vllm-ascend介紹:

vLLM 昇騰插件 (vllm-ascend) 是一個讓vLLM在Ascend NPU無縫運行的后端插件。
此插件是 vLLM 社區中支持昇騰后端的推薦方式。它遵循[RFC]: Hardware pluggable所述原則:通過解耦的方式提供了vLLM對Ascend NPU的支持。
使用 vLLM 昇騰插件,可以讓類Transformer、混合專家(MOE)、嵌入、多模態等流行的大語言模型在 Ascend NPU 上無縫運行。
支持的NPU系列:
- Atlas A2 Training series (Atlas 800T A2, Atlas 900 A2 PoD, Atlas 200T A2 Box16, Atlas 300T A2)
- Atlas 800I A2 Inference series (Atlas 800I A2)
部署:
1、拉取鏡像,
docker pull vllm-ascend-dev-image:latest![]()
啟動容器,
docker run -itd \
--name vllm-tool \
--device /dev/davinci2 \
--device /dev/davinci5 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-v /data:/data \
-p 8000:8000 \
-e VLLM_USE_MODELSCOPE=True \
-e PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256 \
quay.io/ascend/vllm-ascend:v0.8.5rc1 bash
其中,/dev/davinci2根據自己的顯卡設置,比如我的是/dev/davinci2、/dev/davinci5
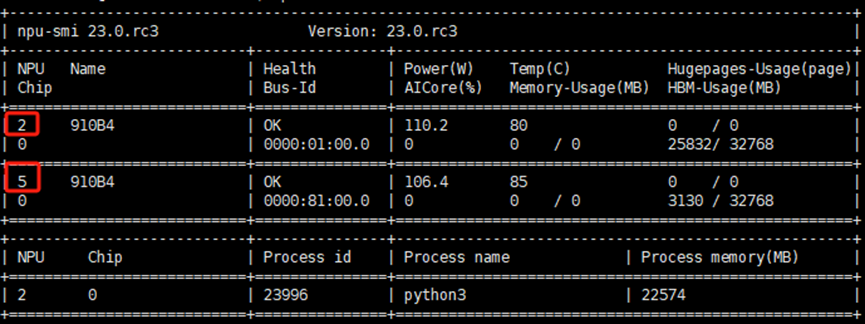
模型文件存儲在/data/models/目錄下,所以掛載了data目錄。
2、利用vllm進行部署模型:
進入容器,
docker exec -it vllm-tool /bin/bash利用vllm進行部署,
vllm serve /data/models/Qwen3-0.6B --trust-remote-code --tensor-parallel-size 1 --dtype half或者,gpu-memory-utilization取值0-1之間,默認取值0.9,之所以增加gpu-memory-utilization參數,是因為DeepSeek 的"max_position_embeddings": 131072,遠遠大于qwen3的"max_position_embeddings": 40960。
vllm serve /data/models/DeepSeek-R1-Distill-Qwen-7B --trust-remote-code --tensor-parallel-size 2 --dtype half --gpu-memory-utilization 0.99--tensor-parallel-size
張量并行通過將單個張量的計算分割成更小的塊,分配到多個 GPU上。這樣可以提高計算的吞吐量,特別是當單個張量的數據量很大時,張量并行可以讓多個 GPU 協同完成一個操作。
解釋:比如跑Qwen3-8B 模型,--tensor-parallel-size=2 表示將一個層中的計算任務分成2份,在2個 GPU 之間并行執行。例如,假設模型的線性層需要矩陣乘法操作,張量并行會將這個矩陣分割到2個 GPU 上并行計算,最終合并結果。
適用場景:張量并行適用于那些計算量大的層(如注意力層和前饋層),它能幫助緩存。
出現以下信息即可:

3、利用curl請求進行對話(在宿主機):
查看模型列表:
curl http://localhost:8000/v1/models | python3 -m json.tool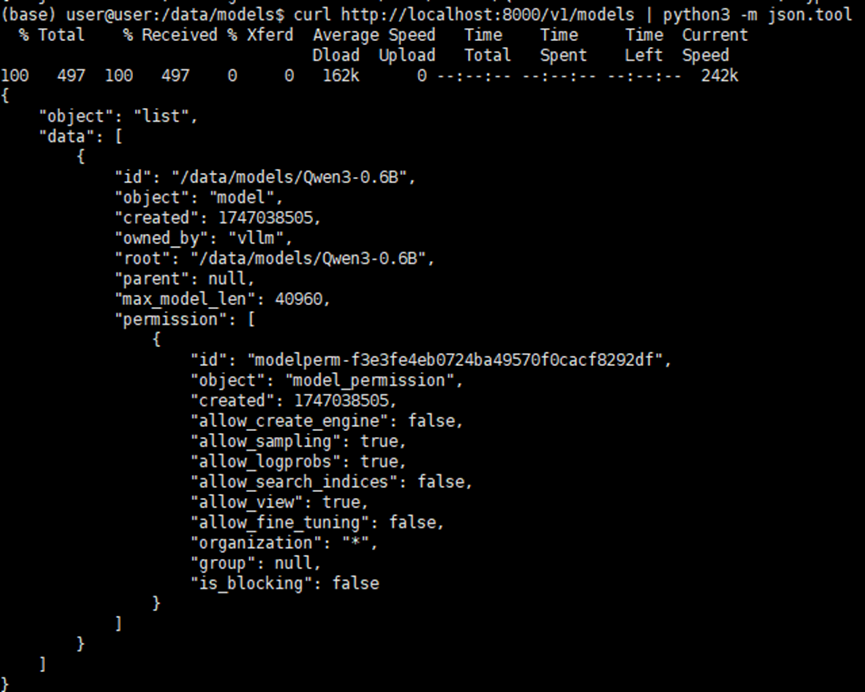
請求服務,
curl http://172.17.1.1:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "/data/models/Qwen2.5-7B-Instruct","messages": [{"role": "user", "content": "你好,請介紹一下你自己"}],"temperature": 0.7,"max_tokens": 512}'
![]()
實測效果:
| 模型 | 顯存占用 |
| Qwen3-0.6B | 25G |
| Qwen3-1.7B | 24G |
| Qwen3-4B | 21G |
| Qwen3-8B | 用了2張卡,1張卡23G,,一共46G |
| DeepSeek-R1-Distill-Qwen-7B | 用了2張卡,1張卡16G,,一共32G |
| Qwen2.5-7B-Instruct | 用了2張卡,1張卡24G,,一共48G |
華為atlas比英偉達的顯存占用高出很多。
參考鏈接:
Quickstart — vllm-ascend
vllm-ascend: vllm_ascend
歡迎來到 vLLM! | vLLM 中文站












:[macOS 64bit App開發]: 如何獲取當前用戶主目錄(即:~波浪符號目錄)?](http://pic.xiahunao.cn/[原創](現代Delphi 12指南):[macOS 64bit App開發]: 如何獲取當前用戶主目錄(即:~波浪符號目錄)?)

)

)


