文章目錄
- 智能體的4大要素
- 一些上手的例子與思考。
- 創建簡單的AI agent.
- 從本地讀取文件,然后讓AI智能體總結。
- 也可以自己定義一些工具 來完成一些特定的任務。
- 我們可以使用智能體總結一個視頻。用戶可以隨意問關于視頻的問題。
智能體的4大要素
AI 智能體有以下幾個重要的要素:
1 規劃: AI agent 需要擁有規劃和決策能力,規劃能力通常包括 目標分解,思維鏈(連續的進行思考), 自我的反思,以及對過去的反思。
2. 記憶: 包含長期記憶和短期記憶
3. 能使用工具:使用外部的工具來輔助完成更加復雜的任務。可以理解成是擴大了智能體的知識范圍,因為訓練好的大模型的知識是固定的,相對難以直接擴展。
4. 執行:通過以上提到來執行任務。
一些上手的例子與思考。
創建簡單的AI agent.
使用lang chain創建一個AI 智能體是相對簡單的。只需要調用一些開放接口就可以了。一般是使用OpenAI 的接口相對方便一點,但是因為所有的OpenAI 接口都要收費,所以這里我是用的是google的gemini.
一個基礎的智能體,應該有向外獲取信息的能力。 所以出了將大模型作為智能體的大腦外,還需要定義一些基礎的工具讓他使用。我使用奴serpapi的作為智能體的搜索工具,這個工具可以免費使用100次/月。 首先是獲取大模型gemini,和serpapi的接口的密鑰,并將它寫入本地的.env文件中。之后只用dotenv.load進行讀取就好,這樣做的好處是直接將密鑰顯式的寫入代碼中。 然后就可以直接構建一個llm
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain_google_genai import ChatGoogleGenerativeAI
#創建一個gemini-1.5模型
llm = ChatGoogleGenerativeAI(model='gemini-1.5-flash-001')
這就可以讓我們直接使用gemini了,如果想要直接使用的話可以:
result = llm.invoke("從文化的角度評價一下印度")
以下是只用大模型的輸出結果。從一些固定的角度去評價印度。
 但是我們要創建智能體,需要大腦(大模型)還有工具聯系到一起,并且定義智能體的推理框架,
但是我們要創建智能體,需要大腦(大模型)還有工具聯系到一起,并且定義智能體的推理框架,
#定義工具
tools = load_tools(['serpapi'])
#初始化智能體
agent = initialize_agent(tools,llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
推理框架(AgentType)選擇ReACT, 他是一種知道大模型推理和行動的認知框架。基本上就是有三個主要步驟,思考,行動,觀察。比如我們用這個最簡單的智能體去從文化角度評價一下印度,它的輸出會比只用大模型更加的全面。
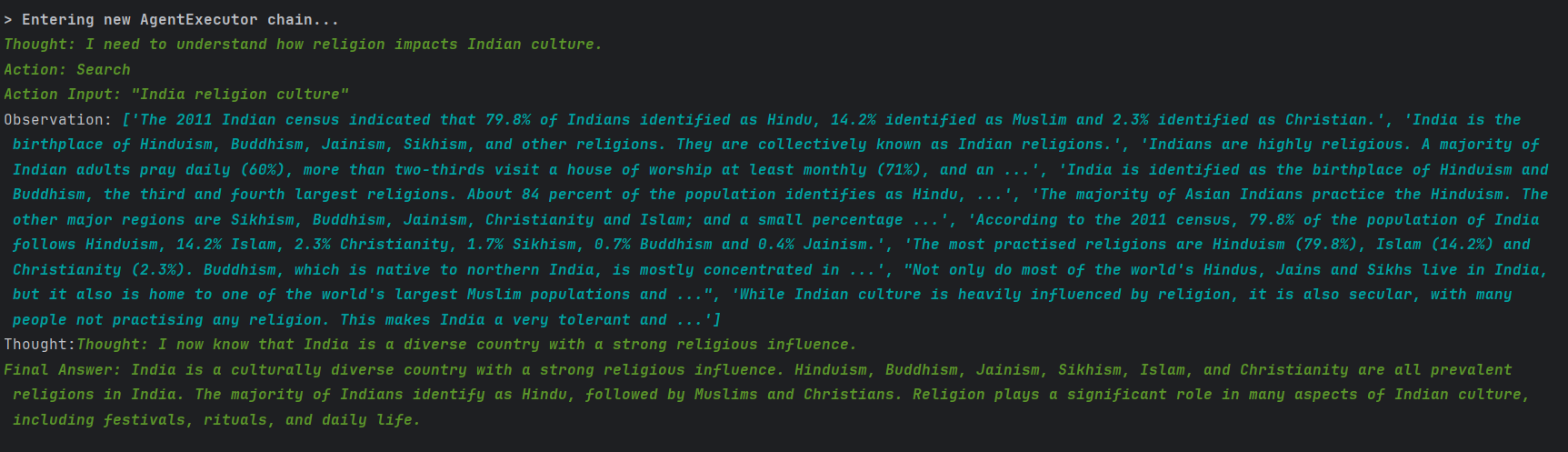
從本地讀取文件,然后讓AI智能體總結。
這個案例主要是講解如何使用 智能體做一個總結工具。在langchain 框架中,有很多不同的現成的chain工具。 可以把每一個chain理解成是一個任務。我們可以直接使用summarize_chain來完成本地文檔的總結。但是需要注意的點有兩個。 首先如果文檔過長可能會超過大模型的token_size限制。所以一般將很長的文檔打散成多個chunk,然后根據不同的chain_type進行總結。
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
from langchain_google_genai import ChatGoogleGenerativeAI
import osclass LoadFiles():def __init__(self,path):self.path = pathself.loader = UnstructuredFileLoader(self.path)self.splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=2)self.llm = ChatGoogleGenerativeAI(model='gemini-1.5-flash-001')def get_documents(self):return self.loader.load()def spilit_files(self):documents = self.get_documents()print('split_text:{}'.format(len(self.splitter.split_documents(documents))))return self.splitter.split_documents(documents)def __call__(self, *args, **kwargs):chain = load_summarize_chain(self.llm,chain_type='refine',verbose=True)chain.run(self.spilit_files()[:5])if __name__ == '__main__':load_dotenv()path = '3D-decoupling.pdf'summerzier = LoadFiles(path)summerzier()
需要記錄的點是 RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=2)的overlap參數是指每個chunk的重疊程度。當chunk=0時說明每個chunk之間是沒有重疊的。重疊chunk在一定程度上可以增加chunk之間的關聯性。還有就是 在創建load_summarize_chain中的chain_type有多種種類,代碼中的refine 就是深度學習中的殘差概念,將第n個文本塊總結出來的內容和第n+1個文本塊同時輸入到大模型中經行總結。
除此之外,stuff 就是將所有的文件一次性塞入模型,map_reduce是先將每一個chunk先做一個初步的總結,然后將所有的總結內容再總結一次。 map_rerank是將總結的文件做一個置信度排名。 比較適合從多個文檔中找到最相關的答案。
也可以自己定義一些工具 來完成一些特定的任務。
這個相對比較的簡單,只需要使用tool類,來定義工具,然后將它在初始化agent的時候當作參數傳入就行了。我們只需要先定義好工具的示例然后當作Tool類的參數傳入即可。
def tools(self):tool = [Tool(name = 'searcher',func= self.searcher.run,description= 'searcher',),Tool(name= 'calculator',func= self.calculator.run,description= 'calculator',)]return tool
然后初始化智能體即可。
def ini_agent(self):self.agent = initialize_agent(tools=self.tools,llm=self.llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,verbose=True)def __call__(self, *args, **kwargs):self.ini_agent()self.agent.run(kwargs['message'])
我們可以使用智能體總結一個視頻。用戶可以隨意問關于視頻的問題。
首先因為我們需要連續的問智能體關于視頻的問題。 我們希望智能體能以一種相對固定的格式返回答案,所以我們先需要設定一個回答的模板。
def meg_template(self):system_template = """Use the following context to answer the user's question.If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.-----------{question}-----------{chat_history}"""messages = [SystemMessagePromptTemplate.from_template(system_template),HumanMessagePromptTemplate.from_template('{question}')]prompt = ChatPromptTemplate.from_messages(messages)return prompt
接下來,我們需要獲取視頻的內容,并將它存到一個數據庫中,來確保訪問。 首先需要先讀取一個視頻,這里使用油管上的一個隨便的視頻,這里使用一個youtubeLoader.
self.loader = YoutubeLoader.from_youtube_url(video_url)
獲取到視頻內容之后,我們需要將這些內容進行向量化,然后存入 Chroma中。 這里有一點需要注意,因為我們需要用到OpenAI的Embedding,但是這個也是需要收費的。所以我用了sentence_transformer來輸出embedding. 只需要做一個簡單的包裝重寫 embed_query 和embed_documents兩個類函數即可.
class My_embedding():def __init__(self):self.model = SentenceTransformer('all-MiniLM-L6-v2')def embed_query(self,documents):texts = [doc for doc in documents]return self.model.encode(texts, show_progress_bar=False)[0]def embed_documents(self,documents):texts = [doc for doc in documents]return self.model.encode(texts, show_progress_bar=False).tolist()
之后, 我們將數據存入數據庫中:
self.vector_store = Chroma.from_documents(self.data_spilt(),self.embedding_model)self.retriever = self.vector_store.as_retriever()
然后我們使用RetrievalChain去構建這個智能體.
def __call__(self, *args, **kwargs):self.data_spilt()self.store_and_retrive()prompt = self.meg_template()qa = ConversationalRetrievalChain.from_llm(self.llm, self.retriever,condense_question_prompt=prompt)chat_history = []while True:question = input('問題:')# 開始發送問題 chat_history 為必須參數,用于存儲對話歷史result = qa({'question': question, 'chat_history': chat_history})chat_history.append((question, result['answer']))print(result['answer'])




:設計原則(二):DIP、ISP、LoD)











)


