本文將展示YOLOv8中損失函數計算的完整代碼解析,注釋中提供了詳盡的解釋,并結合示例演示了數據維度的轉換,以幫助更好地理解。
YOLOv8的損失函數計算代碼位于'ultralytics/utils/loss.py'文件中(如下所示),我在代碼中的注釋提供了詳細解析。
首先看一下整體包含哪些方法
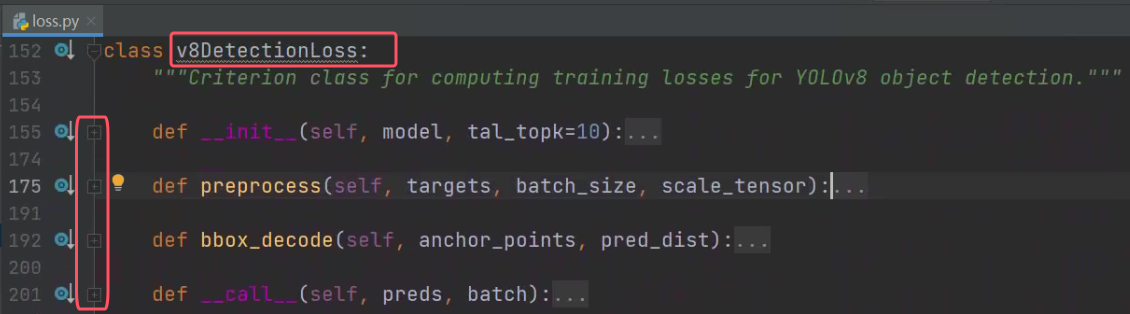
__init__和preprocess的代碼如下
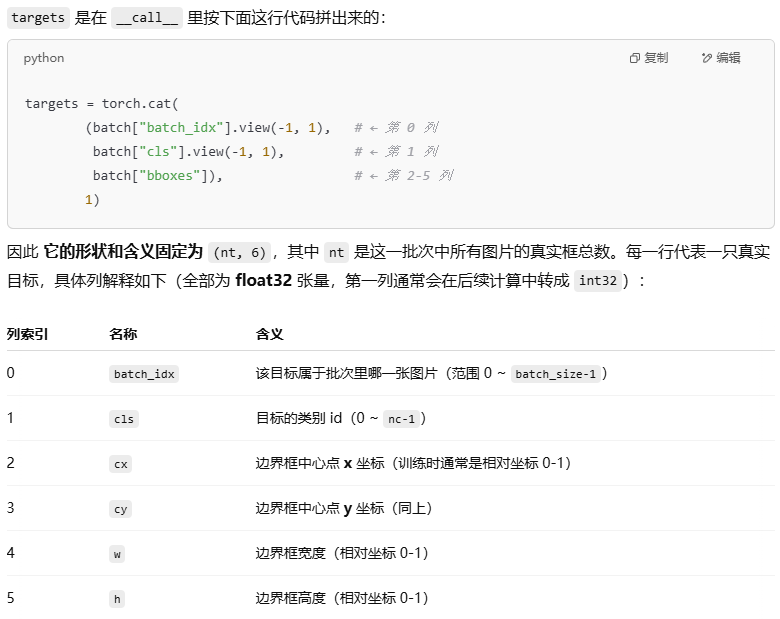
class v8DetectionLoss:"""Criterion class for computing training losses for YOLOv8 object detection."""def __init__(self, model, tal_topk=10): # model must be de-paralleled"""Initialize v8DetectionLoss with model parameters and task-aligned assignment settings."""# 獲取模型的設備信息(模型參數所在的設備 CPU/GPU)device = next(model.parameters()).device # get model device# 獲取模型的超參數配置(如超參數字典,包含損失權重等)h = model.args # hyperparameters# 獲取模型最后一層,一般是 Detect() 模塊,其中包含輸出相關的屬性m = model.model[-1] # Detect() module# 定義二元交叉熵損失(帶Logits版),用于分類損失計算(reduction="none"表示不在內部求和,保留逐元素損失)self.bce = nn.BCEWithLogitsLoss(reduction="none")# 保存超參數配置到屬性 hyp,以便后續使用(例如獲取損失權重)self.hyp = h# 模型的步長列表,每個輸出層相對于原圖的下采樣倍數self.stride = m.stride # model strides# 模型的類別數(number of classes)self.nc = m.nc # number of classes# 輸出通道數 no = 類別數 + 每個邊界框預測的分布參數數目 (reg_max * 4)# 例如,如果類別數 nc=80,reg_max=16,則 no = 80 + 16*4 = 144self.no = m.nc + m.reg_max * 4# 每個邊界框回歸的最大分布區間(reg_max,一般用于分布Focal Loss)self.reg_max = m.reg_max# 保存設備信息到屬性 deviceself.device = device# 標志是否使用 DFL(Distribution Focal Loss),當 reg_max > 1 時使用self.use_dfl = m.reg_max > 1# 初始化任務對齊分配器(Task-Aligned Assigner),用于在訓練時匹配預測和真實目標self.assigner = TaskAlignedAssigner(topk=tal_topk, num_classes=self.nc, alpha=0.5, beta=6.0)# 初始化邊界框損失函數(BboxLoss),傳入 reg_max,用于計算邊界框的回歸損失(如 IoU 和 DFL)self.bbox_loss = BboxLoss(m.reg_max).to(device)# 創建投影張量 self.proj,用于將分布轉換為具體距離(值為0,1,...,reg_max-1),放在與模型相同的設備上self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)def preprocess(self, targets, batch_size, scale_tensor):"""預處理目標數據:轉換為張量格式并縮放坐標模型需要固定形狀的輸入(如 (batch_size, N, 5)),而原始標注的目標數量是動態的。比如targets中的nl(總目標數),不同batch中的總目標數不一樣,預測的結果難以統一。targets 是在 __call__ 里用concat拼出來的:參數:targets: 原始標注數據,形狀為(nl, ne),其中nl = 當前batch的總目標數ne = [batch_index, class_id, x_center, y_center, width, height]batch_size: 當前batch的樣本數scale_tensor: 縮放因子(用于將歸一化坐標還原為輸入圖像尺度)示例輸入:batch_size=2targets = [[0, 3, 0.5, 0.5, 0.2, 0.3], # 圖像0中的目標[0, 1, 0.3, 0.4, 0.1, 0.2],[1, 5, 0.7, 0.8, 0.2, 0.1] # 圖像1中的目標]scale_tensor = tensor([640, 640, 640, 640])(假設輸入圖像尺寸為640x640)"""nl, ne = targets.shapeif nl == 0: # 如果當前batch沒有目標'''out是預處理后的目標張量,其形狀為: (batch_size, max_targets_per_image, 5)其中:batch_size:當前批次的圖像數量(例如2)。max_targets_per_image:當前批次中單張圖像的最大目標數量(例如10)。5: 每個目標的屬性,格式為 [class_id, x_min, y_min, x_max, y_max]。'''out = torch.zeros(batch_size, 0, ne - 1, device=self.device)else:i = targets[:, 0] # 取出了所有真實框的圖像索引列,方便按圖像分組統計。# 計算每個圖像的目標數# 對一維張量i做去重,并計算每個唯一值出現的次數。counts里的每個元素就是對應那張圖像有多少個真實框。_, counts = i.unique(return_counts=True) counts = counts.to(dtype=torch.int32)# 創建輸出張量:形狀為(batch_size, max_counts, ne-1)# 示例:當max_counts=2時,形狀為(2, 2, 5)out = torch.zeros(batch_size, counts.max(), ne - 1, device=self.device)# 按圖像填充數據for j in range(batch_size):'''例:假設 batch_size=3 且i = tensor([0, 0, 1, 2, 2]) # 5 個框? 當 j = 0 :matches = tensor([ True, True, False, False, False])? 當 j = 1 :matches = tensor([False, False, True, False, False])? 當 j = 2 :matches = tensor([False, False, False, True, True ])matches 是一個布爾張量,標記哪些目標屬于第 j 張圖像'''matches = i == j if n := matches.sum(): # 該圖像有n個目標# 將匹配的目標數據存入out[j],去除第一列(圖像索引)# 示例:當j=0時,存入前兩個目標的[3,0.5,0.5,0.2,0.3]和[1,0.3,0.4,0.1,0.2]out[j, :n] = targets[matches, 1:] # [max_counts, 5]# 將坐標從歸一化的xywh轉換為圖像尺度的xyxy# out[..., 1:5]形狀:(batch_size, max_counts, 4)# 示例轉換前:[[0.5,0.5,0.2,0.3], ...] 歸一化的xywh# 轉換后得到絕對坐標:[[320, 320, 192, 384], ...]out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))return out # 輸出形狀:(batch_size, max_counts, 5)上面代碼中的targets來源如下
bbox_decode代碼如下:
def bbox_decode(self, anchor_points, pred_dist):"""將網絡輸出的 **距離分布(pred_dist)** 解碼成最終的邊界框坐標 (x1,y1,x2,y2)。─────────────────────────────────────────────────────────────? 參數說明----------------------------------------------------------------anchor_points : Tensor(shape=(A, 2))→ 每個輸出位置(=anchor) 在特征圖上的中心點坐標 (cx, cy),已按 stride歸一化到與 pred_dist 同尺度;A=全部輸出點總數 (H?W?+H?W?+…)pred_dist : Tensor(shape=(B, A, 4*reg_max))→ 模型回歸頭直接輸出的 **離散距離分布**:對于每個 anchor,一共 4 個方向(左、上、右、下),每個方向用 reg_max 個 bin 表示離地的概率分布。例:batch_size(B)=2,A=8400,reg_max=16? pred_dist.shape = (2, 8400, 4*16=64)? 返回值Tensor(shape=(B, A, 4)) # 對應每個 anchor 的 [l, t, r, b] 像素距離─────────────────────────────────────────────────────────────"""# 1) 如果使用 Distribution Focal Loss(DFL) —— reg_max > 1if self.use_dfl: # True 當 reg_max > 1b, a, c = pred_dist.shape # b=B, a=A, c=4*reg_max# ---------- ① view ----------# 把 “channel = 4*reg_max” 拆成 “4 個方向 × reg_max bins”# (B, A, 64) → (B, A, 4, 16)pred_dist = pred_dist.view(b, a, 4, c // 4)# ---------- ② softmax ----------# 對最后一維(16)做 softmax → 獲得離散概率分布pred_dist = pred_dist.softmax(3)# ---------- ③ 期望值 (matmul) ----------# self.proj = tensor([0,1,2,…,15]) ← shape (16,)# 期望 = Σ p_k * k# 形狀推導:# (B, A, 4, 16) @ (16,) → (B, A, 4)pred_dist = pred_dist.matmul(self.proj.type(pred_dist.dtype))# ?? 此時 pred_dist 的含義已經從“概率分布”→“具體距離值(左,上,右,下)”# ▼ 小示例(單 anchor)------------------------------------# 假設 reg_max=4, softmax 結果 = [0.1, 0.2, 0.6, 0.1]# self.proj = [0, 1, 2, 3]# 距離 = 0*0.1 + 1*0.2 + 2*0.6 + 3*0.1 = 1.7# --------------------------------------------------------# 2) 將 “距離格式(l,t,r,b)” 轉成 “bbox 坐標(x1,y1,x2,y2)”# dist2bbox 內部做:x1 = cx - l , y1 = cy - t# x2 = cx + r , y2 = cy + b# 如果 xywh=False ? 返回 xyxybboxes = dist2bbox(pred_dist, # (B, A, 4) 距離anchor_points, # (A, 2) 錨點中心xywh=False) # ← 輸出 xyxyreturn bboxes
形狀與數據流全覽(以 B=2, A=8400, reg_max=16 為例)
| 步驟 | 張量名 | 形狀 | 備注 |
|---|---|---|---|
| 輸入 | pred_dist | (2, 8400, 64) | 每點 64 通道 = 4×16 |
| ① | view | (2, 8400, 4, 16) | 拆成 4 方向 × 16 bin |
| ② | softmax | (2, 8400, 4, 16) | 每方向得到概率分布 |
| ③ | matmul | (2, 8400, 4) | 期望 → 距離值 (l,t,r,b) |
| ④ | dist2bbox | (2, 8400, 4) | 計算 (x1,y1,x2,y2) |
__call__代碼如下:
def __call__(self, preds, batch):"""計算一個 batch 的 3 項損失 (box / cls / DFL) 并返回總損失。下面的中文注釋**帶著具體數字示例**來演示每一步張量維度的變化,方便對 YOLOv8 的內部維度有直觀認識。─────────────────────────────── 示例假設 ───────────────────────────────? batch_size = 2 # 這一 batch 有 2 張圖片? 模型輸出 3 個特征層 feats:┌──feature0: (B, no, 80, 80) → 80×80 = 6400 點├──feature1: (B, no, 40, 40) → 40×40 = 1600 點└──feature2: (B, no, 20, 20) → 20×20 = 400 點? total_points = 6400 + 1600 + 400 = 8400? nc = 80 # COCO 數據集 80 類? reg_max = 16 # DFL 每方向 16 bins? no = nc + 4*reg_max = 80 + 64 = 144所以:feature0.shape = (2, 144, 80, 80)feature1.shape = (2, 144, 40, 40)feature2.shape = (2, 144, 20, 20)───────────────────────────────────────────────────────────────────────"""# 1? 初始化損失向量 [box, cls, dfl]loss = torch.zeros(3, device=self.device)# 2? 拿到特征層列表 feats# 如果模型還輸出了 mask/proto 等信息時,preds = (proto, feats)feats = preds[1] if isinstance(preds, tuple) else preds# 3? 把 3 個特征層拼接成一個大張量,# 同時把通道 no 拆分為回歸分布(pred_distri)和分類分數(pred_scores)# --- 3.1 先 view ---# 把 (B, no, H, W) → (B, no, H*W)# 以 feature0 為例: (2, 144, 80, 80) → (2, 144, 6400)# 三層分別得到 (2,144,6400), (2,144,1600), (2,144,400)# --- 3.2 再 cat ---# 按 dim=2 把三個張量拼成 (2, 144, 8400)cat_out = torch.cat([xi.view(feats[0].shape[0], self.no, -1) # -1 相當于 H*Wfor xi in feats],dim=2) # ? shape = (2, 144, 8400)# --- 3.3 split ---# 在 dim=1(通道維) 按 (64, 80) 切兩塊# · pred_distri : (2, 64, 8400) ← 4*reg_max# · pred_scores : (2, 80, 8400) ← ncpred_distri, pred_scores = cat_out.split((self.reg_max * 4, self.nc), dim=1)# 4? 為后續計算把維度換成 (B, 8400, C)# permute(0,2,1) 即把通道維和點數維互換pred_scores = pred_scores.permute(0, 2, 1).contiguous() # (2, 8400, 80)pred_distri = pred_distri.permute(0, 2, 1).contiguous() # (2, 8400, 64)# 5? 記錄一些常用量batch_size = pred_scores.shape[0] # =2dtype = pred_scores.dtype# 6? 計算此層對應的 **原圖尺寸** (img_h, img_w)# 假設最小特征層 stride=8, feats[0].shape[2:]=(80,80)imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) \* self.stride[0] # (80,80)*8 → (640,640)# 7? 生成 anchor_points 和 stride_tensor# anchor_points.shape = (8400, 2) ← (cx, cy) in feature space# stride_tensor.shape = (8400, 1) ← 每點對應的 strideanchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)# 8? 組裝并預處理 targets# 原始 batch 字典里是分散的,拼成 (nt,6) → preprocess → (B, M, 5)targets = torch.cat((batch["batch_idx"].view(-1, 1), # (nt,1)batch["cls"].view(-1, 1), # (nt,1)batch["bboxes"]), 1).to(self.device)targets = self.preprocess(targets,batch_size,scale_tensor=imgsz[[1, 0, 1, 0]]) # (2, M, 5)gt_labels, gt_bboxes = targets.split((1, 4), 2) # (2,M,1) (2,M,4)mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0) # (2,M,1) True/False# 9? 把離散分布解碼成 bbox 距離 → bbox 坐標pred_bboxes = self.bbox_decode(anchor_points, pred_distri)# shape = (2, 8400, 4) [x1,y1,x2,y2] 特征圖尺度# 🔟 assigner 做正負樣本匹配,得到:# target_bboxes (2, 8400, 4) 給回歸分支一個要對齊到的坐標真值。# target_scores (2, 8400, 80) 給分類分支一個帶權重的一熱標簽矩陣,權重代表匹配質量,質量越高分類損失權重越大。# fg_mask (2, 8400) 告訴回歸分支哪些 anchor 參與回歸損失。_, target_bboxes, target_scores, fg_mask, _ = self.assigner(pred_scores.detach().sigmoid(), # (2,8400,80)(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor,gt_labels, gt_bboxes, mask_gt)# 11? 計算分類損失 (BCE)target_scores_sum = max(target_scores.sum(), 1)loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum# 12? 計算回歸 / DFL 損失(僅正樣本)if fg_mask.sum():target_bboxes /= stride_tensor # 按 stride 還原到特征尺度loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points,target_bboxes, target_scores, target_scores_sum, fg_mask)# 13? 乘以超參權重loss[0] *= self.hyp.box # IoU / bboxloss[1] *= self.hyp.cls # 分類loss[2] *= self.hyp.dfl # DFL# 14? 返回total_loss = loss.sum() * batch_size # 注意 *B 做到“每張圖總損失求和”return total_loss, loss.detach() # loss = [box, cls, dfl]
上述代碼中的BboxLoss代碼如下所示:
class BboxLoss(nn.Module):"""負責計算 YOLOv8 “邊界框回歸” 兩項損失:① IoU 損失(這里用 CIoU)② DFL(Distribution Focal Loss)—— 只有 reg_max > 1 時才啟用下文所有注釋都混入了 **示例數字**,沿用前面提到的場景:batch_size = 2total_points = 8400reg_max = 16"""def __init__(self, reg_max: int = 16):super().__init__()# 如果 reg_max>1 才需要 DFLoss,否則就說明只做普通 L1/IoU,不用分布回歸self.dfl_loss = DFLoss(reg_max) if reg_max > 1 else Nonedef forward(self,pred_dist, # (B, N, 4*reg_max) ← 例: (2, 8400, 64)pred_bboxes, # (B, N, 4) ← 例: (2, 8400, 4) [x1,y1,x2,y2] (特征尺度)anchor_points, # (N, 2) ← (8400, 2) 每個 anchor 的中心點 (cx,cy)target_bboxes, # (B, N, 4) ← 跟 pred_bboxes 同形target_scores, # (B, N, nc) ← 用于加權的匹配質量分數target_scores_sum, # 標量 ← 正樣本權重之和, 用作歸一化fg_mask # (B, N) (Bool) ← True 表示該 anchor 是正樣本):"""返回:loss_iou : IoU 回歸損失loss_dfl : DFL 分布回歸損失 (若 reg_max==1 則為 0)"""# ─────────────────────────────────────────────────────────# 1? IoU 損失# ─────────────────────────────────────────────────────────# ? target_scores.sum(-1) → (B, N) 取每個 anchor 的匹配質量總分# ? [fg_mask] → (num_fg) 只保留正樣本# ? .unsqueeze(-1) → (num_fg,1) 方便后面乘法廣播# 例: 假設 num_fg = 900weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1) # (900, 1)# 計算預測框 和 真值框 的 CIoU# bbox_iou 返回形狀 (num_fg, 1)iou = bbox_iou(pred_bboxes[fg_mask], # (900,4)target_bboxes[fg_mask], # (900,4)xywh=False,CIoU=True)# IoU 損失 = (1 - IoU) * 權重# 形狀仍 (900,1),再 sum → 標量,再除 target_scores_sum 歸一化loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum# ─────────────────────────────────────────────────────────# 2? DFL 損失 (僅當 reg_max>1 時啟用)# ─────────────────────────────────────────────────────────if self.dfl_loss:# 2.1 GT bbox → “距離格式” 并離散到 0~(reg_max-1) 之間# target_ltrb.shape = (B, N, 4) ,數值為整數 bin# 例如一個方向的真值距離 = 5.8 像素,當 reg_max-1 = 15,# 則 target_ltrb ≈ round(5.8) = 6target_ltrb = bbox2dist(anchor_points, # (N,2)target_bboxes, # (B,N,4)self.dfl_loss.reg_max - 1 # max_dis=15)# 2.2 把 pred_dist 和 target_ltrb 先按 fg_mask 過濾,再 reshape# pred_dist[fg_mask] : (900, 64)# .view(-1, reg_max) : (900*4, 16)# ? 900 個正樣本 × 4方向 = 3600 行# pred_flat是模型預測值:每個正樣本 4 個方向 (左、上、右、下) 的離散距離概率分布,已鋪平成shape = (正樣本數 × 4, reg_max)。# target_flat是監督標簽:對應方向的 真實距離落在哪個 bin 的整數編號shape = (正樣本數 × 4,),取值范圍 0 ~ reg_max-1。pred_flat = pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max) # (3600,16)target_flat = target_ltrb[fg_mask].view(-1) # (3600,)# 2.3 計算 DFLoss (正樣本 & 逐方向)# 返回形狀 (3600,)loss_dfl_each = self.dfl_loss(pred_flat, target_flat)# 2.4 給每個正樣本方向乘它所屬 anchor 的 weight# weight.shape = (900,1) → view(-1,1) 再 repeat → (3600,1)loss_dfl = loss_dfl_each.unsqueeze(-1) * weight.repeat_interleave(4, dim=0)# 2.5 匯總并歸一化loss_dfl = loss_dfl.sum() / target_scores_sumelse:# 不使用 DFL 時,返回 0(放到正確設備上確保 dtype 一致)loss_dfl = torch.tensor(0.0, device=pred_dist.device)return loss_iou, loss_dfl
在BboxLoss中,還包含了邊界框交并比(bbox IoU)的計算,這是我們修改損失函數代碼時需要注意的部分。
def bbox_iou(box1, box2,xywh: bool = True,GIoU: bool = False,DIoU: bool = False,CIoU: bool = False,eps: float = 1e-7):"""計算兩組邊界框的 IoU / GIoU / DIoU / CIoU。───────────────────────────── 示例假設 ─────────────────────────────? 在 bbox 回歸損失里調用本函數:pred_bboxes[fg_mask] → (900, 4) # 正樣本預測框target_bboxes[fg_mask]→ (900, 4) # 對應 GT 框? 也支持更高維情況:box1.shape = (B, N, 1, 4) &box2.shape = (B, 1, M, 4)內部依靠 **逐元素廣播** 同樣能算出 (B,N,M) 的 IoU 矩陣。─────────────────────────────────────────────────────────────────────"""# ① 先把輸入拆成 4 個分量;如果 xywh=True,需要把中心點+長寬 轉成 左上+右下# -----------------------------------------------------------------if xywh: # (x, y, w, h) → (x1,y1,x2,y2)# .chunk(4, -1) 以最后一個維度(-1)平均切 4 份# 得到 (X, Y, W, H),形狀與 box1/box2 除最后維外完全一致(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)# ↙ 半寬、高 (保持與原維度一致,便于廣播)w1h1_2 = w1 / 2, h1 / 2w2h2_2 = w2 / 2, h2 / 2# ↙ 得到四角坐標b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1h1_2[0], x1 + w1h1_2[0], y1 - w1h1_2[1], y1 + w1h1_2[1]b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2h2_2[0], x2 + w2h2_2[0], y2 - w2h2_2[1], y2 + w2h2_2[1]# 形狀依舊與原輸入保持一致:例如 (900,4) 拆完后各分量 (900,1)else: # 已經是 (x1,y1,x2,y2) 直接拆b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)# 額外算寬高,用于 union (w*h)w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + epsw2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + epsif xywh: # xywh 模式下 w1 h1 還沒算w1, h1 = w1, h1 # 已在上方得到w2, h2 = w2, h2# ② 交集面積# -----------------------------------------------------------------# min/max 會自動廣播到同形狀,再 * 相乘得到交集面積 tensorinter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)# 例:正樣本情景 → inter.shape = (900,1)# ③ 并集面積 (w1*h1 + w2*h2 - inter)union = w1 * h1 + w2 * h2 - inter + eps# ④ IoUiou = inter / union # shape 與 inter 相同# ⑤ 根據標志計算 G/DI/CIoUif CIoU or DIoU or GIoU:# ? 最小包圍框 (convex) 寬高cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1)ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1)if CIoU or DIoU: # 距離 IoU / 完整 IoUc2 = cw.pow(2) + ch.pow(2) + eps # 對角線平方rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2).pow(2) +(b2_y1 + b2_y2 - b1_y1 - b1_y2).pow(2)) / 4 # 中心距平方if CIoU:# 額外的長寬比懲罰項v = (4 / math.pi**2) * ((w2 / h2).atan() - (w1 / h1).atan()).pow(2)with torch.no_grad():alpha = v / (v - iou + (1 + eps))return iou - (rho2 / c2 + v * alpha) # CIoUelse:return iou - rho2 / c2 # DIoUelse: # GIoUc_area = cw * ch + epsreturn iou - (c_area - union) / c_area # GIoUreturn iou # 純 IoU 模式
900 個正樣本 (900,4) 情景如下面示意圖所示:
box1 (900,4) ─┬─chunk─┬─> b1_x1 (900,1)│ ├─> b1_y1 (900,1)│ ├─> b1_x2 (900,1)│ └─> b1_y2 (900,1)
box2 (900,4) ─┘ ↑↑自動廣播 + clamp → inter (900,1)
inter / union --------------→ iou (900,1) ←【返回】
如果傳入形如 (B, N, 1, 4) × (B, 1, M, 4) 的高維張量,上面所有逐元素運算依靠 PyTorch 廣播機制 依舊能得到 (B, N, M) 的 IoU 矩陣。這樣就既支持“一對一”回歸損失,也支持“一對多” NMS / 匹配場景。
“ 報 errCode: 10008 的解決方案)




)









)
)

:邏輯回歸原理與公式推導)
