文章目錄
- 概要
- 一、原理
- 1.1、案例
- 1.2、關鍵匯編
- 二、LOCK匯編指令
- 2.1、 LOCK
- 2.2、 原理
- 2.2.1、 緩存行
- 2.2.2、 緩存一致性之MESI協議
- 2.2.3、lock原理
- 三、x86緩存發展
- 四、x86 DMA發展
- 參考
概要
在并發操作下,對一個簡單的a=a+2的操作都會出錯,這是因為這樣簡單的操作在被CPU執行時,分為三步:
- cpu從內存中讀取a的值;
- cpu執行a=a+2操作;
- cpu將執行結果寫回內存。
在多核環境下,很容易發生,A核和B核同時從內存中讀取a的值,經過各自計算后寫回內存的情況,這也解釋了為什么在并發下,不加鎖的累加操作結果常常比預期值小的原因。
在go語言中,對于有競爭的數據操作,我們常常用sync/atomic標準庫提供的原子操作,經典的比如借助CAS原子操作實現自旋鎖。
原子操作即是進行過程中不能被中斷的操作。針對某個值的原子操作在被某個CPU執行的過程當中,其它CPU絕不會進行其它針對該值的原子操作,也就是說,為了實現這樣的嚴謹邏輯,同一時刻原子操作僅會由一個獨立的CPU執行,其它CPU等待,只有這樣才能夠在并發環境下保證原子操作的絕對安全。
Go語言提供的原子操作都是非侵入式的,我們通過調用sync/atomic標準庫提供的函數,對6種簡單的類型的值進行原子操作,這些類型包括int32、int64、uint32、uint64、uintptr和unsafe.Pointer類型。這些函數提供的原子操作共有5種,分別是增加(Add)、比較并交換(CompareAndSwap)、載入(Load)、存儲(Store)、交換(Swap)。
調試的服務器信息:Centos Linux 7 ,CPU AMD x86_64,Go version 1.24
本文通過在CPU x86_64環境下的匯編分析這些原子操作的原理。
前置知識:
x86系列CPU寄存器和匯編指令
go 通過匯編分析棧布局和函數棧幀
一、原理
本章以原子操作Add為例,通過其匯編逐步去分析。
1.1、案例
package mainimport ("fmt""sync/atomic"
)func main() {a := uint64(1)atomic.AddUint64(&a, 5)a+=5fmt.Println("Add", a)
}
1.2、關鍵匯編
[root@test gofunc]# dlv debug atomic.go
Type 'help' for list of commands.
(dlv) b atomic.go:8
Breakpoint 1 set at 0x4b1b13 for main.main() ./atomic.go:8
(dlv) c
> [Breakpoint 1] main.main() ./atomic.go:8 (hits goroutine(1):1 total:1) (PC: 0x4b1b0e)3: import (4: "fmt"5: "sync/atomic"6: )7:
=> 8: func main() {9: a := uint64(1)10: atomic.AddUint64(&a, 5)11: a+=512:13: fmt.Println("Add", a)
(dlv) disass
Sending output to pager...
TEXT main.main(SB) /home/fpf/server/moa-20241226160534/background/tools/source/go-apps/src/gofunc/atomic.goatomic.go:8 0x4b1b00 493b6610 cmp rsp, qword ptr [r14+0x10]atomic.go:8 0x4b1b04 0f86e8000000 jbe 0x4b1bf2atomic.go:8 0x4b1b0a 55 push rbp #BP寄存器值入棧atomic.go:8 0x4b1b0b 4889e5 mov rbp, rsp #保存main函數棧幀基址
=> atomic.go:8 0x4b1b0e* 4883ec68 sub rsp, 0x68 #申請0x68大小棧內存atomic.go:9 0x4b1b12 48c744241801000000 mov qword ptr [rsp+0x18], 0x1 #令變量a=1atomic.go:10 0x4b1b1b b905000000 mov ecx, 0x5 #令CX寄存器值等于5atomic.go:10 0x4b1b20 488d542418 lea rdx, ptr [rsp+0x18] #&a操作,即將變量a的地址加載到DX寄存器atomic.go:10 0x4b1b25 f0480fc10a lock xadd qword ptr [rdx], rcx #atomic.AddUint64原子操作,對變量a的地址進行原子操作,可以看到用的是x86_64 cpu提供的lock和xadd匯編指令配合,xadd進行加法操作,lock對變量a地址上鎖atomic.go:11 0x4b1b2a 48ff442418 add qword ptr [rsp+0x18], 0x5 #a+=5操作,add匯編指令完成atomic.go:13 0x4b1b2f 440f117c2448 movups xmmword ptr [rsp+0x48], xmm15atomic.go:13 0x4b1b35 440f117c2458 movups xmmword ptr [rsp+0x58], xmm15atomic.go:13 0x4b1b3b 488d4c2448 lea rcx, ptr [rsp+0x48]atomic.go:13 0x4b1b40 48894c2428 mov qword ptr [rsp+0x28], rcxatomic.go:13 0x4b1b45 8401 test byte ptr [rcx], alatomic.go:13 0x4b1b47 488d1592a00000 lea rdx, ptr [rip+0xa092]#...省略
二、LOCK匯編指令
x86指令之LOCK
2.1、 LOCK
在x86架構下,當指令附加LOCK前綴時,CPU會在執行該指令期間置位LOCK#信號,將指令轉換為?原子操作?。在多核環境下,LOCK#信號確保CPU在信號置位期間獨占操作任何共享內存。
LOCK前綴僅可附加于以下指令,且?目標操作數必須為內存操作數?:
ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC,
NEG, NOT, OR, SBB, SUB, XOR, XADD, XCHG。
2.2、 原理
在單核環境下,不存在對某個內存地址出現競爭讀寫的情況,故我們只需討論多核環境。
現代CPU基本都是多核架構,并且為了平衡CPU執行指令與內存讀寫之間的效率差距,引入了三級緩存,從緩存角度看,其結構如下圖:
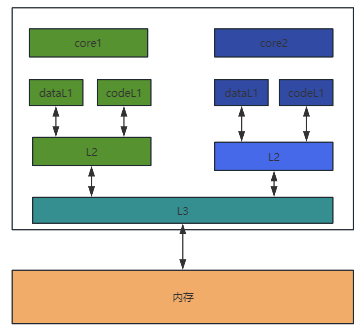
L1 緩存距離 CPU 核心最近,具有最快的訪問速度但容量較小。通常,L1 緩存會分為兩部分:數據緩存(L1 Data)和指令緩存(L1 code)。這是因為代碼和數據的更新策略不同,需要分別進行緩存管理。
L2 緩存的容量比 L1 緩存大,但訪問速度稍慢。它充當了中間緩沖區的作用,當 L1 緩存未命中時,CPU 會嘗試從 L2 緩存中獲取數據。每個核心擁有獨立的 L2 緩存。
L3 緩存通常具有更大的容量,但訪問速度相對較慢。它在多核心處理器中扮演著重要的角色,多個核心共享 L3 緩存中的數據。如果 L1 和 L2 緩存都未命中,CPU 核心會嘗試從 L3 緩存中獲取數據,以減少直接訪問主內存的高延遲。
主內存的容量更大,但訪問速度相對更慢。
2.2.1、 緩存行
由于每一級緩存的訪問都是有成本的,所以本級緩存向下一級取數據時的基本單位并不是字節,而是緩存行(cache line)。每個cache line包含Flag、Tag和Data,通常Data的大小是64字節,但不同型號 CPU 的 Flag 和 Tag 可能不相同。數據是按照緩存塊大小從內存向緩存加載和從緩存寫回內存的,也就是說,即使緩存只訪問1字節的數據,也得把這個字節附近以緩存行對齊的64字節的數據加載到緩存中。

- FLAG:用于指示緩存行的狀態,例如是否有效、是否被修改等;
- TAG:用于記錄該緩存行所對應的內存地址,這樣同一緩存塊在不同核心的緩存中,也能識別出來;
- DATA:實際存儲的數據,通常是64字節。
緩存行大小一般是64字節,從下級緩存取數據一定是64字節,假設內存地址[0,1024],那么CPU讀取第89地址內容時,會直接取[64,128]這整個內存塊。取內存塊時從0開始以64字節為單位進行對齊的。
緩存行(cache line)緩存管理的最小存儲單元,也被稱為緩存塊.
2.2.2、 緩存一致性之MESI協議
多級緩存在提高CPU性能的同時,由于不是所有核共有的,就有了緩存一致性的問題,因此誕生了MESI協議(一致性協議除了MESI,還有其改進版MOESI、簡化版MSI、其他如Dragon?協議)。
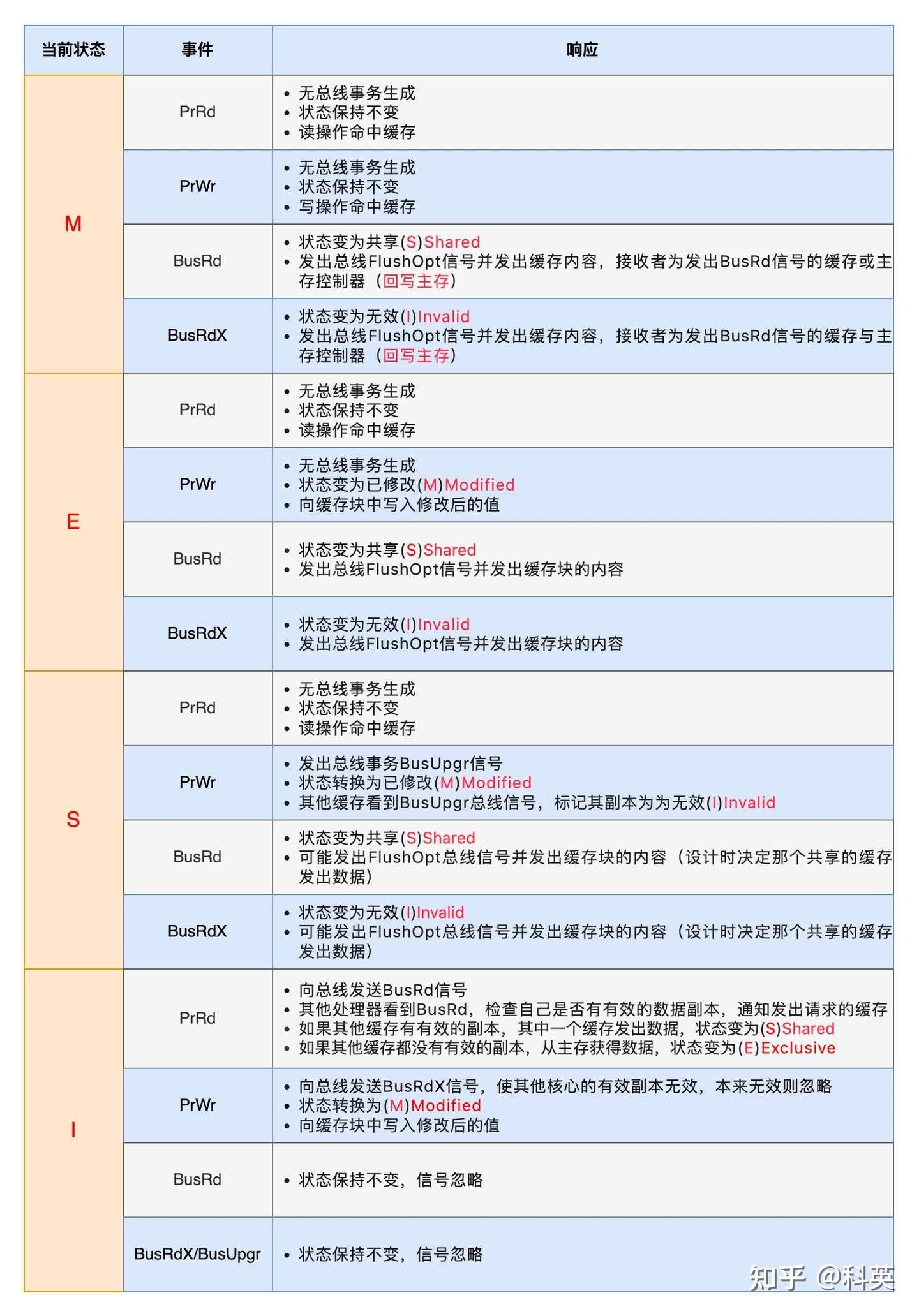
由?伊利諾伊大學(或稱伊利諾斯州立大學)?的研究者提出,因此也稱為?伊利諾斯協議(Illinois Protocol)。MESI協議是早期?緩存一致性協議?的代表,其設計背景與?多核處理器?的發展密切相關,尤其是在需要解決共享數據一致性問題的場景中。協議名稱來源于其核心四種狀態:?Modified(M)?、?Exclusive(E)?、?Shared(S)?、?Invalid(I)。
1:狀態機
- 已修改(Modified,簡稱M):表示緩存塊中的數據與內存中的數據不一致,即緩存塊是臟的。如果其他核心要讀取這塊數據,那么必須先將緩存塊的數據寫回內存,然后將緩存塊的狀態變為共享(S)。在這種狀態下,確保其他核心可以讀取到最新的內存數據,并維護一致性。
- 獨占(Exclusive,簡稱E):表示緩存塊只存在于當前核心的緩存中,并且是干凈的,即與內存中的數據一致。如果其他核心要讀取這個緩存塊,那么當前核心會將自己的緩存塊的狀態變為共享(S)。當當前核心寫入數據時,緩存塊的狀態變為已修改(M)。
- 共享(Shared,簡稱S)表示緩存塊是共享的,存在于當前核心和其他核心的緩存中,并且是干凈的,即與內存中的數據一致。在共享狀態下,多個核心可以同時讀取這個緩存塊,而且這個緩存塊隨時都可以被其他緩存塊替換,并且不需要寫回內存,因為它的內容與內存中的數據一致。
- 無效Invalid (I):緩存行是無效的。
該狀態信息存在緩存行結構的FLAG中.
2:事件
為了解決多個核心之間的數據傳播問題,Intel公司提出了總線嗅探(Bus Snooping)策略,即把讀寫請求事件都通過總線廣播給所有核心,各個核心能夠嗅探到這些請求,然后根據本地緩存塊狀態對其進行響應。
1)緩存塊收到來自核心的事件
- PrRd事件指的是讀取事件,其中Pr代表Processor(處理器)。該事件表示某個核心對一個緩存塊發起了一個讀取操作,希望獲取對這個緩存塊的共享訪問權限;
- PrWr事件指的是寫入事件,其中Pr也代表Processor。該事件表示某個核心對一個緩存塊發起了一個寫入操作,希望獲取對這個緩存塊的獨占訪問權限。
2)緩存塊收到來自總線的事件 - BusRd事件表示某個核心發起了一個讀操作,希望獲取對某個緩存塊的共享訪問權。該事件使得多個核心能夠在需要時同時共享相同的數據,從而提高系統性能并有效管理共享數據。不涉及對緩存塊的修改,因此不需要執行失效或寫回操作,確保了共享數據的正確同步;
- BusRdX事件表示某個核心發起了一個讀-修改-寫的操作,希望獲取對特定緩存塊的獨占訪問權限。這個事件的發生意味著該核心需要讀取該緩存塊的數據并執行修改,可能導致其他核心的緩存失效或需要寫回內存,以確保在修改之前獲取最新的數據狀態;
- BusUpgr表示某個核心發起了升級請求,希望從對某個緩存塊的共享訪問切換到獨占訪問。這個事件觸發時,核心通常需要將其他核心的相同緩存塊的狀態切換為無效或將其寫回內存,以確保在執行修改操作之前,該核心獲得最新且獨占性的數據狀態;
- Flush事件表示某個核心對一個緩存塊進行刷新操作。這可能包括將緩存塊的數據寫回內存或者通知其他核心將其緩存中的對應數據失效。通過執行 Flush 操作,系統確保所有核心使用相同的、最新的數據,避免緩存中的數據與內存不一致;
- FlushOpt事件也表示某個核心對一個緩存塊執行刷新操作,但不是寫回內存,而是將整個緩存塊發送給另一個核心,即緩存到緩存的傳遞。
------------------------------------------------- MESI協議緩存塊在不用狀態下收到不同事件的行為
ps:其實緩存一致性,除了多核、多級緩存外,DMA也會引起緩存一致性問題。
在x86發展過程中,不是一開始就是多級緩存的:
1:一開始就是單核直接訪問內存;
2:后因為性能問題,即cpu執行指令與訪問內存速度上存在巨大差異,引入了多級緩存;
3:后來單核性能也不足,就提出了多核機制,也就引入了MESI等協議(只作用于處理器內部,與DMA無關),形成了現代CPU的普遍架構。
2.2.3、lock原理
早期緩存一致性的解決方案比較粗暴,某個cpu核心LOCK指令發出后會直接鎖總線(獨占總線),這樣其他cpu核心或MDA根本無法通過總線總內存讀取數據了,也就不存在緩存一致性問題了。
弊端顯而易見,鎖范圍過大,在引入多級緩存時,為了更好的管理內存,提出了緩存行,基于此,LOCK指令不在鎖總線,而是只鎖操作值所在的緩存行。
假如兩個CPU核心都持有相同的緩存行,且各自狀態為S,此時core0 執行lock指令要修改緩存行內某個值,會出現如下流程:
- 總線通過總線嗅探(Bus Snooping)策略檢測到沖突,向core1 發出BusRdX事件;
- core1 收到BusRdX事件,將core1本地對應緩存行狀態置為I;
- core0 執行操作,將core0本地對應緩存行狀態置為M,并更改相應操作值;
- 假如接著core1 也要執行lock指令修改該操作值,總線通過總線嗅探(Bus Snooping)策略檢測到沖突,向core0 發出BusRdX事件;
- core0 收到BusRdX事件,將core0本地對應緩存行狀態置為I,并通過FlushOpt事件將緩存行發給core1;
- core1收到core0發來的緩存行后,將core1本地對應緩存行狀態置為M,并更改相應操作值;
- …
三、x86緩存發展
- 單核時代(1978–2000 初期)??
早期的 x86 CPU(如 ??8086、80286、80386??)是純粹的單核設計,??沒有緩存??:
無緩存階段??:CPU 直接訪問內存,性能受限于內存速度。
??緩存引入??:
??80486(1989)??:首次在芯片內集成 ??L1 緩存??(8 KB),顯著減少內存訪問延遲。
??Pentium(1993)??:分離為 ??指令 L1 緩存?? 和 ??數據 L1 緩存??(各 8 KB),提升并行性。
??Pentium Pro(1995)??:首次引入 ??L2 緩存??(256 KB–1 MB),但位于 CPU 封裝外的獨立芯片(速度較慢)。
??Pentium III(1999)??:將 L2 緩存集成到 CPU 芯片內(256 KB),速度大幅提升。
??2. 多級緩存的完善(2000 初期)??
隨著單核性能提升遇到瓶頸,緩存層級逐漸擴展:
??L3 緩存的引入??:
??Intel Xeon(2003)??:為服務器市場引入 ??L3 緩存??(共享緩存),優化多任務性能。
??Core 2 系列(2006)??:在消費級 CPU 中普及 L2/L3 緩存(如 4 MB L2 緩存)。
??緩存邏輯的優化??:引入緩存一致性協議(如 ??MESI??)、非阻塞緩存、預取技術等。
??3. 多核技術的誕生(2005 年后)??
單核頻率提升遭遇物理極限(功耗、散熱),轉向多核并行:
??早期嘗試??:
??Pentium D(2005)??:通過“雙芯封裝”(兩個獨立單核)實現“偽多核”,無共享緩存。
??Core 2 Duo(2006)??:真正的 ??原生雙核設計??,共享 L2 緩存,標志多核時代開啟。
??多核與緩存的協同??:
??每個核心獨立 L1/L2 緩存??:減少核心間競爭。
??共享 L3 緩存??(如 Intel Nehalem, 2008):提升多核數據共享效率。
??NUMA 架構??:在服務器 CPU 中優化多核內存訪問。
四、x86 DMA發展
DMA(直接內存訪問)控制器繞過 CPU,直接讀寫內存。
如果 CPU 緩存未與內存同步,會導致數據不一致,解決:
1)總線仲裁,當 CPU 和 DMA 同時請求訪問內存時,總線仲裁器會按仲裁策略選擇優先分給誰,另一個等待。
2)CPU緩存刷新,當 CPU緩存與主存不一致時,DMA 請求訪問內存時總線會先讓CPU將對應緩存寫回主存;
3)DMA將數據寫回內存時,強制 CPU 丟棄其緩存中的舊數據(即對應緩存行狀態置為I)
| 事件 | 關鍵產品/技術 | 意義 |
|---|---|---|
| 1976年? | Intel 8257 DMA控制器發布 | 首款商用可編程DMA控制器,奠定基礎架構 |
| ?1980年? | 8237芯片組集成DMA控制器 | DMA技術普及至PC主板 |
| ?1993年? | 奔騰系列芯片組支持UDMA | 優化存儲設備性能 |
| ??2023年? | 酷睿Ultra集成雷電5與DMA加速 | 融合高速I/O與DMA技術,提升擴展性 |
參考
1]:十年碼農內功:緩存篇(第2版)
2]:Linux CPU 多級緩存與實踐

)







)
進行拾取和放置)



)
)



