一、編碼
????????當我們用數字來讓電腦“認識”字符或單詞時,最簡單的方法是為每個字符或單詞分配一個唯一的編號,然后用一個長長的向量來表示它。比如,假設“我”這個字在字典中的編號是第10個,那么它的表示就是一個很多0組成的向量,除了第10個位置是1,其余都是0。這種表示叫做one-hot編碼,中文常用字就有大約五千個,所以每個字的向量長度也就大約是五千維。
????????不過,這樣的表示有兩個問題。第一,向量很長,存儲和計算都很浪費空間,因為大部分位置都是0,沒有任何信息。第二,雖然這種編碼能讓每個字唯一標識,但是它完全沒有體現字與字之間的關系。
? ? ?one-hot編碼方式存在一個問題,one-hot矩陣相當于簡單的給每個單詞編了 個號,但是單詞和單詞之間的關系則完全體現不出來,比如說”cat“和”dog“經過onehot編碼后可能是‘[1,0,0,0,0,0]’和‘[0,1,0,0,0,0]’我們可以求他們的余弦相似度:
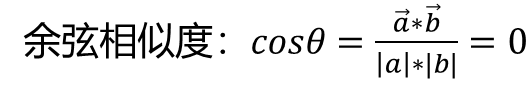
????????余弦相似度為0,他們毫不相關,但實際上”cat“和”dog“應該是有關系的,至少他們都 是動物,可以發現one-hot編碼并不能表示單詞之間的關系。 綜上所述,one-hot編碼存在兩個問題(維度災難和語義鴻溝):?
????????編碼后形成高維稀疏矩陣占用大量空間
????????編碼后不能表示單詞之間的關系
二、詞嵌入(Word Embedding)
????????詞嵌入是一種將詞轉換為低維稠密向量的技術,旨在用連續的向量表示單詞的語義和語法信息。不同于傳統的獨熱編碼(One-Hot Encoding),詞嵌入能夠捕捉單詞之間的語義關系,比如相似詞的距離更近。
主要特點:
????????稠密向量:每個單詞由一個實數向量表示,通常維度較低(如100、300維),節省存儲空間。
????????語義捕捉:通過訓練,詞向量中相似或相關的詞在空間中的距距離更近,包括詞義相似、上下文關系等。
????????可遷移性:預訓練的詞嵌入(如Word2Vec、GloVe)可以遷移到不同的任務上,提升模型效果。
主要方法:
????????Word2Vec:利用Skip-Gram或CBOW模型,通過預測鄰近詞或目標詞學習詞向量。
????????GloVe:結合全局統計信息,優化詞與詞之間的共現概率,得到詞向量。
????????FastText:考慮到詞內部的子詞(字符n-gram),更善于處理未登錄詞(OOV)。
應用場景:
????????詞義相似性計算
????????詞性標注
????????文本分類
????????機器翻譯
????????其他多種NLP任務
三、Embedding降維
????????WordEmbedding解決了這個問題,WordEmbedding的核心就是給每個單詞賦予一 個固定長度的詞嵌入向量。
????????這個向量可以自己調整,可以是64維,也可以是128,512、1024,等等。而這個向 量的維度遠遠小于字典的長度。為了得到這個向量我們可以用一個可訓練參數矩陣與 原來的one-hot編碼矩陣相乘,比如說one-hot編碼的矩陣大小是 100*100,可訓 練參數矩陣的大小是100*100 ,那得到的詞嵌入矩陣就為100*64 的矩陣,可以看 到我們將100維的特征維度降低為64維。
四、?Embedding映射
????????比如說”cat“的詞嵌入向量為[-0.95 0.44],"dog"的詞嵌入向量為[-2.15 0.11]。此時我 們再計算”cat“和”dog“的余弦相似度:
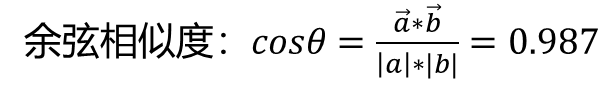
????????可以看到,現在可以體現出兩個單詞之間的關系。從坐標系上看他們也靠的很近。當 然這只是一種簡單的詞嵌入方式,即通過一個可訓練矩陣將高維稀疏的矩陣映射為低 維稠密的矩陣。
五、設計思路
import torch
import torch.nn as nn# 定義一個簡單的詞嵌入層
embedding_dim = 64
vocab_size = 10000 # 假設詞典大小為10000
embedding_layer = nn.Embedding(vocab_size, embedding_dim)# 輸入一個單詞的索引
word_index = torch.tensor([567]) # 假設單詞"cat"在詞典中的索引是567# 通過詞嵌入層獲取詞嵌入向量a
word_embedding = embedding_layer(word_index)# 打印詞嵌入向量
print("Word Embedding for 'cat':")
print(word_embedding)


)






![[自動化集成] 使用明道云上傳附件并在Python后端處理Excel的完整流程](http://pic.xiahunao.cn/[自動化集成] 使用明道云上傳附件并在Python后端處理Excel的完整流程)

:Python復刻「崩壞星穹鐵道」嗷嗚嗷嗚事務所---源碼級解析該小游戲背后的算法與設計模式【純原創】)






之scenario、Stage插件詳解二)