概述

SQL 仍然是當前行業中最受歡迎的技能之一
免責聲明:Spark NLP 中的 Text2SQL 注釋器在 v3.x(2021 年 3 月)中已被棄用,不再使用。如果您想測試該模塊,請使用 Spark NLP for Healthcare 的早期版本。
自新千年伊始,每日產生的數據量呈指數級增長。其中大部分數據存儲在關系型數據庫中。在過去,只有大型公司能夠使用結構化查詢語言(SQL)查詢這些數據。隨著手機的普及,越來越多的個人數據被存儲,因此,越來越多來自不同背景的人試圖查詢和使用自己的數據。盡管數據科學的熱度不斷攀升,但大多數人仍缺乏編寫 SQL 查詢數據的必要知識。此外,大多數人也沒有時間去學習和理解 SQL。即使是 SQL 專家,反復編寫類似的查詢也是枯燥乏味的任務。正因如此,如今海量的數據無法被有效獲取 [1]。您可以查看 這一系列文章 和 一篇博客文章,以了解更多關于 Text2SQL 及該研究領域的最新趨勢 [2]。
我們的目標是讓人們能夠直接用人類語言與數據對話。因此,這類自然語言接口幫助任何背景的用戶輕松查詢和分析海量數據。為了構建這種自然語言接口,系統必須理解用戶的問題,并自動將其轉換為對應的 SQL 查詢。
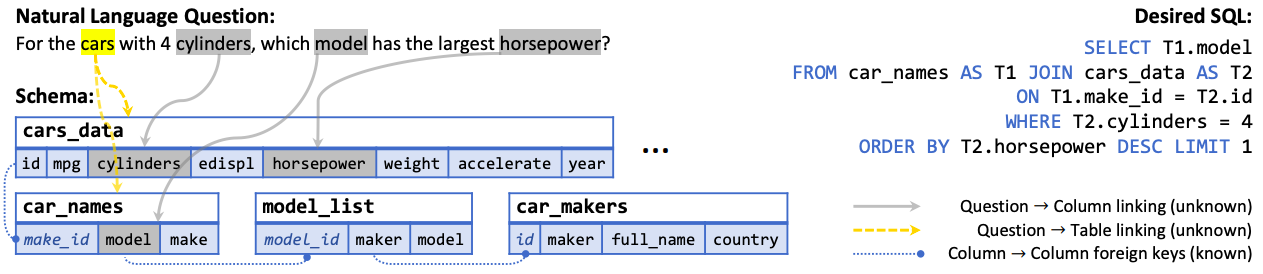
來自 Spider 數據集的一個具有挑戰性的 Text-to-SQL 任務
Text2SQL 是自然語言處理研究中的一個重大挑戰,目前最先進的模型(SOTA)仍然難以達到人類基線水平的準確率,這是由于問題本身的固有特性。因此,目前最先進的模型在 Spider 數據集 上的準確率僅為 70%,而 Spider 數據集是 Text2SQL 研究中最廣泛使用的基準數據集之一。
還有其他幾個 Text2SQL 基準數據集,例如 ATIS、GeoQuery、Scholar、Advising 等,以及 WikiSQL,它們覆蓋了整個 SQL 查詢范圍的不同領域。
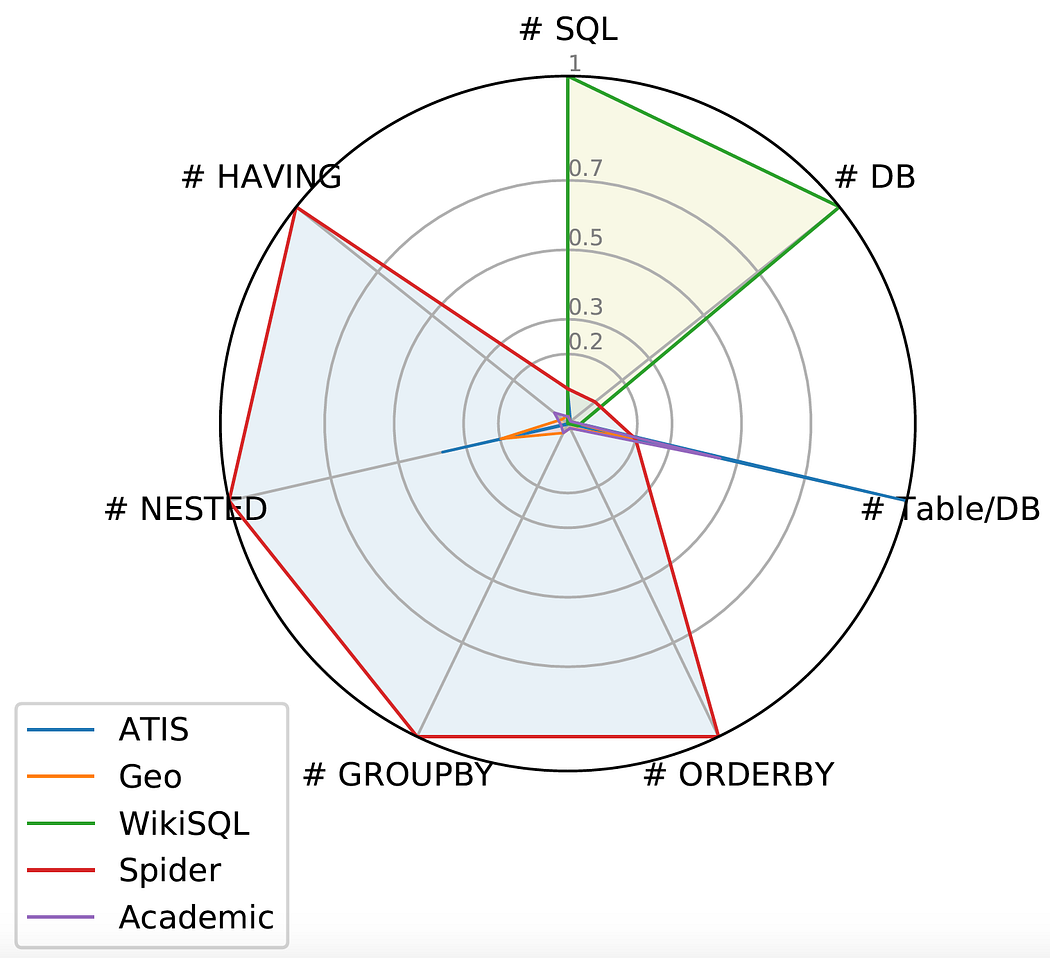
一些 Text-to-SQL 數據集的圖表(圖片來自 Spider 項目)
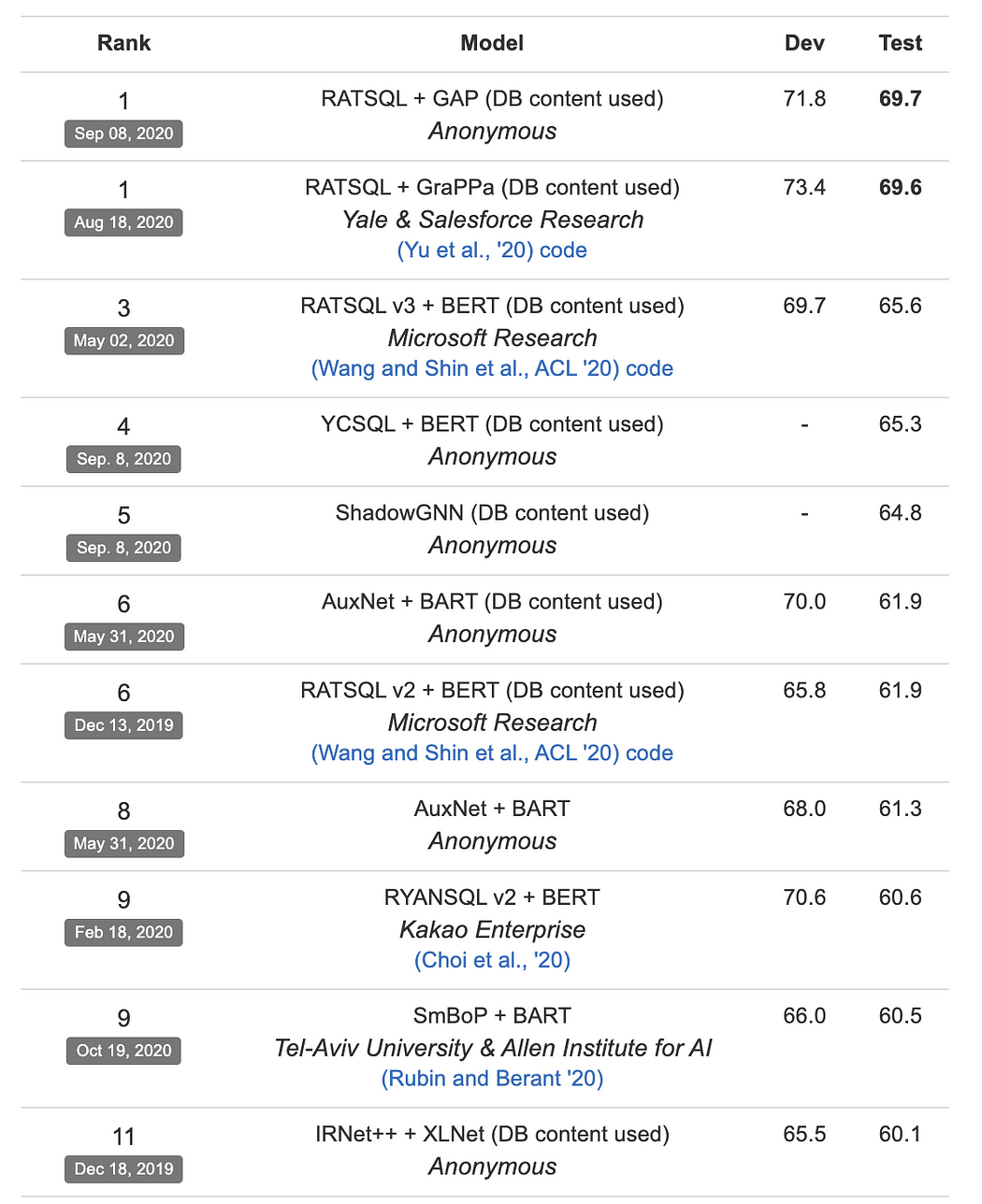
Spider 數據集上的 Text2SQL 任務排行榜
如左圖所示,Spider 數據集在圖表中占據了最大面積,使其成為第一個復雜且跨領域的 Text-to-SQL 數據集,它具有以下特點:
- 大規模:包含超過 10,000 個問題,以及大約 6,000 個對應的、獨特的 SQL 查詢。
- 復雜性:大多數 SQL 查詢涵蓋了幾乎所有重要的 SQL 組件,包括 GROUP BY、ORDER BY、HAVING 和嵌套查詢。此外,所有數據庫都包含多個通過外鍵關聯的表。
- 跨領域:包含 200 個復雜的數據庫。我們將 Spider 數據集劃分為訓練集、開發集和測試集,基于數據庫進行劃分。這樣,我們可以在未見過的數據庫上測試系統的性能。
Spark NLP:大規模的自然語言處理
Spark NLP 是基于 Apache Spark ML 構建的自然語言處理庫,每天的下載量超過 10,000 次,總下載量達到 180 萬。它是增長最快的自然語言處理庫之一,支持 Python、R、Scala 和 Java 等流行編程語言。它為機器學習管道提供了簡單、高效且準確的自然語言處理注釋,這些注釋可以在分布式環境中輕松擴展。
Spark NLP 提供了 330 多個預訓練的管道和模型,涵蓋 46 種以上的語言。它支持最先進的 Transformer 模型,例如 BERT、XLNet、ELMO、ALBERT 和 Universal Sentence Encoder,這些模型可以在集群中無縫使用。此外,它還提供分詞、詞性標注、命名實體識別、依存句法分析、拼寫檢查、多類文本分類、多類情感分析等 自然語言處理任務。如需了解更多詳細信息和示例 Colab 筆記本,我們強烈建議您查看我們的 工作坊倉庫。

Spark NLP for Healthcare 2.7 于 2020 年 10 月 28 日發布
Spark NLP 中實現的 Text2SQL 算法
我們在 Spark NLP 中實現了一種名為 IRNet 的深度學習架構。中間表示(IRNet) 旨在解決復雜且跨領域的 Text-to-SQL 任務中的兩個主要挑戰:自然語言中表達的意圖與預測列之間的不匹配,以及由于大量超出領域詞匯導致的問題。讓我們看看 IRNet 提供了什么。
- IRNet 將自然語言分解為 3 個階段,而不是端到端地合成 SQL 查詢:模式編碼器(Schema Encoder)、解碼器(Decoder)和自然語言編碼器(NL Encoder)。
- 在第一階段,對數據庫模式和問題進行模式鏈接。IRNet 采用基于語法的神經模型來合成
SemQL查詢,這是一種我們設計的中間表示(IR),用于連接自然語言和 SQL。模式編碼器以數據庫模式為輸入,輸出表和列的表示。 - 解碼器用于使用上下文無關語法合成
SemQL查詢,IRNet 確定性地從合成的 SemQL 查詢中推斷出 SQL 查詢,并利用領域知識。 - 最后,自然語言編碼器將自然語言輸入編碼為嵌入向量。這些嵌入向量隨后用于通過雙向 LSTM 構建隱藏狀態。
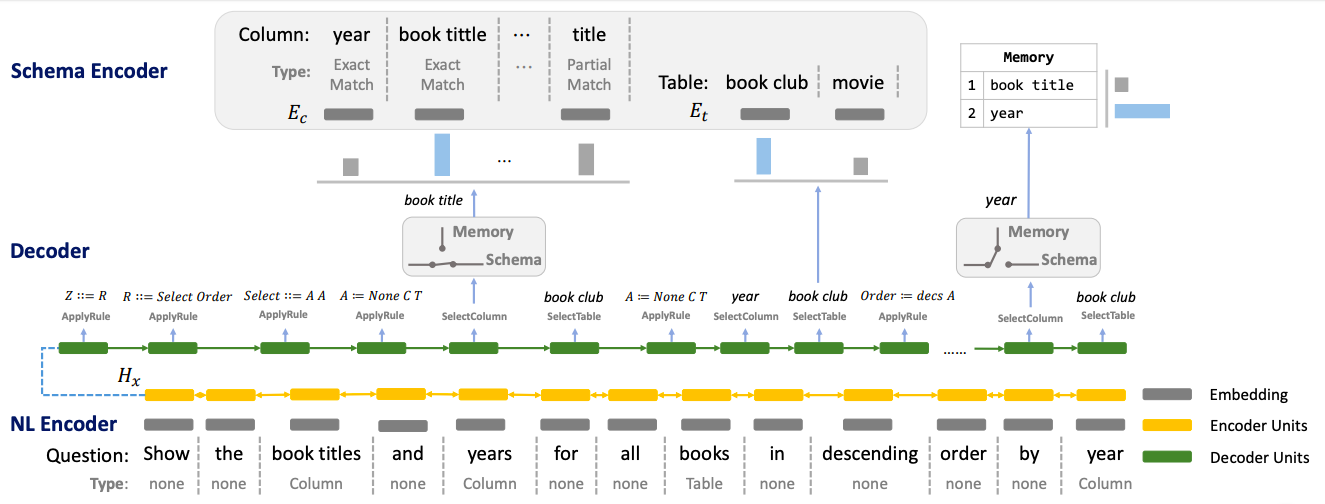
合成 SemQL 查詢的神經模型概覽。基本上,IRNet 由自然語言編碼器、模式編碼器和解碼器構成。如圖所示,從模式中選擇了“書名”列,而第二列“年份”是從記憶中選擇的。(來源)
Spark NLP 中的實現方式
Text2SQL 是在 Spark NLP for Healthcare 2.7.0 中宣布的一項功能,這是撰寫本文時的最新版本。基本上,我們使用 Tensorflow 實現了 IRNet 算法,并在 Spider 基準數據集上進行訓練,并將其封裝為 Spark NLP 中的 Tex2SQLModel。目前,它僅提供了一個預訓練模型,名為 text2sql_glove,因為它是使用 Spark NLP 中的 glove_6B_300 嵌入進行訓練的。
正如我們之前解釋的,IRNet 需要在實際構建查詢之前解析數據庫模式(模式編碼器)。這是通過我們創建的另一個注釋器 Text2SQLSchemaExporter 來完成的。
以下是獲取 Spark NLP 中的 Text2SQL 管道的步驟,以便您可以使用口語查詢數據庫。
- 首先,我們需要從原始數據庫模式準備一個 json 文件。假設我們有一個 醫院記錄的 SqLite,包含以下 15 個表:
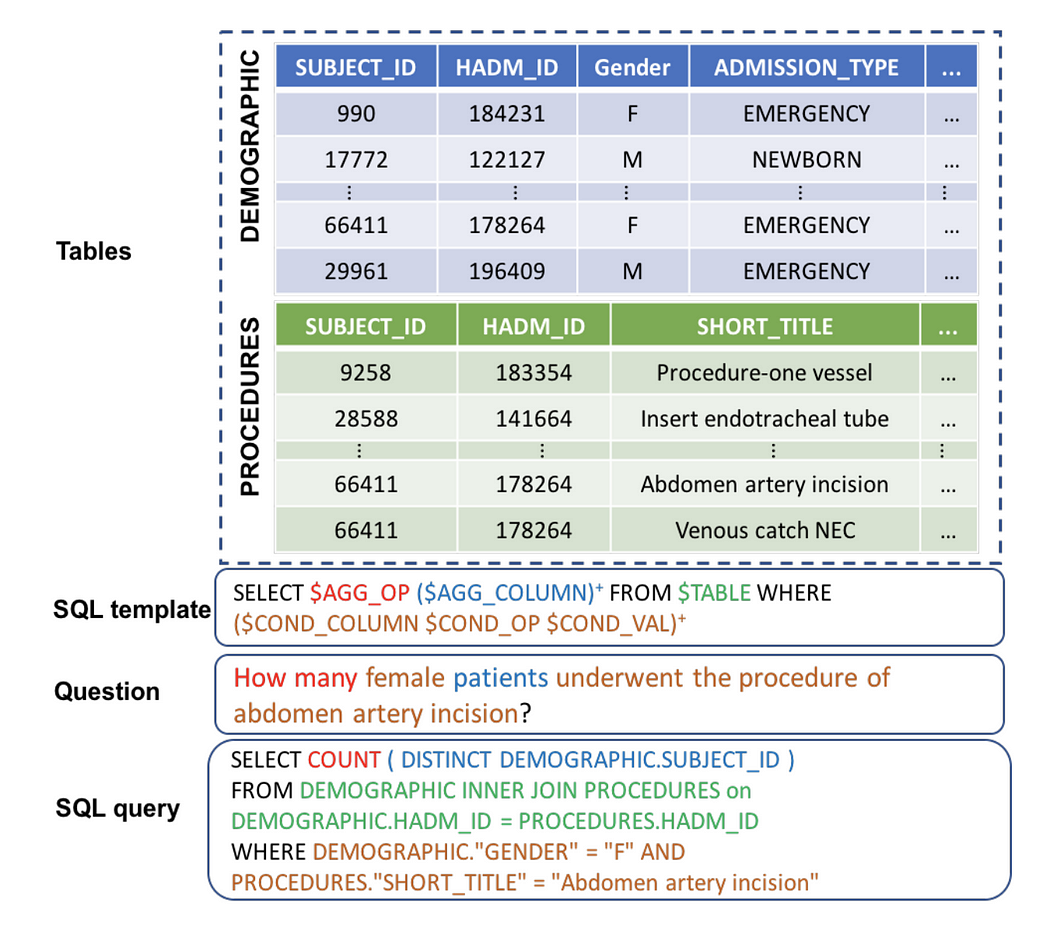
來自醫療記錄的 Text2SQL(圖片來自 官方論文)
['Physician', 'Department', 'Affiliated_With', 'Procedures', 'Trained_In', 'Patient', 'Nurse', 'Appointment', 'Medication', 'Prescribes', 'Block', 'Room', 'On_Call', 'Stay', 'Undergoes']
然后,我們使用以下代碼將該模式轉換為我們的模式解析器可以理解的 json 格式。將此處理放在 Text2SQLSchemaExporter 注釋器之外的原因是為了能夠支持其他數據庫模式,而無需更改注釋器邏輯。
from sparknlp_jsl._tf_graph_builders.text2sql import util
input_schema = "hospital_records.sqlite"
output_schema = "hospital_schema_converted.json"
util.sqlite2json(input_schema, output_schema)
然后,使用 Text2SQLSchemaExporter,我們使用詞嵌入處理這個模式,以創建表和列名的表示。
schema_json_path = 'hospital_schema_converted.json'
output_json_path = "db_embeddings.json"
prepare_db_schema(schema_json_path, output_json_path)
prepare_db_schema 函數來自包含 Text2SQLSchemaExporter 階段的 Spark NLP 管道。本文末尾將分享整個管道。
下一步是準備一個管道,將文本查詢的表示轉換為我們的 Text2SQLModel 注釋器可以理解的格式。基本上,它將接受用戶以純文本形式提出的問題,并創建算法返回查詢所需的所有特征。
sql_prediction_light = get_text2sql_model (schema_json_path, output_json_path)
sql_prediction_light 函數來自包含 Text2SQLModel 階段的 Spark NLP 管道。本文末尾將分享整個管道。
現在,我們可以開始使用純文本查詢數據庫:
question = "Find the id of the appointment with the most recent start date"
annotate_and_print(question)
>> question:
SELECT T1.Appointment FROM Prescribes
AS T1 JOIN Appointment AS T2 ON
T1.Appointment = T2.AppointmentID
ORDER BY T2.Start
DESC LIMIT 1
>> query:
| | Appointment |
|---:|:------------|
| 0 | 086213939 |
另一個例子
question = "What is the name of the nurse who has the most appointments?"
annotate_and_print(question)
>> query:
SELECT T1.Name FROM Nurse AS T1
JOIN Appointment AS T2 ON
T1.EmployeeID = T2.PrepNurse
GROUP BY T2.prepnurse
ORDER BY count(*)
DESC LIMIT 1
>> result:
| | Name |
|---:|:-----------------|
| 0 | Carla Espinosa |
再舉一個例子
question = "How many patients do each physician take care of? List their names and number of patients they take care of."
annotate_and_print(question)
>> query:
SELECT T1.Name, count(*)
FROM Physician AS T1
JOIN Patient AS T2 ON
T1.EmployeeID = T2.PCP
GROUP BY T1.Name
>> result:
| | Name | count(*) |
|---:|:-----------------|-----------:|
| 0 | Christopher Turk | 1 |
| 1 | Elliot Reid | 2 |
| 2 | John Dorian | 1 |
正如您所見,它返回了相當不錯的結果!實際上,由于它僅在通用數據集(Spider)上進行訓練,因此在某些特定領域的數據庫(如醫療保健或金融)上可能表現不佳。但這只是找到合適的數據集并重新訓練模型的問題。
我們計劃在未來幾個月內對其他領域數據集訓練新的 Text2SQL 模型。下一個將基于 MIMIC 數據集進行訓練,它將在醫療記錄方面表現更好。
總結
自新千年伊始,每日產生的數據量呈指數級增長。其中大部分數據存儲在關系型數據庫中。盡管數據科學的熱度不斷攀升,但大多數人仍缺乏編寫 SQL 查詢數據的必要知識。
結合查詢非結構化文本數據的固有困難,從數據庫中查找相關信息的任務需要多學科的技能。Spark NLP for Healthcare 旨在通過解析文本數據以提取有意義的實體(NerDL)、分配斷言狀態(AssertionDL)和醫學術語代碼(EntityResolver)、構建實體之間的關系(RelationExtractionDL)、將所有這些內容寫入類似 OMOP 的結構化數據庫模式,最后使用本文中描述的對話式純文本查詢這些記錄,為這一任務提供解決方案。
您可以在 這個 Colab 筆記本 中找到所有代碼和更多示例,如果您想在自己的數據上嘗試,可以申請 Spark NLP Healthcare 免費試用許可證。
Spark NLP 庫在企業項目中得到應用,它原生基于 Apache Spark 和 TensorFlow 構建,并提供全方位最先進的自然語言處理解決方案,為機器學習管道提供簡單、高效且準確的自然語言處理注釋,這些注釋可以在分布式環境中輕松擴展。
)



1.二分查找)
:基礎設備篇——人類精密制造的“巔峰對決”)




![[ linux-系統 ] 命令行參數 | 環境變量](http://pic.xiahunao.cn/[ linux-系統 ] 命令行參數 | 環境變量)

凱撒密碼——附py代碼)




詳解,附代碼。)

