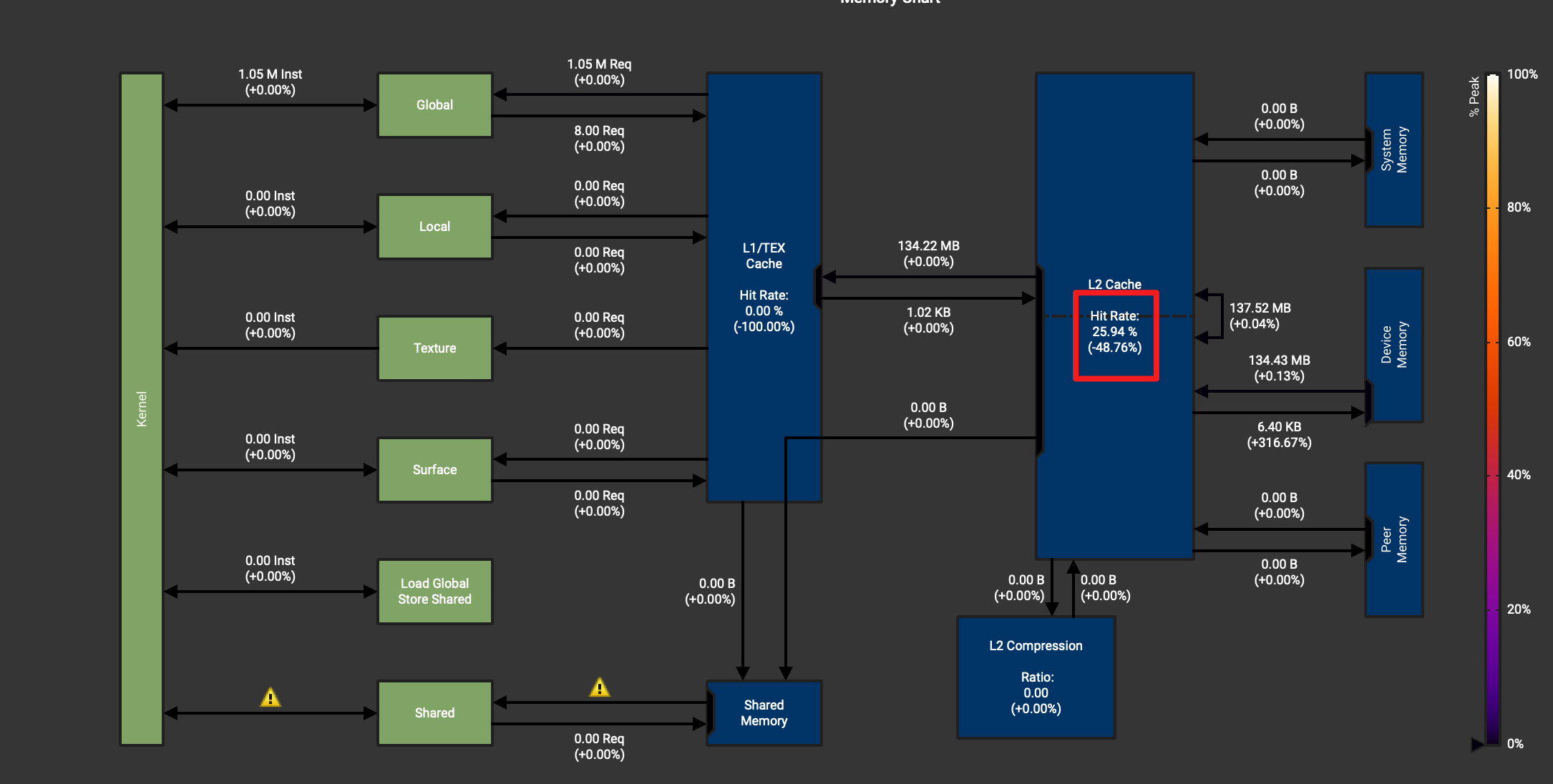 ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152422066-825943602.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152422066-825943602.png =700x)
從這里可以看到 L2 cache 命中率降低了 50% 左右,原因是因為按照 kernel1 的訪問方式,第一次訪問了 32bytes 長度,但是只用了一部分后,剩下的會緩存在 L2 中,而 Kernel2 雖然訪問顯存連續了,但每次的 cache 命中率會隨著讀入數據利用效率的變高而降低,根本原因是因為線程和 block 太少導致的。另外這張圖上還有個明顯的嘆號,我們沒有合理的用到 shared_memory. 接下來的 kernel3 重點優化這兩部分
GPU 實現 3 - 增大并發 & 利用 shared_memory
__global__ void norm_kernel3(float* tensor, float* result, size_t len) {auto tid = threadIdx.x + blockIdx.x * blockDim.x;extern __shared__ double sum[];auto loop_stride = gridDim.x * blockDim.x;sum[threadIdx.x] = 0;while (tid < len) {sum[threadIdx.x] += tensor[tid] * tensor[tid];tid += loop_stride;}__syncthreads();if (threadIdx.x == 0) {for (auto i = 1; i < blockDim.x; ++i) {sum[0] += sum[i];}result[blockIdx.x] = float(sum[0]);}
}
//grid_size3=64
//norm_kernel3<<<grid_size3, block_size, block_size * sizeof(double)>>>(d_tensor, d_result3, len);
//for (auto i = 1; i < grid_size3; ++i) {
// h_result3[0] += h_result3[i];
//}
//sqrt(h_result3[0])
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152437547-1649475252.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152437547-1649475252.png =700x)
短短幾行改動,讓程序快了 27 倍,這是什么魔法 (黑人問號)? kernel3 做了如下幾個優化:
- 使用 shared_memory 用來存儲臨時加和,最后在每個 block 的第一個 thread 里把這些加和再加到一塊,最后再寫回 HBM. shared_memory 訪問速度 19T/s, HBM 速度才 1.5TB/s, 所以我們如果有需要臨時存儲的變量,要盡可能的把 shared_mem 利用起來.
- 這次使用了 64 個 block, GPU 的其他 SM 終于不用看戲了。但其實還是可以增加的,A100 有 108 個 SM 呢,讓我們把他用滿再看下性能
auto grid_size3 = (len + block_size - 1) /block_size;可以看到我們終于讓計算吞吐打滿了~
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152524570-318241188.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152524570-318241188.png =700x)
到這里還有 2 個問題需要解決: 1. 我們只是在 GPU 里求了局部加和,全局和還得挪到 CPU 算好挫. 2. 每個 block 在 syncthread 之后只有第一個線程在計算,能不能加快計算的同時減少一下計算量
GPU 實現 4 - 優化加和
template <int64_t BLOCK_SIZE>
__global__ void norm_kernel4(float* tensor, double* result, size_t len) {using BlockReduce = cub::BlockReduce<double, BLOCK_SIZE>;__shared__ typename BlockReduce::TempStorage temp_storage;int tid = threadIdx.x + blockIdx.x * blockDim.x;double sum = 0.0;if (tid < len) {sum += tensor[tid] * tensor[tid];}double block_sum = BlockReduce(temp_storage).Sum(sum);if (threadIdx.x == 0) {atomicAdd(result, block_sum);}
}
//norm_kernel4<block_size><<<grid_size, block_size>>>(d_tensor, d_result4, len);
//sqrt(h_result4)
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152540197-967725268.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152540197-967725268.png =700x)
對與第一個線程連續加和的問題,我偷懶使用了 cub::BlockReduce 方法,BlockReduce 的原理是經典的樹形規約算法。利用分治的思想,把原來的 32 輪加和可以簡化為 5 輪加和,這樣就能極大減少長尾線程的計算量.
[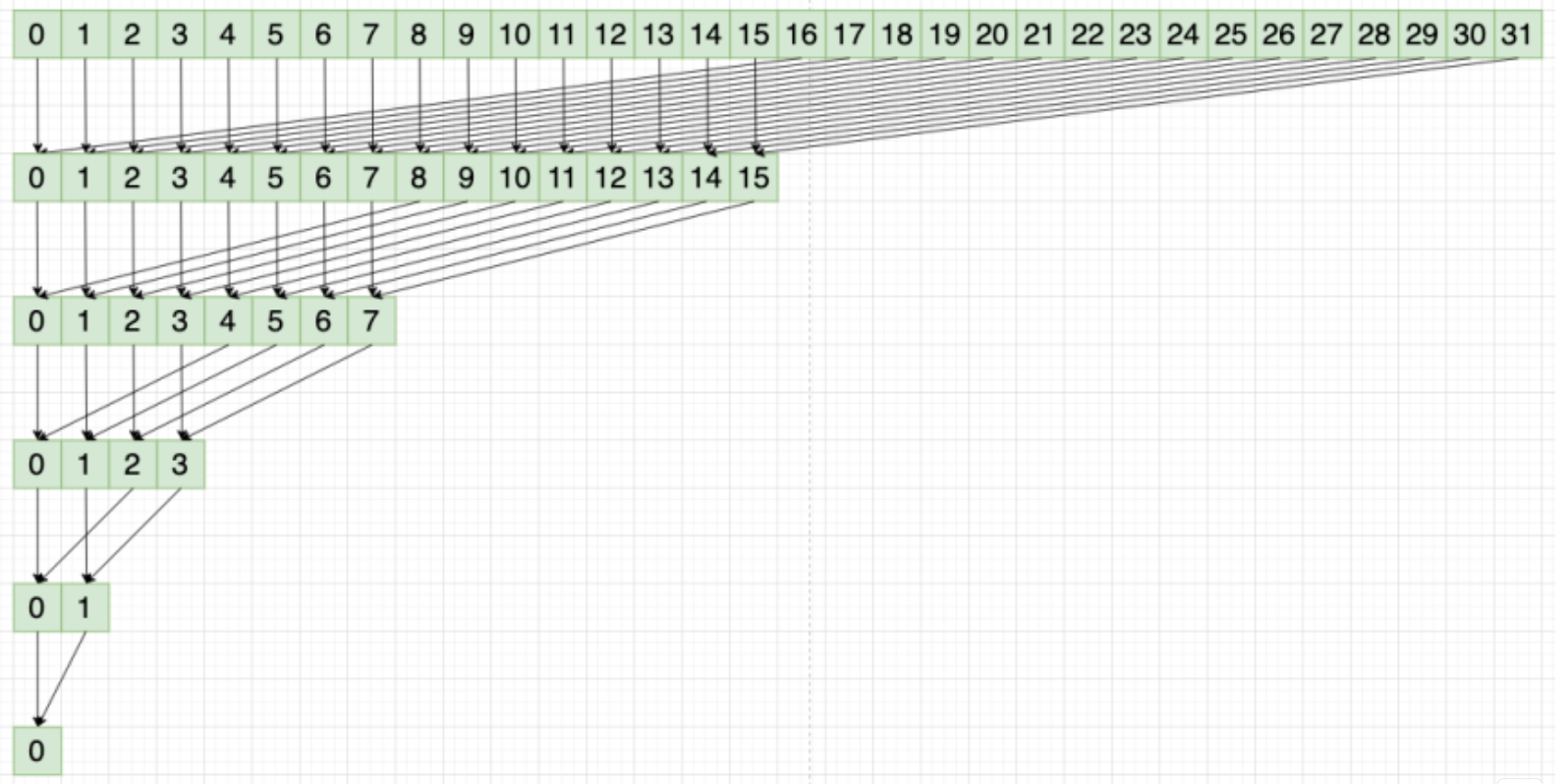 ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152547698-1157082575.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152547698-1157082575.png =700x)
對于顯存上的全局求和問題,由于 block 之間是沒有任何關聯的,我們必須使用原子操作來解決對全局顯存的操作。這里為了減少原子寫沖突,只在 block 的第一個線程上進行原子加。另外我們可以不用 cub 的 BlockReduce 優化到和他差不多的性能嗎?
GPU 實現 5 - 自己實現 BlockReduce
template <int64_t BLOCK_SIZE>
__global__ void norm_kernel5(float* tensor, double* result, size_t len) {using WarpReduce = cub::WarpReduce<double>;const int64_t warp_size = BLOCK_SIZE / 32;__shared__ typename WarpReduce::TempStorage temp_storage[warp_size];__shared__ float reduce_sum[BLOCK_SIZE];int tid = threadIdx.x + blockIdx.x * blockDim.x;int warp_id = threadIdx.x / 32;float sum = 0.0;if (tid < len) {sum += tensor[tid] * tensor[tid];}auto warp_sum = WarpReduce(temp_storage[warp_id]).Sum(sum);reduce_sum[threadIdx.x] = warp_sum; //這里盡量避免wrap內的分支__syncthreads();//樹形規約int offset = warp_size >> 1;if (threadIdx.x % 32 == 0) {while (offset > 0) {if (warp_id < offset) {reduce_sum[warp_id * 32] += reduce_sum[(warp_id + offset) * 32];}offset >>= 1;__syncthreads();}}if (threadIdx.x == 0) {atomicAdd(result, reduce_sum[0]);}
}
//norm_kernel5<block_size><<<grid_size5, block_size>>>(d_tensor, d_result5, len);
//sqrt(h_result5)
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152605137-331016775.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152605137-331016775.png =700x)
kernel5 主要分為兩個部分,第一步進行了 warp 內的規約,第二步手動實現了樹形規約的方法。耗時基本與 BlockReduce 一致,由于 warp 內的 32 個線程會共享寄存器和 shared_mem 讀寫,在 warp 內先做一些規約可以適當減少后續的 sync_threads 輪數.
其實這個 kernel 還是有很大優化空間,篇幅受限原因更深層次的優化技巧在后續說明
計算分析
[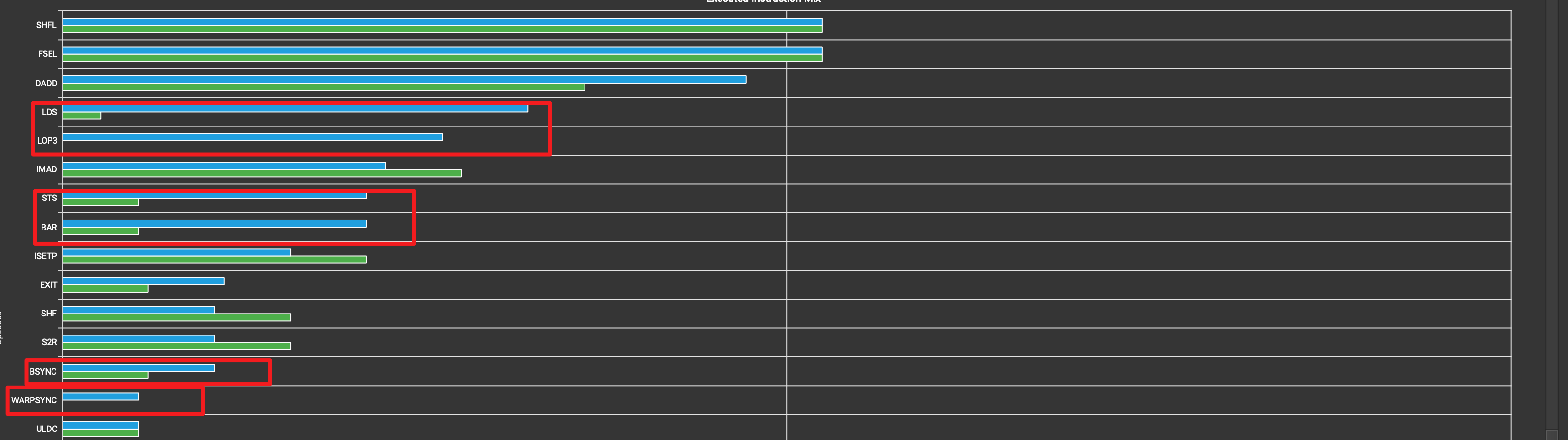 ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152622218-867073834.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152622218-867073834.png =700x)
在匯編指令統計這塊可以看到 LDS (從 shared_mem 加載指令), LOP3 (logic 操作), STS (往 mem 中寫入操作), BAR (barrier), BSYNC (線程同步時的 barrier, 對應 atomic 操作), WARPSYNC (warp 同步) 這些相較于 kernel4 多了很多. WARPSYNC/LOP3/BAR 這些變多是正常的,是 kernel5 里新增的邏輯. LDS/STS 增加應該是因為我們在 warp_reduce 時的頻率比 block_reduce 對共享內存的訪問頻率更高導致.
訪存注意要點 - bank conflicts
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152637810-1790818641.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152637810-1790818641.png =700x)
內存分析里出現了一個新名詞 bank conflicts , 先根據 官方文檔 解釋下這個名詞.
SharedMemory 結構:放在 shared memory 中的數據是以 4bytes 作為 1 個 word,依次放在 32 個 banks 中。第 i 個 word 存放在第 (i % 32) 個 bank 上。每個 bank 在每個 cycle 的 bandwidth 為 4bytes。所以 shared memory 在每個 cycle 的 bandwidth 為 128bytes。這也意味著每次內存訪問只會訪問 128bytes 數據
[ ](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152647400-1139929431.png =700x)
](https://img2024.cnblogs.com/blog/1439743/202406/1439743-20240617152647400-1139929431.png =700x)
如果同一個 warp 內的多個 threads 同時訪問同一個 bank 內的同一個 word, 會觸發 broadcast 機制,會同時發給多個 thread. 不會產生沖突
沖突主要產生在多個 threads 訪問同一個 bank 內的不同 word, 如上圖的第二列。這樣就會導致本來的一次 memory transaction 被強制拆分成了 2 次,而且需要 ** 串行 ** 訪問 memory
解決方法:
通過錯位的方式訪問數組,避免訪問步長和 32 產生交集,每個線程根據線程編號 tid 與訪問步長 s 的乘積來訪問數組的 32-bits 字 (word):
extern __shared__ float shared[];
float data = shared[baseIndex + s * tid];
如果按照上面的方式,那么當 s*n 是 bank 的數量 (即 32) 的整數倍時或者說 n 是 32/d 的整數倍 (d 是 32 和 s 的最大公約數) 時,線程 tid 和線程 tid+n 會訪問相同的 bank。我們不難知道如果 tid 與 tid+n 位于同一個 warp 時,就會發生 bank 沖突,相反則不會。
仔細思考你會發現,只有 warp 的大小 (即 32) 小于等于 32/d 時,才不會有 bank 沖突,而只有當 d 等于 1 時才能滿足這個條件。要想讓 32 和 s 的最大公約數 d 為 1,s 必須為奇數。于是,這里有一個顯而易見的結論:當訪問 ** 步長 s 為奇數 ** 時,就不會發生 bank 沖突。
via:
-
CUDA Shared Memory 在向量化指令下的訪存機制 孤獨代碼 發表于 2023 年 12 月 26 日
https://code.hitori.moe/post/cuda-shared-memory-access-mechanism-with-vectorized-instructions/ -
CUDA 程序優化 - 1. 基礎介紹 - SunStriKE - 博客園 posted @ 2024-06-06 19:49
https://www.cnblogs.com/sunstrikes/p/18235920 -
cuda 程序優化 - 2. 訪存優化 - SunStriKE - 博客園 posted @ 2024-06-17 15:31
https://www.cnblogs.com/sunstrikes/p/18252517




)
)

:邏輯回歸原理與公式推導)











