摘要:文本到音頻系統雖然性能不斷提高,但在推理時速度很慢,因此對于許多創意應用來說,它們的延遲是不切實際的。 我們提出了對抗相對對比(ARC)后訓練,這是第一個不基于蒸餾的擴散/流模型的對抗加速算法。 雖然過去的對抗性后訓練方法難以與昂貴的蒸餾方法進行比較,但ARC后訓練是一個簡單的程序,它(1)將最近的相對論對抗性公式擴展到擴散/流后訓練,(2)將其與一種新的對比鑒別器目標相結合,以鼓勵更好的提示依從性。 我們將ARC后訓練與Stable Audio Open的一些優化相結合,構建了一個能夠在H100上大約75毫秒內生成大約12秒的44.1kHz立體聲音頻,在移動邊緣設備上大約7秒的模型,據我們所知,這是最快的文本到音頻模型。Huggingface鏈接:Paper page,論文鏈接:2505.08175
研究背景和目的
研究背景
近年來,文本到音頻(Text-to-Audio, T2A)生成系統取得了顯著進展,能夠在各種應用場景中生成高質量的音頻內容。然而,這些系統在推理(inference)階段普遍存在速度較慢的問題,生成一段音頻往往需要數秒甚至數分鐘的時間。這種高延遲極大地限制了T2A系統在創意應用領域的實用性,如實時音樂創作、游戲音效生成、虛擬助手交互等。在這些場景中,用戶期望系統能夠即時響應并生成符合要求的音頻內容,而現有的T2A系統顯然無法滿足這一需求。
為了解決這一問題,研究人員開始探索加速T2A系統的方法。目前,主流的加速技術主要基于蒸餾(distillation),即通過訓練一個較小的模型來模擬較大模型的行為,從而在保持一定生成質量的同時提高推理速度。然而,蒸餾方法存在諸多局限性,如訓練成本高、需要大量存儲資源來保存教師模型生成的軌跡-輸出對、以及可能導致生成多樣性的降低等。此外,蒸餾方法往往依賴于分類器無引導(Classifier-Free Guidance, CFG)技術來提高生成質量,但CFG同時也會帶來生成多樣性的降低和過度飽和(over-saturation)的問題。
研究目的
本研究旨在提出一種不依賴于蒸餾的對抗性加速算法,用于加速基于擴散模型或流模型的文本到音頻生成系統。具體而言,研究目的包括:
- 開發一種新的對抗性后訓練(post-training)方法:通過引入相對論對抗性損失(Relativistic Adversarial Loss)和對比損失(Contrastive Loss),在保持生成質量的同時顯著提高推理速度。
- 優化模型架構和采樣策略:通過改進模型架構和采用更高效的采樣策略,進一步減少推理時間,使得T2A系統能夠在邊緣設備上實時運行。
- 評估加速效果和生成質量:通過客觀指標和主觀評價,驗證所提方法在加速效果和生成質量方面的優越性,并與現有加速方法進行比較。
- 探索創意應用潛力:通過實際案例展示加速后的T2A系統在創意應用領域的潛力,如音樂創作、聲音設計等。
研究方法
1. 基礎模型選擇與預訓練
本研究選擇Stable Audio Open(SAO)作為基礎模型,該模型是一個基于擴散模型的文本到音頻生成系統,能夠生成高質量的立體聲音頻。SAO模型由預訓練的自動編碼器、T5文本嵌入器和擴散Transformer(DiT)組成,總參數量約為1.06B。為了加速推理,研究對SAO模型進行了優化,減少了DiT的維度和層數,最終得到一個參數量約為0.34B的輕量級模型。
2. 對抗性相對對比后訓練(ARC Post-Training)
ARC后訓練是本研究的核心方法,它結合了相對論對抗性損失和對比損失來優化預訓練的擴散模型。具體而言,ARC后訓練包括以下步驟:
- 初始化:將預訓練的擴散模型作為生成器(G)和鑒別器(D)的初始化模型。
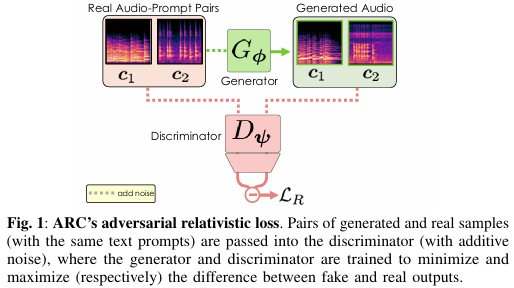
- 相對論對抗性損失(LR):通過引入相對論對抗性損失,鼓勵生成器生成更逼真的音頻樣本,同時使鑒別器能夠更準確地區分真實樣本和生成樣本。相對論對抗性損失通過比較成對的真實樣本和生成樣本(共享相同的文本提示)來計算損失,從而提供更強的梯度信號。
- 對比損失(LC):為了增強生成器對文本提示的遵循能力,研究引入了對比損失。對比損失通過訓練鑒別器來區分具有正確和錯誤文本提示的音頻樣本,從而鼓勵鑒別器關注語義特征而不是高頻特征。這有助于提高生成音頻與文本提示之間的一致性。
- 聯合優化:在訓練過程中,交替更新生成器和鑒別器的參數,以最小化相對論對抗性損失和對比損失的總和。
3. 采樣策略優化
為了進一步提高推理速度,研究采用了乒乓采樣(Ping-Pong Sampling)策略。乒乓采樣通過交替進行去噪和再加噪操作來迭代優化樣本,從而減少了對傳統ODE求解器的依賴。這種采樣策略使得模型能夠在更少的采樣步驟內生成高質量的音頻樣本。
4. 邊緣設備優化
為了使加速后的T2A系統能夠在邊緣設備上實時運行,研究還進行了邊緣設備優化。具體而言,研究采用了Arm的KleidiAI庫和LiteRT運行時,通過動態Int8量化技術來減少模型大小和推理時間。動態Int8量化技術允許在推理過程中動態量化激活值,從而在保持一定生成質量的同時顯著減少內存占用和推理時間。
研究結果
1. 加速效果
實驗結果表明,ARC后訓練顯著提高了T2A系統的推理速度。在H100 GPU上,優化后的模型能夠在約75毫秒內生成12秒的44.1kHz立體聲音頻,相比原始SAO模型(約100秒)加速了超過100倍。在移動邊緣設備上(如Vivo X200 Pro智能手機),優化后的模型也能在約7秒內完成生成任務,實現了實時音頻生成。
2. 生成質量
通過客觀指標(如FD openl3、KL passt、CLAP分數等)和主觀評價(如webMUSHRA測試)發現,ARC后訓練在保持生成質量的同時顯著提高了推理速度。具體而言,優化后的模型在音頻質量、語義對齊和提示遵循能力方面均表現出色,且生成多樣性顯著高于現有蒸餾方法(如Presto)。
3. 邊緣設備性能
邊緣設備優化實驗表明,通過動態Int8量化技術,優化后的模型在保持一定生成質量的同時顯著減少了內存占用和推理時間。在Vivo X200 Pro智能手機上,優化后的模型能夠在約7秒內完成生成任務,且峰值運行時RAM使用量從6.5GB降低到3.6GB。
研究局限
盡管本研究在加速文本到音頻生成系統方面取得了顯著進展,但仍存在以下局限性:
- 模型大小和存儲需求:優化后的模型仍然占用較大的存儲空間(數GB),這可能限制了其在某些應用場景中的部署和分發。
- 計算資源需求:盡管ARC后訓練顯著提高了推理速度,但在資源受限的設備上(如低端智能手機),實時音頻生成可能仍然面臨挑戰。
- 生成多樣性評估:盡管本研究提出了CLAP條件多樣性分數(CCDS)來評估條件生成多樣性,但該指標可能無法全面反映生成音頻的多樣性。未來研究可以探索更全面的多樣性評估方法。
- 特定領域性能:本研究主要關注通用音頻生成任務,對于特定領域(如音樂、語音合成等)的音頻生成任務,ARC后訓練的性能可能需要進一步驗證和優化。
未來研究方向
針對本研究的局限性和現有技術的不足,未來研究可以從以下幾個方面展開:
- 模型壓縮與輕量化:探索更高效的模型壓縮和輕量化技術,以減少模型大小和存儲需求。例如,可以采用知識蒸餾、剪枝、量化等技術來進一步壓縮模型。
- 邊緣設備優化:針對資源受限的邊緣設備,研究更高效的推理加速策略。例如,可以探索更高效的采樣策略、硬件加速技術(如專用神經網絡處理器)等。
- 多樣性評估與增強:研究更全面的多樣性評估方法,以更準確地評估生成音頻的多樣性。同時,探索增強生成多樣性的技術,如條件變分自編碼器(CVAE)、生成對抗網絡(GAN)的變種等。
- 特定領域應用:針對特定領域(如音樂、語音合成等)的音頻生成任務,研究專門的加速和優化方法。例如,可以結合領域知識來設計更高效的模型架構和訓練策略。
- 多模態融合:探索文本到音頻生成系統與其他模態(如圖像、視頻)的融合技術,以實現更豐富的多媒體內容生成。例如,可以研究文本到視頻生成系統中的音頻同步和生成技術。
- 實時交互與反饋:研究實時交互和反饋機制,以使用戶能夠在生成過程中實時調整參數和提供反饋。這將有助于提高生成音頻的滿意度和實用性。
結論
本研究提出了一種不依賴于蒸餾的對抗性加速算法——對抗性相對對比后訓練(ARC Post-Training),用于加速基于擴散模型或流模型的文本到音頻生成系統。實驗結果表明,ARC后訓練在保持生成質量的同時顯著提高了推理速度,使得T2A系統能夠在邊緣設備上實時運行。未來研究可以進一步探索模型壓縮與輕量化、邊緣設備優化、多樣性評估與增強、特定領域應用、多模態融合以及實時交互與反饋等方向,以推動T2A技術在更多領域的應用和發展。





)




:設計原則(二):DIP、ISP、LoD)








