原文地址
1.核心理論:貝葉斯多感官整合框架
目標:結合視覺線索 c v i c_{vi} cvi?和前庭線索 c v e c_{ve} cve?來估計頭部方向或位置 θ
貝葉斯公式
p ( θ ∣ c v i , c v e ) ∝ p ( c v i ∣ θ ) p ( c v e ∣ θ ) p ( θ ) p(\theta | c_{vi}, c_{ve}) \propto p(c_{vi} | \theta)p(c_{ve} | \theta)p(\theta) p(θ∣cvi?,cve?)∝p(cvi?∣θ)p(cve?∣θ)p(θ)
- p ( θ ∣ c v i , c v e ) p(\theta | c_{vi}, c_{ve}) p(θ∣cvi?,cve?):給定所有線索后, θ \theta θ 的后驗概率分布。
- p ( c v i ∣ θ ) / p ( c v e ∣ θ ) p(c_{vi} | \theta) / p(c_{ve} | \theta) p(cvi?∣θ)/p(cve?∣θ):觀察到線索 c v i / c v e c_{vi} / c_{ve} cvi?/cve? 的可能性,取決于真實狀態 θ \theta θ。
- p ( θ ) p(\theta) p(θ): θ \theta θ 的先驗概率(初始信念)。
簡化假設:
- 沒有先驗時 p ( θ ) p(\theta) p(θ)均勻分布即為1。
- 視覺和前庭線索的噪聲相互獨立。
時間迭代:
p t ( θ ∣ c v i , c v e ) ∝ p t ( c v i ∣ θ ) p t ( c v e ∣ θ ) p t ? 1 ( θ ∣ c v i , c v e ) p^t(\theta \mid c_{vi}, c_{ve}) \propto p^t(c_{vi} \mid \theta)p^t(c_{ve} \mid \theta)p^{t-1}(\theta \mid c_{vi}, c_{ve}) pt(θ∣cvi?,cve?)∝pt(cvi?∣θ)pt(cve?∣θ)pt?1(θ∣cvi?,cve?)
將當前時刻的線索與上一時刻的后驗信念結合。
這個公式可以拆分為路徑積分和地標校準:
路徑積分 (Path Integration)
- 利用前庭/運動線索更新估計。
- 對應于貝葉斯框架中的前庭線索更新:
p t ( θ ∣ c v i , c v e ) ∝ p t ( c v e ∣ θ ) p t ? 1 ( θ ∣ c v i , c v e ) p^t(\theta | c_{vi}, c_{ve}) \propto p^t(c_{ve} | \theta)p^{t-1}(\theta | c_{vi}, c_{ve}) pt(θ∣cvi?,cve?)∝pt(cve?∣θ)pt?1(θ∣cvi?,cve?)
模擬動物根據自身運動(步數、速度)不斷更新位置的過程。
地標校準 (Landmark Calibration)
- 利用視覺線索(熟悉地標)修正估計。
- 對應于貝葉斯框架中的視覺線索更新:
p t ( θ ∣ c v i , c v e ) ∝ p t ( c v i ∣ θ ) p t ? 1 ( θ ∣ c v i , c v e ) p^t(\theta \mid c_{vi}, c_{ve}) \propto p^t(c_{vi} \mid \theta)p^{t-1}(\theta \mid c_{vi}, c_{ve}) pt(θ∣cvi?,cve?)∝pt(cvi?∣θ)pt?1(θ∣cvi?,cve?)
當看到熟悉的景象時,調整內部地圖以匹配外部世界。
2.模型架構
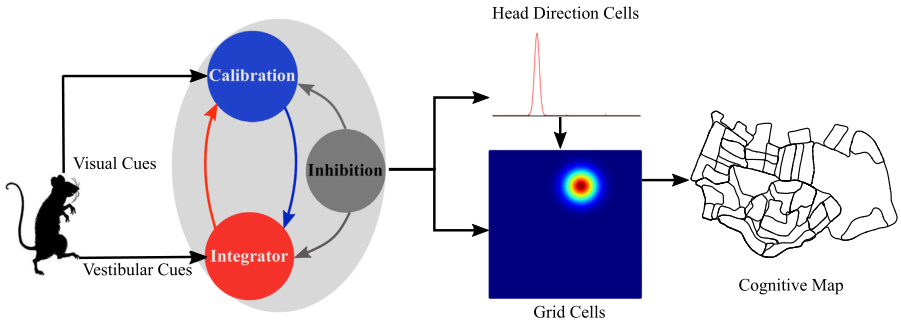 該圖展示了模型的貝葉斯吸引子網絡架構及其信息流動圖表。
該圖展示了模型的貝葉斯吸引子網絡架構及其信息流動圖表。
- 頭部方向細胞(Head Direction Cells)編碼方向。
- 網格細胞(Grid Cells)編碼位置。
來自前庭線索和視覺線索的信息分別由整合細胞(Integrator Cells)和校準細胞(Calibration Cells)整合。
- 整合細胞接收前庭路徑積分信息。
- 校準細胞接受視覺校準信息。
當線索沖突出現時,這兩種細胞通過相互抑制和全局抑制來解決沖突,從而在網絡中產生單峰活動。頭部方向細胞網絡中編碼的方向被用于網格細胞網絡中編碼代理的位置。基于網格細胞網絡提供的位置信息,構建了一個認知地圖。
2.1 HD細胞網絡
2.1.1表示:
- 每個細胞群體(整合細胞和校準細胞)維護一個一維高斯分布 p ( θ ) p(\theta) p(θ) 來表示對頭部方向的信念。
p ( θ ) = 1 σ 2 π e ? ∣ θ ? μ ∣ 2 / 2 σ 2 p(\theta) = \frac{1}{\sigma\sqrt{2\pi}} e^{-|\theta - \mu|^2 / 2\sigma^2} p(θ)=σ2π?1?e?∣θ?μ∣2/2σ2
- μ \mu μ:方向的最大似然估計(均值),代表當前頭部方向
- σ 2 \sigma^2 σ2:信念的不確定性(方差)
2.1.2 吸引子動力學
全局抑制:限制整體活動水平,防止過度興奮。
1 ( σ inte t ) 2 = E W ( σ inte t ? 1 ) 2 , 1 ( σ cali t ) 2 = E W ( σ cali t ? 1 ) 2 \frac{1}{(\sigma_{\text{inte}}^{t})^{2}} = \frac{E}{W(\sigma_{\text{inte}}^{t-1})^{2}}, \quad \frac{1}{(\sigma_{\text{cali}}^{t})^{2}} = \frac{E}{W(\sigma_{\text{cali}}^{t-1})^{2}} (σintet?)21?=W(σintet?1?)2E?,(σcalit?)21?=W(σcalit?1?)2E?
- W W W 是總信息量
- E E E 是預設的總信息量上限
相互抑制:確保網絡中只有一個穩定的“活動包”(單峰)占據主導地位。
1 ( σ inte t ) 2 = 1 ( σ inte t ? 1 ) 2 ? Δ inte 1 ( σ cali t ? 1 ) 2 , 1 ( σ cali t ) 2 = 1 Δ cali 1 ( σ inte t ? 1 ) 2 \frac{1}{(\sigma_{\text{inte}}^{t})^{2}} = \frac{1}{(\sigma_{\text{inte}}^{t-1})^{2}} - \Delta_{\text{inte}} \frac{1}{(\sigma_{\text{cali}}^{t-1})^{2}}, \quad \frac{1}{(\sigma_{\text{cali}}^{t})^{2}} = \frac{1}{\Delta_{\text{cali}}} \frac{1}{(\sigma_{\text{inte}}^{t-1})^{2}} (σintet?)21?=(σintet?1?)21??Δinte?(σcalit?1?)21?,(σcalit?)21?=Δcali?1?(σintet?1?)21?
- Δ inte \Delta_{\text{inte}} Δinte? 和 Δ cali \Delta_{\text{cali}} Δcali? 控制抑制強度
2.1.3路徑積分更新
μ i n t e t = mod ( μ i n t e t ? 1 + v t Δ t , 2 π ) \mu_{inte}^t = \text{mod}(\mu_{inte}^{t-1} + v^t \Delta t, 2\pi) μintet?=mod(μintet?1?+vtΔt,2π)
μ c a l l t = mod ( μ c a l l t ? 1 + v t Δ t , 2 π ) \mu_{call}^t = \text{mod}(\mu_{call}^{t-1} + v^t \Delta t, 2\pi) μcallt?=mod(μcallt?1?+vtΔt,2π)
- v t v^t vt:來自前庭系統的速度信息。
- 由于方向具有周期性,故對 2 π 2\pi 2π取mod。
2.1.4視覺校準更新
當檢測到熟悉視覺場景時,校準細胞接收注入能量 p inject ( θ ) p_{\text{inject}}(\theta) pinject?(θ)。
1 ( σ cali t ) 2 = 1 ( σ cali t ? 1 ) 2 + 1 ( σ inject t ) 2 \frac{1}{(\sigma^t_{\text{cali}})^2} = \frac{1}{(\sigma^{t-1}_{\text{cali}})^2} + \frac{1}{(\sigma^t_{\text{inject}})^2} (σcalit?)21?=(σcalit?1?)21?+(σinjectt?)21?
μ cali t = mod ( ( σ cali t ) 2 ( σ cali t ? 1 ) 2 μ cali t ? 1 + ( σ cali t ) 2 ( σ inject t ) 2 μ inject t , 2 π ) \mu^t_{\text{cali}} = \text{mod}\left( \frac{(\sigma^t_{\text{cali}})^2}{(\sigma^{t-1}_{\text{cali}})^2} \mu^{t-1}_{\text{cali}} + \frac{(\sigma^t_{\text{cali}})^2}{(\sigma^t_{\text{inject}})^2} \mu^t_{\text{inject}} \,,\, 2\pi \right) μcalit?=mod((σcalit?1?)2(σcalit?)2?μcalit?1?+(σinjectt?)2(σcalit?)2?μinjectt?,2π)
- σ inject t \sigma^{t}_{\text{inject}} σinjectt?:注入能量的標準差
- μ inject t \mu^{t}_{\text{inject}} μinjectt?:注入能量的均值(預期校準方向)
最終信念是整合細胞和校準細胞信念的融合:
1 ( σ f t ) 2 = 1 ( σ inte t ) 2 + 1 ( σ cali t ) 2 \frac{1}{(\sigma_f^t)^2} = \frac{1}{(\sigma_{\text{inte}}^t)^2} + \frac{1}{(\sigma_{\text{cali}}^t)^2} (σft?)21?=(σintet?)21?+(σcalit?)21?
μ f t = mod ( ( σ f t ) 2 ( σ inte t ) 2 μ inte t + ( σ f t ) 2 ( σ cali t ) 2 μ cali t , 2 π ) \mu_f^t = \text{mod} \left( \frac{(\sigma_f^t)^2}{(\sigma_{\text{inte}}^t)^2} \mu_{\text{inte}}^t + \frac{(\sigma_f^t)^2}{(\sigma_{\text{cali}}^t)^2} \mu_{\text{cali}}^t \,,\, 2\pi \right) μft?=mod((σintet?)2(σft?)2?μintet?+(σcalit?)2(σft?)2?μcalit?,2π)
- σ f t \sigma_f^t σft?:綜合不確定性的標準差
- μ f t \mu_f^t μft?:綜合方向估計(整合與校準的加權融合結果)
- 公式說明:
- 第一條公式體現整合(路徑積分)和校準(地標修正)不確定性的加權調和平均
- 第二條公式通過方差倒數作為權重,融合整合細胞( μ inte t \mu_{\text{inte}}^t μintet?)和校準細胞( μ cali t \mu_{\text{cali}}^t μcalit?)的估計
2.2 網格細胞網絡
2.2.1表示
- 類似于 HD 網絡,但使用二維高斯分布 p ( x , y ) p(x, y) p(x,y) 來表示對位置的信念。
p ( x , y ) = 1 2 π σ x σ y e ? ( ( x ? μ x ) 2 2 σ x 2 + ( y ? μ y ) 2 2 σ y 2 ) p(x, y) = \frac{1}{2\pi\sigma_x\sigma_y} e^{-\left( \frac{(x - \mu_x)^2}{2\sigma_x^2} + \frac{(y - \mu_y)^2}{2\sigma_y^2} \right)} p(x,y)=2πσx?σy?1?e?(2σx2?(x?μx?)2?+2σy2?(y?μy?)2?)
- ( μ x , μ y ) (\mu_x, \mu_y) (μx?,μy?):位置的最大似然估計(均值),代表機器人在物理空間中的位置
- σ x 2 , σ y 2 \sigma_x^2, \sigma_y^2 σx2?,σy2?:信念在兩個維度上的不確定性
2.2.2神經空間
- 采用具有周期性邊界條件的二維神經空間(環面吸引子)。
- ( x , y ) ∈ [ 0 , 2 π ) (x, y) \in [0, 2\pi) (x,y)∈[0,2π)
- 均值 ( μ x , μ y ) (\mu_x, \mu_y) (μx?,μy?) 編碼的實際位置需要通過解卷繞(unwrapping)操作來恢復
2.2.3更新機制
機制與HD網絡類似,但作用于二維位置。
3 系統實現
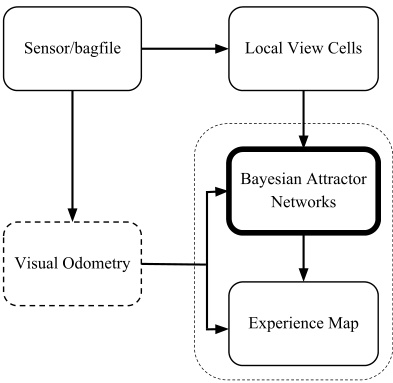
圖片展示了NeuroBayesSLAM系統的軟件架構。傳感器/bagfile節點提供圖像和里程計信息。視覺里程計為純視覺數據集提供速度估計。局部視圖單元節點確定當前視圖是否熟悉。貝葉斯吸引子網絡節點執行路徑積分并做出環閉合決策。經驗地圖節點生成拓撲地圖。整個系統通過這些組件協同工作,實現對環境的建模和導航。

)

















)