
一、GPU 與顯卡的概念澄清
首先需要明確一個容易誤解的概念:GPU 不等同于顯卡。
顯卡和GPU是兩個不同的概念。
【概念區分】
在討論圖形計算領域時,需首先澄清一個常見誤區:GPU(圖形處理單元)與顯卡(視頻卡)并非等同概念。通俗理解,GPU是顯卡的核心計算單元,二者是包含關系而非全等關系。
【核心組件解析】
顯卡作為計算機與顯示器的連接樞紐,是由以下組件構成的完整硬件系統:
□ GPU計算芯片(核心處理單元)
□ 顯存(VRAM,存儲圖形數據)
□ 主板接口及供電模塊
□ BIOS固件(控制硬件運行)
□ 輸出接口(HDMI/DP等)
這一系統通過顯卡將計算機處理后的圖形數據轉換為顯示器可識別的信號。
【技術功能演進】
GPU作為專為圖形計算設計的微處理器,其技術演進呈現明顯分化:
- 基礎功能:實現并行圖形運算(如3D建模、視頻解碼)
- 技術擴展:利用并行計算優勢,涉足科學計算(如分子建模)、AI訓練(如NPU輔助訓練)等領域
- 架構革新:從固定功能管線發展到可編程著色器,支持光線追蹤等高級渲染技術
【精簡類比說明】
若將顯卡類比為"圖形工作站",GPU則相當于其中的"超級計算核心":
顯卡 = GPU + 輔助系統(顯存、電源、接口等)
GPU = 專注圖形/通用計算的專業處理器
這一區別類似于中央處理器(CPU)與主板的關系——重要組件而非完整系統。
簡單來說,顯卡是帶圖形輸出功能的 GPU 組件集合,而 GPU 泛指具有計算功能的圖形處理器芯片。
【延伸閱讀】
(一)本質定義與硬件構成
顯卡(Graphics Card)
- 屬性:是計算機系統中獨立的硬件組件,必須具備圖形輸出功能,用于將數字信號轉換為圖像信號并輸出至顯示器。
- 核心構成:
??GPU 芯片:負責圖形渲染與并行計算(如 NVIDIA Ada Lovelace 架構 GPU);
??顯存(VRAM):獨立存儲空間(如 GDDR6 顯存),用于緩存圖形數據;
??電路板(PCB):集成供電模塊、接口芯片(如 HDMI/DP 控制器)等;
??BIOS 固件:存儲硬件配置信息,控制初始化流程。
GPU(英文全稱:Graphics Processing Unit)
- 屬性:是專注于并行計算的處理器芯片,早期以圖形渲染為核心功能,現代 GPU 已擴展至通用計算(GPGPU)領域。
- 應用場景:
??傳統場景:圖形渲染(如游戲、CAD 設計);
??AI 場景:深度學習訓練 / 推理(如 CUDA 加速的 PyTorch 模型)、科學計算(如氣象模擬)。
(二)關鍵差異對比
| 維度 | 顯卡 | GPU |
|---|---|---|
| 功能完整性 | 完整的圖形輸出解決方案 | 僅為計算核心(需搭配其他組件) |
| 硬件獨立性 | 可獨立安裝于主板 PCIe 插槽 | 可能集成于 CPU(如核顯 GPU)或獨立存在 |
| AI 計算適配性 | 依賴顯存容量與計算單元配置 | 核心計算能力決定 AI 性能(如 Tensor Core 數量) |
| 典型產品 | NVIDIA RTX 4080 顯卡 | NVIDIA A100 GPU(計算卡核心) |
(三)AI 開發場景的特殊意義
在人工智能開源項目中,GPU 的 “計算屬性” 被高度放大,而顯卡的 “顯示屬性” 退居次要地位:
- 獨立顯卡的雙重角色:
當用于 AI 計算時,顯卡的 GPU 芯片承擔張量運算任務(如矩陣乘法),但顯存容量、帶寬等參數的重要性遠超圖形渲染性能。例如:
? RTX 4090 顯卡的 24GB GDDR6X 顯存更適合中小型模型訓練,而 RTX A6000 專業卡的 48GB 顯存則適用于高精度可視化與計算混合場景。 - 核顯的 GPU 屬性:
主板集成的核顯(如 Intel UHD Graphics)本質上是集成于 CPU 的低功耗 GPU,雖計算性能弱于獨顯,但可通過 OpenCL 等框架參與輕量級 AI 任務(如圖像預處理),同時承擔系統顯示功能。
(四)常見認知誤區
??誤區 1:GPU = 顯卡
→ 正解:顯卡是包含 GPU 的完整硬件系統,而 GPU 可以是獨立芯片(如獨顯 GPU)或集成芯片(如核顯 GPU)。
??誤區 2:AI 計算只需顯卡無需核顯
→ 正解:當顯卡(如計算卡)專注 AI 計算時,核顯的顯示功能成為系統交互的必需組件,尤其在顯存滿載時保障桌面流暢性。
二、核顯在 AI 開源項目中的獨特價值
在家用或辦公 Windows 電腦運行人工智能開源項目時,即使已配備獨立顯卡,保留或配備核顯仍具有顯著必要性,這主要體現在以下方面:
(一)顯存瓶頸下的系統流暢性保障
人工智能開源項目(如深度學習框架 TensorFlow、PyTorch 等)對顯存資源具有高度依賴性。當獨立顯卡的顯存占用逼近或超過 100% 時,會導致以下問題:
- 系統響應卡頓:獨顯因全力處理 AI 計算任務,難以兼顧圖形輸出任務,導致桌面操作、窗口切換等交互操作延遲明顯。
- 程序穩定性風險:顯存溢出可能引發程序崩潰、系統藍屏等極端情況,影響開發調試效率。
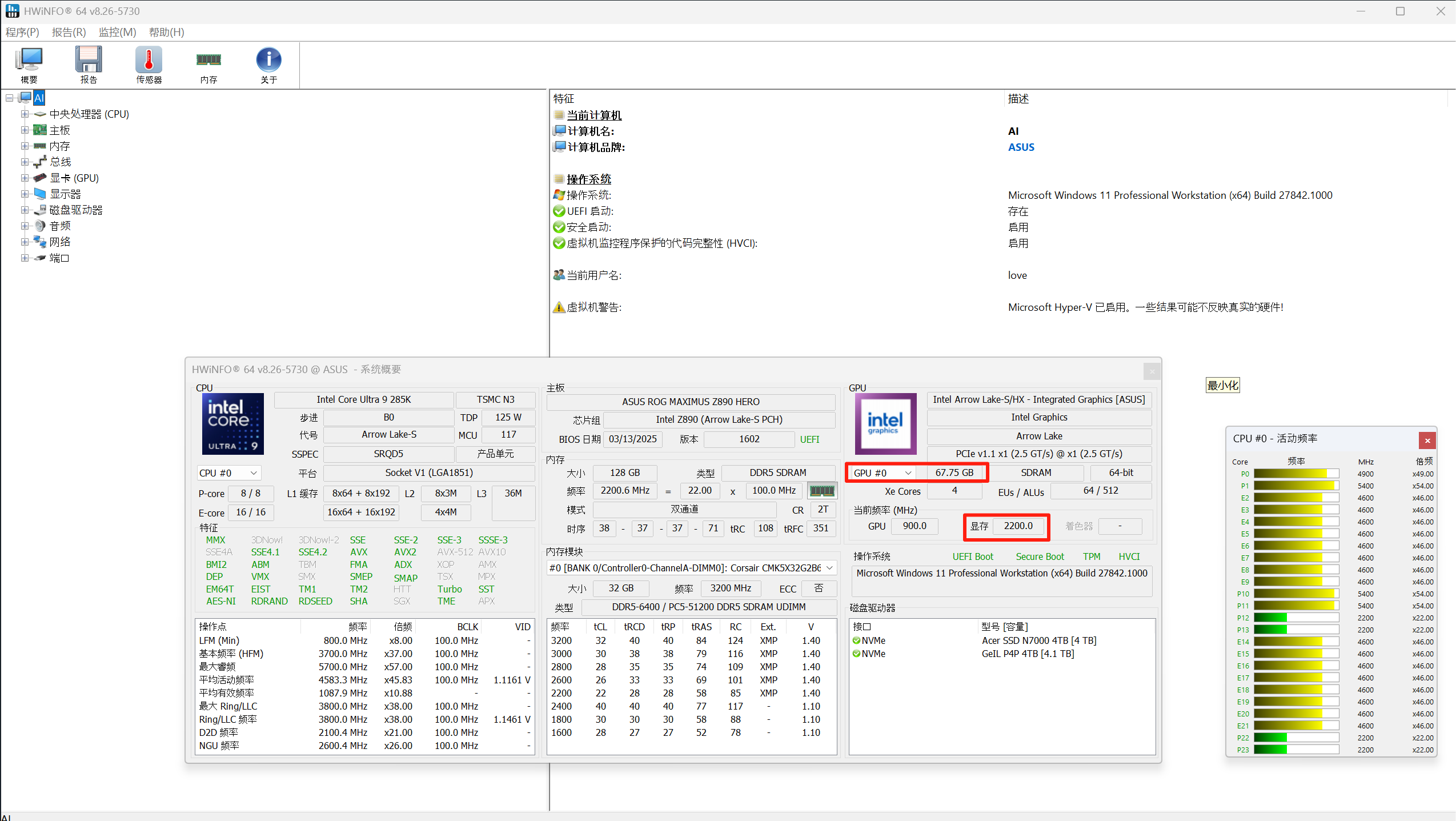
若將顯示器通過光纖 HDMI 2.1 線或 DP 光纖線連接至核顯,則可構建獨顯專注計算、核顯負責圖形輸出的分工模式:
- 計算與顯示解耦:核顯獨立承擔桌面渲染、視頻輸出等任務,釋放獨顯的全部顯存資源用于 AI 計算,避免因顯存競爭導致的系統卡頓。
- 熱插拔兼容性優勢:部分主板支持核顯輸出與獨顯計算的動態切換,即使獨顯因高負載暫時 “凍結”,核顯仍能維持顯示器正常輸出,保障用戶對電腦的實時操控。
(二)多任務協同與能效優化
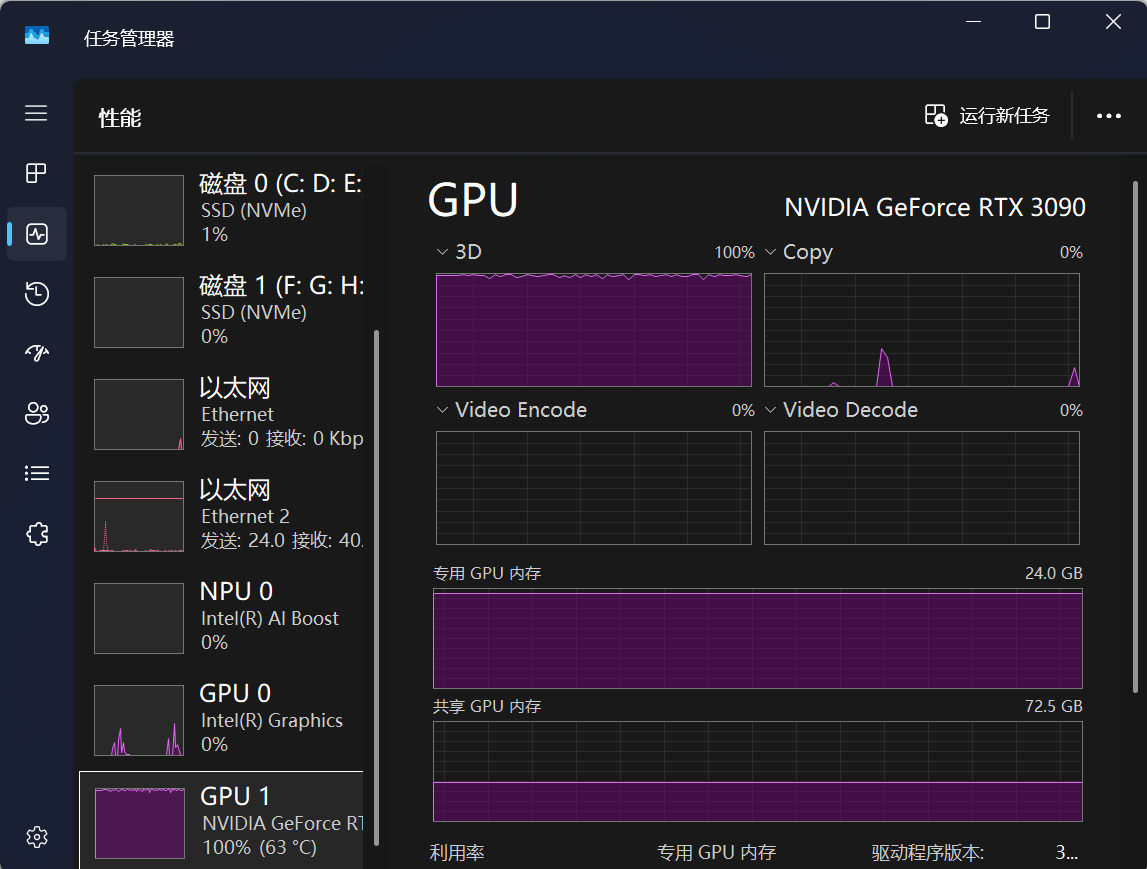
核顯的存在可進一步提升 Windows 系統在 AI 開發場景下的多任務處理能力:
- 異構計算支持:部分 AI 框架(如 OpenCL)支持核顯與獨顯的混合計算,可將輕量化任務(如圖像預處理、模型推理)分配至核顯執行,充分利用硬件資源。
- 低負載場景能效比優勢:在非 AI 計算任務(如日常辦公、網頁瀏覽)中,核顯的功耗顯著低于獨顯,可延長筆記本電腦續航,或降低臺式機的整體功耗。
(三)兼容性與調試便利性
- 驅動與系統兼容性:部分老舊 AI 開源項目或特定框架版本對獨顯驅動兼容性存在限制,核顯可作為備用圖形方案,避免因驅動沖突導致項目無法運行。
- 調試環境隔離:在調試 AI 模型時,核顯可獨立輸出調試界面(如 TensorBoard 可視化窗口),避免因獨顯計算任務中斷導致調試信息丟失。
三、NPU 的引入:AI 計算的專用加速單元
(一)NPU 的定義與特性
NPU(神經網絡處理單元)是專為人工智能任務設計的專用計算芯片,基于張量運算架構(如矩陣乘法)優化,相比傳統 GPU 的通用計算架構,在深度學習模型推理任務中具備更高能效比與更低延遲。例如:
- 英特爾第 12 代酷睿處理器集成的 NPU 可加速 Stable Diffusion 圖像生成任務,推理速度提升約 30%。
- 部分 AMD 銳龍 APU(如 Ryzen 7 7840HS)通過 VCN(視頻編碼單元)與 NPU 協同,可實現 AI 視頻降噪與編碼同步處理。
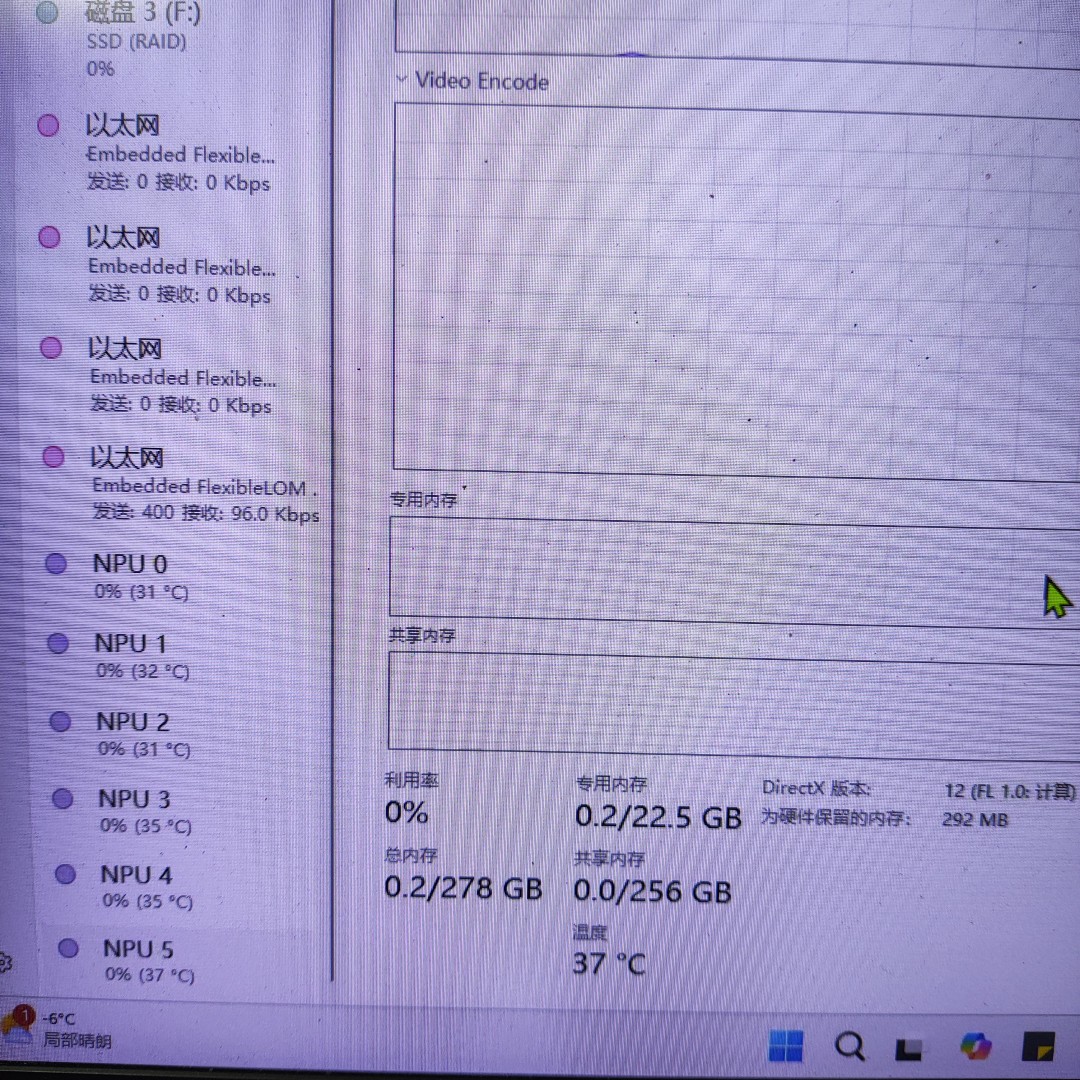
(二)核顯與 NPU 的協同場景
當核顯與 NPU 集成于同一 CPU 芯片時(如 Intel UHD Graphics + NPU),可構建輕量級 AI 加速方案:
- 端側推理優化:在邊緣計算場景(如家用安防攝像頭數據處理)中,核顯負責視頻流解碼與渲染,NPU 獨立執行目標檢測模型推理,減少對獨顯的依賴。
- 低功耗 AI 應用:筆記本電腦在電池模式下,可通過 NPU 運行輕量化模型(如 MobileNet),避免喚醒獨顯導致的續航驟降。
?
四、專業卡、游戲卡、計算卡的差異化適配分析
(一)硬件設計目標差異
| 類型 | 核心架構優化方向 | 顯存配置特點 | 驅動支持重點 |
| 專業卡 | 圖形渲染精度、API 兼容性 | 高容量顯存(如 32GB GDDR6) | 支持 OpenGL/DirectX 專業圖形接口 |
| 游戲卡 | 實時圖形渲染速度 | 中高容量顯存(8-24GB GDDR6) | 側重游戲引擎優化 |
| 計算卡 | 并行計算效率、雙精度浮點 | 超大容量顯存(如 A100 的 80GB HBM3) | 深度優化 CUDA/ROCm 計算框架 |
(二)對 AI 開源項目的適配性對比
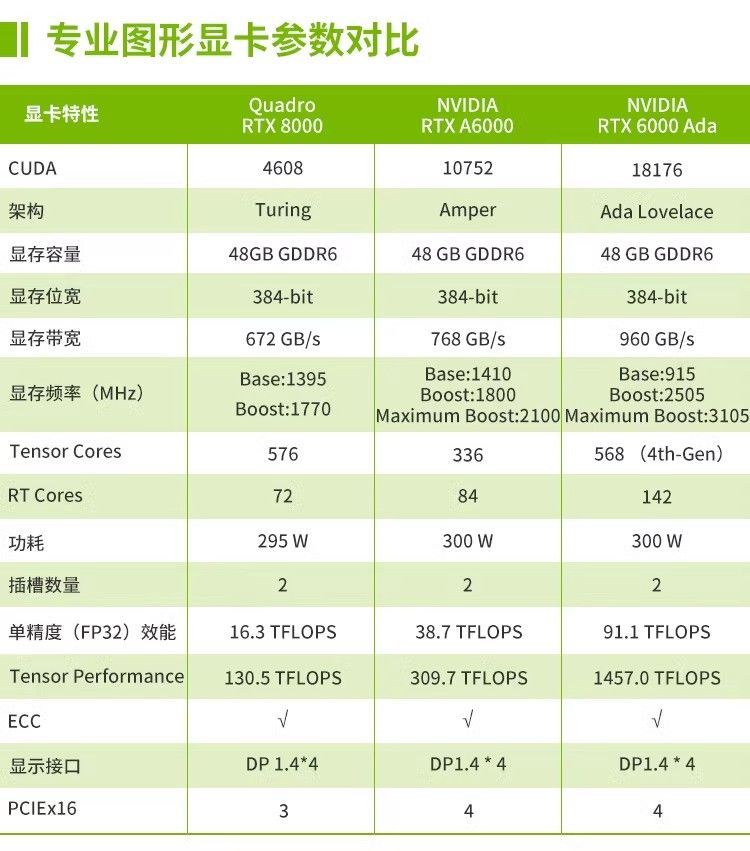
1. 專業卡(如 NVIDIA RTX A 系列)
- 優勢場景:需高精度圖形渲染的 AI 可視化項目(如 3D 點云標注、醫學影像重建),支持 CUDA 與 OptiX 庫協同加速。
- 局限性:顯存容量雖大但成本高昂,通用計算性能略低于同價位計算卡。
2. 游戲卡(如 NVIDIA RTX 40 系列)
- 優勢場景:中小型深度學習模型訓練(如 ResNet-34 圖像分類),憑借 CUDA 核心數量與顯存性價比(如 RTX 4090 的 24GB 顯存)成為入門級首選。
- 局限性:缺乏 ECC 顯存糾錯機制,長時間高負載訓練可能因數據位錯誤導致模型崩潰。
3. 計算卡(如 NVIDIA A10/A40)
- 優勢場景:大規模模型訓練(如 GPT-2 級別自然語言處理)、科學計算模擬,HBM 顯存帶寬是 GDDR6 的 3-5 倍,支持多卡 NVLink 互聯。
- 局限性:無視頻輸出接口,必須依賴核顯或專業卡實現桌面輸出,且功耗較高(如 A100 單卡 300W),需配套散熱系統。

(三)核顯在異構計算中的橋梁作用
無論使用何種類型顯卡,核顯均可作為系統圖形輸出的 “基礎錨點”:
- 專業卡 + 核顯組合:在 CAD 設計與 AI 算法開發并行場景中,核顯輸出設計界面,專業卡運行 AI 驅動的自動化建模任務。
- 計算卡 + 核顯組合:純計算卡(如 NVIDIA Tesla 系列)無顯示功能,必須通過核顯實現系統初始化與調試界面輸出,避免 “有卡無顯” 的尷尬局面。
-
計算卡的圖形輸出依賴問題:
以 NVIDIA Tesla 系列為代表的專業計算卡(如 A100、V100)完全剝離圖形輸出功能,僅保留 PCIe 計算接口。這類顯卡在 Linux/Windows 服務器中運行 AI 訓練任務時,必須通過核顯或獨立專業卡實現系統顯示。例如:
某用戶配置的數萬元級 AI 服務器采用 NVIDIA A40 計算卡,因無視頻接口導致系統初始化時無法輸出畫面,最終通過主板核顯(Intel UHD Graphics)連接顯示器完成驅動調試。
計算卡高負載運行時,若未連接核顯,用戶將無法通過本地顯示器監控任務狀態,只能依賴遠程 SSH 調試,增加操作復雜度。
- 核顯對計算卡的必要性延伸:
即使在 Linux 服務器場景中,核顯仍可作為 “帶外管理” 的硬件基礎 —— 當計算卡因顯存溢出或程序崩潰導致系統無響應時,核顯輸出的控制臺界面(如 GRUB 引導菜單、SSH 登錄界面)仍是唯一可交互的本地通道。
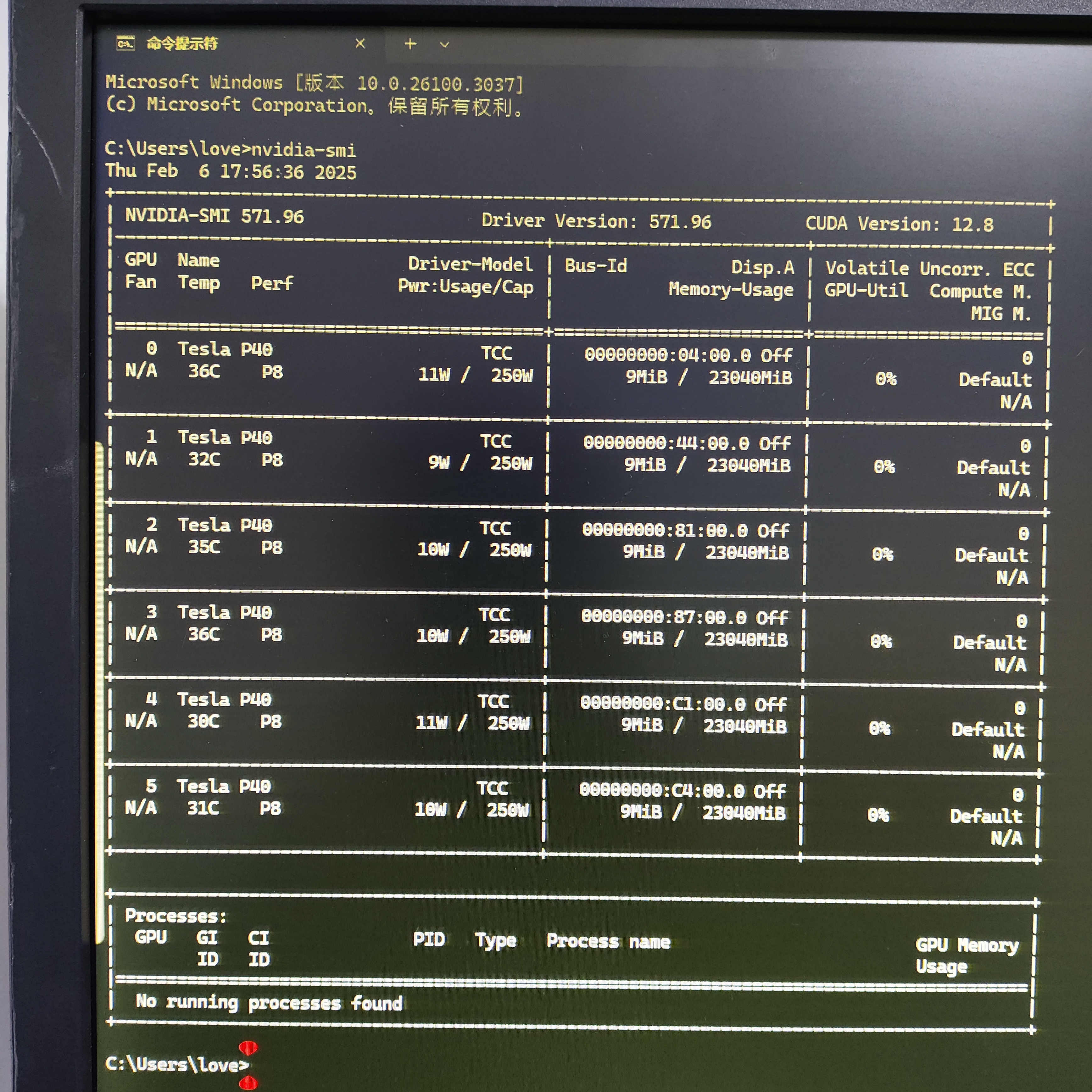
如果需要圖形支持,需要另外安裝GRID驅動,且效果不是很完美
?
五、硬件配置與連接方案建議(擴展內容)
(一)NPU 兼容 CPU 選擇
- Intel 陣營:優先選擇帶 “P” 或 “U” 后綴的處理器(如 i5-1340P),集成 NPU 與核顯,支持 OpenVINO 工具鏈加速。
- AMD 陣營:Ryzen 7000 系列 APU(如 7840HS)通過 AMD VCN 單元實現視頻處理與 NPU 聯動,適合多媒體 AI 項目。
(二)顯卡類型與核顯協同策略
- 游戲卡用戶:核顯承擔日常顯示任務,游戲卡專注 AI 計算,通過 NVIDIA Optimus 技術動態切換(需在 BIOS 中啟用核顯輸出)。?
- 計算卡用戶:強制將顯示器連接核顯,計算卡通過 PCIe 插槽專用于 AI 訓練,避免因顯示驅動占用計算資源。
- 計算卡服務器用戶:
無論操作系統為 Windows 或 Linux,必須確保主板 CPU 支持核顯輸出,并將顯示器物理連接至核顯接口。例如:- 使用 AMD Ryzen 9 7950X(帶 Vega 核顯)搭配 NVIDIA A10 計算卡時,核顯負責輸出系統桌面,計算卡通過 CUDA 工具鏈專用于模型訓練。
- 避免因 “計算卡無顯示功能” 導致的 “黑屏調試” 困境,尤其在 BIOS 設置、驅動安裝等關鍵環節,核顯是不可替代的交互入口。
六、典型應用場景擴展(含 NPU 與顯卡類型)
- 多模態 AI 開發:核顯渲染文本 - 圖像聯合模型的可視化界面,NPU 加速文本嵌入計算,獨顯執行圖像生成任務,形成 “顯示 + 預處理 + 計算” 的流水線架構。
- 邊緣 AI 服務器:使用計算卡(如 A10)運行推理模型,核顯輸出服務器管理界面,NPU 實時處理傳感器數據預處理,降低整體功耗。
七、總結
對于 AI 開發硬件架構而言,核顯是連接 “計算任務” 與 “人機交互” 的底層樞紐:
- 對游戲卡 / 專業卡用戶,核顯通過功能分工提升系統流暢性;
- 對計算卡用戶,核顯是物理顯示的剛需組件,甚至在服務器場景中決定了本地運維的可行性。
這一設計邏輯在 Windows 辦公環境與 Linux 服務器中具有一致性 ——核顯的價值遠超 “備用顯卡” 范疇,而是現代 AI 開發平臺的基礎組成部分。
核顯的價值已從單純的 “備用顯示” 延伸為 AI 硬件生態中的系統級協調組件:與 NPU 協同實現輕量級計算,為專業卡 / 計算卡提供顯示兜底,與游戲卡形成 “日常 - 計算” 分工。在選擇顯卡類型時需明確:游戲卡適合快速驗證,專業卡適合圖形 - AI 融合場景,計算卡是大規模訓練的終極方案,但三者均需核顯作為系統交互的基礎支撐。對于家用或辦公場景,建議優先選擇帶核顯的 CPU(如 i5-14600K 或 Ryzen 5 7600G),再根據項目規模疊加對應類型顯卡,構建性價比與擴展性兼備的 AI 開發平臺。
參考資料(擴展內容)
2025 年電腦硬件選購指南量表(“硬件卡尺”)_電腦硬件評測-CSDN博客
全文總結:
在 2025 年人工智能蓬勃發展的背景下,用戶對電腦及服務器的 AI 性能期望提升。作者因工作需要完成服務器與前端配置,過程中發現硬件從業者與軟件應用間存在認知鴻溝,為突破困境編制 “硬件卡尺” 量表。該量表為硬件選購提供清晰實用評估標準,以不同硬件組件為分類,詳細闡述各組件關鍵參數、示例產品及適用場景。如處理器關鍵參數包括核心數、主頻等,主板涉及芯片組、內存支持等,內存涵蓋內存類型、容量等,顯卡有顯存、GPU 架構等,存儲則區分存儲類型、接口類型等,全方位為硬件選購者提供全面、可靠參考依據。
重要亮點
- 硬件知識學習的背景與動機:在 2025 年科技浪潮中,AI 技術發展促使人們對設備 AI 性能要求提高。作者在服務器與前端配置工作里,發現硬件從業者與軟件應用存在認知隔閡,為解決硬件在特定 AI 場景適配性問題,通過查閱大量資料與真機測試,編制 “硬件卡尺” 量表,助力硬件選購者做出更優決策。
- 處理器選購要點:處理器關鍵參數多樣。核心數和線程數影響并行處理能力,主頻關乎單線程性能,不同架構各有優勢,緩存大小影響數據處理效率,TDP 與散熱功耗相關,集成顯卡滿足不同圖形需求,NPU 支持用于 AI 加速,ECC 支持保障數據可靠性,PCIe 通道支持決定數據傳輸速率。如 Intel Core Ultra 9 285K 適合多任務與 AI 推理,AMD Ryzen 9 7950X 適用于專業視頻編輯等。
- 主板選購要點:主板關鍵參數包括芯片組,不同芯片組對內存、PCIe 及處理器適配有別;內存支持需關注 DDR5 相關參數及插槽數量;PCIe 插槽帶寬影響顯卡等設備性能發揮;存儲接口涉及 M.2 和 SATA,滿足不同存儲需求;網絡接口分 Wi - Fi 和有線,滿足不同場景;擴展接口提供高速傳輸與設備擴展;供電設計保障電力穩定;BIOS/UEFI 支持方便系統設置;版型分 ATX、Micro - ATX 和 Mini - ITX,適配不同機箱與用戶需求。
- 內存選購要點:內存類型上,DDR5 帶寬高、功耗低,適合高端應用,DDR4 價格親民,適用于普通場景。容量選擇依使用場景而定,日常辦公 16GB 通常足夠,專業工作需 32GB 或更高。頻率決定數據傳輸速度,但要與主板、處理器匹配。內存時序中 CL 值越低響應越快,需綜合考量。ECC 內存用于對數據準確性要求高的場景,普通用戶用非 ECC 內存即可。雙通道提升帶寬,部分高端主板支持四通道。散熱片保證高頻率內存穩定運行,兼容性確保與各硬件協同工作。
- 顯卡選購要點:選購顯卡需區分其與計算卡。關鍵參數里,顯存容量決定處理復雜圖形能力,不同分辨率和任務需求不同。GPU 架構是性能核心,NVIDIA 和 AMD 架構各有優勢。CUDA 核心 / 流處理器數量影響并行計算能力。光線追蹤支持帶來逼真光影效果,DLSS 等技術提升游戲幀率。NVLink 支持多卡并行,提升專業領域計算性能。散熱設計保障顯卡性能穩定,接口類型決定連接方式,功耗影響電源與散熱布局。不同型號顯卡適用于不同游戲及專業場景。
- 存儲選購要點:存儲類型主要有機械硬盤(HDD)和固態硬盤(SSD)。HDD 容量大、成本低,適合長期存儲不常用數據,但讀寫速度慢。SSD 以高速讀寫性能見長,適合做系統盤和常用程序安裝盤。在 SSD 接口類型中,SATA 接口價格親民但帶寬受限,M.2 接口的 NVMe SSD 基于 PCIe 協議,能提供更高帶寬,如 PCIe 5.0 接口的 NVMe SSD 順序讀取速度可達較高水平,滿足對存儲速度要求高的場景。
?
)








)

知識詳解(2)和注意事項以及應用示例)


)

)


——合理使用表分區)