目錄
一、引言
二、LLaVA與LLaMA的定義
2.1 LLaMA
2.2 LLaVA
2.3 LLaVA-NeXT 的技術突破
三、產生的背景
3.1 LLaMA的背景
3.2? LLaVA的背景
四、與其他競品的對比
4.1? LLaMA的競品
4.2? LLaVA的競品
五、應用場景
5.1? LLaMA的應用場景
5.2 LLaVA的應用場景
六、LLaVA和LLaMA的學習地址與開源情況
6.1? LLaMA 和 Llama 4
6.2 LLaVA
七、結語

🎬 攻城獅7號:個人主頁
🔥 個人專欄:《AI前沿技術要聞》
?? 君子慎獨!
?🌈 大家好,歡迎來訪我的博客!
?? 此篇文章主要介紹 LLaVA與LLaMA
📚 本期文章收錄在《AI前沿技術要聞》,大家有興趣可以自行查看!
?? 歡迎各位 ?? 點贊 👍 收藏 ?留言 📝!
?一、引言
????????隨著人工智能技術的飛速發展,大語言模型(Large Language Models, LLMs)已成為自然語言處理(NLP)領域的核心驅動力。近年來,多模態大語言模型(Multimodal Large Language Models, MLLMs)的出現,進一步拓展了AI的應用邊界。其中,LLaVA(Large Language and Vision Assistant)和LLaMA(Large Language Model Meta AI)作為兩個備受矚目的模型,不僅在學術界引發了廣泛討論,也在工業界掀起了新一輪的技術革新。本文將詳細介紹LLaVA和LLaMA的定義、背景、競品對比、應用場景以及使用方法,幫助讀者全面了解這兩個模型的特點和潛力。
二、LLaVA與LLaMA的定義
2.1 LLaMA
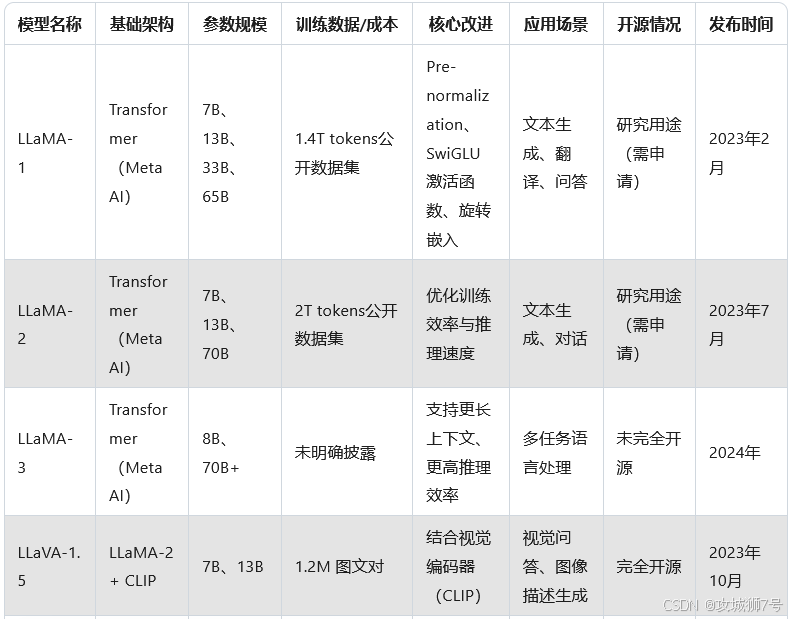
????????LLaMA(Large Language Model Meta AI)是由Meta AI(原Facebook AI)開發的開源大語言模型。它基于Transformer架構,通過大規模預訓練和微調,能夠生成高質量的自然語言文本。LLaMA的設計初衷是提供一個高效、可擴展的模型,以支持各種NLP任務,如文本生成、問答、翻譯等。LLaMA的開源特性使其成為學術界和工業界研究的熱點,也為后續的多模態模型奠定了基礎。
????????在2024年4月,Meta發布了第四代Llama系列模型——Llama 4,這是一個具有重大突破的多模態模型系列。Llama 4系列包括三個主要模型:
(1)Llama 4 Scout:
?? - 170億活躍參數,16個專家
?? - 支持1000萬token的上下文窗口
?? - 可在單個NVIDIA H100 GPU上運行
?? - 性能優于Gemma 3和Gemini 2.0 Flash-Lite
(2) Llama 4 Maverick:
?? - 170億活躍參數,128個專家
?? - 總參數量達4000億
?? - 性能超越GPT-4o和Gemini 2.0 Flash
?? - ELO評分達1417,展現卓越的性能成本比
(3)Llama 4 Behemoth:
?? - 2880億活躍參數,近2萬億總參數
?? - 在數學、多語言和圖像基準測試中超越GPT-4.5
?? - 作為teacher模型用于知識蒸餾
Llama 4系列的主要技術特點:
- 原生多模態架構:在模型結構層面融合文本、圖像和視頻輸入
- 混合專家(MoE)架構:顯著降低計算開銷和部署門檻
- iRoPE位置編碼:支持超長上下文處理
- 高效訓練體系:
? - 使用超過30萬億tokens的多語種數據
? - 支持FP8精度訓練
? - 采用MetaP技術優化訓練過程
- 全面的安全機制:
? - Llama Guard和Prompt Guard提供安全防護
? - GOAT系統增強紅隊測試
? - 顯著降低敏感話題的拒答率
2.2 LLaVA
????????LLaVA(Large Language and Vision Assistant)是由威斯康星大學麥迪遜分校、微軟研究院和哥倫比亞大學的研究人員共同設計的多模態大語言模型。它基于LLaMA的架構,通過引入視覺編碼器(如CLIP或DALL-E),能夠同時處理文本和圖像輸入,生成與圖像相關的自然語言描述或回答。LLaVA的目標是構建一個能夠理解、分析和生成多模態內容的AI助手,為用戶提供更豐富的交互體驗。
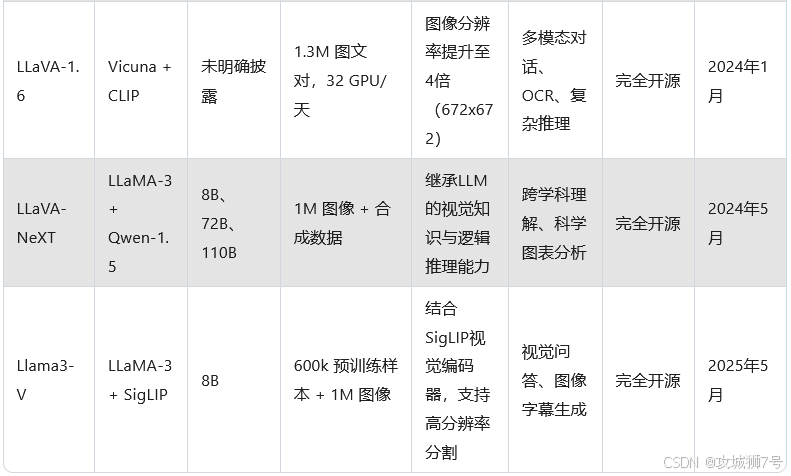
????????在2024年,LLaVA迎來了重大升級,推出了LLaVA-NeXT版本。這個新版本由字節跳動、香港科技大學和南洋理工大學的研究人員共同開發,采用了最新的LLaMA-3(8B)和Qwen-1.5(72B & 110B)作為基礎語言模型,顯著提升了多模態能力。LLaVA-NeXT在多項基準測試中展現出與GPT-4V相當的性能,同時保持了高效訓練的特點,最大的110B參數版本僅需在128臺H800服務器上訓練18小時即可完成。
2.3 LLaVA-NeXT 的技術突破
(1)模型架構與訓練
- 模型規模:提供三種參數規模版本
? - LLaMA-3-LLaVA-NeXT-8B
? - LLaVA-NeXT-72B
? - LLaVA-NeXT-110B
- 訓練效率:
? - 8B版本:8個A100-80G GPU,20小時
? - 72B版本:64個A100-80G GPU,18小時
? - 110B版本:128個H800-80G GPU,18小時
- 訓練數據:
? - 第一階段:558K樣本
? - 第二階段:790K樣本
? - 總訓練數據:1348K樣本
(2)評估基準與性能
LLaVA-NeXT在多個關鍵基準測試中展現出卓越性能:
1. MMMU(跨學科理解):評估模型在跨學科領域的理解能力
2. Mathvista(視覺數學推理):測試模型在視覺數學問題上的推理能力
3. AI2D(科學圖表理解):評估模型對科學圖表的理解能力
4. LLaVA-Bench(Wilder):專門用于評估日常視覺對話場景的新基準
(3) LLaVA-Bench(Wilder)數據集
這是一個專門用于評估多模態模型在日常視覺對話場景中表現的新基準:
- 數據集規模:
? - 輕量級版本:120個測試案例
? - 進階版本:1020個測試案例
- 數據特點:
? - 覆蓋數學解題、圖像解讀、代碼生成等多個場景
? - 數據來源于真實用戶需求
? - 經過嚴格的隱私保護和風險評估
? - 參考答案由GPT-4V生成并經過人工驗證
- 評估方法:
? - 采用GPT-4V作為評分標準
? - 直接比較模型回答與參考答案的匹配度
? - 確保評分標準的一致性和公平性
(4)性能對比
LLaVA-NeXT在各項基準測試中展現出與GPT-4V相當的性能:
- 多模態理解:在視覺-語言任務中達到最先進水平
- 推理能力:在復雜場景下的邏輯推理能力顯著提升
- 知識應用:在跨學科知識應用方面表現優異
- 實際應用:在日常對話場景中展現出強大的實用性
三、產生的背景
3.1 LLaMA的背景
????????LLaMA的誕生源于Meta AI對開源AI技術的追求。在2023年,Meta AI發布了LLaMA模型,旨在推動AI技術的民主化和透明化。LLaMA的開源特性使其成為學術界和工業界研究的熱點,也為后續的多模態模型奠定了基礎。LLaMA的設計理念是提供一個高效、可擴展的模型,以支持各種NLP任務,如文本生成、問答、翻譯等。
3.2? LLaVA的背景
????????LLaVA的出現是AI技術向多模態方向發展的必然結果。隨著計算機視覺和自然語言處理技術的成熟,研究者們開始探索如何將這兩種能力結合起來,構建更智能的AI系統。LLaVA基于LLaMA的架構,通過引入視覺編碼器,能夠同時處理文本和圖像輸入,生成與圖像相關的自然語言描述或回答。LLaVA的目標是構建一個能夠理解、分析和生成多模態內容的AI助手,為用戶提供更豐富的交互體驗。
四、與其他競品的對比
4.1? LLaMA的競品
????????- GPT-4:由OpenAI開發,是目前最強大的大語言模型之一,支持多模態輸入,但未開源。
????????- Claude:由Anthropic開發,專注于安全性和可控性,支持多模態輸入,但未開源。
????????- PaLM:由Google開發,支持多模態輸入,但未開源。
????????LLaMA的優勢在于其開源特性,使得研究者可以自由使用和修改模型,推動AI技術的民主化和透明化。
4.2? LLaVA的競品
????????- GPT-4V:OpenAI的多模態模型,支持圖像和文本輸入,但未開源。
????????- Claude 3 Opus:Anthropic的多模態模型,支持圖像和文本輸入,但未開源。
????????- PaLM 2:Google的多模態模型,支持圖像和文本輸入,但未開源。
????????LLaVA的優勢在于其開源特性,使得研究者可以自由使用和修改模型,推動AI技術的民主化和透明化。
五、應用場景
5.1? LLaMA的應用場景
????????- 文本生成:LLaMA可以生成高質量的自然語言文本,適用于內容創作、廣告文案、新聞報道等。
????????- 問答系統:LLaMA可以回答用戶的問題,適用于客服機器人、教育輔導、知識庫等。
????????- 翻譯:LLaMA可以翻譯不同語言之間的文本,適用于跨語言交流、國際化產品等。
5.2 LLaVA的應用場景
????????- 圖像描述:LLaVA可以生成與圖像相關的自然語言描述,適用于圖像標注、內容審核、社交媒體等。
????????- 視覺問答:LLaVA可以回答與圖像相關的問題,適用于教育輔導、醫療診斷、智能客服等。
????????- 多模態交互:LLaVA可以同時處理文本和圖像輸入,生成多模態內容,適用于虛擬助手、智能家居、自動駕駛等。
六、LLaVA和LLaMA的學習地址與開源情況
6.1? LLaMA 和 Llama 4
- 學習地址:
? - 官方下載:[Meta AI官網](https://llama.meta.com/)
? - Hugging Face:[Meta Llama](https://huggingface.co/meta-llama)
? - 在線體驗:[Meta AI](https://ai.meta.com/)
- 開源情況:LLaMA和Llama 4都是開源的,研究者可以自由使用和修改模型。
- Llama 4特性:
? - 多模態能力:原生支持文本、圖像和視頻處理
? - 超長上下文:支持高達1000萬token的上下文窗口
? - 高效推理:采用MoE架構,顯著降低計算開銷
? - 安全機制:提供全面的安全防護和合規治理
? - 應用場景:支持多文檔摘要、代碼處理、圖像理解等
6.2 LLaVA
- 學習地址:
? - 論文鏈接:[LLaVA 論文](https://arxiv.org/pdf/2304.08485.pdf)
? - 項目鏈接:[LLaVA 項目](https://llava-vl.github.io/)
? - GitHub 地址:[LLaVA GitHub](https://github.com/haotian-liu/LLaVA)
? - LLaVA-NeXT GitHub:[LLaVA-NeXT GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT)
? - Demo 鏈接:[LLaVA-NeXT Demo](https://llava-next.lmms-lab.com/)
- 開源情況:LLaVA 和 LLaVA-NeXT 都是開源的,研究者可以自由使用和修改模型。
- LLaVA-NeXT 特性:
? - 模型規模:提供8B、72B和110B三種參數規模
? - 訓練效率:最大模型僅需18小時訓練時間
? - 性能提升:在多項基準測試中達到與GPT-4V相當的水平
? - 評估基準:包含LLaVA-Bench(Wilder)等新的評估數據集
? - 應用場景:優化了視覺對話功能,滿足多樣化的現實場景需求
? - 開源資源:
??? - 代碼倉庫:[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT)
??? - 在線演示:[Demo](https://llava-next.lmms-lab.com/)
??? - 評估數據集:[Hugging Face](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild)
?七、結語
????????LLaVA和LLaMA作為多模態大語言模型的代表,不僅推動了AI技術的發展,也為用戶提供了更豐富的交互體驗。特別是LLaVA-NeXT的推出,通過整合最新的語言模型技術,進一步縮小了開源模型與私有模型之間的性能差距。它們的開源特性使得研究者可以自由使用和修改模型,推動AI技術的民主化和透明化。未來,隨著技術的不斷進步,LLaVA和LLaMA將在更多領域發揮重要作用,為人類帶來更智能、更便捷的生活。
看到這里了還不給博主點一個:
?? 點贊??收藏 ?? 關注!
💛 💙 💜 ?? 💚💓 💗 💕 💞 💘 💖
再次感謝大家的支持!
你們的點贊就是博主更新最大的動力!
)














 與 torch.no_grad() PyTorch 中的區別與應用)



 -- noogle DefCamp 2024)