感謝 GPT,對很多問題的理解有機會更深。
大家攻擊 Lambda 架構,常說的一個點就是 “實時離線指標存在差異”。“實時離線指標存在差異”,是一個真實困擾運營方的問題嗎?
答案:是的,這是一個真實生活中的痛點。
原因如下,特別是第一條,會讓業務運營存在不確定性,為了應對這種不確定性,可能需要預留出業務余量,造成浪費。
-
實時數據偏差引發錯誤判斷
? 運營團隊可能在實時看板上看到用戶注冊數為 900,以為目標還沒達成,于是推送通知、加大預算。
? 結果第二天離線數據跑完,真實注冊是 1100,實際早就達成了。
? 這會造成 資源浪費、判斷誤差。 -
數據不一致影響信任
? 運營問:“實時看板顯示新增 900,日報卻說新增 1100,這是哪個錯了?”
? 數據團隊解釋:“實時數據有水位延遲、數據亂序、去重不完整……”
? 非技術同學聽不懂,久而久之就對系統失去信任。 -
多方依賴相同指標,版本不一致
? 實時系統和離線系統往往使用不同代碼、不同計算鏈路:
? 實時:Kafka → Flink → Redis/ClickHouse
? 離線:Hive/Spark → HDFS → 數據倉庫
? 一點小的業務邏輯差異、時間處理方式不同、清洗策略不同,就會讓指標產生偏差。
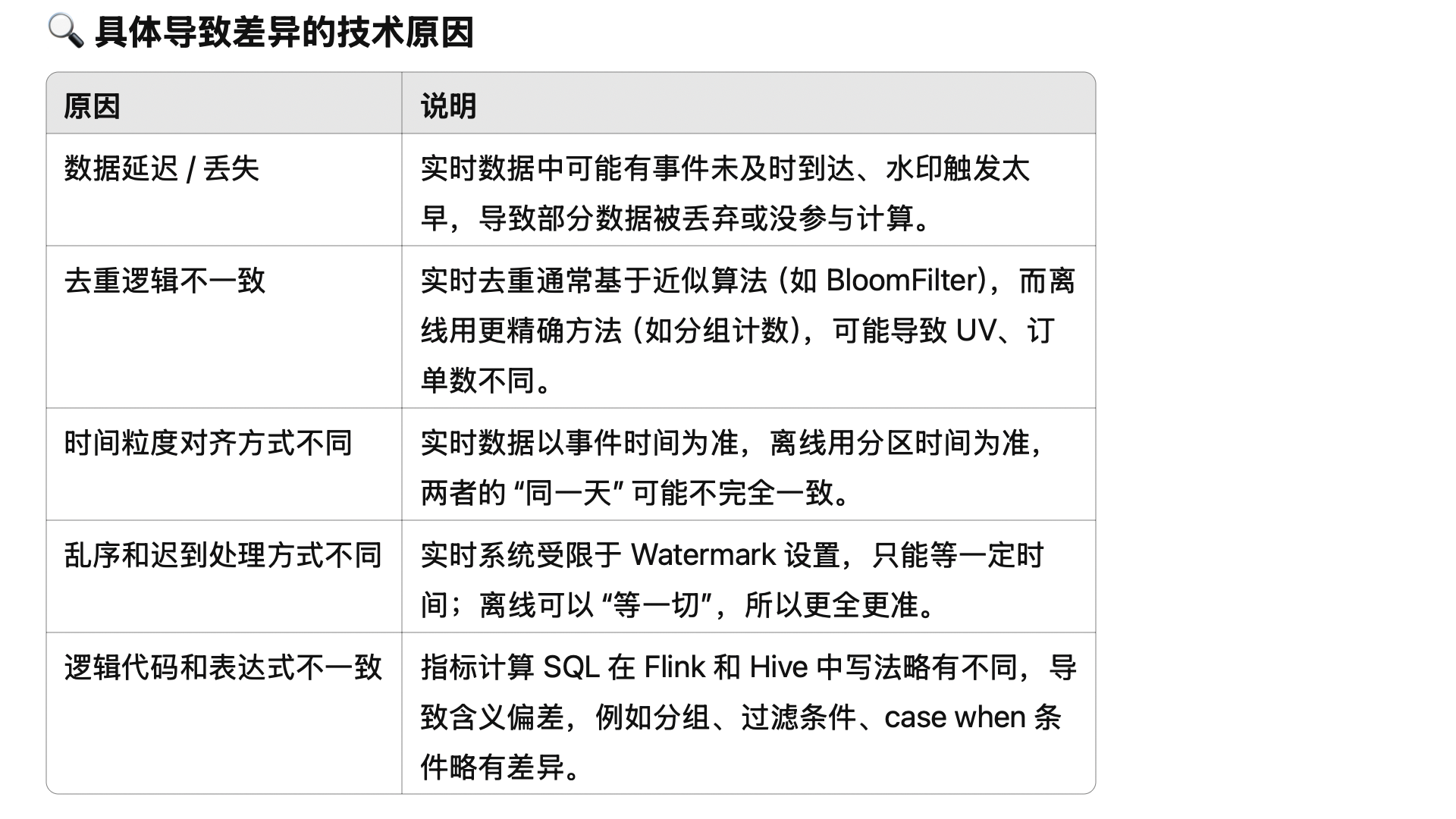
附1:實時指標為什么可能不對?
答:因為 Flink 的計算有時間窗口的概念,比如:每個整點,計算上一個小時的銷售額。因為隊列延遲、網絡出錯、重試導致數據重復等原因,會讓 Kafka 等隊列中的數據不能完全被信任,上一個小時的數據不一定真的全了,可能有一些數據要等幾分鐘才到,也有可能永遠不到。
為了解決這個問題,一般會延遲幾分鐘,等等跑慢了的數據。但也不能無限等下去。理論上總是可能有數據來晚了。
附2:批處理系統(離線) + 流處理系統(實時) + Serving 層合并結果為什么不準?
簡而言之:因為實時數據不準確,那么 Serving 的到的數據肯定也不準確。
Lambda 架構:批處理系統(離線) + 流處理系統(實時) + Serving 層合并結果
我之前的疑問:Serving 層如何合并?如何保證離線+實時,得到準確的全量數據?
一般大家說得不到,原因就在于
(1)流處理系統拿到的數據可能是不準確的
(2)離線、實時數據的邊界可能有模糊的地方。











--Java版)

)



)

