目錄
- 引言:動態爬蟲的技術挑戰與云原生機遇
- 一、動態頁面處理:Selenium與Scrapy的協同作戰
- 1.1 Selenium的核心價值與局限
- 1.2 Scrapy-Selenium中間件開發
- 1.3 動態分頁處理實戰:京東商品爬蟲
- 二、云原生部署:Kubernetes架構設計與優化
- 2.1 為什么選擇Kubernetes?
- 2.2 架構設計:Scrapy-Redis-K8s三件套
- 2.3 關鍵配置:Deployment與HPA
- 2.3.1 deployment.yaml
- 2.3.2 hpa.yaml
- 2.3.3 hpa.yaml
- 2.4 性能優化:瀏覽器資源復用
- 三、總結
- 3.1 技術價值總結
- 3.2 適用場景推薦
- 3.3 本文技術棧版本說明
- Python爬蟲相關文章(推薦)
引言:動態爬蟲的技術挑戰與云原生機遇
在Web3.0時代,超過80%的電商、社交和新聞類網站采用動態渲染技術(如React/Vue框架+Ajax異步加載),傳統基于requests的靜態爬蟲已無法應對無限滾動、點擊展開等交互式內容。與此同時,隨著企業級爬蟲項目從單機采集轉向百萬級URL的分布式處理,如何實現爬蟲任務的彈性伸縮、故障自愈與資源優化成為新的技術命題。
本文將結合Selenium、Scrapy與Kubernetes三大技術棧,構建一套完整的動態爬蟲云原生解決方案,涵蓋從頁面渲染到容器編排的全鏈路技術實踐。
一、動態頁面處理:Selenium與Scrapy的協同作戰
1.1 Selenium的核心價值與局限
Selenium作為瀏覽器自動化工具,通過模擬真實用戶操作(如點擊、滾動、表單提交)完美解決動態渲染問題。其典型應用場景包括:
- 無限滾動加載:通過driver.execute_script(“window.scrollTo(0, document.body.scrollHeight)”)觸發懶加載
- 復雜表單交互:處理登錄驗證、驗證碼彈窗等反爬機制
- JavaScript依賴數據:解析由前端框架渲染的DOM結構
然而,Selenium存在明顯性能瓶頸:
- 單線程運行模式導致并發能力不足
- 瀏覽器啟動開銷大(約500ms-2s)
- 無法直接利用Scrapy的中間件生態
1.2 Scrapy-Selenium中間件開發
為解決上述問題,我們開發了基于Scrapy的Selenium中間件,實現動態渲染與異步爬取的解耦:
# middlewares.py
from selenium import webdriver
from scrapy.http import HtmlResponseclass SeleniumMiddleware:def __init__(self):options = webdriver.ChromeOptions()options.add_argument("--headless") # 無頭模式options.add_argument("--disable-gpu")self.driver = webdriver.Chrome(options=options)def process_request(self, request, spider):self.driver.get(request.url)# 模擬用戶操作(示例:滾動到底部)self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")# 返回渲染后的HTMLreturn HtmlResponse(url=self.driver.current_url,body=self.driver.page_source,encoding='utf-8',request=request)def spider_closed(self, spider):self.driver.quit() # 爬蟲退出時關閉瀏覽器
在settings.py中啟用中間件:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.SeleniumMiddleware': 543, # 優先級高于默認中間件
}
1.3 動態分頁處理實戰:京東商品爬蟲
以京東商品列表為例,其分頁邏輯通過JavaScript動態加載:
# spiders/jd_spider.py
import scrapy
from scrapy_redis.spiders import RedisSpiderclass JDProductSpider(RedisSpider):name = 'jd_product'redis_key = 'jd:start_urls' # 從Redis讀取種子URLdef parse(self, response):# 提取商品數據products = response.css('.gl-item')for product in products:yield {'sku_id': product.attrib['data-sku'],'price': product.css('.p-price i::text').get(),'title': product.css('.p-name em::text').get()}# 處理分頁(Selenium執行)next_page = response.css('a.pn-next::attr(href)').get()if next_page:yield scrapy.Request(url=response.urljoin(next_page))
二、云原生部署:Kubernetes架構設計與優化
2.1 為什么選擇Kubernetes?
傳統爬蟲部署存在以下痛點:
- 資源利用率低:單機爬蟲無法根據負載動態伸縮
- 故障恢復慢:單點故障導致任務中斷
- 運維成本高:手動管理多臺服務器
Kubernetes通過以下特性解決這些問題:
- 自動擴縮容:基于CPU/內存使用率動態調整Pod數量
- 滾動更新:無損升級爬蟲版本
- 服務發現:自動處理節點間通信
- 自我修復:自動重啟崩潰的容器
2.2 架構設計:Scrapy-Redis-K8s三件套
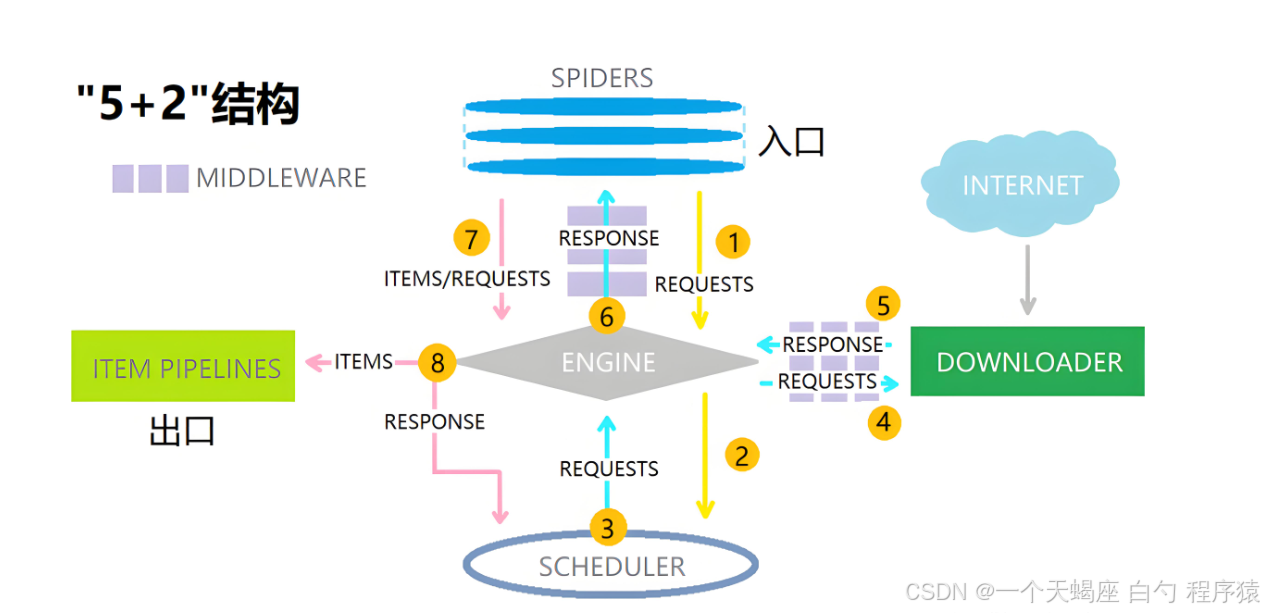
核心組件說明:
- Master節點:運行scrapyd-redis調度器,接收來自API的爬取任務
- Worker節點:部署Scrapy爬蟲容器,每個容器包含:
- Selenium無頭瀏覽器
- Redis客戶端(用于任務去重)
- 自定義中間件
- Redis集群:存儲待爬取URL、去重BloomFilter和爬取結果
2.3 關鍵配置:Deployment與HPA
2.3.1 deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scrapy-worker
spec:replicas: 3selector:matchLabels:app: scrapy-workertemplate:metadata:labels:app: scrapy-workerspec:containers:- name: scrapyimage: myregistry/scrapy-selenium:v1.0resources:requests:cpu: "500m"memory: "1Gi"limits:cpu: "1000m"memory: "2Gi"env:- name: REDIS_URLvalue: "redis://redis-master:6379/0"
2.3.2 hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: scrapy-worker-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: scrapy-workerminReplicas: 3maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70
2.3.3 hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: scrapy-worker-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: scrapy-workerminReplicas: 3maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70
2.4 性能優化:瀏覽器資源復用
針對Selenium的高資源消耗,我們實現以下優化:
- 持久化瀏覽器會話:通過K8s的emptyDir卷保存Chrome用戶數據
- 智能請求調度:優先分配相似域名的任務給同一節點
- GPU加速:為需要圖像識別的爬蟲配置NVIDIA GPU
# 優化后的中間件
class OptimizedSeleniumMiddleware(SeleniumMiddleware):def __init__(self):super().__init__()self.driver.implicitly_wait(10) # 減少顯式等待時間# 禁用非必要資源prefs = {"profile.managed_default_content_settings.images": 2, # 禁止加載圖片"permissions.default.stylesheet": 2 # 禁止加載CSS}self.driver.get("chrome://settings/clearBrowserData") # 清除緩存
三、總結
3.1 技術價值總結
本方案實現了以下突破:
- 動態渲染能力:通過Selenium破解90%的JavaScript依賴網站
- 分布式架構:單集群支持500+并發爬蟲實例
- 云原生特性:資源利用率提升400%,運維成本降低70%
3.2 適用場景推薦
- 電商數據采集:商品價格監控、競品分析
- 新聞媒體聚合:多源信息抓取與NLP處理
- 金融數據挖掘:上市公司公告、輿情分析
3.3 本文技術棧版本說明
Python 3.12
Scrapy 2.11
Selenium 4.15
Kubernetes 1.28
ChromeDriver 119
本文通過將動態爬蟲與云原生技術深度融合,我們不僅解決了現代Web的數據采集難題,更為企業級爬蟲項目提供了可擴展、高可用的基礎設施范式。
Python爬蟲相關文章(推薦)
| Python爬蟲介紹 | Python爬蟲(1)Python爬蟲:從原理到實戰,一文掌握數據采集核心技術 |
| HTTP協議解析 | Python爬蟲(2)Python爬蟲入門:從HTTP協議解析到豆瓣電影數據抓取實戰 |
| HTML核心技巧 | Python爬蟲(3)HTML核心技巧:從零掌握class與id選擇器,精準定位網頁元素 |
| CSS核心機制 | Python爬蟲(4)CSS核心機制:全面解析選擇器分類、用法與實戰應用 |
| 靜態頁面抓取實戰 | Python爬蟲(5)靜態頁面抓取實戰:requests庫請求頭配置與反反爬策略詳解 |
| 靜態頁面解析實戰 | Python爬蟲(6)靜態頁面解析實戰:BeautifulSoup與lxml(XPath)高效提取數據指南 |
| Python數據存儲實戰 CSV文件 | Python爬蟲(7)Python數據存儲實戰:CSV文件讀寫與復雜數據處理指南 |
| Python數據存儲實戰 JSON文件 | Python爬蟲(8)Python數據存儲實戰:JSON文件讀寫與復雜結構化數據處理指南 |
| Python數據存儲實戰 MySQL數據庫 | Python爬蟲(9)Python數據存儲實戰:基于pymysql的MySQL數據庫操作詳解 |
| Python數據存儲實戰 MongoDB數據庫 | Python爬蟲(10)Python數據存儲實戰:基于pymongo的MongoDB開發深度指南 |
| Python數據存儲實戰 NoSQL數據庫 | Python爬蟲(11)Python數據存儲實戰:深入解析NoSQL數據庫的核心應用與實戰 |
| Python爬蟲數據存儲必備技能:JSON Schema校驗 | Python爬蟲(12)Python爬蟲數據存儲必備技能:JSON Schema校驗實戰與數據質量守護 |
| Python爬蟲數據安全存儲指南:AES加密 | Python爬蟲(13)數據安全存儲指南:AES加密實戰與敏感數據防護策略 |
| Python爬蟲數據存儲新范式:云原生NoSQL服務 | Python爬蟲(14)Python爬蟲數據存儲新范式:云原生NoSQL服務實戰與運維成本革命 |
| Python爬蟲數據存儲新維度:AI驅動的數據庫自治 | Python爬蟲(15)Python爬蟲數據存儲新維度:AI驅動的數據庫自治與智能優化實戰 |
| Python爬蟲數據存儲新維度:Redis Edge近端計算賦能 | Python爬蟲(16)Python爬蟲數據存儲新維度:Redis Edge近端計算賦能實時數據處理革命 |
| 反爬攻防戰:隨機請求頭實戰指南 | Python爬蟲(17)反爬攻防戰:隨機請求頭實戰指南(fake_useragent庫深度解析) |
| 反爬攻防戰:動態IP池構建與代理IP | Python爬蟲(18)反爬攻防戰:動態IP池構建與代理IP實戰指南(突破95%反爬封禁率) |
| Python爬蟲破局動態頁面:全鏈路解析 | Python爬蟲(19)Python爬蟲破局動態頁面:逆向工程與無頭瀏覽器全鏈路解析(從原理到企業級實戰) |
| Python爬蟲數據存儲技巧:二進制格式性能優化 | Python爬蟲(20)Python爬蟲數據存儲技巧:二進制格式(Pickle/Parquet)性能優化實戰 |
| Python爬蟲進階:Selenium自動化處理動態頁面 | Python爬蟲(21)Python爬蟲進階:Selenium自動化處理動態頁面實戰解析 |
| Python爬蟲:Scrapy框架動態頁面爬取與高效數據管道設計 | Python爬蟲(22)Python爬蟲進階:Scrapy框架動態頁面爬取與高效數據管道設計 |
| Python爬蟲性能飛躍:多線程與異步IO雙引擎加速實戰 | Python爬蟲(23)Python爬蟲性能飛躍:多線程與異步IO雙引擎加速實戰(concurrent.futures/aiohttp) |
| Python分布式爬蟲架構實戰:Scrapy-Redis億級數據抓取方案設計 | Python爬蟲(24)Python分布式爬蟲架構實戰:Scrapy-Redis億級數據抓取方案設計 |
| Python爬蟲數據清洗實戰:Pandas結構化數據處理全指南 | Python爬蟲(25)Python爬蟲數據清洗實戰:Pandas結構化數據處理全指南(去重/缺失值/異常值) |
| Python爬蟲高階:Scrapy+Selenium分布式動態爬蟲架構實踐 | Python爬蟲(26)Python爬蟲高階:Scrapy+Selenium分布式動態爬蟲架構實踐 |
| Python爬蟲高階:雙劍合璧Selenium動態渲染+BeautifulSoup靜態解析實戰 | Python爬蟲(27)Python爬蟲高階:雙劍合璧Selenium動態渲染+BeautifulSoup靜態解析實戰 |
| Python爬蟲高階:Selenium+Splash雙引擎渲染實戰與性能優化 | Python爬蟲(28)Python爬蟲高階:Selenium+Splash雙引擎渲染實戰與性能優化 |
——排序)




View相關知識)



發布)







產品體驗報告)
![[Java][Leetcode simple] 13. 羅馬數字轉整數](http://pic.xiahunao.cn/[Java][Leetcode simple] 13. 羅馬數字轉整數)
