壓抑與痛苦,那些輾轉反側的夜,終會讓我們更加強大????????? ? ? ??
????????????????????????????????????????????????????????????????????????????????????????—— 25.5.20
????????Faiss(Facebook AI Similarity Search)是由 Facebook AI 團隊開發的一個開源庫,用于高效相似性搜索的庫,特別適用于大規模向量數據集的存儲與搜索
- 相似性搜索:Faiss 可以高效地搜索大規模向量集合中與查詢向量最相似的向量。這對于圖像檢索、推薦系統、自然語言處理和大數據分析等領域非常有用。
- 多索引結構(軟件層面):Faiss 提供了多種索引結構,包括Flat、IVF、HNSW、PQ、LSH 索引等,以滿足不同數據集和搜索需求的要求。
- 高性能(硬件層面):Faiss 可利用了多核處理器和 GPU 來加速搜索操作。
- 多語言支持:Faiss 支持 Python、C++ 語言。
- 開源:Faiss 是開源的,可以免費使用和修改,適用于學術研究和商業應用。
一、基本使用
1.基本操作
準備數據
np.random.rand():NumPy 庫中用于生成隨機數的函數,它返回一個或多個在?[0, 1)?區間內均勻分布的隨機數。
| 參數 | 類型 | 描述 | 默認值 |
|---|---|---|---|
| d0, d1, ..., dn | int (可選) | 指定輸出數組的形狀。如果不提供任何參數,則返回單個隨機浮點數。 | 無(必須至少提供一個維度) |
dim:定義向量維度?
# 1.1 定義數據和向量維度data = np.random.rand(10000, 256)dim = 256 # 存儲的向量維度Ⅰ、創建向量數據庫(索引)
① API函數
faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:

faiss.IndexFlatIP():?創建一個使用?內積(點積)?進行相似度搜索的 Faiss 索引。
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
點積公式:
 ② 工廠函數?
② 工廠函數?
faiss.index_factory():通過字符串描述創建 Faiss 索引,支持多種索引類型(如?"IVF100,Flat")。
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
description | str | 索引描述字符串(如?"IVF100,Flat") |
metric | int?(可選) | 距離度量( |
# 1.2 創建向量數據庫(索引)對象 API函數index1 = faiss.IndexFlatL2(dim) # Flat:線性搜索 (O(n)) L2:使用歐式距離計算相似度 dim: 向量維度index2 = faiss.IndexFlatIP(dim) # Flat:線性搜索 (O(n)) IP:使用點積計算相似度 dim: 向量維度# 1.3 創建向量數據庫(索引)對象 工廠函數index3 = faiss.index_factory(dim, "Flat", faiss.METRIC_L2) # Flat:線性搜索 (O(n)) L2:使用歐式距離計算相似度 dim: 向量維度index4 = faiss.index_factory(dim, "Flat", faiss.METRIC_INNER_PRODUCT) # Flat:線性搜索 (O(n)) INNER_PRODUCT:使用點積計算相似度 dim: 向量維度Ⅱ、添加向量
向量數據庫對象(索引).add():向向量數據庫(索引)中添加向量數據。
| 參數 | 類型 | 描述 |
|---|---|---|
xb | np.array | 待添加的向量數組(形狀?(n, d)) |
# 2.添加向量index1.add(data)index2.add(data)index3.add(data)index4.add(data)Ⅲ、搜索向量
np.random.rand():NumPy 庫中用于生成隨機數的函數,它返回一個或多個在?[0, 1)?區間內均勻分布的隨機數。
| 參數 | 類型 | 描述 | 默認值 |
|---|---|---|---|
| d0, d1, ..., dn | int (可選) | 指定輸出數組的形狀。如果不提供任何參數,則返回單個隨機浮點數。 | 無(必須至少提供一個維度) |
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
D:Distance 兩向量相似度
I:最相似的向量的索引
# 3.搜索向量query_vectors = np.random.rand(2, 256) # 創建兩個 256 維的向量作為查詢向量# query_vectors: 待搜索的向量 k: 返回的向量個數D, I = index1.search(query_vectors, k=2)# D: Distance 兩向量相似度 I: Index 返回最相似的向量的索引print("index1_D:", D, "index1_I:", I)D, I = index2.search(query_vectors, k=2)print("index2_D:", D, "index2_I:", I)D, I = index3.search(query_vectors, k=2)print("index3_D:", D, "index3_I:", I)D, I = index4.search(query_vectors, k=2)print("index4_D:", D, "index4_I:", I)Ⅳ、刪除向量
np.array():將 Python 列表或類似結構轉換為 NumPy 數組。
| 參數 | 類型 | 描述 |
|---|---|---|
data | list/array-like | 輸入數據 |
dtype | str/np.dtype?(可選) | 數據類型(如?'float32') |
向量數據庫對象(索引).remove_ids():從索引中刪除指定 ID 的向量。
| 參數 | 類型 | 描述 |
|---|---|---|
ids | np.array/list | 要刪除的向量 ID 列表 |
向量數據庫對象(索引).reset():清空索引中的所有向量。
向量數據庫對象(索引).ntotal:返回索引中當前存儲的向量數量(屬性,非函數)。
# 4.刪除向量index1.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index1剩余向量個數為:", index1.ntotal) # 打印剩余的向量個數index2.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index2剩余向量個數為:", index2.ntotal) # 打印剩余的向量個數index3.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index3剩余向量個數為:", index3.ntotal) # 打印剩余的向量個數index4.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index4剩余向量個數為:", index4.ntotal) # 打印剩余的向量個數index3.reset() # 刪除全部向量print("index3剩余向量個數為:", index3.ntotal) # 打印剩余的向量個數Ⅴ、存儲向量數據庫(索引)
faiss.write_index():將 Faiss 索引保存到磁盤。
| 參數 | 類型 | 描述 |
|---|---|---|
index | faiss.Index | Faiss 索引對象 |
file_path | str | 保存路徑 |
faiss.write_index(index1, 'flat.faiss')Ⅵ、加載向量數據庫(索引)
faiss.read_index():從磁盤加載 Faiss 索引。
| 參數 | 類型 | 描述 |
|---|---|---|
file_path | str | 索引文件路徑 |
faiss.read_index('flat.faiss')Ⅶ、完整代碼
import faiss
import numpy as npnp.random.seed(0)# 一、基本操作
def test01():# 1.構建索引(向量數據庫)# 1.1 定義數據和向量維度data = np.random.rand(10000, 256)dim = 256 # 存儲的向量維度# 1.2 創建索引對象 API函數index1 = faiss.IndexFlatL2(dim) # Flat:線性搜索 (O(n)) L2:使用歐式距離計算相似度 dim: 向量維度index2 = faiss.IndexFlatIP(dim) # Flat:線性搜索 (O(n)) IP:使用點積計算相似度 dim: 向量維度# 1.3 創建索引對象 工廠函數index3 = faiss.index_factory(dim, "Flat", faiss.METRIC_L2) # Flat:線性搜索 (O(n)) L2:使用歐式距離計算相似度 dim: 向量維度index4 = faiss.index_factory(dim, "Flat", faiss.METRIC_INNER_PRODUCT) # Flat:線性搜索 (O(n)) INNER_PRODUCT:使用點積計算相似度 dim: 向量維度# 2.添加向量index1.add(data)index2.add(data)index3.add(data)index4.add(data)# 3.搜索向量query_vectors = np.random.rand(2, 256) # 創建兩個 256 維的向量作為查詢向量# query_vectors: 待搜索的向量 k: 返回的向量個數D, I = index1.search(query_vectors, k=2)# D: Distance 兩向量相似度 I: Index 返回最相似的向量的索引print("index1_D:", D, "index1_I:", I)D, I = index2.search(query_vectors, k=2)print("index2_D:", D, "index2_I:", I)D, I = index3.search(query_vectors, k=2)print("index3_D:", D, "index3_I:", I)D, I = index4.search(query_vectors, k=2)print("index4_D:", D, "index4_I:", I)# 4.刪除向量index1.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index1剩余向量個數為:", index1.ntotal) # 打印剩余的向量個數index2.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index2剩余向量個數為:", index2.ntotal) # 打印剩余的向量個數index3.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index3剩余向量個數為:", index3.ntotal) # 打印剩余的向量個數index4.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index4剩余向量個數為:", index4.ntotal) # 打印剩余的向量個數index3.reset() # 刪除全部向量print("index3剩余向量個數為:", index3.ntotal) # 打印剩余的向量個數# 5.存儲索引faiss.write_index(index1, 'flat.faiss')# 6.加載索引faiss.read_index('flat.faiss')if __name__ == '__main__':test01()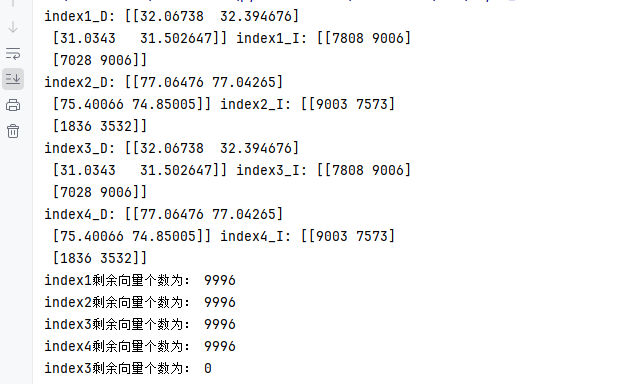
2.ID映射
Ⅰ、創建向量數據庫(索引)
?faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:
# 1.創建索引(向量數據庫)index = faiss.IndexFlatL2(256)Ⅱ、? 包裝向量數據庫(索引)
實現自定義向量編號
faiss.IndexIDMap():為索引添加自定義 ID 映射,支持按 ID 管理向量。
| 參數 | 類型 | 描述 |
|---|---|---|
index | faiss.Index | 底層索引(如?IndexFlatL2) |
# 2.包裝索引:實現自定義向量編號index = faiss.IndexIDMap(index)Ⅲ、添加向量【準備數據】
np.random.rand():生成?[0, 1)?區間均勻分布的隨機數組。
| 參數 | 類型 | 描述 |
|---|---|---|
d0, d1, ..., dn | int?(可選) | 數組形狀 |
向量數據庫對象(索引).add_with_ids():添加向量并指定自定義 ID(需配合?IndexIDMap?使用)。
| 參數 | 類型 | 描述 |
|---|---|---|
xb | np.array | 向量數組 |
ids | np.array | 對應的 ID 數組 |
np.arange():生成等間隔數值序列(類似 Python?range)。
| 參數 | 類型 | 描述 |
|---|---|---|
start | int/float | 起始值(默認?0) |
stop | int/float | 結束值(不包含) |
step | int/float | 步長(默認?1) |
# 3.添加向量data = np.random.rand(10000, 256)index.add_with_ids(data, np.arange(10000, 20000)) # 向量編號從 10000 開始, 20000 結束Ⅳ、搜索向量
向量數據庫對象(索引).ntotal:返回索引中當前存儲的向量數量(屬性,非函數)。
向量數據庫對象(索引).remove_ids():從索引中刪除指定 ID 的向量。
| 參數 | 類型 | 描述 |
|---|---|---|
ids | np.array/list | 要刪除的向量 ID 列表 |
np.array():將 Python 列表或類似結構轉換為 NumPy 數組。
| 參數 | 類型 | 描述 |
|---|---|---|
data | list/array-like | 輸入數據 |
dtype | str/np.dtype?(可選) | 數據類型(如?'float32') |
# 4.刪除索引向量print("index1向量個數為:", index.ntotal) # 打印向量個數index.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index1剩余向量個數為:", index.ntotal) # 打印剩余的向量個數# 有些索引類型本身支持用戶指定 ID,如果不支持的話,可以使用IndexIDMap包裝一下Ⅴ、完整代碼
import faiss
import numpy as npnp.random.seed(0)# 二、向量 ID 映射
def test02():# 1.創建索引(向量數據庫)index = faiss.IndexFlatL2(256)# 2.包裝索引:實現自定義向量編號index = faiss.IndexIDMap(index)# 3.添加向量data = np.random.rand(10000, 256)index.add_with_ids(data, np.arange(10000, 20000)) # 向量編號從 10000 開始, 20000 結束# 4.刪除索引向量print("index1向量個數為:", index.ntotal) # 打印向量個數index.remove_ids(np.array([0, 1, 2, 3])) # 刪除索引為 0, 1, 2, 3 的向量print("index1剩余向量個數為:", index.ntotal) # 打印剩余的向量個數# 有些索引類型本身支持用戶指定 ID,如果不支持的話,可以使用IndexIDMap包裝一下if __name__ == '__main__':test02()
二、更快的索引
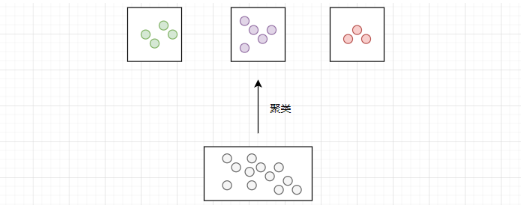
????????IndexFlat 索引是一種基于線性搜索的索引,它通過逐個計算與每個向量的相似度來進行搜索。在數據量較大的時候,搜索效率會較低。此時,我們可以使用 IndexIVFFlat 索引來提升搜索效率。它的原理如下:對于所有的向量進行聚類,相當于把所有的數據進行分類。當進行查詢時,在最相似的 N 個簇中進行線性搜索。這就減少了需要進行相似度計算的數據量,從而提升搜索效率。
????????需要注意:這種方法是一種在查詢的精度和效率之間平衡的方法。簇數目越多,精度越高,效率越低
1.定義數據和向量維度
np.random.rand():生成等間隔數值序列(類似 Python?range)
| 參數 | 類型 | 描述 |
|---|---|---|
start | int/float | 起始值(默認?0) |
stop | int/float | 結束值(不包含) |
step | int/float | 步長(默認?1) |
np.arange():生成等間隔數值序列(類似 Python?range)。
| 參數 | 類型 | 描述 |
|---|---|---|
start | int/float | 起始值(默認?0) |
stop | int/float | 結束值(不包含) |
step | int/float | 步長(默認?1) |
np.random.seed():設置隨機數生成器的種子,確保結果可復現。
| 參數 | 類型 | 描述 |
|---|---|---|
seed | int | 隨機種子 |
# 1.1 定義數據和向量維度
data = np.random.rand(1000000, 256)
dim = 256 # 存儲的向量維度
ids = np.arange(0, 1000000)
np.random.seed(4)
query_vector = np.random.rand(1, 256)2.線性搜索
faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:
向量數據庫對象(索引).add():向向量數據庫(索引)中添加向量數據。
| 參數 | 類型 | 描述 |
|---|---|---|
xb | np.array | 待添加的向量數組(形狀?(n, d)) |
time.time():返回當前時間的時間戳(自紀元以來的秒數,浮點數形式)。常用于計算代碼執行時間或記錄時間點。
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
D:Distance 兩向量相似度
I:最相似的向量的索引
# 使用線性搜索
def test01():# 1.構建索引(向量數據庫)# 1.2 創建索引對象 API函數index1 = faiss.IndexFlatL2(dim) # Flat:線性搜索 (O(n)) L2:使用歐式距離計算相似度 dim: 向量維度# 2.添加向量index1.add(data)# 3.搜索向量start = time.time()# query_vector: 待搜索的向量 k: 返回的向量個數D, I = index1.search(query_vector, k=1)# D: Distance 兩向量相似度 I: Index 返回最相似的向量的索引print("index1_D:", D, "index1_I:", I)print("method1_time:", time.time() - start)3.聚類搜索
faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:
faiss.IndexIVFFlat():創建一個基于倒排文件(Inverted File, IVF)和扁平化量化(Flat Quantization)的索引結構。適用于大規模向量搜索,通過聚類減少搜索空間,提升查詢效率。
| 參數 | 類型 | 說明 |
|---|---|---|
d | int | 向量維度(必填) |
nlist | int | 聚類中心數量(必填) |
metric | faiss.MetricType | 距離度量方式(默認?faiss.METRIC_L2,即歐氏距離) |
use_precomputed_table | int | 是否使用預計算的碼本表(默認?0,不使用) |
向量數據庫對象.train():對索引進行訓練,需提供一組代表性向量(通常為數據集的子集),用于學習聚類中心或其他模型參數(如量化碼本)。訓練是構建索引的必要步驟。
| 參數 | 類型 | 說明 |
|---|---|---|
xb | numpy.ndarray | 訓練數據矩陣,形狀為?(n_samples, d),其中?d?是向量維度 |
niter | int | 訓練迭代次數(部分索引類型支持,可選) |
verbose | bool | 是否打印訓練日志(可選,默認?False) |
向量數據庫對象(索引).add():向向量數據庫(索引)中添加向量數據。
| 參數 | 類型 | 描述 |
|---|---|---|
xb | np.array | 待添加的向量數組(形狀?(n, d)) |
time.time():返回當前時間的時間戳(自紀元以來的秒數,浮點數形式)。常用于計算代碼執行時間或記錄時間點。
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
D:Distance 兩向量相似度
I:最相似的向量的索引
# 使用聚類索引 IVF
def test02():# 第一個參數 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 聚類中心個數:nlistquantizer = faiss.IndexFlatL2(dim) # 使用歐式距離計算相似度 dim: 向量維度index = faiss.IndexIVFFlat(quantizer, dim, 100)index.train(data) # 訓練索引,找到所有簇的質心# 將向量分配到距離最近的簇中index.add(data) # 添加向量到索引中start = time.time()# 近似相似的搜索D, I = index.search(query_vector, k=1)print("index1_D:", D, "index1_I:", I)print("method2_time:", time.time() - start)4.聚類搜索(指定聚類簇數)
?faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:
faiss.IndexIVFFlat():創建一個基于倒排文件(Inverted File, IVF)和扁平化量化(Flat Quantization)的索引結構。適用于大規模向量搜索,通過聚類減少搜索空間,提升查詢效率。
| 參數 | 類型 | 說明 |
|---|---|---|
d | int | 向量維度(必填) |
nlist | int | 聚類中心數量(必填) |
metric | faiss.MetricType | 距離度量方式(默認?faiss.METRIC_L2,即歐氏距離) |
use_precomputed_table | int | 是否使用預計算的碼本表(默認?0,不使用) |
向量數據庫對象.nprobe():設置或獲取搜索時的探查聚類中心數量(nprobe)。控制搜索時訪問的聚類中心數目,影響查詢速度和精度(值越大越精確,但速度越慢)。
| 參數 | 類型 | 說明 |
|---|---|---|
nprobe | int | 要探查的聚類中心數量(僅用于設置時傳入) |
向量數據庫對象.train():對索引進行訓練,需提供一組代表性向量(通常為數據集的子集),用于學習聚類中心或其他模型參數(如量化碼本)。訓練是構建索引的必要步驟。
| 參數 | 類型 | 說明 |
|---|---|---|
xb | numpy.ndarray | 訓練數據矩陣,形狀為?(n_samples, d),其中?d?是向量維度 |
niter | int | 訓練迭代次數(部分索引類型支持,可選) |
verbose | bool | 是否打印訓練日志(可選,默認?False) |
向量數據庫對象(索引).add():向向量數據庫(索引)中添加向量數據。
| 參數 | 類型 | 描述 |
|---|---|---|
xb | np.array | 待添加的向量數組(形狀?(n, d)) |
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
time.time():返回當前時間的時間戳(自紀元以來的秒數,浮點數形式)。常用于計算代碼執行時間或記錄時間點。
D:Distance 兩向量相似度
I:最相似的向量的索引
# 使用聚類索引 IVF 效率與準確率平衡
def test03():# 第一個參數 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 聚類中心個數:nlistquantizer = faiss.IndexFlatL2(dim) # 使用歐式距離計算相似度 dim: 向量維度index = faiss.IndexIVFFlat(quantizer, dim, 100)index.nprobe = 10 # 指定在最相似的前多少個簇中進行線性搜索index.train(data) # 訓練索引,找到所有簇的質心# 將向量分配到距離最近的簇中index.add(data) # 添加向量到索引中start = time.time()# 近似相似的搜索D, I = index.search(query_vector, k=1)print("index1_D:", D, "index1_I:", I)print("method2_plus_time:", time.time() - start)5.完整代碼
import faiss
import numpy as np
import time# 1.1 定義數據和向量維度
data = np.random.rand(1000000, 256)
dim = 256 # 存儲的向量維度
ids = np.arange(0, 1000000)
np.random.seed(4)
query_vector = np.random.rand(1, 256)# 使用線性搜索
def test01():# 1.構建索引(向量數據庫)# 1.2 創建索引對象 API函數index1 = faiss.IndexFlatL2(dim) # Flat:線性搜索 (O(n)) L2:使用歐式距離計算相似度 dim: 向量維度# 2.添加向量index1.add(data)# 3.搜索向量start = time.time()# query_vector: 待搜索的向量 k: 返回的向量個數D, I = index1.search(query_vector, k=1)# D: Distance 兩向量相似度 I: Index 返回最相似的向量的索引print("index1_D:", D, "index1_I:", I)print("method1_time:", time.time() - start)# 使用聚類索引 IVF
def test02():# 第一個參數 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 聚類中心個數:nlistquantizer = faiss.IndexFlatL2(dim) # 使用歐式距離計算相似度 dim: 向量維度index = faiss.IndexIVFFlat(quantizer, dim, 100)index.train(data) # 訓練索引,找到所有簇的質心# 將向量分配到距離最近的簇中index.add(data) # 添加向量到索引中start = time.time()# 近似相似的搜索D, I = index.search(query_vector, k=1)print("index1_D:", D, "index1_I:", I)print("method2_time:", time.time() - start)# 使用聚類索引 IVF 效率與準確率平衡
def test03():# 第一個參數 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 聚類中心個數:nlistquantizer = faiss.IndexFlatL2(dim) # 使用歐式距離計算相似度 dim: 向量維度index = faiss.IndexIVFFlat(quantizer, dim, 100)index.nprobe = 10 # 指定在最相似的前多少個簇中進行線性搜索index.train(data) # 訓練索引,找到所有簇的質心# 將向量分配到距離最近的簇中index.add(data) # 添加向量到索引中start = time.time()# 近似相似的搜索D, I = index.search(query_vector, k=1)print("index1_D:", D, "index1_I:", I)print("method2_plus_time:", time.time() - start)if __name__ == '__main__':test01()print("————————————————————————————————")test02()print("————————————————————————————————")test03()# 這種方法是一種在查詢的精度和效率之間平衡的方法。 # time 與 nprobe 的關系是:nprobe 越大,查詢的精度越高,但是查詢的時間也會增加。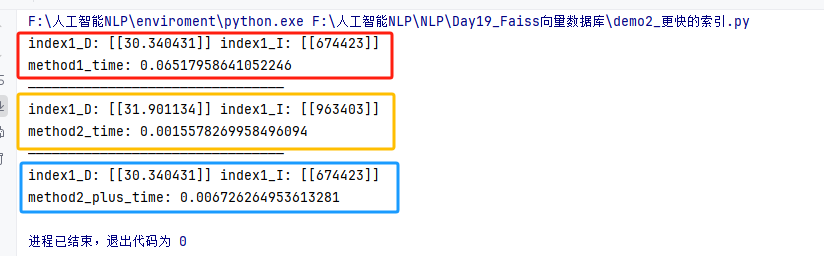
三、更少的內存
????????前面的幾個索引類型為了實現向量搜索,都需要將向量存儲到 Faiss 中,當向量的數量較多時就會占用更多的內存。 這也影響了 Faiss 的應用。所以,為了減少內存的占用,我們就需要會存儲的向量進行重新編碼、壓縮,使其占用更少的內存,從而能夠容納更多的向量。
????????量化技術可以使用較低精度的表示來近似向量數據,從而降低內存需求而又不犧牲準確性。 這對于大規模向量相似性搜索應用程序特別有用。
1.PQ量化壓縮
????????Product Quantization 是一種有效的近似最近鄰搜索方法,具有較高的搜索效率和較低的內存消耗。該方法已被廣泛應用于圖像檢索、文本檢索和機器學習等領域。
????????PQ 將高維數據點分成多個子空間,并對每個子空間使用獨立的編碼方法,將數據點映射到一個有限的編碼集合中。這個編碼過程將高維數據轉換成低維編碼,從而降低了存儲和計算的成本。
? ? ? ? 例如,我們有 N 個 1024 維的數據點:
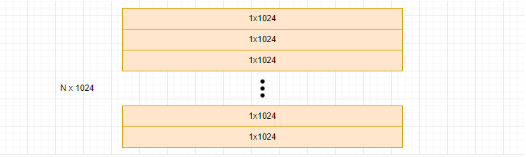
? ? ? ? 將每個向量劃分為 8 個 128 維的子向量 subvectors,更多的子向量劃分意味著將原始向量空間劃分為更多的子空間進行量化,有助于減少量化誤差。
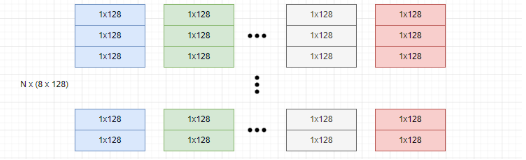
????????對每一組子向量進行聚類,這里簇的數量為 256,聚類的質心數量越多,誤差就越小。如下:
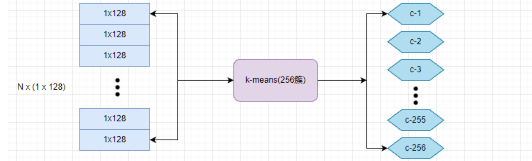
????????聚類之后的每個 subvector 的質心可以作為碼本,用于將子向量映射到一個整數。
????????此時,當我們拿到某一個 1×1024 的數據時,我們就可以通過下面的過程將其量化(用每一個子向量所屬質心的編號來表示):
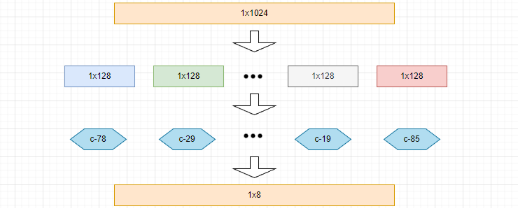
? ? ? ? 最終得到結果,量化前:1 × 1024 = 1024 字節,量化后:1 × 8 = 8 字節
代碼實現
np.random.rand():是 NumPy 庫中的一個函數,用于生成指定形狀的數組,數組中的元素是從均勻分布中隨機采樣的,范圍在 [0, 1) 之間。
| 參數 | 類型 | 說明 |
|---|---|---|
d0, d1, ..., dn | int, 可選 | 定義輸出數組的維度。如果不提供任何參數,則返回一個浮點數(標量)。 |
faiss.ProductQuantizer():是 Faiss 庫中的一個類,用于實現乘積量化(Product Quantization, PQ)。乘積量化是一種高效的向量壓縮和搜索技術,通過將高維向量分解為多個低維子向量,并對每個子向量進行獨立量化,從而減少存儲空間并加速搜索過程。
| 參數 | 類型 | 說明 |
|---|---|---|
d | int | 向量的總維度(必填)。 |
M | int | 子向量的數量,即將原始向量分成?M?個子向量,每個子向量的維度為?d // M(必填)。 |
nbits | int, 可選 | 每個子量化的碼本大小(即每個子向量使用的比特數),默認是 8,對應 256 個碼字。 |
metric_type | faiss.MetricType, 可選 | 距離度量類型,默認是?faiss.METRIC_L2(歐氏距離)。可選值包括?faiss.METRIC_INNER_PRODUCT?等。 |
train_type | faiss.ProductQuantizer.TrainType, 可選 | 訓練類型,控制訓練過程的行為,默認是?faiss.ProductQuantizer.TrainType.DEFAULT。 |
pq:創建一個 ??Product Quantizer (PQ)?? 對象,用于將 ??32 維向量?? 壓縮為 ??8 個子向量??,每個子向量用 ??8 比特(256 個碼字)?? 進行量化。
pq.train():訓練乘積量化(PQ)的碼本(codebook),學習每個子向量的量化中心。
需要提供足夠多樣本的訓練數據,使碼本能覆蓋數據的分布特征。
訓練完成后,才能進行向量編碼(compute_codes())。
| 參數 | 類型 | 說明 |
|---|---|---|
x | numpy.ndarray | 訓練數據矩陣,形狀為?(n_samples, d),dtype=float32(必填)。其中? d?必須與?ProductQuantizer?初始化時的維度一致。 |
pq.compute_codes():將輸入向量編碼為壓縮后的碼字(整數數組)。
每個子向量會被映射到其對應的量化中心(由碼本定義),最終輸出一個緊湊的碼字表示。編碼后的碼字可用于存儲或快速檢索。
| 參數 | 類型 | 說明 |
|---|---|---|
x | numpy.ndarray | 待編碼的向量矩陣,形狀為?(n_samples, d),dtype=float32(必填)。其中? d?必須與?ProductQuantizer?初始化時的維度一致。 |
pq.decode():將碼字解碼為近似原始向量(通過碼本中的量化中心重建)。
由于量化存在誤差,解碼后的向量可能與原始向量不完全相同,但能顯著減少存儲和計算開銷。
| 參數 | 類型 | 說明 |
|---|---|---|
codes | numpy.ndarray | 輸入的碼字矩陣,形狀為?(n_samples, M),dtype=uint8?或?int32(必填)。每個元素必須是? 0?到?2^nbits - 1?的整數。 |
import faiss
import numpy as npdef test():data = np.random.rand(10000, 32).astype('float32')# 訓練碼本(向量維度、子向量數量、子向量質心數量(位數))pq = faiss.ProductQuantizer(32, 8, 8)# pq.verbose = Truepq.train(data)# 編碼量化x1 = np.random.rand(1, 32).astype('float32')x2 = pq.compute_codes(x1)# 解碼量化x3 = pq.decode(x2)print('原始向量:\n', x1)print('編碼量化:\n', x2)print('解碼量化:\n', x3)if __name__ == '__main__':test()
2.定義數據和向量維度
np.random.seed():設置隨機數生成器的種子,確保每次運行代碼時生成的隨機數序列相同(可復現性)。常用于調試或實驗中需要固定隨機結果的情況。
| 參數 | 類型 | 說明 |
|---|---|---|
seed | int 或 None | 隨機數種子(整數)。若為?None,則使用系統時間作為種子(默認行為)。 |
np.random.rand():生成指定形狀的數組,元素從均勻分布 [0, 1) 中隨機采樣。
| 參數 | 類型 | 說明 |
|---|---|---|
d0, d1, ..., dn | int, 可選 | 定義輸出數組的維度。若無參數,返回單個浮點數。 |
np.arrange():生成一個等差數列數組,類似于 Python 內置的?range(),但返回的是 NumPy 數組而非列表。
| 參數 | 類型 | 說明 |
|---|---|---|
start | number, 可選 | 起始值(默認 0)。 |
stop | number | 結束值(不包含該值)。 |
step | number, 可選 | 步長(默認 1)。 |
dtype | dtype, 可選 | 輸出數組的數據類型(默認推斷)。 |
np.random.rand():NumPy 庫中的一個函數,用于生成指定形狀的數組,數組中的元素是從均勻分布中隨機采樣的,范圍在 [0, 1) 之間。
| 參數 | 類型 | 說明 |
|---|---|---|
d0, d1, ..., dn | int, 可選 | 定義輸出數組的維度。如果不提供任何參數,則返回一個浮點數(標量)。 |
np.random.seed(0)
data = np.random.rand(1000000, 256)
ids = np.arange(0, 1000000)
query_vector = np.random.rand(1, 256)3.線性搜索
faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:
faiss.IndexIDMap():將外部ID映射到Faiss索引的內部向量ID,允許通過用戶自定義的ID(如數據庫ID)檢索向量,而非Faiss自動生成的連續整數ID。
| 參數 | 類型 | 說明 |
|---|---|---|
index | faiss.Index | 基礎Faiss索引對象(必填)。 |
own_fields | bool | 是否接管基礎索引的所有權(默認?False)。 |
向量數據庫對象(索引).add_with_ids():?向Faiss索引中添加向量及其對應的自定義ID(需配合IndexIDMap使用),實現通過外部ID檢索向量。
| 參數 | 類型 | 說明 |
|---|---|---|
x | numpy.ndarray | 向量數據,形狀為?(n, d),dtype=float32(必填)。 |
ids | numpy.ndarray | 對應的自定義ID數組,形狀為?(n,),dtype=long(必填)。 |
time.time():返回當前時間的時間戳(自紀元以來的秒數,浮點數形式)。常用于計算代碼執行時間或記錄時間點。
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
D:Distance 兩向量相似度
I:最相似的向量的索引
faiss.write_index():將Faiss索引保存到磁盤文件,支持后續加載復用。
| 參數 | 類型 | 說明 |
|---|---|---|
index | faiss.Index | 要保存的Faiss索引對象(必填)。 |
filename | str | 目標文件路徑(必填)。 |
os.stat():獲取文件或目錄的狀態信息(如大小、修改時間等),返回一個os.stat_result對象。
| 參數 | 類型 | 說明 |
|---|---|---|
path | str 或 bytes | 文件/目錄路徑(必填)。 |
.st_size:從os.stat_result對象中獲取文件的大小(字節)。
def test01():index = faiss.IndexFlatL2(256)index = faiss.IndexIDMap(index)# 添加向量index.add_with_ids(data, ids)# 搜索向量s = time.time()D, I = index.search(query_vector, k=2)print('time1:', time.time() - s)print(D, I)faiss.write_index(index, 'flat.faiss')print("space1:", os.stat('flat.faiss').st_size)4.聚類搜索(指定聚類數目)
?faiss.IndexFlatL2():創建一個使用?L2 距離(歐氏距離)?進行向量相似度搜索的 Faiss 索引。?
| 參數 | 類型 | 描述 |
|---|---|---|
d | int | 向量的維度 |
?歐氏(L2)距離公式:
faiss.IndexIVFFlat():創建基于倒排文件(IVF)和扁平化量化(Flat)的索引結構,用于高效的大規模向量搜索。通過聚類減少搜索空間,顯著提升查詢速度。
| 參數 | 類型 | 說明 |
|---|---|---|
d | int | 向量維度(必填)。 |
nlist | int | 聚類中心數量(必填)。 |
metric | faiss.MetricType | 距離度量方式(默認?faiss.METRIC_L2,即歐氏距離)。 |
use_precomputed_table | int | 是否使用預計算的碼本表(默認?0,不使用)。 |
向量數據庫對象.nprobe():設置或獲取搜索時的探查聚類中心數量(nprobe)。控制搜索時訪問的聚類中心數目,影響查詢速度和精度(值越大越精確,但速度越慢)。
| 參數 | 類型 | 說明 |
|---|---|---|
nprobe | int | 要探查的聚類中心數量(僅用于設置時傳入)。 |
向量數據庫對象.train():對索引進行訓練,需提供一組代表性向量(通常為數據集的子集),用于學習聚類中心或其他模型參數(如量化碼本)。訓練是構建索引的必要步驟。
| 參數 | 類型 | 說明 |
|---|---|---|
xb | numpy.ndarray | 訓練數據矩陣,形狀為?(n_samples, d),其中?d?是向量維度 |
niter | int | 訓練迭代次數(部分索引類型支持,可選) |
verbose | bool | 是否打印訓練日志(可選,默認?False) |
向量數據庫對象.add_with_ids():
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
D:Distance 兩向量相似度
I:最相似的向量的索引
time.time():返回當前時間的時間戳(自紀元以來的秒數,浮點數形式)。常用于計算代碼執行時間或記錄時間點。
faiss.write_index():將Faiss索引保存到磁盤文件,支持后續加載復用。
| 參數 | 類型 | 說明 |
|---|---|---|
index | faiss.Index | 要保存的Faiss索引對象(必填)。 |
filename | str | 目標文件路徑(必填)。 |
os.stat():獲取文件或目錄的狀態信息(如大小、修改時間等),返回一個os.stat_result對象。
| 參數 | 類型 | 說明 |
|---|---|---|
path | str 或 bytes | 文件/目錄路徑(必填)。 |
.st_size:從os.stat_result對象中獲取文件的大小(字節)。
def test02():# 第一個參數 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 聚類中心個數:nlistindex = faiss.IndexFlatL2(256)index = faiss.IndexIVFFlat(index, 256, 100)index.nprobe = 4 # 指定在最相似的前多少個簇中進行線性搜索index.train(data) # 訓練索引,找到所有簇的質心index.add_with_ids(data, ids)s = time.time()D, I = index.search(query_vector, k=2)print('time2:', time.time() - s)print(D, I)faiss.write_index(index, 'ivfflat.faiss')print("space2:", os.stat('ivfflat.faiss').st_size)5.完整代碼
import osimport faiss
import numpy as np
import timenp.random.seed(0)
data = np.random.rand(1000000, 256)
ids = np.arange(0, 1000000)
query_vector = np.random.rand(1, 256)def test01():index = faiss.IndexFlatL2(256)index = faiss.IndexIDMap(index)# 添加向量index.add_with_ids(data, ids)# 搜索向量s = time.time()D, I = index.search(query_vector, k=2)print('time1:', time.time() - s)print(D, I)faiss.write_index(index, 'flat.faiss')print("space1:", os.stat('flat.faiss').st_size)def test02():# 第一個參數 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 聚類中心個數:nlistindex = faiss.IndexFlatL2(256)index = faiss.IndexIVFFlat(index, 256, 100)index.nprobe = 4 # 指定在最相似的前多少個簇中進行線性搜索index.train(data) # 訓練索引,找到所有簇的質心index.add_with_ids(data, ids)s = time.time()D, I = index.search(query_vector, k=2)print('time2:', time.time() - s)print(D, I)faiss.write_index(index, 'ivfflat.faiss')print("space2:", os.stat('ivfflat.faiss').st_size)def test03():# 第一個參 —— 量化參數:quantizer# 第二個參數 —— 向量維度:dim# 第三個參數 —— 質心數量:nlist# 第四個參數 —— 聚類中心個數:ncentroids# 第四個參數 —— 子空間數量(或稱為段數):p 較大的值意味著將原始向量空間劃分為更多的子空間進行量化,有助于減少量化誤差,因為每個子空間都將被更精細地量化。# 第五個參數 —— 量化碼本中碼字的位數,每個段聚類的數量(8位256): q 決定了每個量化碼字的精度,位數越多,每個碼字能夠表示的信息就越多,量化誤差就越小。quantizer = faiss.IndexFlatL2(256)index = faiss.IndexIVFPQ(quantizer, 256, 100, 64, 10)index.nprobe = 4index.train(data)index.add_with_ids(data, ids)# 搜索向量s = time.time()D, I = index.search(query_vector, k=2)print('time3:', time.time() - s)print(D, I)faiss.write_index(index, 'ivfpq.faiss')print("space3:", os.stat('ivfpq.faiss').st_size)if __name__ == '__main__':test01()print("————————————————————————————————")test02()print("————————————————————————————————")test03()
四、GPU訓練
????????傳統 CPU 計算在處理大規模向量數據時往往效率低下,而 GPU 具有并行計算能力強、吞吐量高、延遲低等優勢,可以顯著提高向量相似度搜索的速度。例如:在 Faiss 官方提供的基準測試中,使用 GPU 計算的 Faiss 可以將向量相似度搜索的速度提高數十倍甚至數百倍。
faiss.StandardGpuResources():創建 GPU 資源管理對象,用于在 GPU 上執行 Faiss 操作(如索引構建和搜索)。需配合?index_cpu_to_gpu()?將 CPU 索引轉移到 GPU。
faiss.IndexFlatL2():創建基于 L2 距離(歐氏距離)的暴力搜索索引,直接計算所有向量間的距離。適用于小規模數據或作為其他索引的量化器。
| 參數 | 類型 | 說明 |
|---|---|---|
d | int | 向量維度(必填)。 |
faiss.index_cpu_to_gpu():將 CPU 上的 Faiss 索引轉移到 GPU 上,以加速搜索和訓練操作。需先創建?StandardGpuResources?對象
| 參數 | 類型 | 說明 |
|---|---|---|
res | faiss.StandardGpuResources | GPU 資源對象(必填)。 |
device | int | GPU 設備 ID(默認?0)。 |
index | faiss.Index | 要轉移的 CPU 索引(必填)。 |
sync | bool | 是否同步 GPU 操作(默認?True)。 |
向量數據庫對象(索引).search():在向量數據庫(索引)中搜索最相似的?k?個向量。
| 參數 | 類型 | 描述 |
|---|---|---|
xq | np.array | 查詢向量(形狀?(m, d)) |
k | int | 返回的最近鄰數量 |
向量數據庫對象(索引).add():向向量數據庫(索引)中添加向量數據。
| 參數 | 類型 | 描述 |
|---|---|---|
xb | np.array | 待添加的向量數組(形狀?(n, d)) |
np.random.rand():生成指定形狀的數組,元素從均勻分布 [0, 1) 中隨機采樣。
| 參數 | 類型 | 說明 |
|---|---|---|
d0, d1, ..., dn | int, 可選 | 定義輸出數組的維度。若無參數,返回單個浮點數。 |
D:Distance 兩向量相似度
I:最相似的向量的索引?
import faiss
import numpy as npdef test():# 創建標準的 GPU 資源對象,用它來管理GPU相關的計算資源。res = faiss.StandardGpuResources()# 1. 在 CPU 創建索引index_cpu = faiss.IndexFlatL2(256)print(index_cpu)# 2. 將索引轉到 GPU# 參數1:GPU 使用資源# 參數2:GPU 設備編號# 參數3:轉移的索引index_gpu = faiss.index_cpu_to_gpu(res, 0, index_cpu)print(index_gpu)# 3. 插入數據index_gpu.add(np.random.rand(100000, 256))# 4. 向量搜索D, I = index_gpu.search(np.random.rand(2, 256), k=2)print(D)print(I)if __name__ == '__main__':test()

![[ 計算機網絡 ] | 宏觀談談計算機網絡](http://pic.xiahunao.cn/[ 計算機網絡 ] | 宏觀談談計算機網絡)








)





)

