DeepSeekMath論文筆記
- 0、研究背景與目標
- 1、GRPO結構
- GRPO結構
- PPO知識點
- **1. PPO的網絡模型結構**
- **2. GAE(廣義優勢估計)原理**
- **1. 優勢函數的定義**
- 2.GAE(廣義優勢估計)
- 2、關鍵技術與方法
- 3、核心實驗結果
- 4、結論與未來方向
- 關鍵問題與答案
- 1. **DeepSeekMath在數據處理上的核心創新點是什么?**
- 2. **GRPO算法相比傳統PPO有何優勢?**
- 3. **代碼預訓練對數學推理能力的影響如何?**
0、研究背景與目標
- 挑戰與現狀:
- 數學推理因結構化和復雜性對語言模型構成挑戰,主流閉源模型(如GPT-4、Gemini-Ultra)未開源,而開源模型在MATH等基準測試中性能顯著落后。
- 目標:通過數據優化和算法創新,提升開源模型數學推理能力,逼近閉源模型水平。


1、GRPO結構
GRPO結構
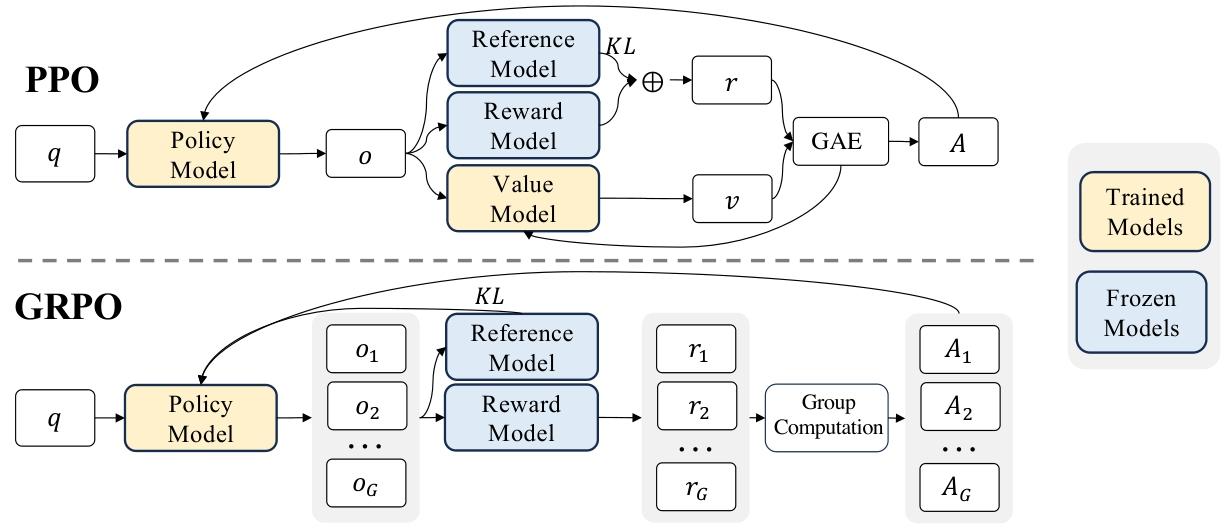
圖 4 |PPO 和我們的 GRPO 示范。GRPO 放棄了價值模型,而是根據組分數估計基線,從而顯著減少了訓練資源。
近端策略優化(PPO)(舒爾曼等人,2017年)是一種演員 - 評論家強化學習算法,在大語言模型(LLMs)的強化學習微調階段得到了廣泛應用(歐陽等人,2022年)。具體來說,它通過最大化以下替代目標來優化大語言模型:
J P P O ( θ ) = E [ q ~ P ( Q ) , o ~ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min ? [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 ? ε , 1 + ε ) A t ] ( 1 ) \mathcal{J}_{PPO}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{old }}(O | q)\right] \frac{1}{|o|} \sum_{t = 1}^{|o|} \min \left[\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{\theta_{old }}\left(o_{t} | q, o_{<t}\right)} A_{t}, \text{clip}\left(\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{\theta_{old }}\left(o_{t} | q, o_{<t}\right)}, 1 - \varepsilon, 1 + \varepsilon\right) A_{t}\right] (1) JPPO?(θ)=E[q~P(Q),o~πθold??(O∣q)]∣o∣1?t=1∑∣o∣?min[πθold??(ot?∣q,o<t?)πθ?(ot?∣q,o<t?)?At?,clip(πθold??(ot?∣q,o<t?)πθ?(ot?∣q,o<t?)?,1?ε,1+ε)At?](1)
其中, π θ \pi_{\theta} πθ?和 π θ o l d \pi_{\theta_{old}} πθold??分別是當前策略模型和舊策略模型, q q q和 o o o分別是從問題數據集和舊策略 π θ o l d \pi_{\theta_{old}} πθold??中采樣得到的問題和輸出。 ε \varepsilon ε是PPO中引入的與裁剪相關的超參數,用于穩定訓練。 A t A_{t} At?是優勢值,通過應用廣義優勢估計(GAE)(舒爾曼等人,2015年)計算得出,該估計基于獎勵值 { r ≥ t } \{r_{\geq t}\} {r≥t?}和學習到的價值函數 V ψ V_{\psi} Vψ? 。因此,在PPO中,價值函數需要與策略模型一起訓練。為了減輕獎勵模型的過度優化問題,標準做法是在每個令牌的獎勵中添加來自參考模型的每個令牌的KL散度懲罰項(歐陽等人,2022年),即:
r t = r φ ( q , o ≤ t ) ? β log ? π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) r_{t}=r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{ref}\left(o_{t} | q, o_{<t}\right)} rt?=rφ?(q,o≤t?)?βlogπref?(ot?∣q,o<t?)πθ?(ot?∣q,o<t?)?
其中, r φ r_{\varphi} rφ?是獎勵模型, π r e f \pi_{ref} πref?是參考模型,通常是初始的監督微調(SFT)模型, β \beta β是KL散度懲罰項的系數。
由于PPO中使用的價值函數通常與策略模型規模相當,這會帶來巨大的內存和計算負擔。此外,在強化學習訓練過程中,價值函數在優勢值計算中被用作基線以減少方差。而在大語言模型的環境中,獎勵模型通常只給最后一個令牌分配獎勵分數,這可能會使精確到每個令牌的價值函數的訓練變得復雜。
為了解決這個問題,如圖4所示,我們提出了組相對策略優化(GRPO)。它無需像PPO那樣進行額外的價值函數近似,而是使用針對同一問題產生的多個采樣輸出的平均獎勵作為基線。更具體地說,對于每個問題 q q q,GRPO從舊策略 π θ o l d \pi_{\theta_{old}} πθold??中采樣一組輸出 { o 1 , o 2 , ? , o G } \{o_{1}, o_{2}, \cdots, o_{G}\} {o1?,o2?,?,oG?},然后通過最大化以下目標來優化策略模型:
J G R P O ( θ ) = E [ q ~ P ( Q ) , { o i } i = 1 G ~ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min ? [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 ? ε , 1 + ε ) A ^ i , t ] ? β D K L [ π θ ∣ ∣ π r e f ] } (3) \begin{aligned} \mathcal{J}_{GRPO}(\theta) & =\mathbb{E}\left[q \sim P(Q),\left\{o_{i}\right\}_{i = 1}^{G} \sim \pi_{\theta_{old}}(O | q)\right] \\ & \frac{1}{G} \sum_{i = 1}^{G} \frac{1}{|o_{i}|} \sum_{t = 1}^{|o_{i}|}\left\{\min \left[\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta_{old}}\left(o_{i, t} | q, o_{i,<t}\right)}\hat{A}_{i, t}, \text{clip}\left(\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta_{old}}\left(o_{i, t} | q, o_{i,<t}\right)}, 1 - \varepsilon, 1 + \varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{KL}\left[\pi_{\theta}|| \pi_{ref}\right]\right\} \end{aligned} \tag{3} JGRPO?(θ)?=E[q~P(Q),{oi?}i=1G?~πθold??(O∣q)]G1?i=1∑G?∣oi?∣1?t=1∑∣oi?∣?{min[πθold??(oi,t?∣q,oi,<t?)πθ?(oi,t?∣q,oi,<t?)?A^i,t?,clip(πθold??(oi,t?∣q,oi,<t?)πθ?(oi,t?∣q,oi,<t?)?,1?ε,1+ε)A^i,t?]?βDKL?[πθ?∣∣πref?]}?(3)
其中, ε \varepsilon ε和 β \beta β是超參數, A ^ i , t \hat{A}_{i, t} A^i,t?是僅基于每組內輸出的相對獎勵計算得到的優勢值,將在以下小節中詳細介紹。GRPO利用組相對的方式計算優勢值,這與獎勵模型的比較性質非常契合,因為獎勵模型通常是在同一問題的輸出之間的比較數據集上進行訓練的。還需注意的是,GRPO不是在獎勵中添加KL散度懲罰項,而是通過直接將訓練后的策略與參考策略之間的KL散度添加到損失中來進行正則化,避免了 A ^ i , t \hat{A}_{i, t} A^i,t?計算的復雜化。并且,與公式(2)中使用的KL散度懲罰項不同,我們使用以下無偏估計器(舒爾曼,2020年)來估計KL散度:
D K L [ π θ ∥ π r e f ] = π r e f ( o i , r ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) ? log ? π r e f ( o i , r ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) ? 1 \mathbb{D}_{KL}\left[\pi_{\theta} \| \pi_{ref}\right]=\frac{\pi_{ref}\left(o_{i, r} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-\log\frac{\pi_{ref}\left(o_{i, r} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-1 DKL?[πθ?∥πref?]=πθ?(oi,t?∣q,oi,<t?)πref?(oi,r?∣q,oi,<t?)??logπθ?(oi,t?∣q,oi,<t?)πref?(oi,r?∣q,oi,<t?)??1
該估計值保證為正。
算法流程:

PPO知識點
強化學習全面知識點參考:https://blog.csdn.net/weixin_44986037/article/details/147685319
https://blog.csdn.net/weixin_44986037/category_12959317.html
PPO的網絡模型結構(優勢估計)
若使用在策略與價值函數之間共享參數的神經網絡架構,則需使用一個結合了策略替代項與價值函數誤差項的損失函數。
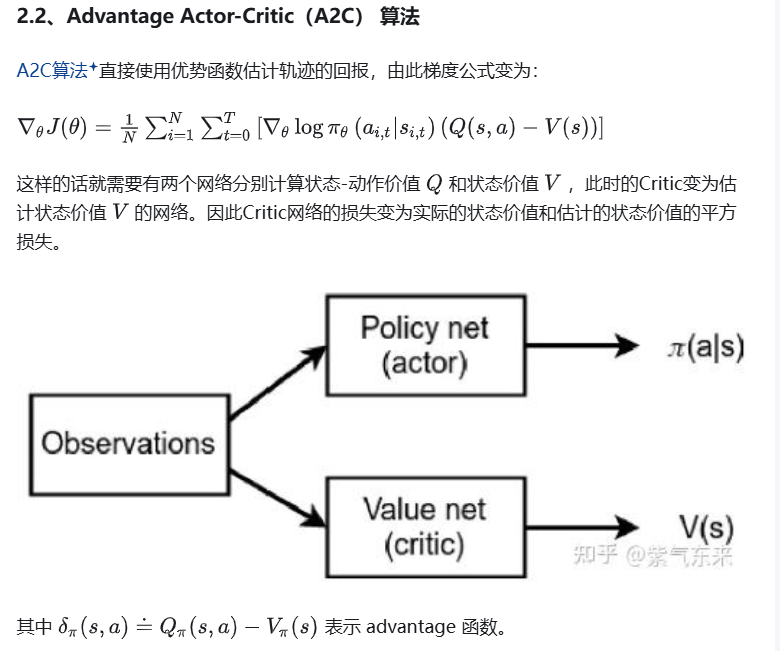
在PPO(Proximal Policy Optimization)算法中,網絡模型的數量為兩個,分別是 Actor網絡 和 Critic網絡。而 GAE(Generalized Advantage Estimation) 是一種用于計算優勢函數(Advantage Function)的方法,并不引入額外的網絡模型。以下是詳細說明:
1. PPO的網絡模型結構
PPO基于 Actor-Critic 架構,包含以下兩個核心網絡:
-
Actor網絡(策略網絡)
? 功能:生成動作概率分布 π ( a ∣ s ) \pi(a|s) π(a∣s),指導智能體行為。
? 結構:多層感知機(MLP)或Transformer,輸出層為動作空間的概率分布。- 輸入:當前狀態 s s s。
- 輸出:動作概率分布(離散動作空間)或動作分布參數(連續動作空間,如高斯分布的均值和方差)。
- 作用:決定智能體在特定狀態下選擇動作的策略(策略優化的核心)。
-
Critic網絡(價值網絡)
? 功能:估計狀態價值函數 V ( s ) V(s) V(s),用于計算優勢函數 A t A_t At?。
? 結構:與Actor類似,但輸出層為標量值(狀態價值)。- 輸入:當前狀態 s s s。
- 輸出:狀態價值 V ( s ) V(s) V(s),即從當前狀態開始預期的累積回報。
- 作用:評估狀態的好壞,輔助Actor網絡更新策略(通過優勢函數的計算)。
-
變體與優化
? 共享參數:部分實現中,Actor和Critic共享底層特征提取層以減少參數量。
? GRPO變體:如DeepSeek提出的GRPO算法,去除Critic網絡,通過組內獎勵歸一化簡化計算,但標準PPO仍保留雙網絡結構。
共享編碼層:
在實際實現中,Actor和Critic網絡的底層特征提取層(如卷積層、Transformer層等)可能共享參數,以減少計算量并提高特征復用效率。例如,在圖像輸入場景中,共享的CNN層可以提取通用的視覺特征,然后分別輸出到Actor和Critic的分支。
PPO基于 Actor-Critic 架構,A2C網絡結構:
參考:https://zhuanlan.zhihu.com/p/450690041
GRPO和PPO網絡結構:
圖 4 |PPO 和我們的 GRPO 示范。GRPO 放棄了價值模型,而是根據組分數估計基線,從而顯著減少了訓練資源。
由于PPO中使用的價值函數通常與策略模型規模相當,這會帶來巨大的內存和計算負擔。此外,在強化學習訓練過程中,價值函數在優勢值計算中被用作基線以減少方差。而在大語言模型的環境中,獎勵模型通常只給最后一個令牌分配獎勵分數,這可能會使精確到每個令牌的價值函數的訓練變得復雜。
為了解決這個問題,如圖4所示,我們提出了組相對策略優化(GRPO)。它無需像PPO那樣進行額外的價值函數近似,而是使用針對同一問題產生的多個采樣輸出的平均獎勵作為基線。
2. GAE(廣義優勢估計)原理
1. 優勢函數的定義
優勢函數 A ( s , a ) A(s, a) A(s,a) 的數學表達式為:
A π ( s , a ) = Q π ( s , a ) ? V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)?Vπ(s)
- Q π ( s , a ) Q^\pi(s, a) Qπ(s,a):動作值函數,表示在狀態 s s s 下執行動作 a a a 后,遵循策略 π \pi π 所能獲得的期望累積獎勵。
- V π ( s ) V^\pi(s) Vπ(s):狀態值函數,表示在狀態 s s s 下,遵循策略 π \pi π 所能獲得的期望累積獎勵(不指定具體動作)。
- 意義:若 A ( s , a ) > 0 A(s, a) > 0 A(s,a)>0,說明執行動作 a a a 相比于當前策略的平均表現更優;若 A ( s , a ) < 0 A(s, a) < 0 A(s,a)<0,則說明該動作不如當前策略的平均水平。
2.GAE(廣義優勢估計)
GAE是PPO中用于估計優勢函數的核心技術,通過平衡偏差與方差優化策略梯度更新。其核心結構包括以下要點:
-
多步優勢加權
GAE通過指數衰減加權不同步長的優勢估計(如TD殘差)構建綜合優勢值,公式為:
A t GAE = ∑ l = 0 ∞ ( γ λ ) l δ t + l A_t^{\text{GAE}} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} AtGAE?=l=0∑∞?(γλ)lδt+l?
其中, δ t = r t + γ V ( s t + 1 ) ? V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt?=rt?+γV(st+1?)?V(st?)為時序差分誤差。 γ \gamma γ(折扣因子)控制長期回報衰減, λ \lambda λ(GAE參數)調節偏差-方差權衡。 -
偏差-方差平衡機制
? λ ≈ 0 \lambda \approx 0 λ≈0:退化為單步TD殘差(高偏差、低方差)? λ ≈ 1 \lambda \approx 1 λ≈1:接近蒙特卡洛估計(低偏差、高方差)
通過調節 λ \lambda λ,GAE在兩者間取得最優折衷。
-
與TD-λ的區別
GAE將TD-λ的資格跡思想引入策略梯度框架,直接服務于優勢函數計算,而非傳統的價值函數更新。
參考:https://blog.csdn.net/animate1/article/details/146100100

2、關鍵技術與方法
-
大規模數學語料構建(DeepSeekMath Corpus):
- 數據來源:從Common Crawl中通過迭代篩選獲取,以OpenWebMath為種子數據,用fastText分類器識別數學網頁,經4輪篩選得到 35.5M網頁、120B tokens,含英/中多語言內容,規模是Minerva所用數學數據的7倍、OpenWebMath的9倍。
- 去污染:過濾含基準測試題的文本(10-gram精確匹配),避免數據泄露。
- 質量驗證:在8個數學基準測試中,基于該語料訓練的模型性能顯著優于MathPile、OpenWebMath等現有語料,證明其高質量和多語言優勢。
-
模型訓練流程:
- 預訓練:
- 基于代碼模型 DeepSeek-Coder-Base-v1.5 7B 初始化,訓練數據含 56%數學語料、20%代碼、10%自然語言 等,總 500B tokens。
- 基準表現:MATH基準 36.2%(超越Minerva 540B的35%),GSM8K 64.2%。
- 監督微調(SFT):
- 使用 776K數學指令數據(鏈思維CoT、程序思維PoT、工具推理),訓練后模型在MATH達 46.8%,超越同規模開源模型。
- 強化學習(RL):Group Relative Policy Optimization (GRPO):
- 創新點:無需獨立價值函數,通過組內樣本平均獎勵估計基線,減少內存消耗,支持過程監督和迭代RL。
- 效果:MATH準確率提升至 51.7%,GSM8K從82.9%提升至88.2%,CMATH從84.6%提升至88.8%,超越7B-70B開源模型及多數閉源模型(如Inflection-2、Gemini Pro)。
- 預訓練:
3、核心實驗結果
-
數學推理性能:
基準測試 DeepSeekMath-Base 7B DeepSeekMath-Instruct 7B DeepSeekMath-RL 7B GPT-4 Gemini Ultra MATH (Top1) 36.2% 46.8% 51.7% 52.9% 53.2% GSM8K (CoT) 64.2% 82.9% 88.2% 92.0% 94.4% CMATH (中文) - 84.6% 88.8% - - - 關鍵優勢:在不依賴外部工具和投票技術的情況下,成為首個在MATH基準突破50%的開源模型,自一致性方法(64樣本)可提升至60.9%。
-
泛化與代碼能力:
- 通用推理:MMLU基準得分 54.9%,BBH 59.5%,均優于同類開源模型。
- 代碼任務:HumanEval(零樣本)和MBPP(少樣本)表現與代碼模型DeepSeek-Coder-Base-v1.5相當,證明代碼預訓練對數學推理的促進作用。
4、結論與未來方向
-
核心貢獻:
- 證明公開網絡數據可構建高質量數學語料,小模型(7B)通過優質數據和高效算法可超越大模型(如Minerva 540B)。
- 提出GRPO算法,在減少訓練資源的同時顯著提升數學推理能力,為RL優化提供統一范式。
- 驗證代碼預訓練對數學推理的積極影響,填補“代碼是否提升推理能力”的研究空白。
-
局限:
- 幾何推理和定理證明能力弱于閉源模型,少樣本學習能力不足(與GPT-4存在差距)。
- arXiv論文數據對數學推理提升無顯著效果,需進一步探索特定任務適配。
-
未來工作:
- 優化數據篩選流程,構建更全面的數學語料(如幾何、定理證明)。
- 探索更高效的RL算法,結合過程監督和迭代優化,提升模型泛化能力。
關鍵問題與答案
1. DeepSeekMath在數據處理上的核心創新點是什么?
答案:通過 迭代篩選+多語言數據 構建高質量數學語料。以OpenWebMath為種子,用fastText分類器從Common Crawl中篩選數學網頁,經4輪迭代獲得120B tokens,涵蓋英/中多語言內容,規模遠超現有數學語料(如OpenWebMath的9倍),且通過嚴格去污染避免基準測試數據泄露。
2. GRPO算法相比傳統PPO有何優勢?
答案:GRPO通過 組內相對獎勵估計基線 替代獨立價值函數,顯著減少訓練資源消耗。無需額外訓練價值模型,直接利用同一問題的多個樣本平均獎勵計算優勢函數,同時支持過程監督(分步獎勵)和迭代RL,在MATH基準上比PPO更高效,準確率提升5.9%(46.8%→51.7%)且內存使用更優。
3. 代碼預訓練對數學推理能力的影響如何?
答案:代碼預訓練能 顯著提升數學推理能力,無論是工具使用(如Python編程解題)還是純文本推理。實驗表明,基于代碼模型初始化的DeepSeekMath-Base在GSM8K+Python任務中得分66.9%,遠超非代碼模型(如Mistral 7B的48.5%),且代碼與數學混合訓練可緩解災難性遺忘,證明代碼中的邏輯結構和形式化推理對數學任務有遷移優勢。
)



)
機制支持 多種連接方式(ConnectionType))
代碼詳解)

)

的調用)
——添加記憶)






)
