正常是4個類別:
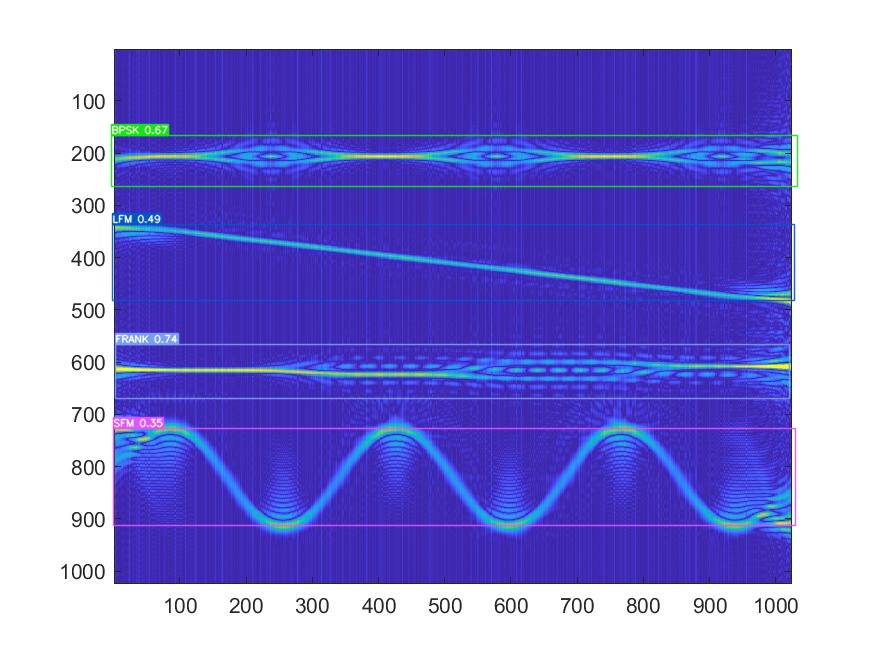
但是YOLOv7訓練完后預測總是只有兩個類別:
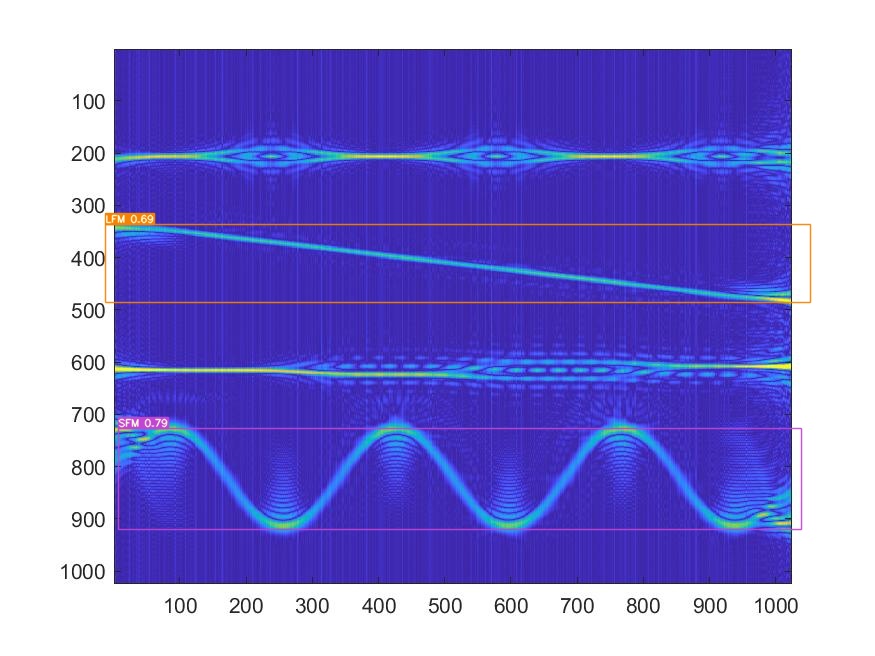
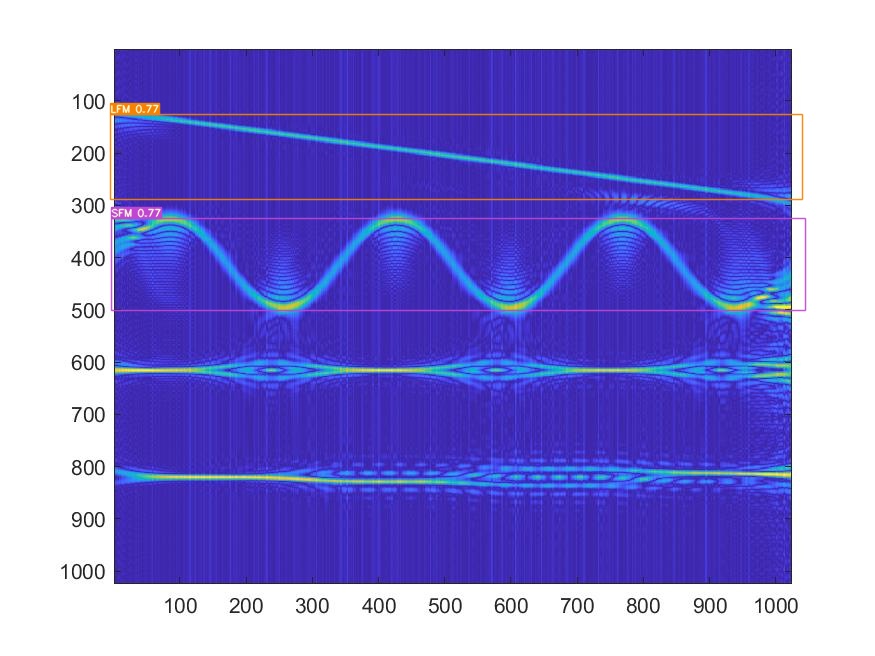
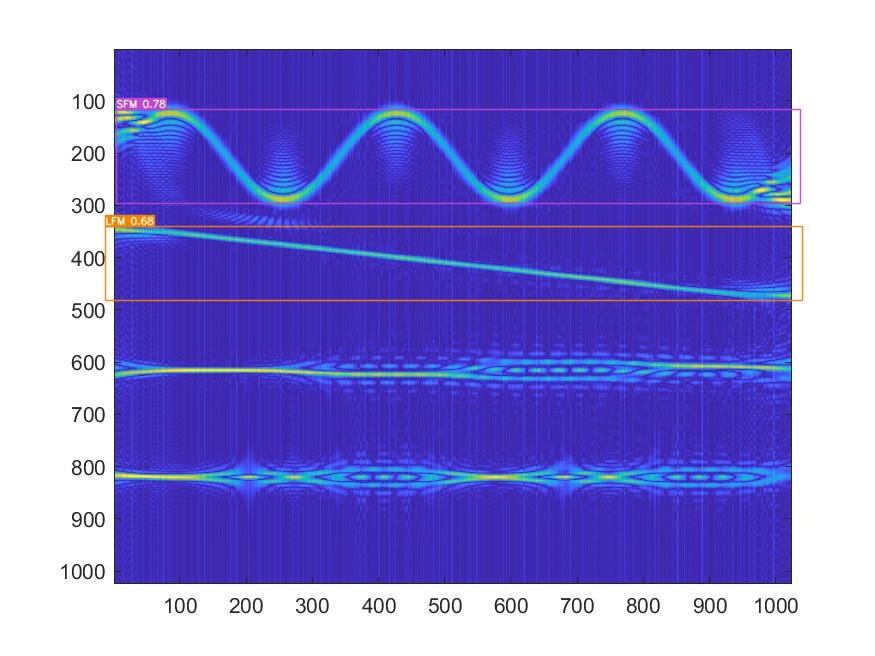
而且都是LFM和SFM
我一開始檢查了下特征圖大小,如果輸入是640*640的話,三個尺度特征圖是80*80,40*40,20*20;如果輸入是416*416的話,三個尺度特征圖是52*52,26*26,13*13。我一開始以為是信號太窄了,特征圖大小設置有問題,但實際上在YOLOv3,YOLOv10下用的同樣大小的特征圖,YOLOv3,YOLOv10挺好使的。
后來檢查了下anchors,用的是YOLO默認的anchors大小,和YOLOv3下用的一樣(YOLOv3好使,別問YOLOv10下多少,YOLOv10是anchor-free的)
anchors =
array([
[ 10., 13.],[ 16., 30.],[ 33., 23.],
[ 30., 61.],[ 62., 45.],[ 59., 119.],
[116., 90.],[156., 198.],[373., 326.]
])
最后發現可能是detect.py下conf-thres參數的問題,這個參數不能太高,一開始我設的0.5,后來調到0.1就好了,設0.5的時候其實還是有極少的BPSK,Frank的類別是預測出來了的
if __name__ == '__main__':parser.add_argument('--conf-thres', type=float, default=0.1, help='object confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.3, help='IOU threshold for NMS')除了conf-thres,以下內容也是我檢查過程中總結出來需要注意的
首先注意類別預測濾波器不要開
if __name__ == '__main__':parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')NMS操作時可以不使用classes參數?
# Apply NMS
# pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, agnostic=opt.agnostic_nms)另外一個就是YOLOv7的train.py下有這么兩句話
# hyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layers
# hyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layers
hyp['cls'] *= nc / 4. * 3. / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 416) ** 2 * 3. / nl # scale to image size and layers類別數和圖片大小記得改成自己的
某段時間我以為是那兩個預測出來的類訓練的不好,于是我記錄了訓練過程的各個類的loss值
具體方法是在:yolov7主路徑/utils/loss.py下面寫了一個函數
def save_every_class_loss_txt(self,pred_class, t):# zhouzhichao# 計算每個類別的損失self.class_loss_save_times = self.class_loss_save_times + 1# print("self.class_loss_save_times:",self.class_loss_save_times)if self.class_loss_save_times%50!=0:returnTXT_PATH = "D:\實驗室\論文\論文-多信號參數估計\實驗\YOLOv7\yolov7-main\\runs\class_loss.txt"class_losses = []for c in range(4):ps_c = pred_class[:, c] # 提取第c個類別的預測t_c = t[:, c] # 提取第c個類別的真值loss_c = self.BCEcls(ps_c, t_c) # 計算單類別損失# class_losses.append(round(loss_c.item(), 3)) # 保留4位小數class_losses.append(f"{loss_c.item():.3f}") # 使用 f-string 格式化# 轉換為制表符分隔的字符串line = "\t".join(class_losses) + "\n"# 追加寫入文件with open(TXT_PATH, "a", encoding="utf-8") as f:f.write(line)class ComputeLossOTA:# Compute lossesdef __init__(self, model, autobalance=False):super(ComputeLossOTA, self).__init__()device = next(model.parameters()).device # get model deviceh = model.hyp # hyperparametersself.class_loss_save_times = 0函數在ComputeLossOTA的__call__下調用:
# Classification
selected_tcls = targets[i][:, 1].long()
if self.nc > 1: # cls loss (only if multiple classes)t = torch.full_like(ps[:, 5:], self.cn, device=device) # targetst[range(n), selected_tcls] = self.cplcls += self.BCEcls(ps[:, 5:], t) # BCEself.save_every_class_loss_txt(ps[:, 5:], t)原本計算的是全部類別的損失值:?
lcls += self.BCEcls(ps[:, 5:], t) # BCE我就拓展了下寫出了save_every_class_loss_txt函數用于記錄訓練過程每個類別的損失值
畫圖的話就從txt里復制,粘貼到excel或origin都行,如下圖
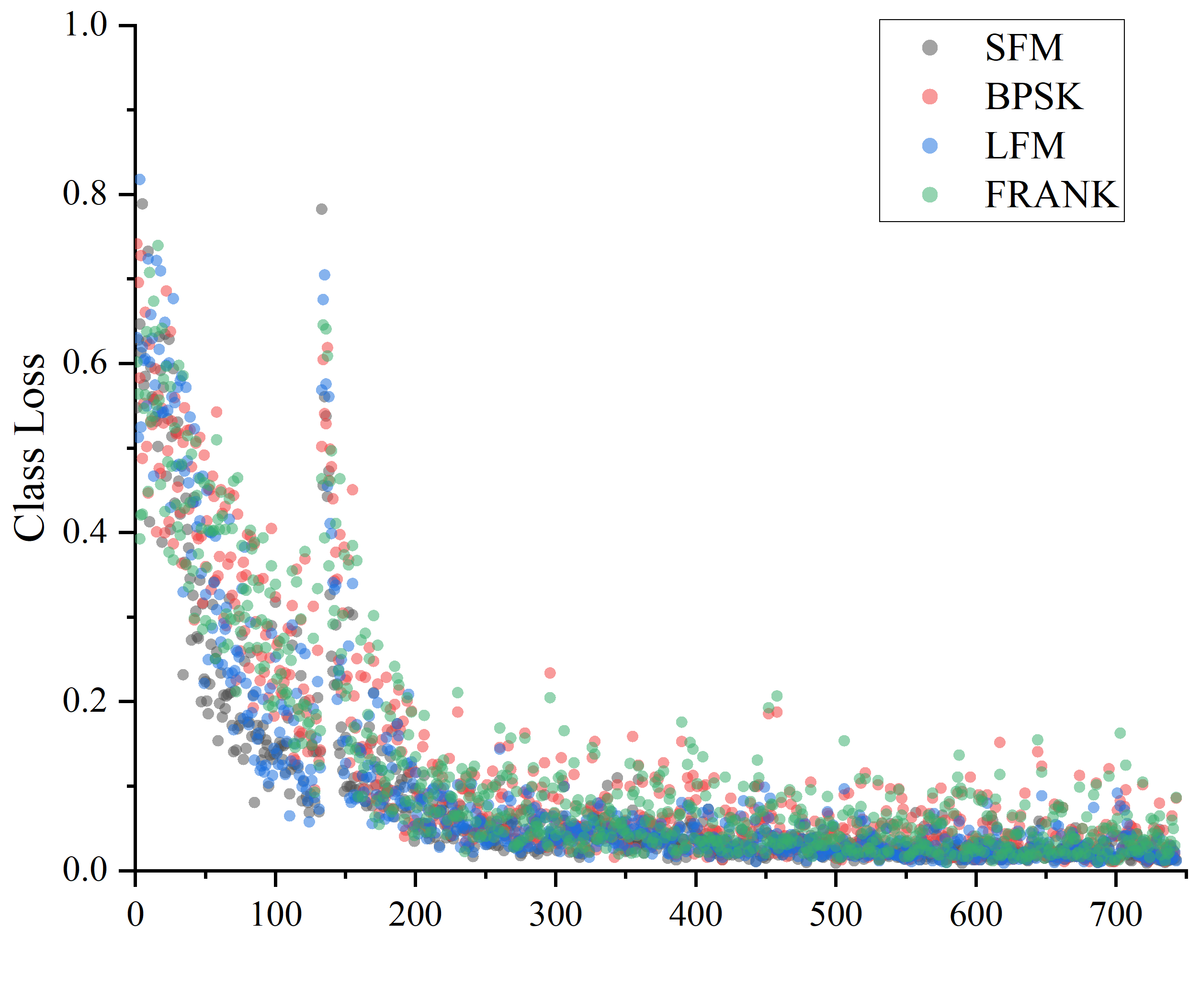
發現所有類別的損失值下降趨勢看起來并沒什么問題
這也使得我將預測類別缺失的問題限制在預測的閾值和Iou值設置上面了,最終調整閾值解決了問題












 與 torch.no_grad() PyTorch 中的區別與應用)



 -- noogle DefCamp 2024)


