【LLM】大模型算力基礎設施——核心硬件GPU/TPU,架構技術NVLink/RDMA,性能指標FP64/FLOPS(NVIDIA Tesla型號表)
文章目錄
- 1、核心硬件GPU/TPU,NVIDIA Tesla
- 2、集群架構設計 NVLink / RDMA / Alluxio
- 3、性能關鍵指標,FP64 / FLOPS
1、核心硬件GPU/TPU,NVIDIA Tesla
核心硬件 chip
- GPU(圖形處理器)
代表:NVIDIA A100/H100、AMD MI300X
優勢:萬級CUDA核心(A100含6912個核心),顯存帶寬達2TB/s(H100),支持TF32/FP64混合精度計算
適用場景:深度學習訓練、大規模并行計算 - TPU(張量處理器)
代表型號:谷歌 v4版本達275 TFLOPS(BF16)
特點:脈動陣列架構優化矩陣運算,片上內存集成(減少數據搬運延遲) - ASIC(專用 chip )
Tesla Dojo(1.1 EFLOPS算力集群) - FPGA(現場可編程門陣列)
應用:微軟Brainwave項目
優勢:低延遲推理(可編程邏輯單元實現定制化計算) - CPU協同計算
AMD EPYC 9754(128核Zen4架構)
Intel Sapphire Rapids(AMX指令集加速AI)
NVIDIA 顯卡型號
-
NVIDIA將顯示核心分為三大系列。GeForce個人家用;Quadro專業繪圖設計;Tesla大規模的并聯電腦運算。 1
-
Tesla類型: 1
K-Series(Kepler架構2012):K8、K10、K20c、K20s、K20m、K20Xm、K40t、K40st、K40s、K40m、K40c、K520、K80
P-Series(Pascal架構2016):P4、P6、P40、P100
V-Series(Volta架構2017):V100
T-Series(Turing架構2018):T4
A-Series(Ampere架構2020):A10、A16、A30、A40、A100、A800
H-Series(Hopper架構2022): H20,H100,H200
L-Series(Ada Lovelace架構2023):L40,L4,L20 -
Quadro類型
NVIDIA RTX Series:RTX A2000、RTX A4000、RTX A4500、RTX A5000、RTX A6000
Quadro RTX Series:RTX 3000、RTX 4000、RTX 5000、RTX 6000、RTX 8000 -
GeForce類型:
Geforce 10:GTX 1050、GTX 1050Ti、GTX 1060、GTX 1070、GTX 1070Ti、GTX 1080、GTX 1080Ti
Geforce 16:GTX 1650、GTX 1650 Super、GTX 1660、GTX 1660 Super、GTX 1660Ti
Geforce 20:RTX 2060、RTX 2060 Super、RTX 2070、RTX 2070 Super、RTX 2080、RTX 2080 Super、RTX 2080Ti
Geforce 30:RTX 3050、RTX 3060、RTX 3060Ti、RTX 3070、RTX 3070Ti、RTX 3080、RTX 3080Ti、RTX 3090 RTX 3090Ti
Geforce 40:RTX 4090 …
Geforce 50:RTX 5090 …
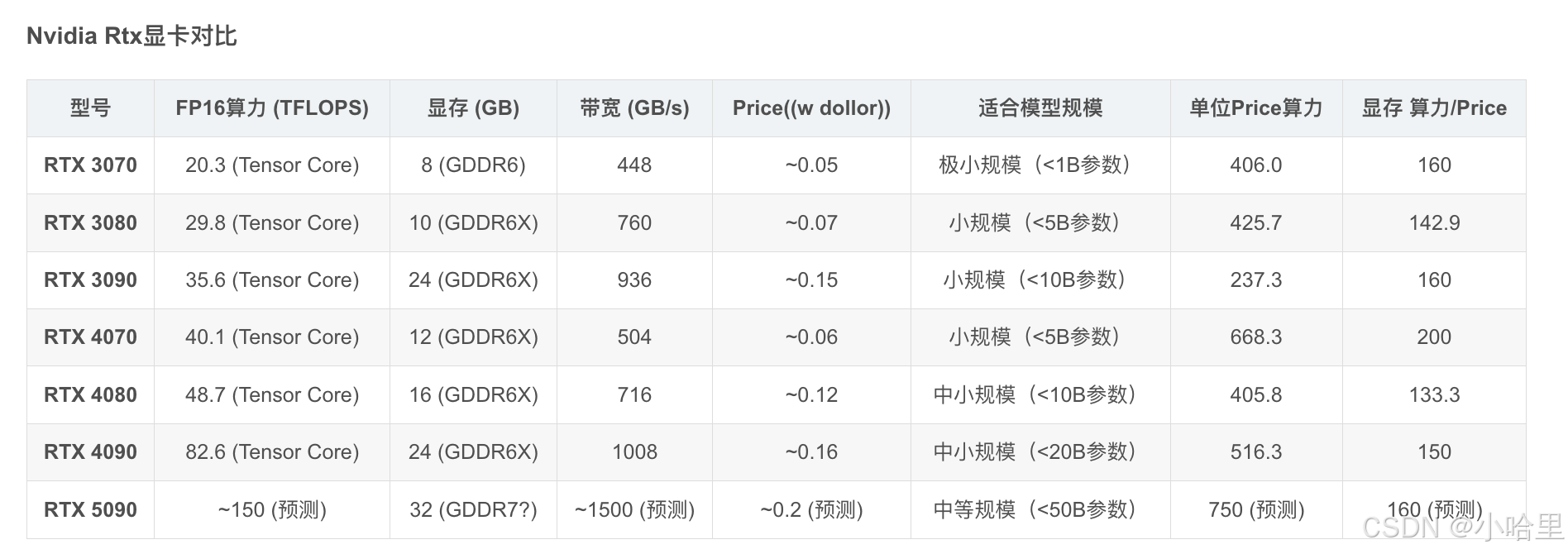
顯卡天梯圖 :1, 2, 3 -
通用的 GPU 中包含三種核心
分別是 CUDA Core、Tensor Core 和 RT Core,這三種核心各自具有不同的特性和功能。
CUDA Core:CUDA Core 是用于通用并行計算任務的計算核心,可以執行單精度和雙精度浮點運算,以及整數運算。它在處理廣泛的并行計算任務方面非常高效。
Tensor Core:Tensor Core 是針對深度學習和 AI 工作負載而設計的專用核心,可以實現混合精度計算并加速矩陣運算,尤其擅長處理半精度(FP16)和全精度(FP32)的矩陣乘法和累加操作。Tensor Core 在加速深度學習訓練和推理中發揮著重要作用。
RT Core:RT Core 是專門用于光線追蹤處理的核心,能夠高速進行光線和聲音的渲染,對于圖形渲染和光線追蹤等任務具有重要意義
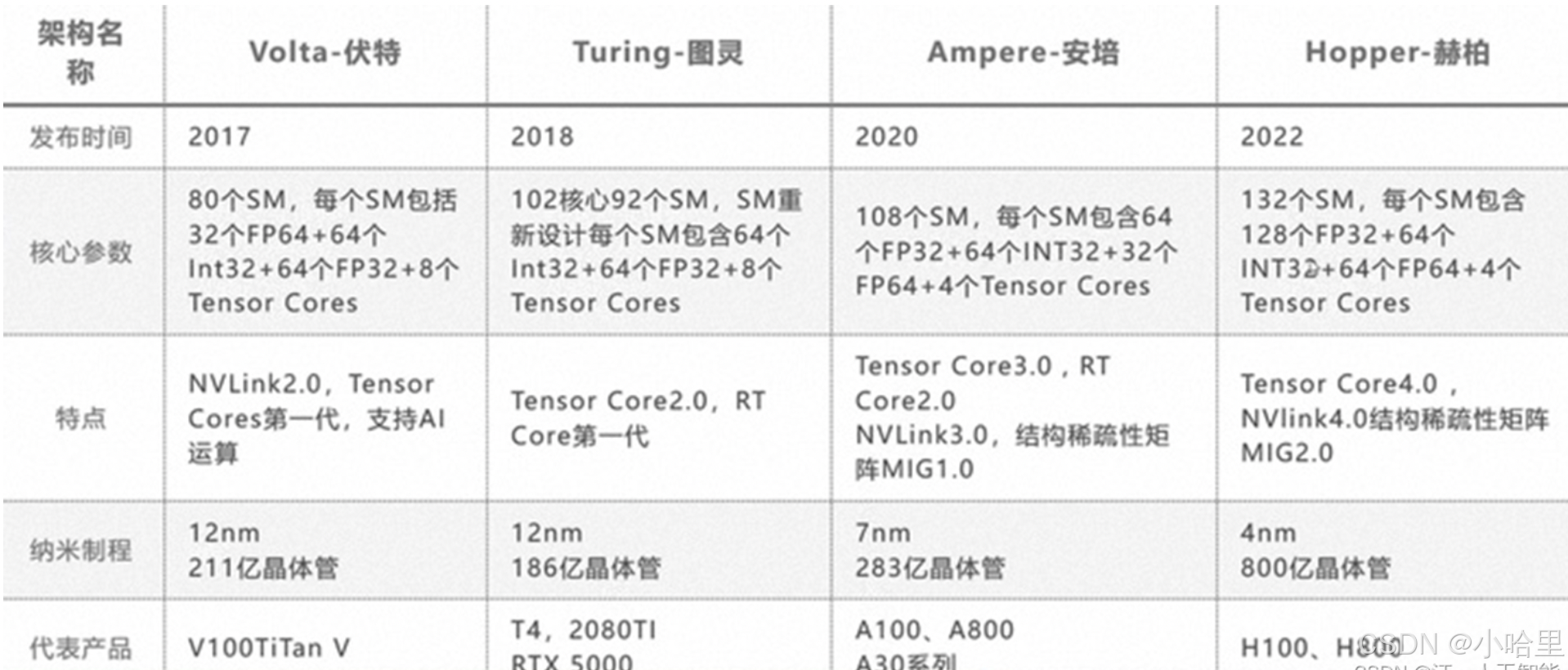

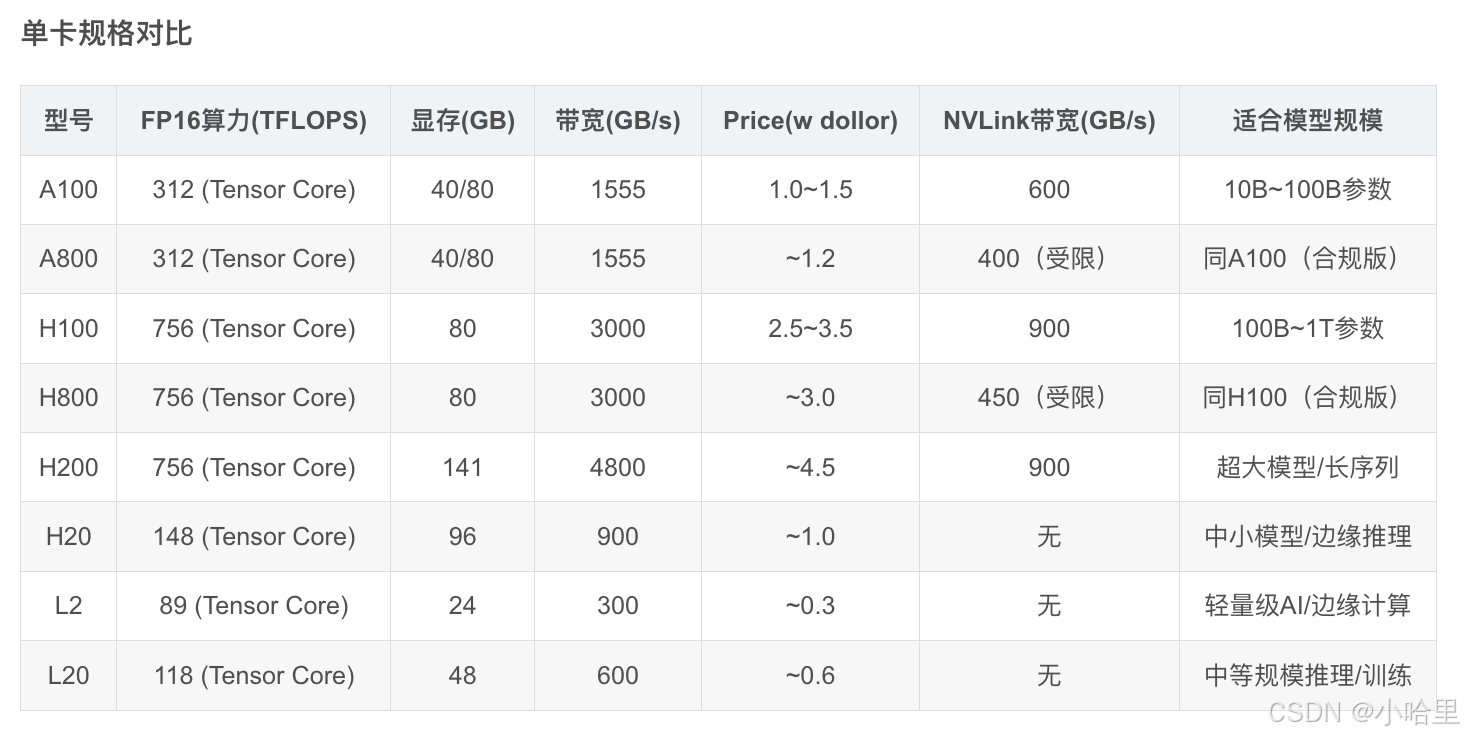
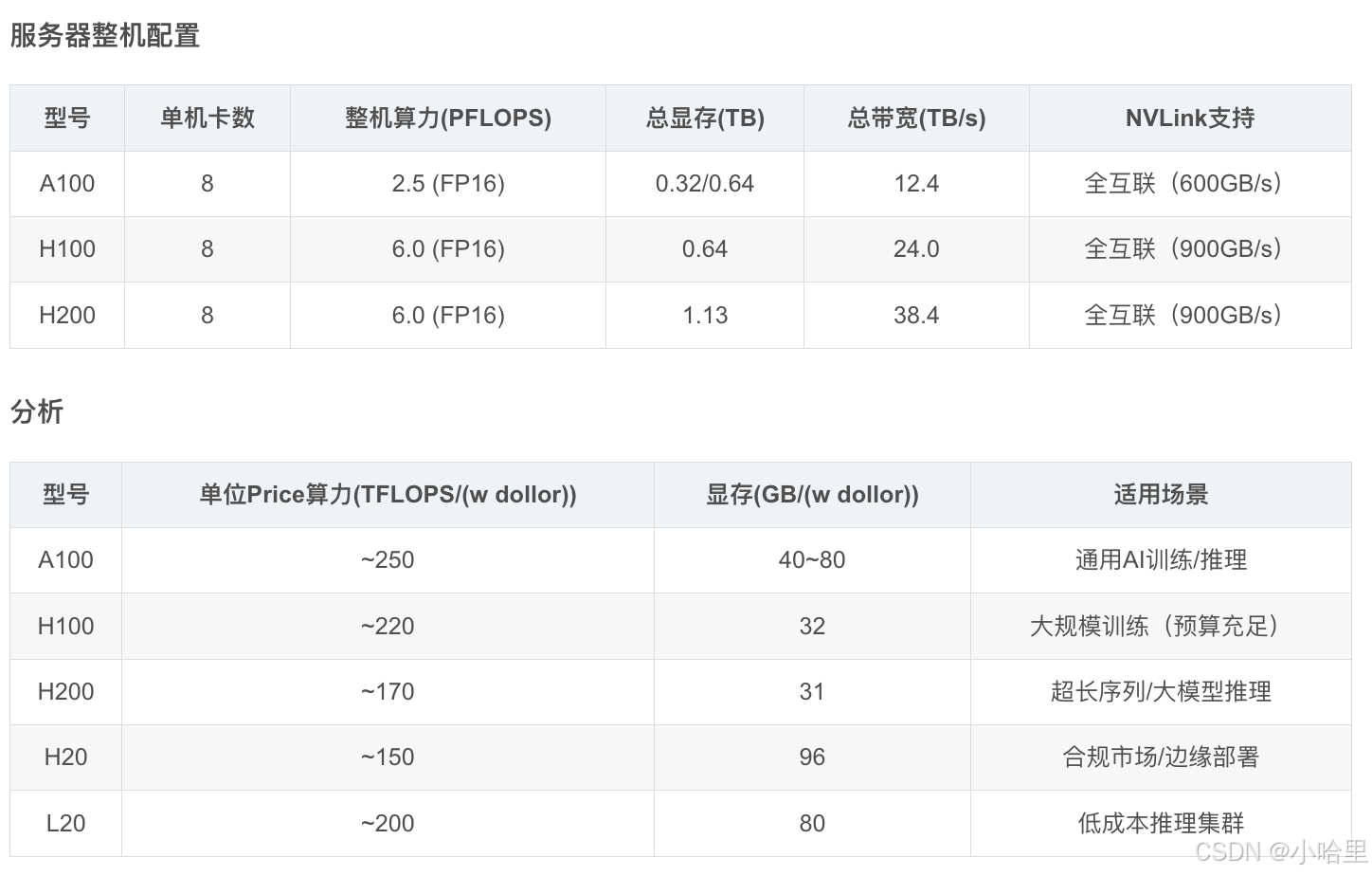
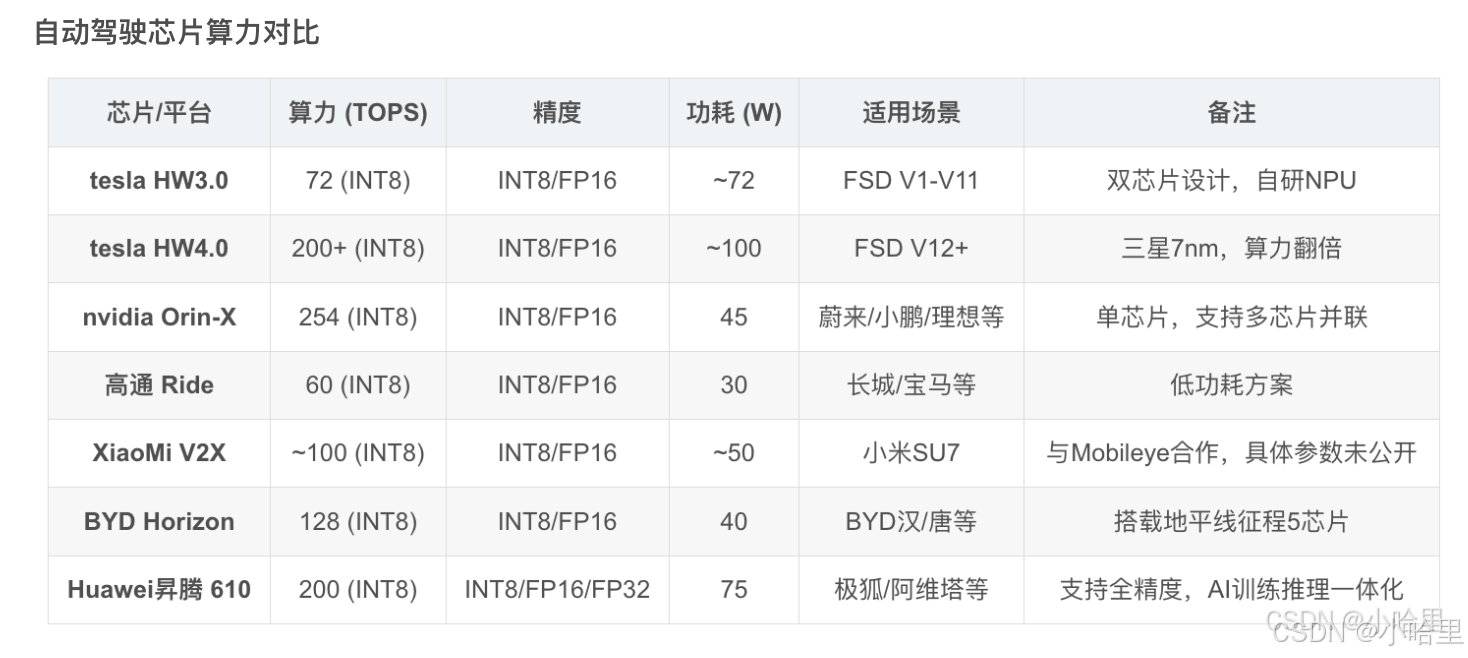
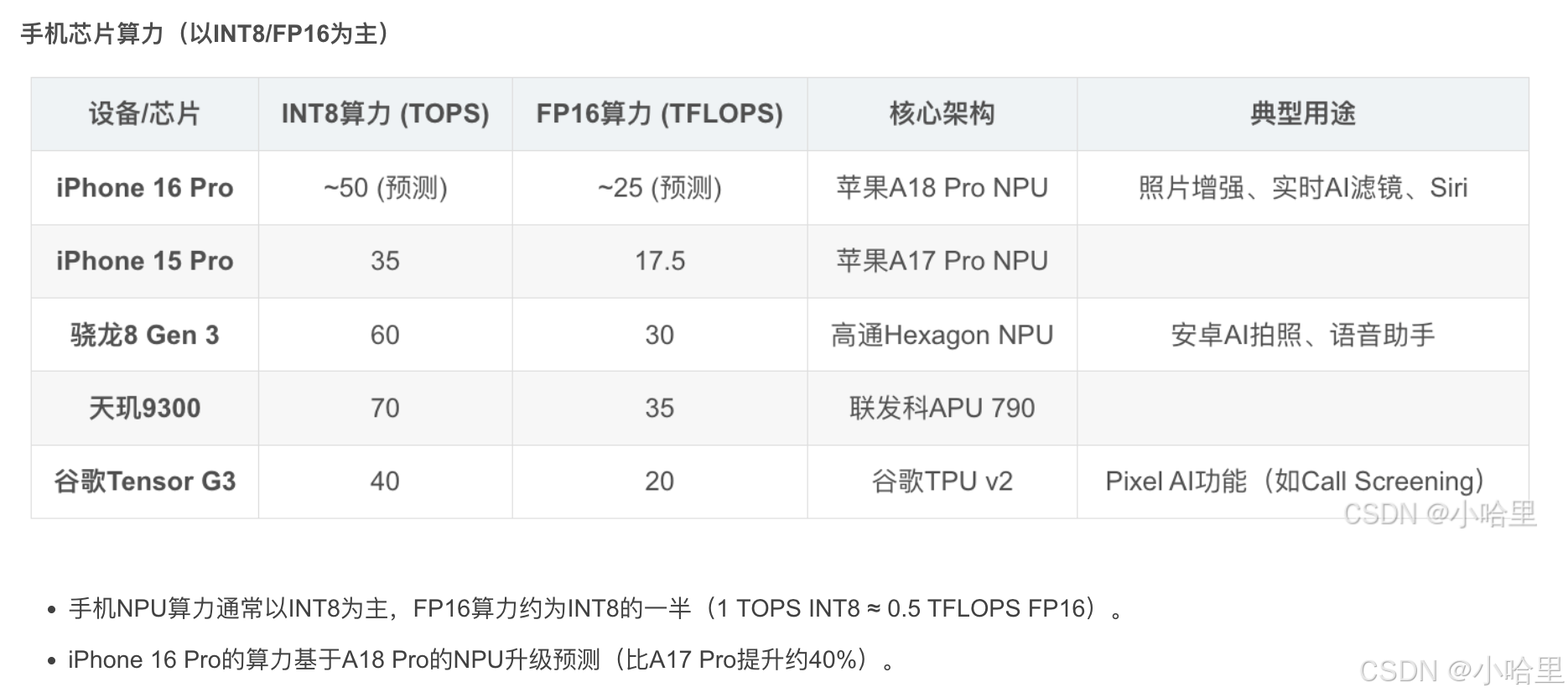
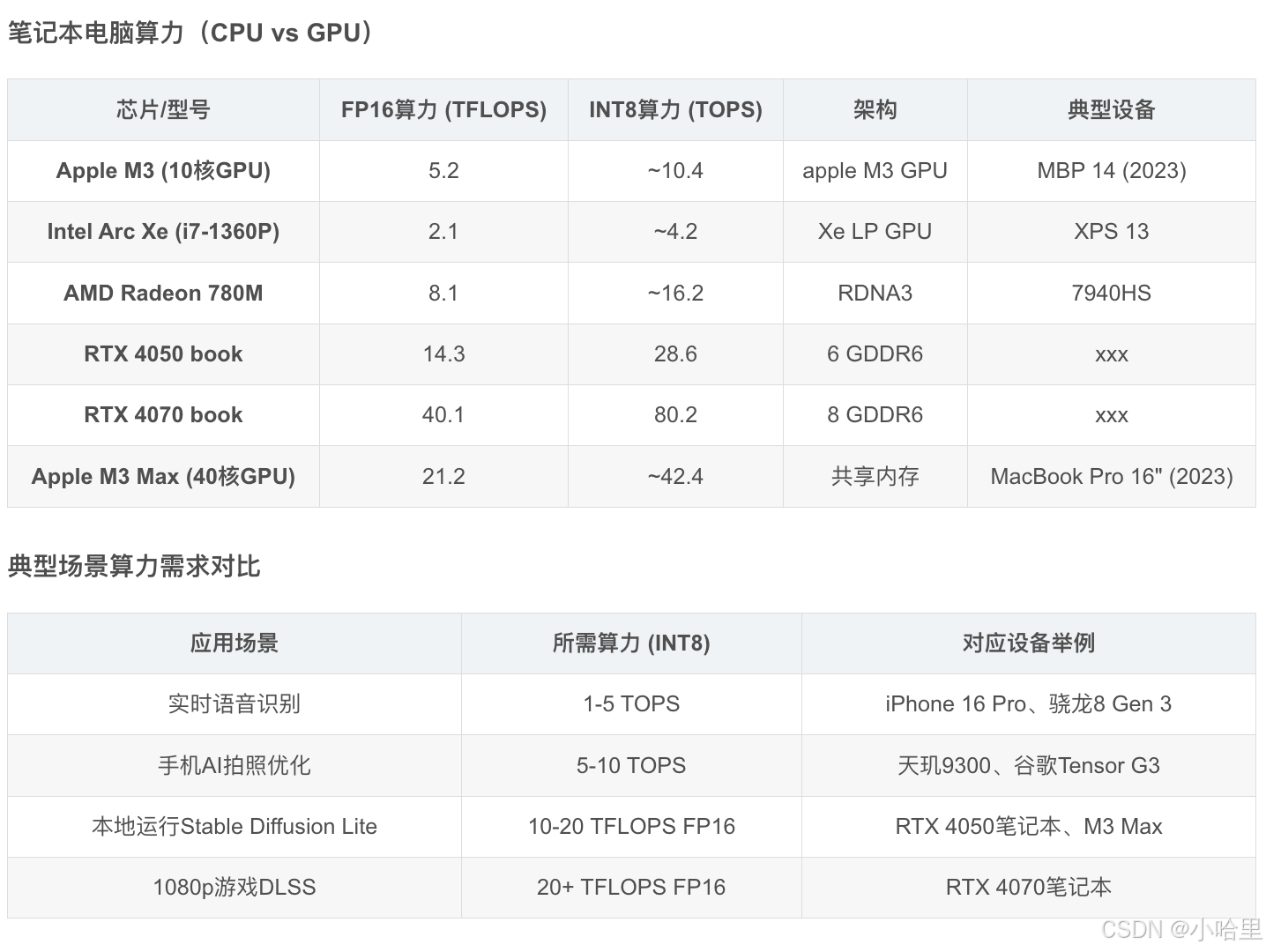
nvidia Tesla近3年型號(含A100, A800, H800, H100, H200, H20, L2, L20)

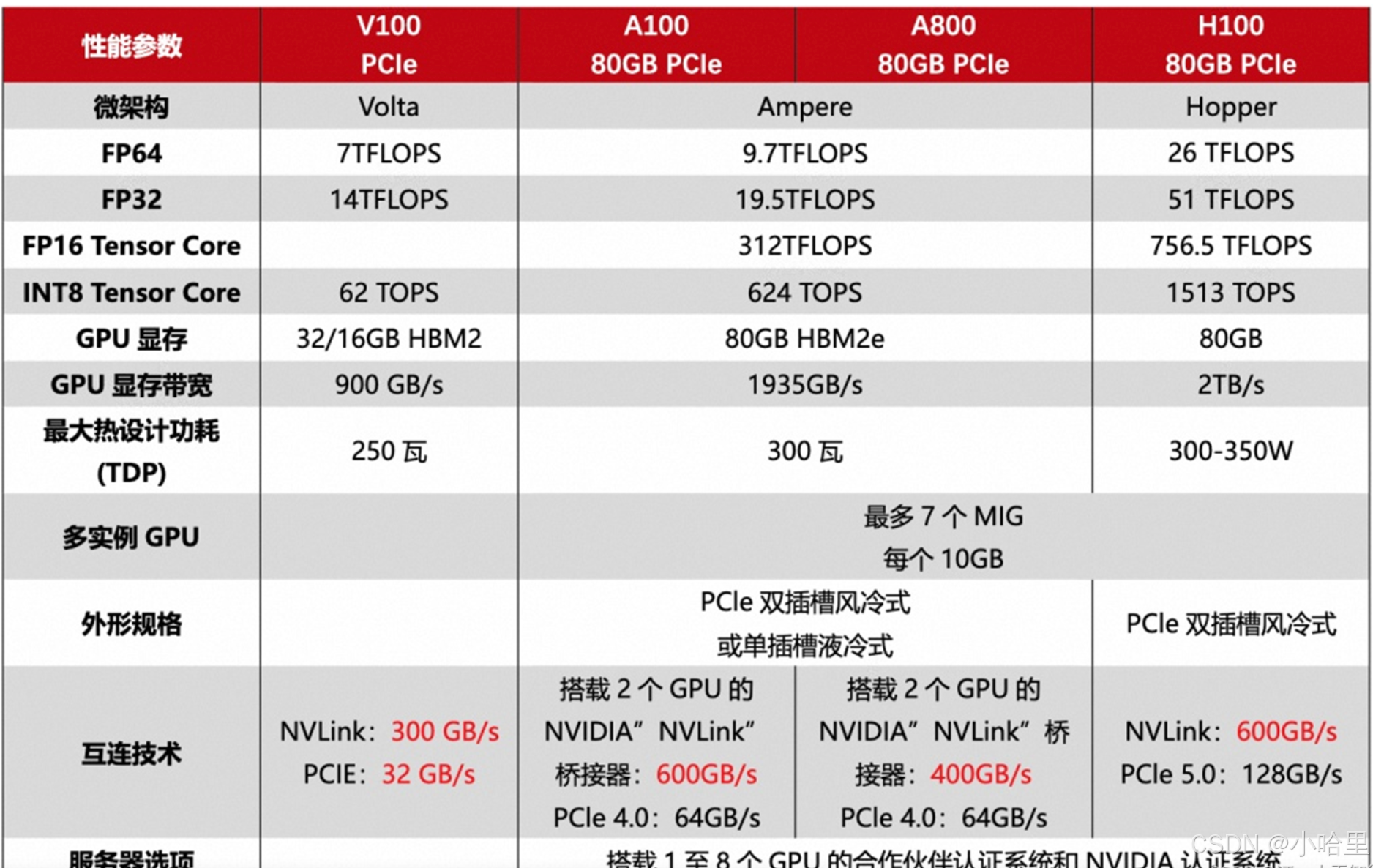
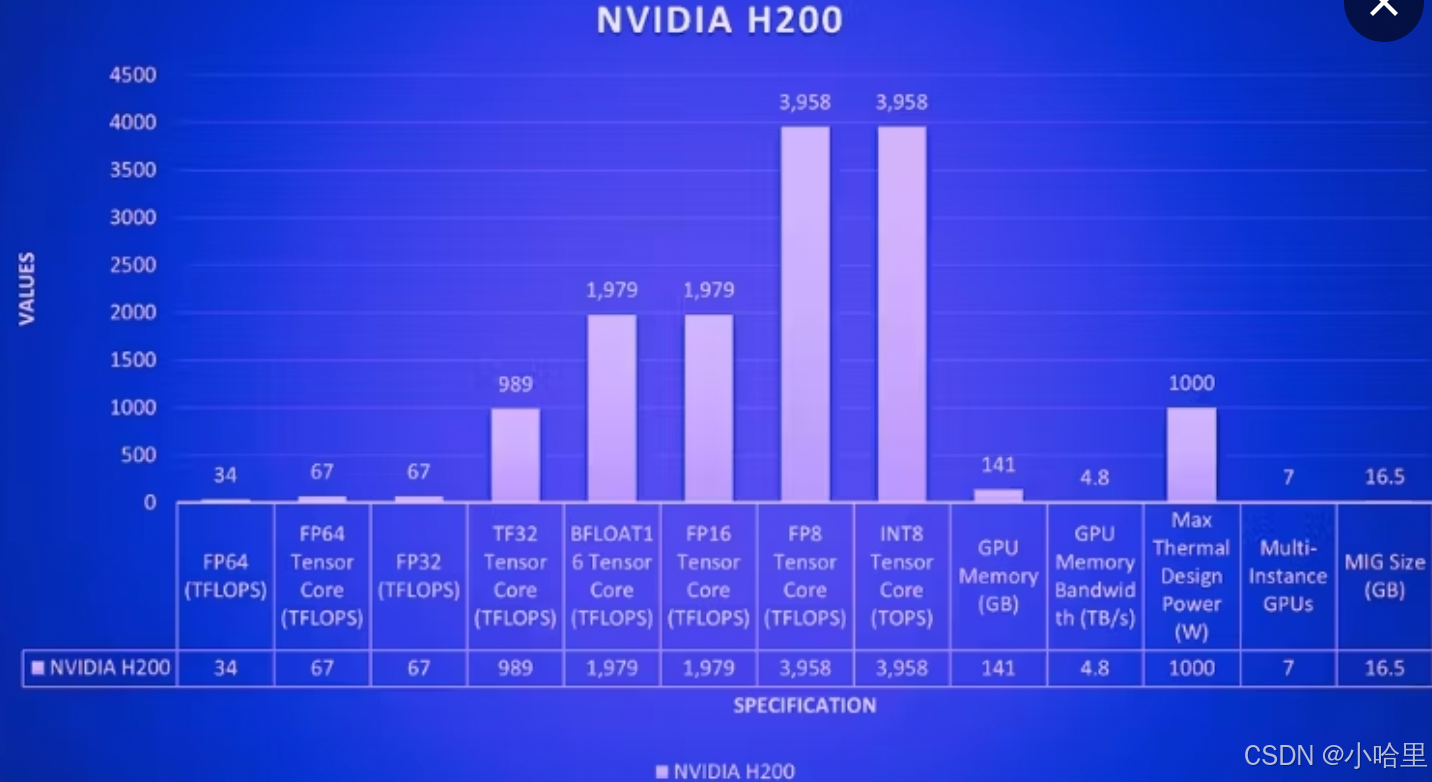

參考資料:1, 2
2、集群架構設計 NVLink / RDMA / Alluxio
集群架構設計
-
NVLink全互聯(計算)
NVIDIA DGX H100:8卡通過NVLink 4.0互聯(900GB/s帶寬)
避免PCIe瓶頸(傳統x16僅64GB/s) -
InfiniBand網絡 網絡
NDR 400G標準(延遲<1μs)
GPUDirect RDMA技術(數據直達GPU顯存) 什么是RDMA技術 2 3 -
存儲加速方案 存儲
非易失內存(NVDIMM):持久化參數存儲
分布式緩存(如Alluxio):加速數據管道
共享對象存儲,文件存儲
技術棧選型
- 計算加速庫
CUDA 12.3(支持動態并行)
oneAPI 2024(統一CPU/GPU/FPGA編程) - 框架優化
PyTorch 2.3(編譯式執行圖)
TensorFlow Lite(稀疏化推理) - 調度系統
Kubernetes + Kubeflow(彈性擴縮容)
Slurm(超算級作業調度)
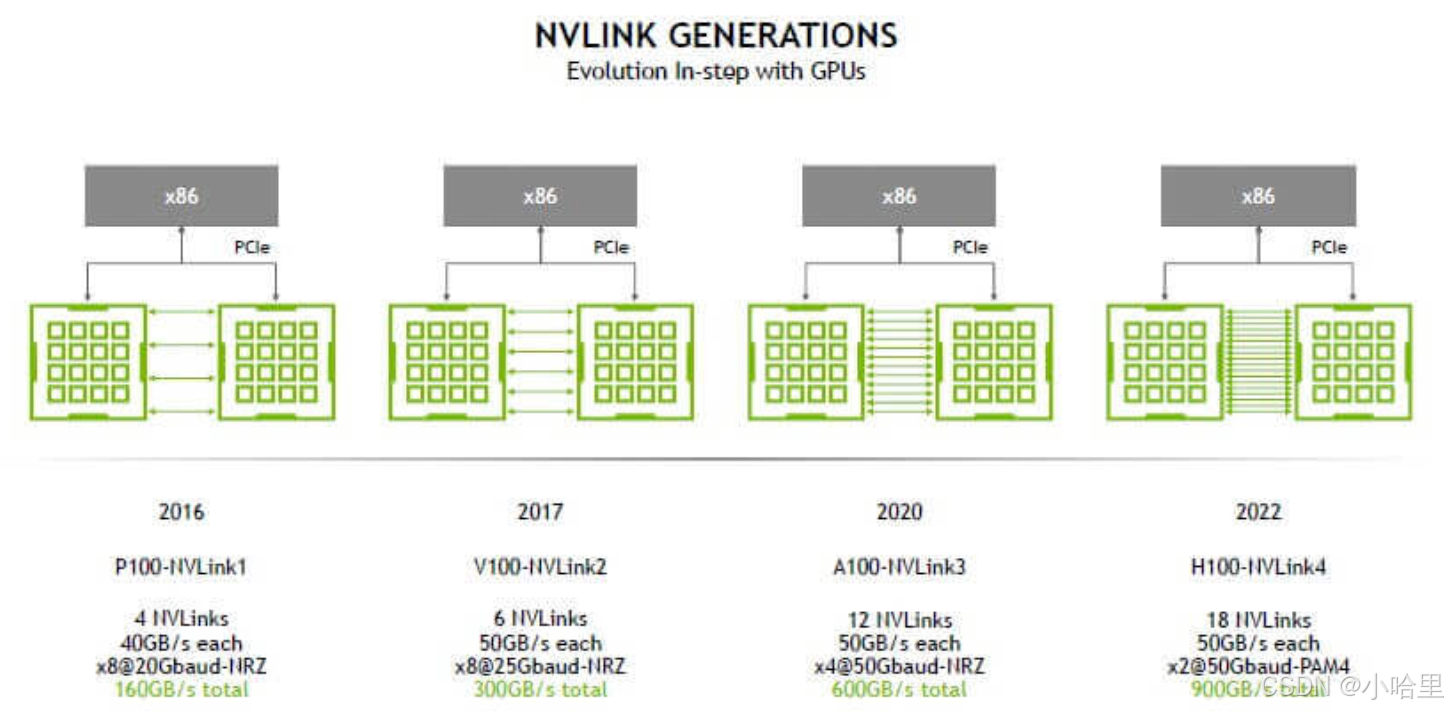
NVLink全互聯技術
- NVLink是NVIDIA開發的GPU間高速互連技術,旨在突破PCIe帶寬限制,實現多GPU之間的低延遲、高帶寬數據交換。
- 帶寬:第三代NVLink單鏈路達50GB/s(雙向),遠高于PCIe 4.0 x16(32GB/s)。
拓撲靈活性:支持全互聯(All-to-All)、網狀(Mesh)、混合連接。
統一內存:支持GPU顯存池化(NVLink Shared Memory)。 - 全互聯模式下,每塊GPU通過NVLink直接與其他所有GPU相連,實現最優通信效率。
# 查看NVLink鏈路激活情況
nvidia-smi topo -mGPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7
GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12
GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12
...
("NV12"表示12條NVLink鏈路激活)# 設置環境變量啟用GPU顯存池化
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps
export CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-log
nvidia-cuda-mps-control -d# PyTorch:自動檢測NVLink,需確保數據并行時使用nccl后端。
torch.distributed.init_process_group(backend='nccl')nvidia-smi dmon -s pucvmt # 監控NVLink帶寬利用率
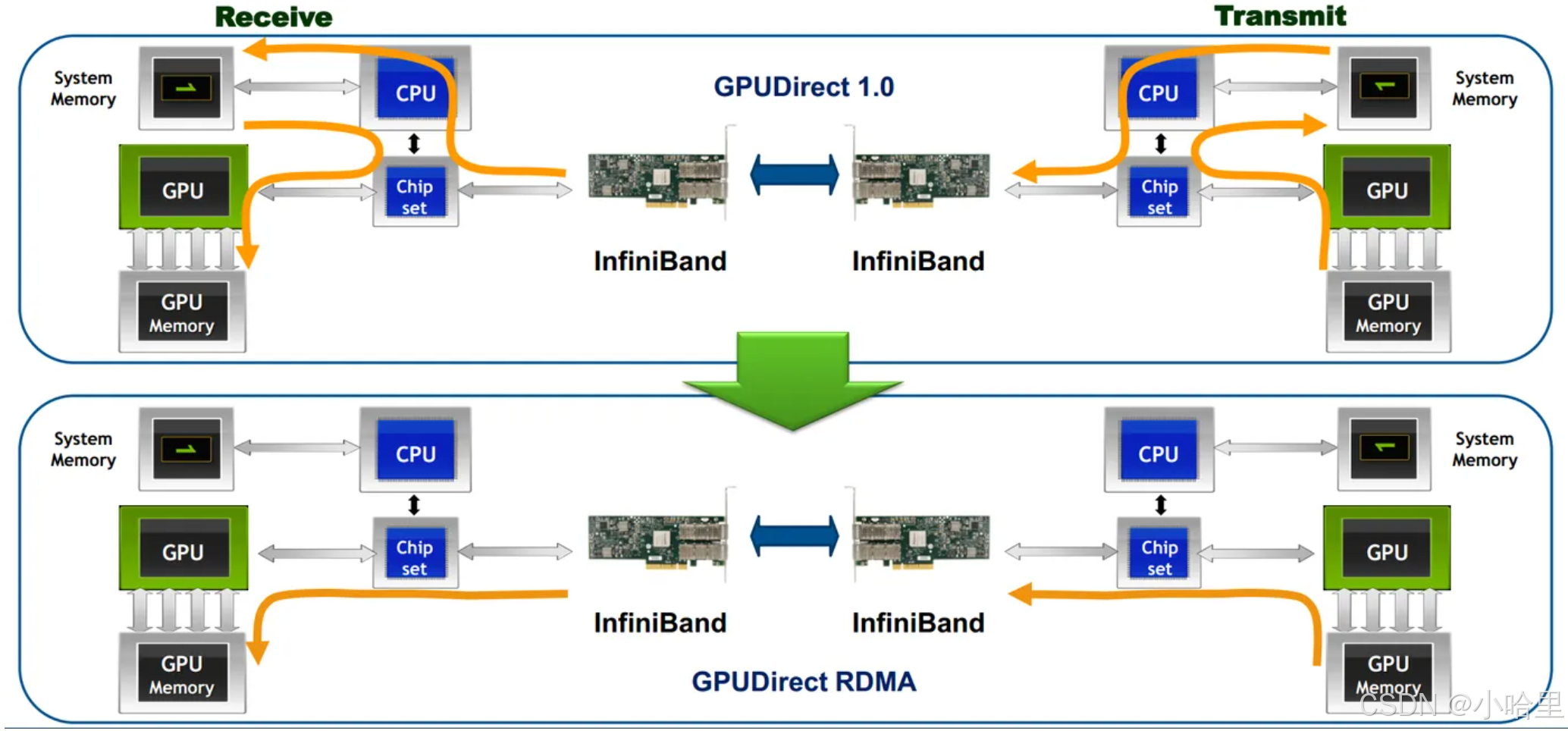
nvidia-smi # 查看利用率,鏈路狀態GPUDirect RDMA技術
- GPUDirect RDMA(Remote Direct Memory Access)是NVIDIA開發的一項技術,允許第三方設備(如網卡、存儲設備)繞過CPU,直接通過PCIe總線訪問GPU顯存,從而顯著降低數據傳輸延遲并提升帶寬利用率。
- 核心目標:消除CPU和系統內存的拷貝開銷,加速GPU與外部設備(如InfiniBand網卡、NVMe SSD)間的數據交換。
- 典型應用:分布式AI訓練、高性能計算(HPC)、實時數據處理。
# 安裝NVIDIA驅動和CUDA
sudo apt install nvidia-driver-530 cuda-12.2
# 安裝RDMA驅動(MLNX_OFED)
wget https://www.mellanox.com/downloads/ofed/MLNX_OFED-5.8-3.0.7.0/MLNX_OFED_LINUX-5.8-3.0.7.0-ubuntu22.04-x86_64.tgz
tar -xzvf MLNX_OFED-*.tgz && cd MLNX_OFED-* && sudo ./mlnxofedinstall# 啟用GPUDirect RDMA:
# 檢查GPU和網卡是否支持
nvidia-smi topo -m # 確認GPU與網卡是"PIX"或"PHB"連接# 加載內核模塊
sudo modprobe nv_peer_mem
sudo service openibd restart# 安裝支持GPUDirect的OpenMPI
./configure --with-cuda=/usr/local/cuda --with-rdma=/usr/mellanox
make -j8 && sudo make install# 運行測試(需GPU-aware MPI)
mpirun -np 2 --mca btl_openib_want_cuda_gdr 1 ./your_gpu_app# 開發
// 1. 分配GPU顯存并獲取IPC句柄
cudaIpcMemHandle_t handle;
void* d_ptr;
cudaMalloc(&d_ptr, size);
cudaIpcGetMemHandle(&handle, d_ptr);
// 2. 在另一進程/節點打開顯存
void* remote_ptr;
cudaIpcOpenMemHandle(&remote_ptr, handle, cudaIpcMemLazyEnablePeerAccess);
// 3. 通過RDMA網卡直接讀寫remote_ptr(需MPI或自定義通信層)
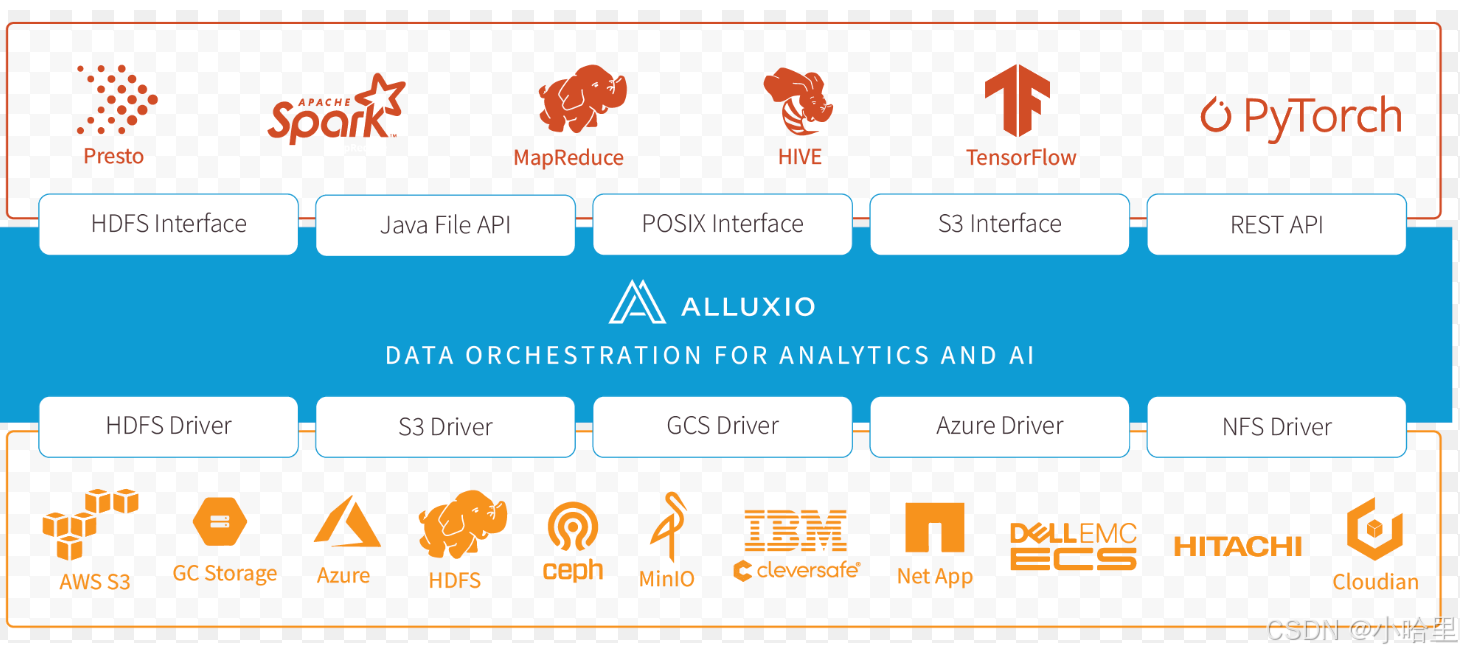
Alluxio 技術
- Alluxio 是一個開源的 內存級虛擬分布式存儲系統,充當計算框架(如Spark、Flink)和底層存儲系統(如HDFS、S3、OSS)之間的抽象層。
加速數據訪問:通過內存緩存、數據本地化優化,減少I/O瓶頸。
統一命名空間:整合多種存儲系統(HDFS/S3/NFS等),提供透明訪問接口。
數據共享:支持多計算框架(Spark/Presto/MapReduce)共享同一份緩存數據。 - LLM 訓練需反復讀取TB級文本數據(如Common Crawl)。
- 1.Alluxio可以加速訓練數據加載
如將遠程存儲(如S3)的數據緩存在訓練集群本地內存/SSD中,減少數據加載延遲。
同時支持預熱緩存(Preload),在訓練開始前主動加載數據,避免I/O等待。 - 2.可以共享中間數據
多個訓練任務(如超參搜索)需共享預處理后的數據集或檢查點。
提供 統一命名空間,避免數據重復拷貝到各計算節點。通過內存緩存加速檢查點(Checkpoint)的讀寫,縮短恢復時。 - 3.混合云數據橋接
訓練數據在私有HDFS,但計算集群在公有云。緩存私有數據到云上Alluxio節點,避免跨數據中心傳輸。
# 下載Alluxio(以2.9.3為例)
wget https://downloads.alluxio.io/downloads/files/2.9.3/alluxio-2.9.3-bin.tar.gz
tar -xzf alluxio-2.9.3-bin.tar.gz
cd alluxio-2.9.3# 配置底層存儲(如S3)
cp conf/alluxio-site.properties.template conf/alluxio-site.properties
echo "alluxio.master.mount.table.root.ufs=s3://your-bucket/path" >> conf/alluxio-site.properties# 啟動集群
./bin/alluxio format
./bin/alluxio-start.sh local# 預加載S3數據到Alluxio緩存
alluxio fs load /s3/dataset
# PyTorch直接讀取Alluxio緩存中的檢查點
checkpoint = torch.load("alluxio://master:19998/checkpoints/model.pt")# 在每臺Worker節點配置緩存路徑(內存+SSD)
echo "alluxio.worker.ramdisk.size=100GB" >> conf/alluxio-site.properties
echo "alluxio.worker.tieredstore.levels=2" >> conf/alluxio-site.propertiesfrom torch.utils.data import DataLoader
from alluxiofs import AlluxioFileSystem # Alluxio的POSIX接口# 掛載Alluxio為本地路徑(通過FUSE)
fs = AlluxioFileSystem("alluxio://master:19998")
fs.mount("/mnt/alluxio")# 直接讀取緩存數據
dataset = HuggingFaceDataset("/mnt/alluxio/dataset")
dataloader = DataLoader(dataset, batch_size=32)# 查看緩存命中率(確保熱數據在內存中)
alluxio fsadmin report
3、性能關鍵指標,FP64 / FLOPS
算力單位:浮點運算次數 FLOPS
-
(Floating Point Operations Per Second,簡稱FLOPS) 是用來衡量計算設備執行浮點運算能力的指標。
這個指標通常用來描述處理器(CPU)、圖形處理器(GPU)或其他計算設備在一秒鐘內能夠執行多少次浮點運算。
浮點運算是指能夠處理帶有小數點的數學運算,這對于科學計算、工程模擬、圖形渣染等領域尤為重要。 -
FP(Float PerSecond) = FLOPS(Floating Point Operations Per Second)
單位:K=>M=>G=>T=>P=>E
FP32:單精度浮點(訓練基線)
FP16:半精度(主流訓練/推理混合精度)
FP8:NVIDIA H100新增格式(推理加速3x)
INT8/INT4:整數量化(推理專用,INT8吞吐量可達FP16的2倍)

-
精度降低
FP32 → FP16:吞吐量2x↑,精度損失<1%
FP16 → INT8:吞吐量再2x↑,需校準量化(Quantization Aware Training)
INT8 → INT4:極致壓縮(適用于NLP模型如BERT)
其他指標
- PCIe帶寬:
Gen4 x16 = 32GB/s(可能成為多卡互聯瓶頸)
Gen5 x16 = 64GB/s(H100標配)
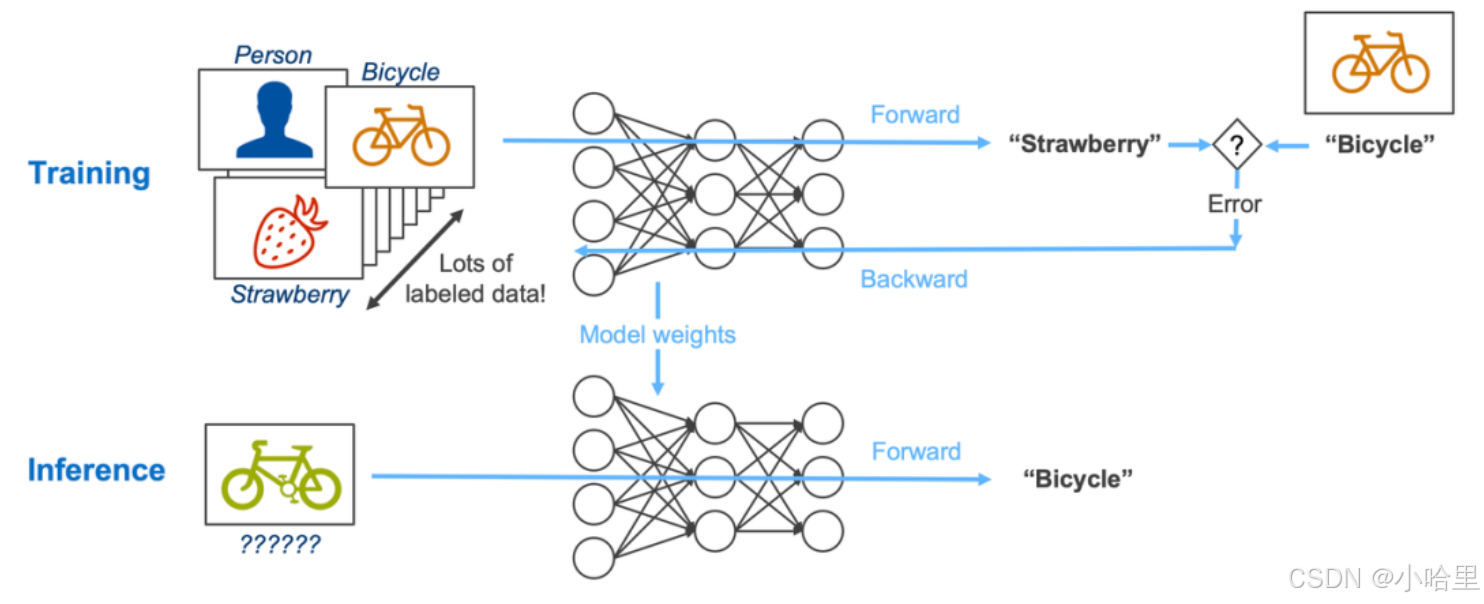
訓練場景 vs 推理場景
- 算力密度:推理需在單位時間內完成更多請求(如自動駕駛的毫秒級響應)
- 顯存容量:訓練時需保留反向傳播的中間結果,推理只需前向計算(如175B參數的GPT-3訓練需1.6TB顯存,推理僅需~80GB)
- 精度要求:推理可通過量化犧牲少量精度換取吞吐量提升(如TensorRT的INT8量化技術)
- 能效比:推理部署在邊緣設備,因此需要低功耗
| 指標 | 訓練場景要求 | 推理場景要求 |
|---|---|---|
| 算力密度 | >50T FLOPS/卡 | >200T FLOPS/卡 |
| 顯存容量 | 80GB+(HBM2e) | 16-48GB(GDDR6X) |
| 互聯帶寬 | 600GB/s+ | 200GB/s+ |
| 能效比 | <500W/TFLOPS | <100W/FLOPS |
參考資料:1, 2, 3, 4, 5














 與 torch.no_grad() PyTorch 中的區別與應用)



 -- noogle DefCamp 2024)
