一、論文

1.1、論文基本信息?
-
標題:Deep Residual Learning for Image Recognition
-
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
-
單位:Microsoft Research
-
會議:CVPR 2016
-
主要貢獻:提出了一種深度殘差學習框架(Residual Learning Framework),有效解決了深度神經網絡訓練中的退化問題(Degradation Problem),使得可以訓練更深的神經網絡,并在圖像識別任務中取得了顯著的性能提升。
1.2、主要內容
1.2.1、退化問題(Degradation Problem)
????????隨著網絡深度的增加,模型的訓練誤差和測試誤差都會增加,這種現象被稱為退化問題。 ?退化問題不是由過擬合引起的,而是由于深度網絡難以優化所致。
1.2.2、殘差學習框架(Residual Learning Framework)
????????核心思想:將網絡層學習的目標從原始的映射函數改為原始映射函數和輸入的差,即殘差映射函數。 ?
????????殘差塊(Residual Block):通過shortcut連接將輸入直接加到某些層(通常是兩到三層)的輸出上。 ?
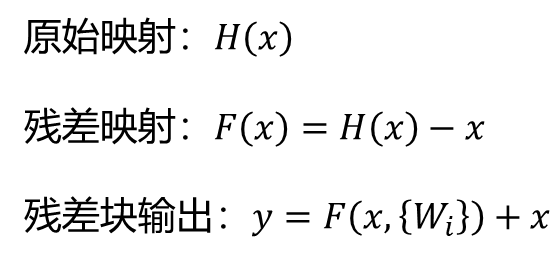
1.2.3、網絡結構
????????提出了一種基于殘差學習的深度卷積神經網絡——ResNet。 ?設計了18層、34層、50層、101層、152層等不同深度的ResNet,并通過實驗驗證了其有效性。 ?ResNet-152是當時ImageNet上最深的網絡結構。 ?
1.2.4、實驗結果
????????在ImageNet分類任務上,ResNet取得了顯著的成果,獲得了ILSVRC 2015分類任務的第一名。 ?在COCO目標檢測數據集上,ResNet也取得了28%的相對提升。 ?
????????實驗結果表明,ResNet能夠有效解決退化問題,并且能夠通過增加網絡深度來提高性能。
1.3、作用
????????解決了深度神經網絡的退化問題,使得訓練更深的網絡成為可能。 ?
????????提高了圖像識別的準確率,在多個基準數據集上取得了state-of-the-art的結果。 ?
????????推動了深度學習的發展,為后續的計算機視覺研究提供了新的思路和方法。 ?
1.4、影響
????????ResNet是深度學習領域的一項重大突破,對后續的深度學習研究產生了深遠的影響。
????????許多后續的網絡結構,如DenseNet、MobileNet等,都借鑒了ResNet的思想。
????????ResNet被廣泛應用于各種計算機視覺任務,如圖像分類、目標檢測、語義分割等。
1.5、優點
????????解決了退化問題,可以訓練非常深的網絡。 ?
????????網絡性能好,顯著提高了圖像識別的準確率。 ?
????????結構簡潔,易于實現和擴展。 ?
1.6、缺點
????????shortcut連接方式較為簡單,可能不是最優的選擇。
????????計算效率有待進一步優化,雖然比VGG網絡計算量小,但仍然較大。 ?
論文地址:
????????[1512.03385] Deep Residual Learning for Image Recognition?
二、ResNet
2.1、網絡的基本介紹
????????ResNet(“殘差網絡”的簡稱)是一種深度神經網絡,由Microsoft研究團隊于2015年提出。它在當時的ImageNet 比賽獲得了圖像分類第一名,目標檢測第一名,在COCO數據集目標檢測第一名,圖像分割第一名。
????????ResNet的主要特點是采用了殘差學習機制。在傳統的神經網絡中,每一層的輸出都是直接通過一個非線性激活函 數得到的。但在ResNet中,每一層的輸出是通過一個“殘差塊”得到的,該殘差塊包含了一個快捷連接 (shortcut)和幾個卷積層。這樣,在訓練過程中,每一層只需要學習殘差(即輸入與輸出之間的差異),而不 是所有的信息。這有助于防止梯度消失和梯度爆炸的問題,從而使得網絡能夠訓練得更深。
????????ResNet的網絡結構相對簡單,并且它的訓練速度也比GoogLeNet快。這使得ResNet成為了在許多計算機視覺任 務中的首選模型。
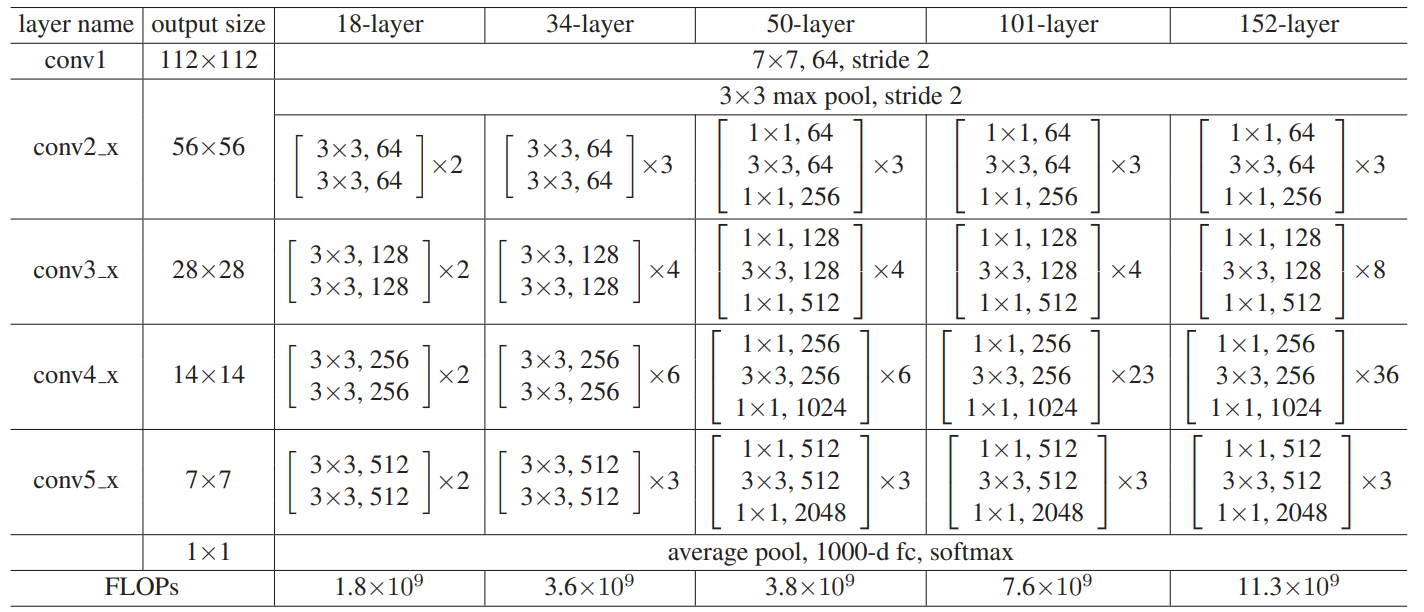
????????ResNet的主要優點是具有非常深的層數,可以達到1000多層,但仍然能夠高效地訓練。這是通過使用殘差連接來 實現的,這種連接允許模型學習跨越多個層的殘差,而不是直接學習每一層的輸出。這使得ResNet能夠更快地收 斂,并且能夠更好地泛化到新的數據集,ResNet論文中共提出了五種結構,分別是ResNet-18,ResNet-34, ResNet-50,ResNet-101,ResNet-152。
2.2、?更深的網絡層數
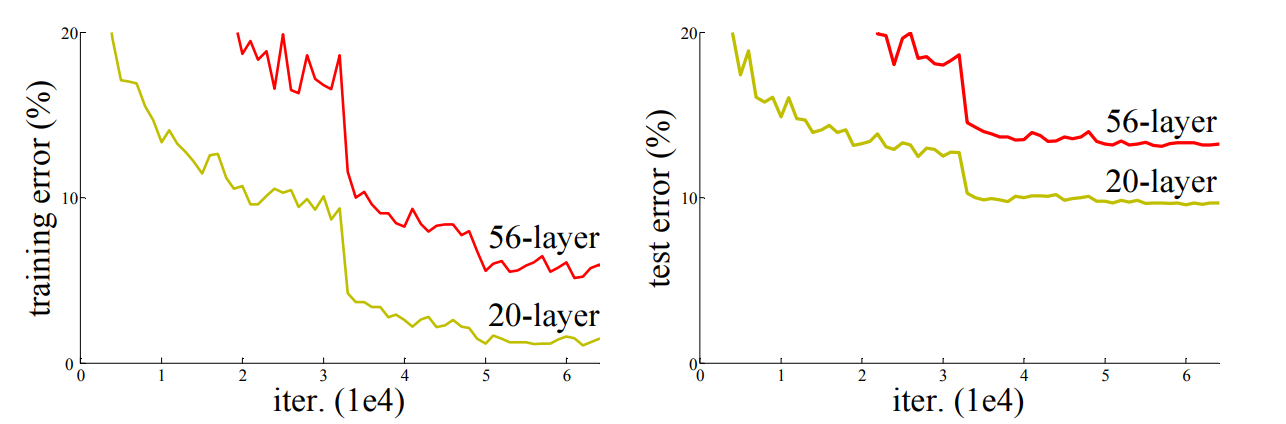
????????上圖都是直接堆疊神經網絡的結果,在左側圖中,黃色線是訓練過程中20層網絡的訓練損失曲線,紅色線是訓練 過程中56層網絡的訓練損失曲線,理論上講,網絡深可以帶來更小的損失,但是實時恰恰相反,56層的錯誤率要 高于20層的錯誤率。
????????主要有兩個原因:
????????1. 梯度消失或梯度爆炸:例如在一個網絡中,每一層的損失梯度的值都小于1,那么連續的鏈式法則之下,每向 前傳播一次,都要乘以一個小于1的誤差梯度,那么如果網絡越深,在經過非常多的前向傳播次數之后,那么 梯度越來越小,直到接近于0,這就是梯度消失。但是如果每一層的損失梯度的值都大于1,那么網絡越深,在 經過非常多的前向傳播次數之后,那么梯度越來越大,導致梯度爆炸。但是誤差梯度肯定不會一直是1或者是 和1非常接近的數值,所以這種情況發生是非常普遍的,所以一般通過數據標準化處理,權重初始化等操作進 行抑制,但網絡太深依然很難很好的抑制,當然Relu也可以抑制梯度消失問題,但是Relu可能會導致原始特征 不可逆損失,導致下一個問題,即網絡退化。
????????2. degradation problem:直譯就是退化問題,隨著網絡層數的增多,訓練集loss逐漸下降,然后趨于飽和,當 再增加網絡深度,訓練集loss反而會增大。注意這并不是過擬合,因為在過擬合中訓練loss是一直減小的。
????????用殘差結構(殘差結構在下一小節會詳細介紹)進行網絡組合時,可以很明顯的解決這個問題
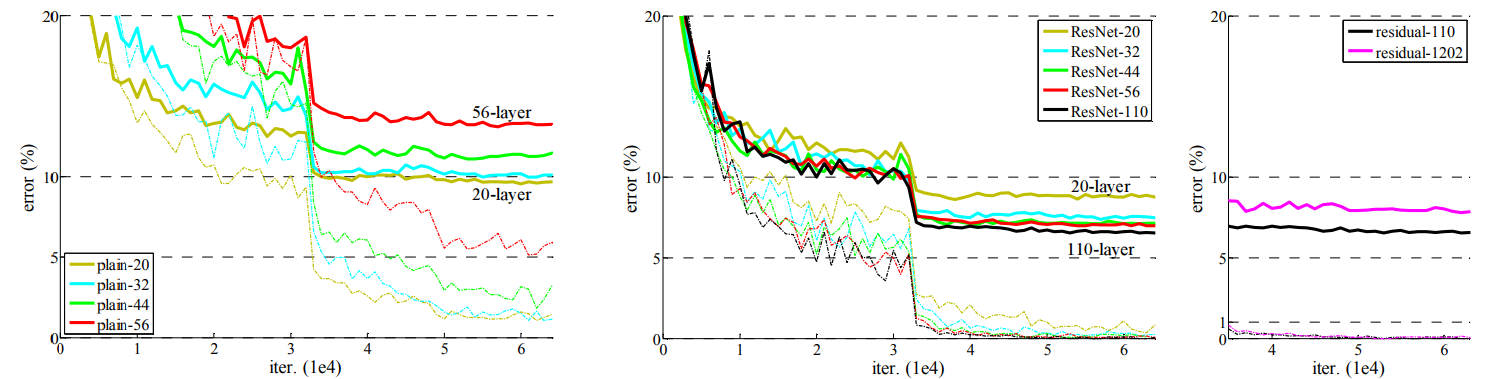
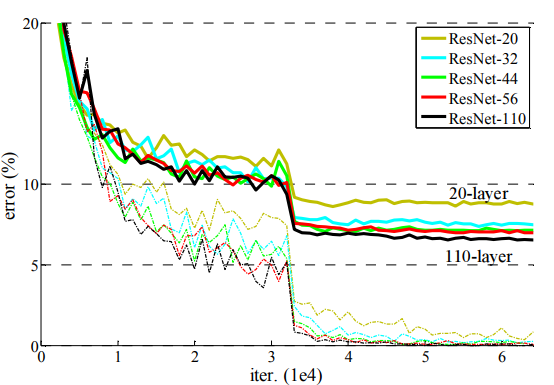
????????在使用殘差結構后,從20層,到110層,錯誤率都是逐步在降低,文章講殘差網絡對 degradation problem是有抑制作用的,還有下下小節講到的Batch Normalization是對解決梯度消失或者梯度爆 炸的抑制起到了作用,但是網絡退化的一部分原因也是因為梯度消失訓練不動了,在使用殘差網絡之后,模型內 部得復雜度降低,所以抑制了退化問題。?
2.3、?Residual結構
????????Residual結構是殘差結構,在文章中給了兩種不同的殘差結構,在ResNet-18和ResNet-34中,用的如下圖中左側 圖的結構,在ResNet-50、ResNet-101和ResNet-152中,用的是下圖中右側圖的結構。
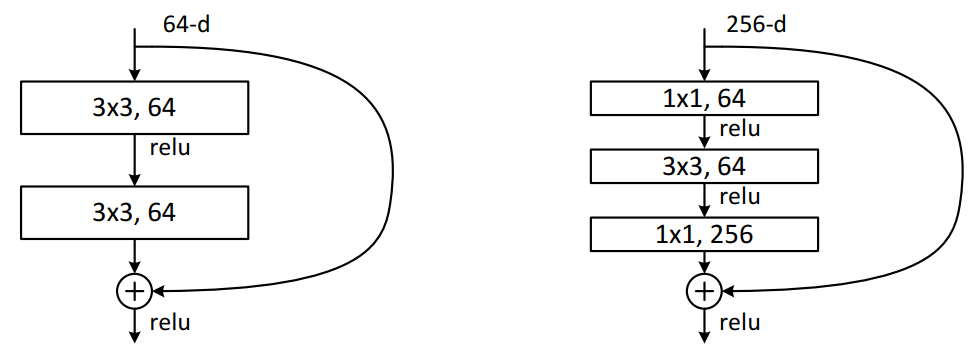
????????在上圖左側圖可以看到輸入特征矩陣的channels是64,經過一個3x3的卷積核卷積之后,要進行Relu激活函數的激活,再經過一個3x3的卷積核進行卷積,但是在這之后并沒有直接經過激活函數進行激活。并且可以看到,在主 分支上有一個圓弧的線從輸入特征矩陣直接連到了一個加號,這個圓弧的線是shortcut(捷徑分支),它直接將 輸入特征矩陣加到經過第二次3x3的卷積核卷積之后的輸出特征矩陣,注意,這里描述的是加,而不是疊加或者拼 接,也就是說是矩陣對應維度位置進行一個和法運算,意味著主分支的輸出矩陣和shortcut的輸出矩陣的shape必 須相同,這里包括寬、高、channels,在相加之后,再經過Relu激活函數進行激活。
????????在上圖右側圖可以看到輸入特征矩陣的channels是256,要先經過一個1x1的卷積,之前在GoogLeNet提到過, 1x1的卷積是為了維度變換,所以這里也是先用1x1的卷積進行降維到64,然后再使用3x3的卷積進行特征提取, 提取完成后,在通過1x1的卷積進行升維到256,之后得到的輸出矩陣再和經過shortcut的輸入矩陣進行對應維度 位置的加法運算,在相加之后,再經過Relu激活函數進行激活。
????????可以看到上圖中shortcut有實線和虛線部分,實現部分就是普通的shortcut,可以看到虛線部分不僅僅有 channels變化,還有特征矩陣的寬和高變化,虛線部分一個處理來讓主分支的輸出特征矩陣和shortcut的輸出特 征矩陣保持一致 。
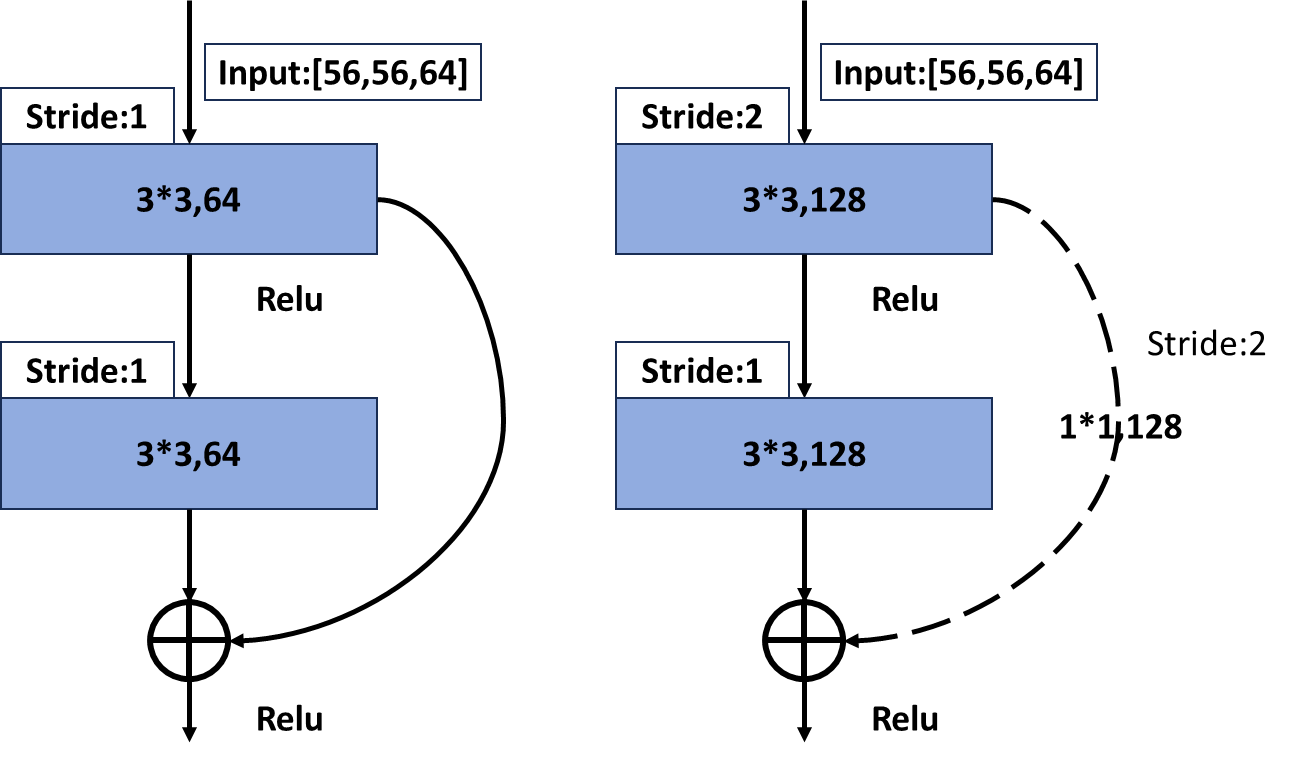
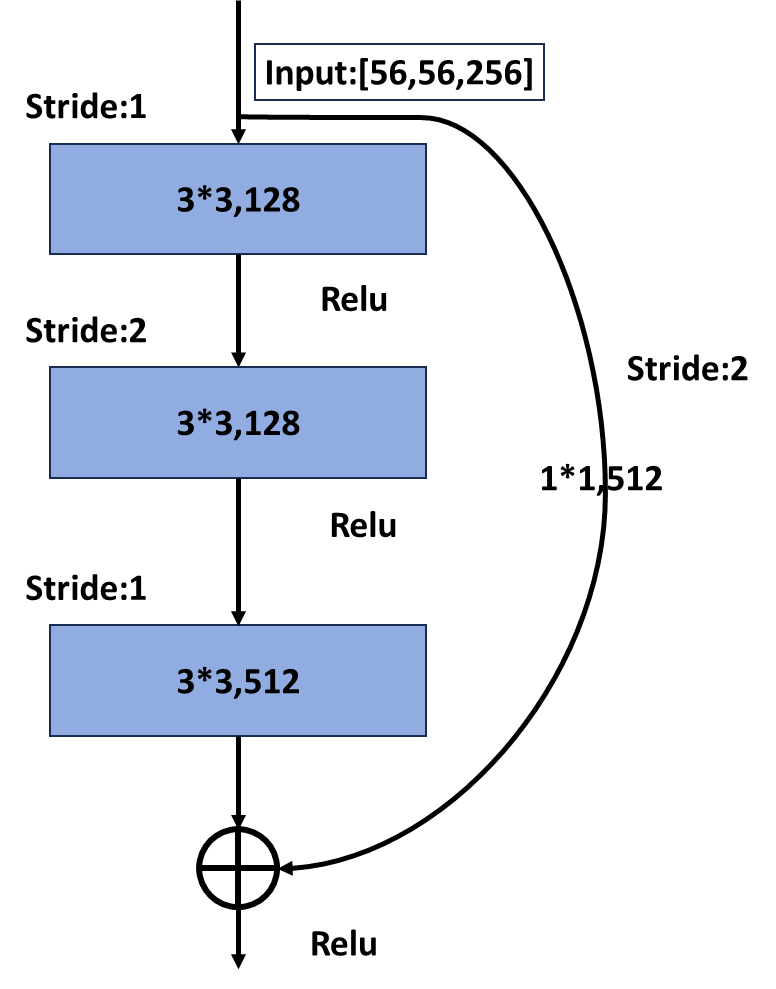
????????從上圖左側圖可以看到,當主分支的輸入特征矩陣和輸出特征矩陣的shape一致時,輸入特征矩陣可以經過 shortcut得到輸出特征矩陣直接與主分支的輸出特征矩陣進行加法運算,但是上圖右側圖主分支上由于步長=2, 導致矩陣的寬和高都減半了,同時由于第一個卷積核的個數是128,導致channels從64升到了128,從而 channels也不一樣了,所以主分支的輸出特征矩陣是[28,28,128],那么如果將shortcut分支上加一個卷積運算, 卷積核個數為128,步長為2,那么經過shortcut分支的輸出矩陣也同樣為[28,28,128],那么兩個輸出矩陣又可以 進行相加了。

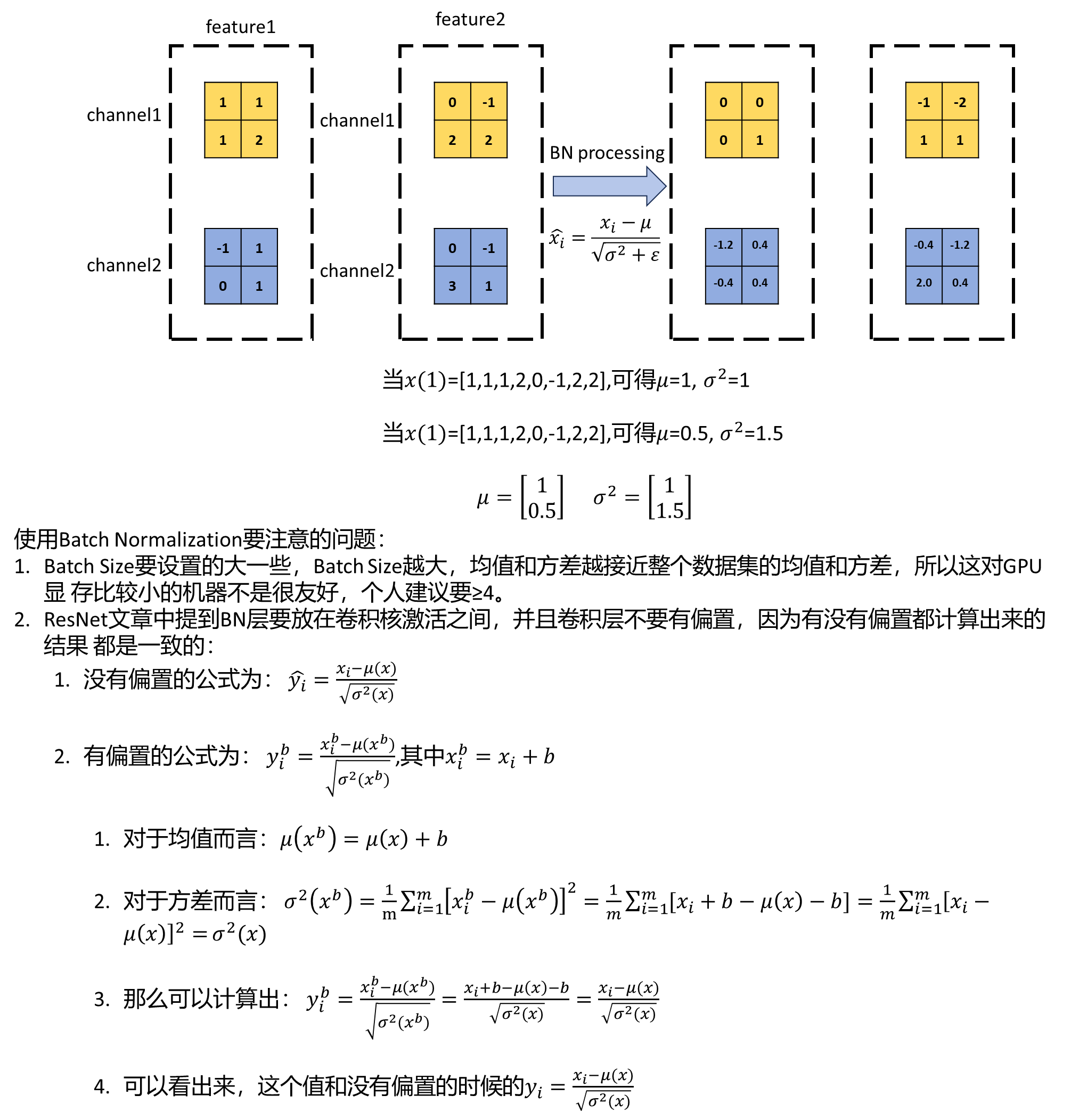
?2.4、Batch Normalization
????????Batch Normalization的作用是將一個批次(Batch)的特征矩陣的每一個channels計算為均值為0,方差為1的分 布規律。
????????一般而言,在一個神經網絡輸入圖像之前,會將圖像進行預處理,這個預處理可能是標準化處理等手段,由于輸 入數據滿足某一分布規律,所以會加速網絡的收斂。這樣在輸入第一次卷積的時候滿足某一分布規律,但是在輸 入第二次卷積時,就不一定滿足某一分布規律了,再往后的卷積的輸入就更不滿足了,那么就需要一個中間商, 讓上一層的輸出經過它之后能夠某一分布規律,Batch Normalization就是這個中間商,它可以讓輸入的特征矩陣 的每一個channels滿足均值為0,方差為1的分布規律。

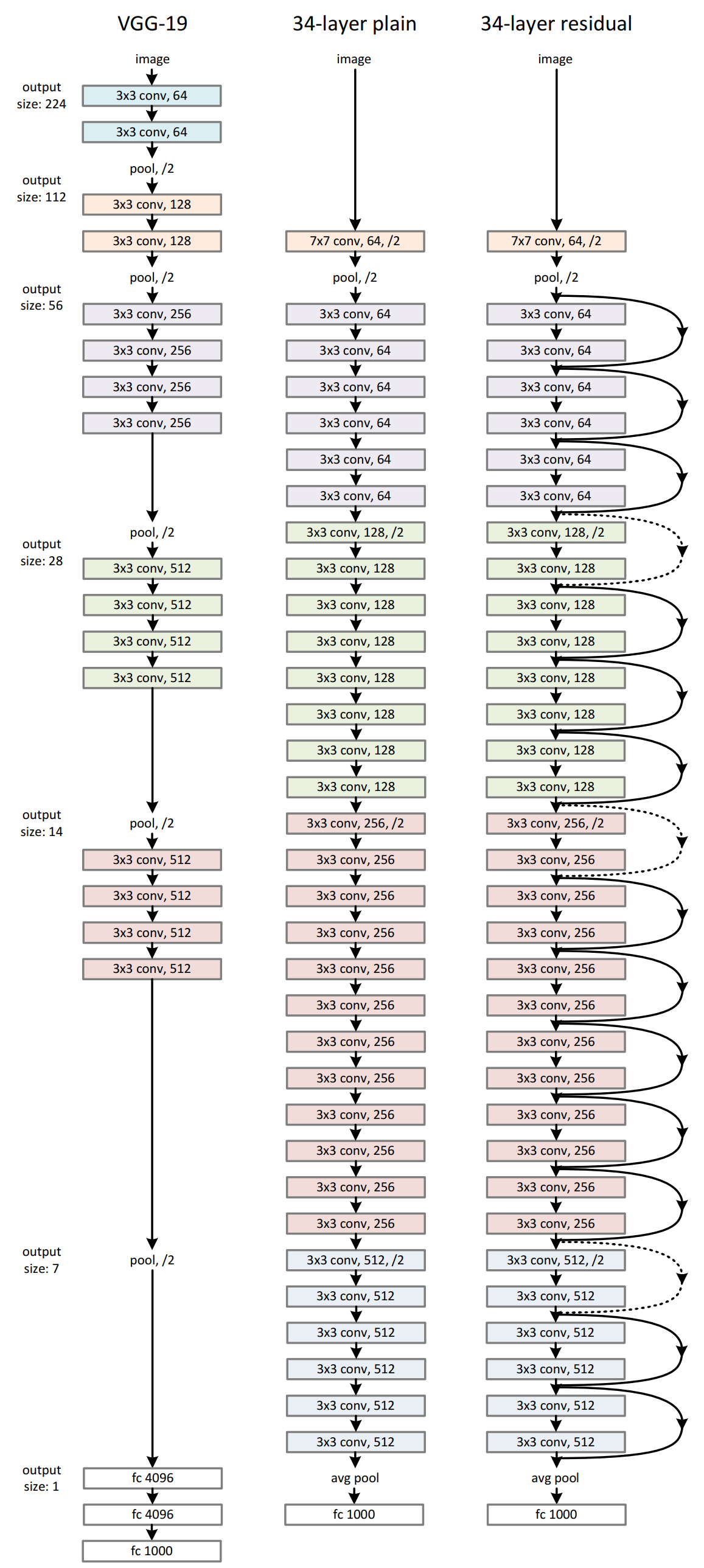
2.5、網絡的結構
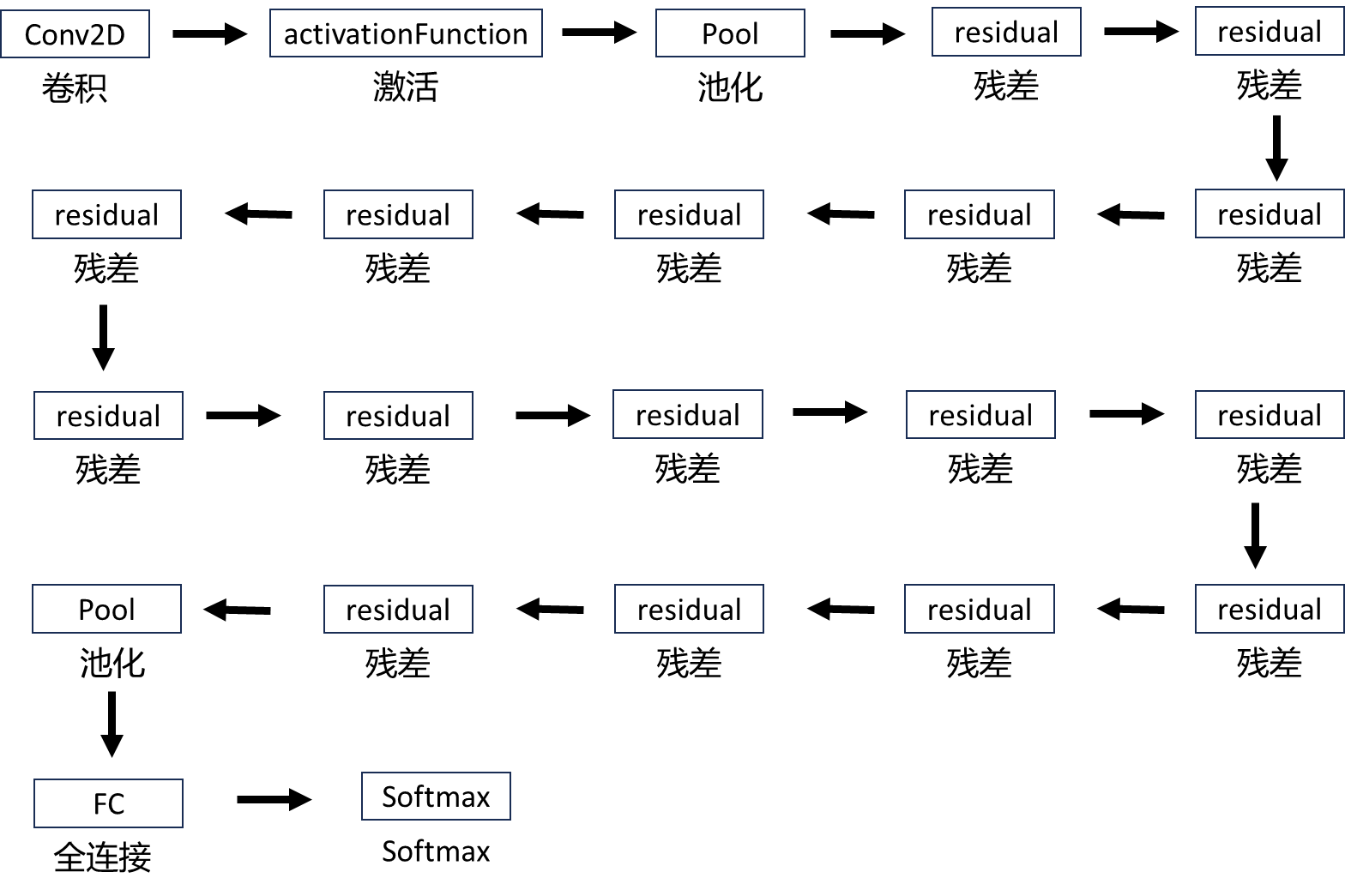
2.6、設計思路
import torch
import torch.nn as nn
from torch import Tensor
from torchsummary import summaryclass BasicBlock(nn.Module):expansion = 1 # 擴張因子,用于調整輸入和輸出通道數def __init__(self, inplanes, planes, stride=1, downsample=None):super().__init__()# 定義第一個卷積層self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(planes) # 批歸一化self.relu = nn.ReLU(inplace=True) # 激活函數# 定義第二個卷積層self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes) # 批歸一化self.downsample = downsample # 可能的降采樣操作self.stride = stride # 步幅def forward(self, x):identity = x # 保存輸入,用于跳躍連接out = self.conv1(x) # 通過第一個卷積層out = self.bn1(out) # 批歸一化out = self.relu(out) # 激活out = self.conv2(out) # 通過第二個卷積層out = self.bn2(out) # 批歸一化if self.downsample is not None: # 如果有降采樣操作identity = self.downsample(x) # 對輸入進行降采樣out += identity # 跳躍連接out = self.relu(out) # 激活return out # 返回輸出class Bottleneck(nn.Module):"""注意:原論文中,在虛線殘差結構的主分支上,第一個1x1卷積層的步距是2,第二個3x3卷積層步距是1。但在pytorch官方實現過程中是第一個1x1卷積層的步距是1,第二個3x3卷積層步距是2,這么做的好處是能夠在top1上提升大概0.5%的準確率。可參考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch"""expansion: int = 4 # 擴張因子,用于調整輸入和輸出通道數def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, base_width=64, dilation=1):super().__init__()width = int(planes * (base_width / 64.0)) * groups # 計算卷積的寬度self.conv1 = nn.Conv2d(inplanes, width, kernel_size=1, stride=1, bias=False)self.bn1 = nn.BatchNorm2d(width) # 批歸一化self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=dilation, bias=False)self.bn2 = nn.BatchNorm2d(width) # 批歸一化self.conv3 = nn.Conv2d(width, planes * self.expansion, kernel_size=1, stride=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * self.expansion) # 批歸一化self.relu = nn.ReLU(inplace=True) # 激活函數self.downsample = downsample # 可能的降采樣操作self.stride = stride # 步幅def forward(self, x: Tensor) -> Tensor:identity = x # 保存輸入,用于跳躍連接out = self.conv1(x) # 通過第一個卷積層out = self.bn1(out) # 批歸一化out = self.relu(out) # 激活out = self.conv2(out) # 通過第二個卷積層out = self.bn2(out) # 批歸一化out = self.relu(out) # 激活out = self.conv3(out) # 通過第三個卷積層out = self.bn3(out) # 批歸一化if self.downsample is not None: # 如果有降采樣操作identity = self.downsample(x) # 對輸入進行降采樣out += identity # 跳躍連接out = self.relu(out) # 激活return out # 返回輸出class ResNet(nn.Module):def __init__(self, block, layers, num_classes=1000):super().__init__()self.inplanes = 64 # 初始通道數# 定義初始卷積層self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(self.inplanes) # 批歸一化self.relu = nn.ReLU(inplace=True) # 激活函數self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大池化層self.layer1 = self._make_layer(block, 64, layers[0]) # 第一層self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 第二層self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # 第三層self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # 第四層self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自適應平均池化self.fc = nn.Linear(512 * block.expansion, num_classes) # 全連接層def _make_layer(self, block, planes, blocks, stride=1):downsample = None # 初始化降采樣層# 如果需要降采樣if stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample) # 添加塊)self.inplanes = planes * block.expansion # 更新輸入通道數for _ in range(1, blocks): # 添加后續的塊layers.append(block(self.inplanes, planes))return nn.Sequential(*layers) # 返回層的序列def forward(self, x):x = self.conv1(x) # 通過初始卷積層x = self.bn1(x) # 批歸一化x = self.relu(x) # 激活x = self.maxpool(x) # 池化x = self.layer1(x) # 通過第一層x = self.layer2(x) # 通過第二層x = self.layer3(x) # 通過第三層x = self.layer4(x) # 通過第四層x = self.avgpool(x) # 通過自適應平均池化x = torch.flatten(x, 1) # 展平張量x = self.fc(x) # 通過全連接層return x # 返回輸出# 定義不同版本的ResNet
def resnet18(num_classes=1000):# https://download.pytorch.org/models/resnet18-f37072fd.pthreturn ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)def resnet34(num_classes=1000):# https://download.pytorch.org/models/resnet34-333f7ec4.pthreturn ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)def resnet50(num_classes=1000):# https://download.pytorch.org/models/resnet50-19c8e357.pthreturn ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes)def resnet101(num_classes=1000):# https://download.pytorch.org/models/resnet101-63fe2227.pthreturn ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes)def resnet152(num_classes=1000):# https://download.pytorch.org/models/resnet152-394f9c45.pthreturn ResNet(Bottleneck, [3, 8, 26, 3], num_classes=num_classes)if __name__ == '__main__':# model = resnet18(num_classes=3)# model = resnet34(num_classes=3)# model = resnet50(num_classes=3)# model = resnet101(num_classes=3)model = resnet152(num_classes=3) # 創建ResNet152模型print(summary(model, (3, 224, 224))) # 打印模型總結from torchvision import models
from torchsummary import summaryresnet_models = {"resnet18": models.resnet18(pretrained=False),"resnet34": models.resnet34(pretrained=False),"resnet50": models.resnet50(pretrained=False),"resnet101": models.resnet101(pretrained=False),"resnet152": models.resnet152(pretrained=False),
}
'''
當pretrained=True是會自動下載預訓練模型
'''for name, model in resnet_models.items():print(summary(model,(3,244,244)))








)

知識詳解(2)和注意事項以及應用示例)


)

)


——合理使用表分區)
