查找算法
基本查找(也叫順序查找,線性查找)
二分查找(需要有序數據)
public static int binarySearch(int[] arr, int number){//1.定義兩個變量記錄要查找的范圍int min = 0;int max = arr.length - 1;//2.利用循環不斷的去找要查找的數據while(true){if(min > max){return -1;}//3.找到min和max的中間位置int mid = (min + max) / 2;//4.拿著mid指向的元素跟要查找的元素進行比較if(arr[mid] > number){//4.1 number在mid的左邊//min不變,max = mid - 1;max = mid - 1;}else if(arr[mid] < number){//4.2 number在mid的右邊//max不變,min = mid + 1;min = mid + 1;}else{//4.3 number跟mid指向的元素一樣//找到了return mid;}}}
插值查找(二分查找改進1)
為什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?
其實就是因為方便,簡單,但是如果我能在二分查找的基礎上,讓中間的mid點,盡可能靠近想要查找的元素,那不就能提高查找的效率了嗎?
mid = min ? + key ? arr [ min ? ]  ̄ arr [ max ? ] ? arr [ min ? ] ? ( max ? ? min ? ) \text{mid} = \min + \frac{\underline{\text{key} - \text{arr}[\min]}}{\text{arr}[\max] - \text{arr}[\min]} \cdot (\max - \min) mid=min+arr[max]?arr[min]key?arr[min]???(max?min)
中間這個為key的大小在查找范圍中的比例(因為是有序的列表)
max-min是獲取比例對應的索引
min+為設置基數注意:需要有序數據分布較為均勻
斐波那契查找(二分查找改進2)

和二分查找類似,只是使用的不是二分,而是黃金分割比
步驟:
1.先生成一個斐波那契數列 f[]
2.找到查找數組長度,找到最小的f[n]使得查找數組的長度 <= f[n]-1 (f[n-1]-1 + f[n-2]-1 + 1 = f[n]-1) ,長度沒到需要將最大值補齊
3.經典初始化三件套int low = 0; int high = arr.length - 1; int mid = 0; 還要加上 int index = n;用來表示這個兔子數列的下標
4.如果比mid小就將index-=1,如果比mid大就-=2,同時調整上下限
5.最后找到輸出,如果是補齊的元素輸出最大元素的原下標
困惑點:
為什么采用f[]-1的形式呢?
**我的理解:**是為了將mid提取為一個部分,剛好可以將原數組分割成f[n-1]-1、mid、f[n-2]-1,三部分,且前后兩個部分又是 f[]-1 的格式,便于代碼的書寫,也方便實現遞歸與循環。
參考代碼:
public class FeiBoSearchDemo {public static int maxSize = 20;public static void main(String[] args) {int[] arr = {1, 8, 10, 89, 1000, 1234};System.out.println(search(arr, 1234));}public static int[] getFeiBo() {int[] arr = new int[maxSize];arr[0] = 1;arr[1] = 1;for (int i = 2; i < maxSize; i++) {arr[i] = arr[i - 1] + arr[i - 2];}return arr;}public static int search(int[] arr, int key) {int low = 0;int high = arr.length - 1;//表示斐波那契數分割數的下標值int index = 0;int mid = 0;//調用斐波那契數列int[] f = getFeiBo();//獲取斐波那契分割數值的下標while (high > (f[index] - 1)) {index++;}//因為f[k]值可能大于a的長度,因此需要使用Arrays工具類,構造一個新法數組,并指向temp[],不足的部分會使用0補齊int[] temp = Arrays.copyOf(arr, f[index]);//實際需要使用arr數組的最后一個數來填充不足的部分for (int i = high + 1; i < temp.length; i++) {temp[i] = arr[high];}//使用while循環處理,找到key值while (low <= high) {mid = low + f[index - 1] - 1;if (key < temp[mid]) {//向數組的前面部分進行查找high = mid - 1;/*對k--進行理解1.全部元素=前面的元素+后面的元素2.f[k]=k[k-1]+f[k-2]因為前面有k-1個元素沒所以可以繼續分為f[k-1]=f[k-2]+f[k-3]即在f[k-1]的前面繼續查找k--即下次循環,mid=f[k-1-1]-1*/index--;} else if (key > temp[mid]) {//向數組的后面的部分進行查找low = mid + 1;index -= 2;} else {//找到了//需要確定返回的是哪個下標if (mid <= high) {return mid;} else {return high;}}}return -1;}
}
查找算法對比分析:斐波那契查找、二分查找與插值查找
在有序數組中,常見的查找算法包括二分查找、斐波那契查找和插值查找。它們都屬于分治類算法,但在分割策略、依賴條件和適用場景上存在差異。以下通過算法原理、時間復雜度、數據分布依賴性及優缺點等方面進行詳細對比,并重點說明斐波那契查找優于二分查找的場景。
算法原理
- 二分查找:在已排序的數組中,每次將待查范圍對半分,檢查中間位置的元素與目標比較,根據大小關系決定向左或向右繼續查找。該算法實現簡單,每次都能排除一半區間,時間復雜度為 O ( log ? n ) O(\log n) O(logn)。
- 斐波那契查找:利用斐波那契數列來分割搜索區間,首先找到不小于數組長度的最小斐波那契數 F m F_m Fm?,然后使用 F m ? 2 F_{m-2} Fm?2? 作為索引偏移量進行比較。相比二分查找固定的“平分”策略,斐波那契查找將區間劃分為相鄰兩個斐波那契數之和的比例(約為黃金比例1:1.618)。查找時根據比較結果調整索引和剩余區間長度,通過加法、減法更新斐波那契數并繼續搜索。斐波那契查找的平均和最壞時間復雜度均為 O ( log ? n ) O(\log n) O(logn),但平均需要執行約4%的額外比較(即比較次數略多)。
- 插值查找:適用于已排序且鍵值大致均勻分布的數值數組。它根據待查值相對于當前區間端點的比例,用線性插值公式估算目標可能的位置 p o s = l o + ( k e y ? a r r [ l o ] ) × ( h i g h ? l o ) a r r [ h i ] ? a r r [ l o ] pos=lo+\frac{(key-arr[lo])\times(high-lo)}{arr[hi]-arr[lo]} pos=lo+arr[hi]?arr[lo](key?arr[lo])×(high?lo)?。不同于二分查找總是檢查中點,插值查找會根據關鍵字值直接跳向估計位置。如果分布均勻,插值查找平均定位更接近目標,從而減少比較次數;若估算位置不準確,則退化為縮小區間的二分或線性查找方式。插值查找的平均時間復雜度可達到 O ( log ? log ? n ) O(\log\log n) O(loglogn)(對數的對數),而最壞情況下可退化至 O ( n ) O(n) O(n)。
時間復雜度與效率比較
三種算法的理論時間復雜度如下表所示:二分查找和斐波那契查找在平均及最壞情況下均為 O ( log ? n ) O(\log n) O(logn),而插值查找在理想(均勻分布)情況平均為 O ( log ? log ? n ) O(\log\log n) O(loglogn),但最壞可達 O ( n ) O(n) O(n)。
| 算法 | 平均時間復雜度 | 最壞時間復雜度 |
|---|---|---|
| 二分查找 | O ( log ? n ) O(\log n) O(logn) | O ( log ? n ) O(\log n) O(logn) |
| 斐波那契查找 | O ( log ? n ) O(\log n) O(logn) | O ( log ? n ) O(\log n) O(logn) |
| 插值查找 | O ( log ? log ? n ) O(\log\log n) O(loglogn) | O ( n ) O(n) O(n) |
從比較次數上看,二分查找每步半分區間,斐波那契查找劃分比例略偏向一端,導致斐波那契查找平均比較次數略多。插值查找在數據非常均勻時平均比較次數最少,但需要做乘除運算來估算位置,實際效率取決于計算開銷與數據分布。在現代硬件上,二分查找計算中間下標可用位運算完成,與斐波那契查找使用加減法的硬件成本差距很小。
數據分布依賴性
- 二分查找:只要求數據有序,不依賴數值分布。無論數據是均勻還是極端分布,二分查找的行為都是固定的,每次訪問中點。
- 斐波那契查找:同樣只要求有序,與數據分布無關。其查找過程由斐波那契數列決定,只關注索引位置,不考慮數值大小分布。
- 插值查找:高度依賴數據分布。插值查找假設關鍵字按數值線性分布,才能準確估算目標位置。當數據均勻時插值查找效率遠優于二分;若分布不均勻(如指數增長或大量重復鍵),插值估算可能誤差大,導致多次不準確探測,從而退化為 O ( n ) O(n) O(n)。如表所示,插值查找對“均勻分布”這一前提要求很高,否則不推薦使用。
優缺點對比
下表總結了三種算法的主要優缺點對比:
| 算法 | 主要優點 | 主要缺點 |
|---|---|---|
| 二分查找 | 簡單易實現;查找過程穩定,時間復雜度始終為 O ( log ? n ) O(\log n) O(logn) | 只適用于有序數據;每次固定平分,未利用數據分布信息;對順序存取介質(如磁帶)不友好 |
| 斐波那契查找 | 時間復雜度也是 O ( log ? n ) O(\log n) O(logn);無需除法,僅用加減運算,可降低硬件成本;訪問位置更靈活(近似斐波比分割),對大數據集的內存局部性較好 | 實現較復雜,需要生成斐波那契數列;平均比較次數略多于二分(約多4%);對數據分布同樣無依賴,無法利用均勻分布優勢 |
| 插值查找 | 均勻分布時效率極高,平均比較次數僅為 O ( log ? log ? n ) O(\log\log n) O(loglogn);可快速接近目標位置 | 僅適用于數值型且分布均勻的有序數據;數據分布偏差大時退化為 O ( n ) O(n) O(n);實現需進行乘除法計算 |
除上述比較,三者在實現上額外空間均為常數級,查找過程中僅需幾個索引變量。
斐波那契查找優勢場景
雖然斐波那契查找在比較次數上不及二分查找,它在一些特定條件下具有優勢:
- 非均勻訪問存儲:當數據存儲在磁盤或磁帶等介質上時,訪問不同位置的開銷不一樣。斐波那契查找傾向于先訪問與上次訪問位置接近的元素,因此可以減少尋道(磁頭移動)距離。例如,在磁盤上從位置1到位置2比從位置1到位置3更快;二分查找若每次跳躍范圍較大,可能導致磁頭頻繁大范圍移動,而斐波那契查找更小的跳躍平均可減小尋道時間。
- 緩存友好性:如果處理器使用直接映射緩存,二分查找由于頻繁訪問固定模式的數組索引,容易集中落在少數緩存行,增加未命中概率。斐波那契查找的分割點不是2的冪次,所以訪問位置更為分散,可降低緩存沖突。此外,當數組特別大無法全部放入高速緩存時,斐波那契查找訪問的元素相對更靠近(具有更好的局部性),對緩存性能更友好。
- 算術運算成本:歷史上,計算機硬件中除法運算比加法和位移運算要慢。斐波那契查找只用加減法計算索引,而二分查找需要做除法或右移來取中點,因此在老舊硬件上可能略有性能優勢。但在現代處理器上,位移運算和加法的成本相當,這一點優勢已不顯著。
綜上所述,當查找操作發生在對尋址開銷敏感的存儲設備上(如旋轉磁盤或磁帶)時,或在對緩存局部性要求較高的大規模數據集上,斐波那契查找可能優于二分查找。它在這些場景下通過減少遠距離內存訪問,實現了平均尋址時間的微小改善。然而,對于一般內存中的有序數組,現代系統上二分查找因實現簡單且效率高,仍然是首選方法。
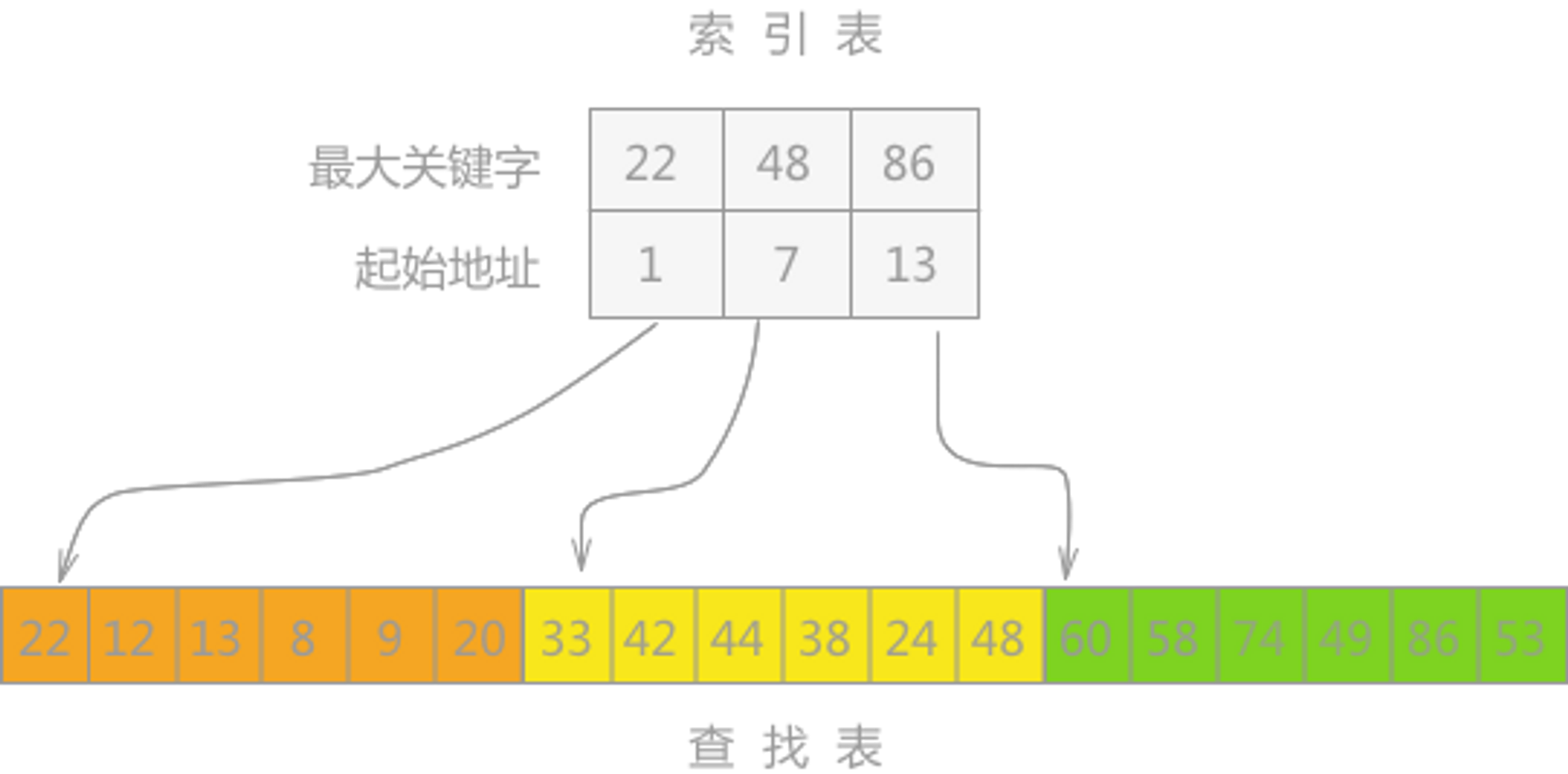
分塊查找
核心思想
- 塊內無序:每個子塊內部無需排序。
- 塊間有序:所有屬于第 i i i 塊的元素均小于所有屬于第 i + 1 i+1 i+1 塊的元素。(我很好奇,真有這樣的數據嗎?)
- 索引表:維護一個長度約為 n \sqrt{n} n? 的索引數組,每項記錄對應塊的最大關鍵字(或最小關鍵字)及該塊的起始下標,用于快速定位目標塊。
實現步驟
1. 分塊預處理
-
確定塊大小 s s s
s = ? n ? s \;=\;\lceil\sqrt{n}\rceil s=?n??
-
劃分塊數
塊數 = ? n / s ? ≈ n \text{塊數} \;=\;\bigl\lceil n/s\bigr\rceil \;\approx\;\sqrt{n} 塊數=?n/s?≈n?
-
構建索引表
我也想知道,黑馬教程直接就手動構建了
2. 查找流程
-
定位塊
- 在索引表中順序或二分查找,找到第一個“塊最大關鍵字 ≥ 目標值” 的塊編號 b b b。
-
塊內順序掃描
- 在原表下標區間 [ L b , R b ] [L_b,R_b] [Lb?,Rb?] 執行簡單線性查找,若找到則返回下標,否則返回 ? 1 -1 ?1。
復雜度分析
-
時間復雜度
- 索引查找:順序 O ( n ) O(\sqrt{n}) O(n?),二分 O ( log ? n ) O(\log\sqrt{n}) O(logn?)。
- 塊內掃描:最壞 O ( n ) O(\sqrt{n}) O(n?)。
- 總計: O ( n ) O(\sqrt{n}) O(n?)。
-
空間復雜度
- 原表: O ( n ) O(n) O(n)。
- 索引表: O ( n ) O(\sqrt{n}) O(n?)。
適用場景
- 靜態查找:數據不發生插入/刪除,或僅偶爾重建索引。
- 數據量中等( 10 4 ~ 10 7 10^4\sim10^7 104~107 級別)時,比線性查找更快,比完全排序的二分查找實現更簡單。
- 對存儲局部有序但全局大規模有序的場景(如日志分段、分批歸檔)非常合適。
困惑(待解決)
我看了黑馬的教程還是不知道這個分塊要如何進行,他似乎是直接調整原索引(在優化塊時)而且數據也非常切合?
上網搜索時也發現講解的人舉得例子似乎全是為了貼合這個分塊思想設計的(如下圖):似乎這個查找只是想告訴我們這個分治的思想
哈希查找
哈希查找利用哈希函數將關鍵字(Key)映射到表(數組)中的下標,從而實現平均情況下 O(1) 的查找、插入和刪除效率。核心難點在于設計良好的哈希函數和高效的沖突處理策略。
1. 原理與結構
1.1 哈希表(Hash Table)
- 表結構:通常用一個定長數組
table[]存儲數據槽(bucket)。 - 映射關系:每個元素的關鍵字
key經哈希函數h(key)計算后,得到一個索引idx = h(key) % M,M 為表長。
1.2 哈希函數(Hash Function)
-
目標:將任意長度輸入均勻分布到
[0, M)的整數區間。 -
性質:
- 確定性:相同輸入總映射到相同輸出。
- 均勻性:輸入在哈希域上盡可能均勻分布,減少沖突概率。
-
常見實現:
-
對字符串:
hash = ∑ (s[i] * p^i) mod P,再對表長取模。 -
對整數:
h(x) = ((x * A) mod 2^w) >> (w ? p)(乘法哈希)。- 字符串的多項式滾動哈希
- 整數的乘法哈希(Multiply-Shift)
在深入細節前,先簡要概述:
- 多項式滾動哈希 通過將字符串視為多項式的系數,將字符值乘以底數的不同冪次后累加,再對大素數取模,以獲得分布均勻且方便滾動更新的哈希值。
- 乘法哈希 則利用鍵與一個隨機奇數常數相乘,并在機器字長范圍內取模,再右移若干位,直接提取高位以獲得哈希索引。
多項式滾動哈希(Polynomial Rolling Hash)
哈希公式
hash = ( ∑ i = 0 n ? 1 ( val ( s [ i ] ) × p i ) ) m o d P , index = hash m o d M \text{hash} = \biggl(\sum_{i=0}^{n-1} \bigl(\text{val}(s[i]) \times p^i\bigr)\bigr)\bmod P \quad,\quad \text{index} = \text{hash} \bmod M hash=(i=0∑n?1?(val(s[i])×pi))modP,index=hashmodM
各部分含義
- s [ i ] s[i] s[i]:字符串中第 i i i 個字符,通常映射為一個整數值(例如 ASCII 或 Unicode 碼點)。這一映射保證不同字符產生不同的數值輸入。
- val ( s [ i ] ) \text{val}(s[i]) val(s[i]):將字符 s [ i ] s[i] s[i] 轉為數值后的結果,用作多項式的系數。
- p i p^i pi:底數 p p p 的第 i i i 次冪,用于賦予字符串中不同位置不同的權重。選擇合適的 p p p(通常是一個質數或 31, 131 等)可使散列值分布更均勻。
- 求和 ∑ \sum ∑:累加所有字符對應的加權值,等價于將字符串視為系數構成的多項式在點 p p p 處的取值。
- 取模 P P P:對一個較大的素數 P P P 取模,既可防止累加結果溢出,又能利用模運算的良好隨機性減少碰撞。常選 Mersenne 素數或接近機器字長的素數,如 2 61 ? 1 2^{61}-1 261?1。
- 最終索引 m o d M \bmod\,M modM:將模 P P P 后的哈希值再次對表長 M M M 取模,以映射到哈希表的實際槽位范圍 [ 0 , M ) [0, M) [0,M)。
示例 1:多項式滾動哈希(字符串)
目標:計算字符串
"abc"的哈希值。設定參數:
- 字符串:
"abc" - 字符編碼:使用 ASCII 值
- 基數 p = 31 p = 31 p=31
- 模數 P = 10 9 + 7 P = 10^9 + 7 P=109+7
計算過程:
- 將每個字符轉換為對應的 ASCII 值:
'a'→ 97'b'→ 98'c'→ 99
- 應用多項式哈希公式:
hash = ( 97 × 31 0 + 98 × 31 1 + 99 × 31 2 ) m o d 10 9 + 7 \text{hash} = (97 \times 31^0 + 98 \times 31^1 + 99 \times 31^2) \mod 10^9 + 7 hash=(97×310+98×311+99×312)mod109+7
- 逐步計算:
- 97 × 1 = 97 97 \times 1 = 97 97×1=97
- 98 × 31 = 3038 98 \times 31 = 3038 98×31=3038
- 99 × 961 = 95139 99 \times 961 = 95139 99×961=95139 (因為 31 2 = 961 31^2 = 961 312=961)
- 累加并取模:
hash = ( 97 + 3038 + 95139 ) m o d 10 9 + 7 = 98274 \text{hash} = (97 + 3038 + 95139) \mod 10^9 + 7 = 98274 hash=(97+3038+95139)mod109+7=98274
結果:字符串
"abc"的哈希值為 98274。乘法哈希(Multiply-Shift Method)
哈希公式
h ( x ) = ( ( A × x ) m o d 2 w ) ? ( w ? p ) h(x) = \bigl((A \times x)\bmod 2^w \bigr)\; \gg\;(w - p) h(x)=((A×x)mod2w)?(w?p)
其中表長 m = 2 p m = 2^p m=2p,機器字長為 w w w。(32位,64位)
各部分含義
- x x x:待哈希的整數鍵,假設能用一個 w w w-位字存儲。
- 常數 A A A:選取一個奇整數,滿足 2 w ? 1 < A < 2 w 2^{w-1} < A < 2^w 2w?1<A<2w。奇數確保與 2 w 2^w 2w 的可逆性,進而使高位更“隨機”
- 乘法 ( A × x ) (A \times x) (A×x):將鍵與常數相乘,相當于線性變換,能很好地打散輸入數據。
- 模 2 w 2^w 2w:在機器字長范圍內自動截斷(或通過按位與 ( 2 w ? 1 ) (2^w - 1) (2w?1) 實現),等價于僅保留乘積的低 w w w 位。此步驟非常高效。
不需顯式寫
mod 2^32,而是溢出擴展:
當編譯器遇到源代碼中顯式對非硬件自然寬度的“? m o d 2 k \bmod 2^k mod2k”操作時,若 kkk 與表長或掩碼相關,它通常識別出冪次性質,并用一次按位與(AND)或右移(>>)來替代除法/取模
例如:// 原始 r = x % 256; // 優化后 r = x & 0xFF;這一步驟是在編譯時完成的
- 右移 ? ( w ? p ) \gg (w - p) ?(w?p):將得到的 w w w 位值向右移動 w ? p w - p w?p 位,相當于取乘積的高 p p p 位,作為哈希表的索引。取高位而非低位能更均勻地利用乘法產生的位混合效果。
- 參數 p p p:滿足表長 m = 2 p m = 2^p m=2p;因而最終索引范圍為 [ 0 , 2 p ) [0, 2^p) [0,2p)。
表長為何常取 m = 2 p m = 2^p m=2p?
- 簡化索引提取:若哈希表長度 m = 2 p m=2^p m=2p,則將 ( A × x ) m o d 2 w (A \times x)\bmod 2^w (A×x)mod2w 的高 p p p 位右移 ( w ? p ) (w-p) (w?p) 位,即可直接得到范圍 [ 0 , 2 p ) [0,2^p) [0,2p) 之間的索引:
h ( x ) = ( ( A ? x ) m o d 2 w ) ? ( w ? p ) . h(x) \;=\; \bigl((A\cdot x)\bmod 2^w\bigr)\;\gg\;(w-p). h(x)=((A?x)mod2w)?(w?p).
位移操作比任意模除更快,也易于硬件優化
-
位掩碼替代:如果想使用低 p p p 位,也可以對 2 p ? 1 2^p-1 2p?1 做位與運算,效果等同于對 2 p 2^p 2p 取模,同樣高效
-
非冪次情況:理論上的乘法哈希(如 CLRS 中描述的多項式乘法法)并不強制要求表長是 2 p 2^p 2p,而是可先算出一個實數乘積的分數部分再乘以任意 m m m 并取底。但若要用純整數、位運算高效實現,就幾乎都選 m = 2 p m=2^p m=2p 來避免除法
示例 2:乘法哈希(整數)
目標:計算整數鍵
123456的哈希索引。設定參數:
- 鍵值:
123456 - 常數 A = 2654435769 A = 2654435769 A=2654435769(Knuth 推薦的乘數)
- 機器字長 w = 32 w = 32 w=32
- 哈希表大小 m = 2 8 = 256 m = 2^8 = 256 m=28=256
計算過程:
- 計算乘積并取模 2 32 2^{32} 232:
( 123456 × 2654435769 ) m o d 2 32 (123456 \times 2654435769) \mod 2^{32} (123456×2654435769)mod232
- 將結果右移 32 ? 8 = 24 32 - 8 = 24 32?8=24 位,提取高位作為哈希索引:
hash = ( ( 123456 × 2654435769 ) m o d 2 32 ) ? 24 \text{hash} = \left( (123456 \times 2654435769) \mod 2^{32} \right) \gg 24 hash=((123456×2654435769)mod232)?24
- 假設計算結果為
0x12345678,則:
hash = 0 x 12345678 ? 24 = 0 x 12 = 18 \text{hash} = 0x12345678 \gg 24 = 0x12 = 18 hash=0x12345678?24=0x12=18
結果:整數鍵
123456的哈希索引為 18。
-
2. 沖突處理(Collision Resolution)
2.1 開放尋址(Open Addressing)
- 線性探測(Linear Probing):
idx = (h(key) + i) % M,i 從 0 遞增 - 二次探測(Quadratic Probing):
idx = (h(key) + c1·i + c2·i^2) % M - 雙重哈希(Double Hashing):
idx = (h1(key) + i·h2(key)) % M
優點:內存集中,緩存友好。
缺點:高負載下“聚集”現象嚴重,探測長度增加。
2.2 鏈地址法(Separate Chaining)
- 每個槽存儲一個鏈表(或其他動態結構,如紅黑樹、平衡樹)。
- 插入:直接插入到對應鏈表頭部或尾部。
- 查找:在鏈表中線性掃描或在樹中對數搜索。
優點:負載因子超過 1 時仍能正常工作;刪除操作簡單。
缺點:額外的指針開銷;鏈表長時查找較慢。
概要:
- 負載因子(Load Factor)是哈希表中實際存儲元素數 n n n 與桶(或槽)總數 m m m 之比。 α = n / m \alpha = n/m α=n/m;它反映了哈希表的“擁擠”程度,直接影響查找、插入和刪除操作的平均性能,值越高意味著沖突越多、性能越差。
- 負載因子不僅限于鏈地址法,在開放尋址(如線性探測、二次探測、雙重哈希)中同樣適用,但最大值受限(開放尋址時 α < 1 \alpha<1 α<1)。
- 再哈希(Rehashing)是當負載因子超過預設閾值后,為恢復高效性能而動態擴大哈希表并重新計算所有現有鍵的哈希索引的過程。
負載因子(Load Factor)
定義
- 數學表達: α = n m \displaystyle \alpha = \frac{n}{m} α=mn?,其中 n n n 為哈希表中當前元素數, m m m 為桶的總數或槽位總數。
- 意義:表示哈希表的“填充率”,負載因子高意味著更多的鍵映射到相同或相鄰的位置,沖突概率也隨之升高,從而增大查找或插入時的探測或鏈表長度。
在鏈地址法中的表現
- 鏈地址法(Separate Chaining):每個桶對應一個鏈表(或其他結構),沖突時元素附加到對應鏈表中。
- 性能影響:平均情況下,鏈長約為 α \alpha α,因此插入與查找的平均時間復雜度為 O ( 1 + α ) O(1 + \alpha) O(1+α);當 α \alpha α 增大時,鏈表變長,操作成本也線性增加。
- 閾值選擇:通常將 α max ? \alpha_{\max} αmax? 設在 1–3 之間,以平衡內存利用與性能,多數實現會在 α \alpha α 超過設定閾值時觸發再哈希。
在開放尋址中的表現
- 開放尋址(Open Addressing):沖突時在表內探測其他空槽,直至找到空位。
- 性能影響:當 α \alpha α 接近 1 時,將出現嚴重的“聚集”現象,探測長度急劇上升,查找與插入效率急劇下降。
- 最大限制:開放尋址表中 m m m 是槽位數,必須保證 n < m n<m n<m,即 α < 1 \alpha<1 α<1;實際應用中,多數實現將 α max ? \alpha_{\max} αmax? 取在 0.6–0.75 之間,以保證高效。
3. 基本操作
| 操作 | 開放尋址復雜度 | 鏈地址法復雜度 |
|---|---|---|
| 插入 | 平均 O(1),最壞 O(M) | 平均 O(1 + α),最壞 O(N) |
| 查找 | 平均 O(1),最壞 O(M) | 平均 O(1 + α),最壞 O(N) |
| 刪除 | 平均 O(1),最壞 O(M) | 平均 O(1 + α),最壞 O(N) |
其中 α = N/M 為負載因子,N 為表中實際元素數。
4. 擴容與再哈希
- 擴容閾值:當負載因子 α 超過設定(如 0.75)時,表長擴倍(通常×2),并對所有元素重新 hash 到新表。
- 再哈希開銷:O(N),但由于擴容次數為 O(log N),均攤插入仍是 O(1)。
再哈希(Rehashing)
概念與定義
- 再哈希是指在哈希表運行過程中,檢測到負載因子 α \alpha α 達到或超過預設閾值后,動態地創建一個更大的新表(通常容量翻倍),并將舊表中所有元素按照新表大小重新計算哈希并插入新表的過程。
- 這一過程又稱“擴容”(resize)或“重散列”,旨在降低 α \alpha α 并顯著減少后續的沖突開銷。
執行流程
- 觸發條件:當插入操作導致 α ≥ α max ? \alpha \ge \alpha_{\max} α≥αmax? 時觸發,再哈希通常放在插入后判斷并執行。
- 分配新表:依據策略(多數為翻倍或乘以固定系數),分配一個新的、更大的桶數組或槽位數組。
- 重計算哈希:遍歷舊表中每個元素,調用哈希函數重新計算索引(因表長已變,索引需更新),并插入到新表中。
- 替換舊表:完成所有元素遷移后,用新表替換舊表,繼續提供服務。
性能與成本
- 單次開銷:再哈希過程本身是 O ( n ) O(n) O(n) 的昂貴操作,因為需要對所有元素重新散列并插入。
- 均攤分析:由于容量每次通常翻倍(或按幾何級數增長),再哈希在 n n n 次插入中的總成本為 O ( n ) O(n) O(n) 級別,故均攤到每次插入仍為 O ( 1 ) O(1) O(1) 平均時間。
- 內存權衡:再哈希會暫時占用兩倍內存,且舊表在遷移完畢前無法立即釋放,需在設計時考慮內存壓力。
結論:
- 負載因子不僅是衡量哈希表裝填度的重要指標,也是觸發再哈希動作的關鍵條件,既適用于鏈地址法,也適用于開放尋址等所有哈希表實現。
- 再哈希通過動態擴容并重散列來降低負載因子,從而保持哈希表在平均 O ( 1 ) O(1) O(1) 性能上的穩定性,但需要留意其偶發的 O ( n ) O(n) O(n) 開銷和內存開銷。
5. 注意事項
- 哈希函數安全:對抗攻擊時需防止惡意構造大量沖突,可以使用隨機化哈希或更復雜的哈希算法。
- 負載因子控制:負載因子過低浪費內存,過高導致沖突增多,應根據業務特點調整。
- 并發環境:使用分段鎖、CAS 與無鎖結構(如 ConcurrentHashMap)來保證線程安全。
游戲服務器方案對比分析)
















--Java版)

)