目錄
一、導包
二、數據準備
1.數據集
2. 標準化轉換(Normalize)
3.設置dataloader
三、定義模型
四、可視化計算圖(不重要)
五、評估函數
六、Tensorboard
一、導包
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
from tqdm.auto import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as Fprint(sys.version_info)
for module in mpl, np, pd, sklearn, torch:print(module.__name__, module.__version__)device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print(device)seed = 42-
%matplotlib inline:Jupyter Notebook魔法命令,使圖表直接顯示在單元格下方 -
device?配置:優先使用CUDA GPU加速計算,如果沒有則使用CPU
二、數據準備
# 導入數據集相關模塊
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch.utils.data import random_split# 加載FashionMNIST數據集
# 訓練集:自動下載并轉換為Tensor格式
train_ds = datasets.FashionMNIST(root="data", # 數據集存儲路徑train=True, # 加載訓練集download=True, # 如果本地不存在則下載transform=ToTensor()# 將PIL圖像轉換為[0,1]范圍的Tensor
)# 測試集:同樣進行格式轉換
test_ds = datasets.FashionMNIST(root="data",train=False, # 加載測試集download=True,transform=ToTensor()
)# 劃分訓練集和驗證集(原始數據沒有提供驗證集)
# 使用random_split按55000:5000比例劃分
# 設置隨機種子保證可重復性
train_ds, val_ds = random_split(train_ds, [55000, 5000],generator=torch.Generator().manual_seed(seed) # 固定隨機種子
)#%% 數據預處理模塊
from torchvision.transforms import Normalize# 計算數據集的均值和標準差(用于標準化)
def cal_mean_std(ds):mean = 0.std = 0.for img, _ in ds: # 遍歷數據集中的每個圖像# 計算每個通道的均值和標準差(dim=(1,2)表示在H和W維度上計算)mean += img.mean(dim=(1, 2)) # 形狀為 [C]std += img.std(dim=(1, 2)) # C為通道數(這里為1)mean /= len(ds) # 求整個數據集的平均std /= len(ds)return mean, std# 根據計算結果創建標準化轉換
# 實際計算值約為 mean=0.2856,std=0.3202
transforms = nn.Sequential(Normalize([0.2856], [0.3202]) # 單通道標準化
)#%% 數據檢查
img, label = train_ds[0] # 獲取第一個訓練樣本
img.shape, label # 輸出形狀(通道×高×寬)和標簽#%% 創建數據加載器
from torch.utils.data.dataloader import DataLoaderbatch_size = 32 # 每批加載的樣本數# 訓練集加載器
train_loader = DataLoader(train_ds,batch_size=batch_size,shuffle=True, # 每個epoch打亂順序num_workers=4 # 使用4個子進程加載數據
)# 驗證集加載器
val_loader = DataLoader(val_ds,batch_size=batch_size,shuffle=False, # 不需要打亂順序num_workers=4
)# 測試集加載器
test_loader = DataLoader(test_ds,batch_size=batch_size,shuffle=False, # 保持原始順序num_workers=4
)?tips:
1.數據集
datasets.FasionMNIST是pytorch提供的標準數據集類
-
類別:10 類(T恤、褲子、套頭衫、連衣裙、外套、涼鞋、襯衫、運動鞋、包、靴子)。
-
圖像大小:28×28 像素,單通道灰度圖。
-
用途:替代原始 MNIST,作為更復雜的圖像分類基準數據集。
2. 標準化轉換(Normalize)
在cal_mean_std中,先遍歷數據集中的每個圖像和標簽(忽略),計算每個通道的均值和標準差,然后求整個數據集的平均值和標準差,為后序標準化提供參數。img.mean(dim=(1,2))是在圖像的高度和寬度兩個維度上求均值,保留通道維度。transforms使用nn.Sequential將多個數據轉換操作按順序組合起來,對圖像數據進行標準化,nn.Sequential是pytorch提供的容器,用于按順序執行多個操作,Normalize是torchvision.transforms中的一個標準化操作,功能是對輸入數據的每個通道進行均值平移和標準差縮放,對圖片的每個像素值進行以下變換:
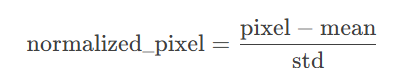
代碼中的圖片沒有使用這個標準化,所以想使用的話可以
transforms = Compose([ToTensor(), # 1. 轉Tensor并縮放到[0,1]Normalize([0.2856], [0.3202]) # 2. 標準化
])然后在加載數據那里把transform=后面改成transforms。
修改前:
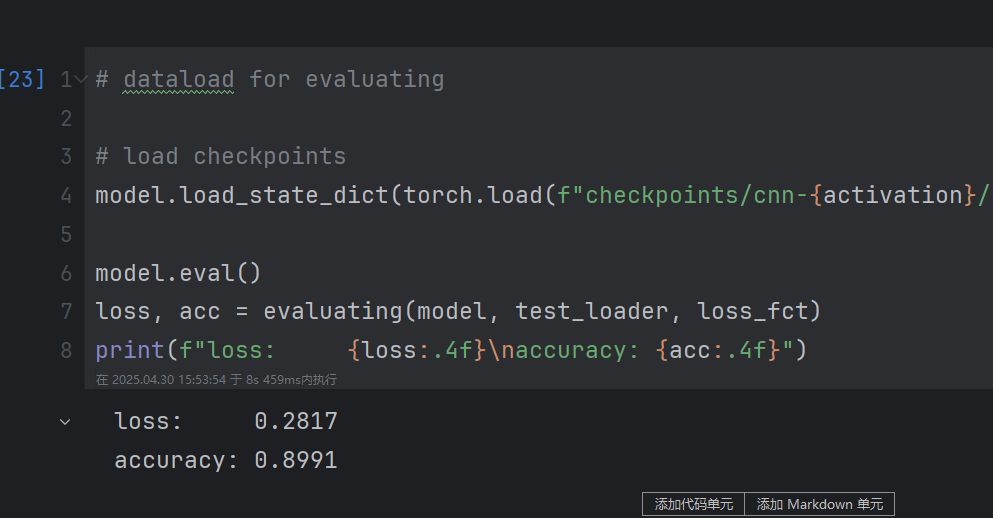
修改后:
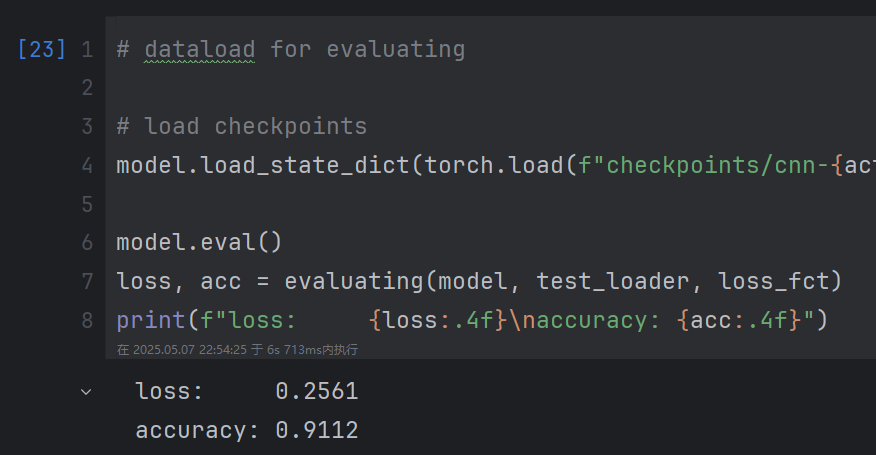
圖像數據標準化后結果更優秀。
3.設置dataloader
將batch_size設置為32,只打亂訓練集,驗證集和測試集不需要打亂,num_workers=4使用4個子進程并行加載數據(和CPU核心數相關)。
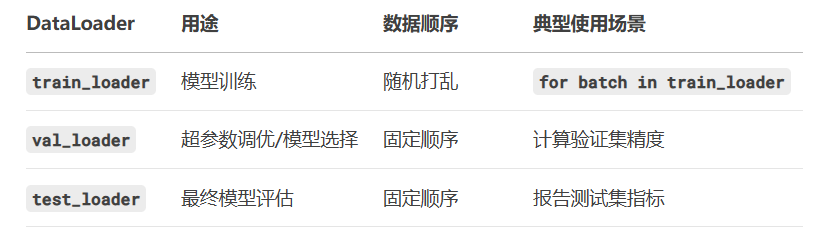
?Dataloader可以自動將數據集分成多個批次,打亂數據,設置多進程加速,提供標準化接口,都可以for batch in dataloader: 。
三、定義模型
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass CNN(nn.Module):"""一個用于圖像分類的卷積神經網絡(CNN)模型"""def __init__(self, activation="relu"):"""初始化CNN模型結構Args:activation: 激活函數類型,可選"relu"或"selu""""super(CNN, self).__init__()# 設置激活函數self.activation = F.relu if activation == "relu" else F.selu# 卷積層定義# 輸入形狀: (batch_size, 1, 28, 28)self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1) # 保持空間維度不變self.conv2 = nn.Conv2d(32, 32, kernel_size=3, padding=1) # 雙卷積結構增強特征提取# 最大池化層(下采樣)self.pool = nn.MaxPool2d(2, 2) # 將特征圖尺寸減半# 后續卷積層(逐步增加通道數)self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.conv4 = nn.Conv2d(64, 64, kernel_size=3, padding=1)self.conv5 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.conv6 = nn.Conv2d(128, 128, kernel_size=3, padding=1)# 展平層(將多維特征圖轉換為一維向量)self.flatten = nn.Flatten()# 全連接層# 輸入尺寸計算:經過3次池化后是3x3,通道數128 → 128*3*3=1152self.fc1 = nn.Linear(128 * 3 * 3, 128) # 特征壓縮self.fc2 = nn.Linear(128, 10) # 輸出10類(FashionMNIST有10個類別)# 初始化權重self.init_weights()def init_weights(self):"""使用Xavier均勻分布初始化權重,偏置初始化為0"""for m in self.modules():if isinstance(m, (nn.Linear, nn.Conv2d)): nn.init.xavier_uniform_(m.weight) # 保持前向/反向傳播的方差穩定nn.init.zeros_(m.bias) # 偏置初始為0def forward(self, x):"""前向傳播過程"""act = self.activation# 第一個卷積塊(兩次卷積+激活+池化)x = self.pool(act(self.conv2(act(self.conv1(x))))) # [32,1,28,28]→[32,32,14,14]# 第二個卷積塊x = self.pool(act(self.conv4(act(self.conv3(x))))) # [32,32,14,14]→[32,64,7,7]# 第三個卷積塊x = self.pool(act(self.conv6(act(self.conv5(x))))) # [32,64,7,7]→[32,128,3,3]# 分類頭x = self.flatten(x) # [32,128,3,3]→[32,1152]x = act(self.fc1(x)) # [32,1152]→[32,128]x = self.fc2(x) # [32,128]→[32,10]return x # 輸出10個類別的logits# 打印模型各層參數量
for idx, (key, value) in enumerate(CNN().named_parameters()):print(f"{key:<30} paramerters num: {np.prod(value.shape)}")定義模型在前幾篇文章已有詳細描述,這里補充一些內容。
此文的模型結構包含3個卷積塊,每個卷積塊包含兩個卷積層,3個最大池化層,2個全連接層。
這里詳細介紹一下pytorch構建新模型的步驟:
1.繼承nn.Module類,所有pytorch模型都必須繼承torch.nn.Module類
基礎代碼:
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定義模型組件調用父類的構造函數,確保底層機制正確初始化。
2.在__init__方法中定義所有層和組件、實現forward方法,和此實戰代碼類似。
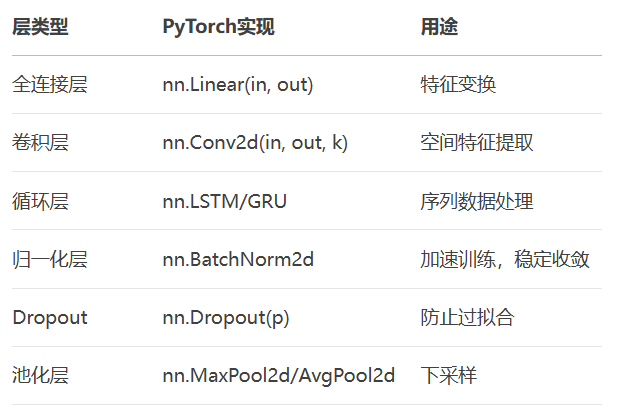
這里介紹一下常用的網絡層類型:
四、可視化計算圖(不重要)
需要下載包,如果遇到下載困難也許可以看這篇文章:關于安裝graphviz庫遇到ExecutableNotFound: failed to execute WindowsPath(‘dot‘)……解決方案-CSDN博客
from torchviz import make_dot# Assuming your model is already defined and named 'model'
# Construct a dummy input
dummy_input = torch.randn(1, 1, 28, 28) # Replace with your input shape# Forward pass to generate the computation graph
output = model(dummy_input)# Visualize the model architecture
dot = make_dot(output, params=dict(model.named_parameters()))
dot.render("model_CNN", format="png")使用之后的效果像這樣?
五、評估函數
接下來就是訓練的部分了,第一個是構造評估函數:
from sklearn.metrics import accuracy_score # 導入準確率計算函數@torch.no_grad() # 禁用梯度計算裝飾器,減少內存消耗并加速計算
def evaluating(model, dataloader, loss_fct):"""模型評估函數參數:model: 待評估的PyTorch模型dataloader: 數據加載器,提供驗證/測試數據集loss_fct: 損失函數返回:tuple: (平均損失, 準確率)"""# 初始化存儲列表loss_list = [] # 存儲每個batch的損失值pred_list = [] # 存儲所有預測結果label_list = [] # 存儲所有真實標簽# 遍歷數據加載器中的每個batchfor datas, labels in dataloader:# 將數據轉移到指定設備(如GPU)datas = datas.to(device)labels = labels.to(device)# 前向計算(預測)logits = model(datas) # 模型輸出原始預測值(未歸一化)loss = loss_fct(logits, labels) # 計算當前batch的損失值loss_list.append(loss.item()) # 將損失值(標量)添加到列表# 獲取預測類別(將logits轉換為類別索引)preds = logits.argmax(axis=-1) # 取每行最大值的索引作為預測類別# 將結果轉移到CPU并轉換為Python列表pred_list.extend(preds.cpu().numpy().tolist()) # 添加當前batch的預測結果label_list.extend(labels.cpu().numpy().tolist()) # 添加當前batch的真實標簽# 計算整體準確率(所有batch的預測與真實標簽比較)acc = accuracy_score(label_list, pred_list) # 返回平均損失和準確率return np.mean(loss_list), acc 這里@torch.no_grad()是pytorch中的一個關鍵機制,用于在模型推理(評估)階段關閉自動梯度計算功能,因為梯度自動計算只需要在模型訓練里存在。
六、Tensorboard
```shell
tensorboard \--logdir=runs \ # log 存放路徑--host 0.0.0.0 \ # ip--port 8848 # 端口from torch.utils.tensorboard import SummaryWriterclass TensorBoardCallback:def __init__(self, log_dir, flush_secs=10):"""Args:log_dir (str): dir to write log.flush_secs (int, optional): write to dsk each flush_secs seconds. Defaults to 10."""self.writer = SummaryWriter(log_dir=log_dir, flush_secs=flush_secs)def draw_model(self, model, input_shape):self.writer.add_graph(model, input_to_model=torch.randn(input_shape))def add_loss_scalars(self, step, loss, val_loss):self.writer.add_scalars(main_tag="training/loss", tag_scalar_dict={"loss": loss, "val_loss": val_loss},global_step=step,)def add_acc_scalars(self, step, acc, val_acc):self.writer.add_scalars(main_tag="training/accuracy",tag_scalar_dict={"accuracy": acc, "val_accuracy": val_acc},global_step=step,)def add_lr_scalars(self, step, learning_rate):self.writer.add_scalars(main_tag="training/learning_rate",tag_scalar_dict={"learning_rate": learning_rate},global_step=step,)def __call__(self, step, **kwargs):# add lossloss = kwargs.pop("loss", None)val_loss = kwargs.pop("val_loss", None)if loss is not None and val_loss is not None:self.add_loss_scalars(step, loss, val_loss)# add accacc = kwargs.pop("acc", None)val_acc = kwargs.pop("val_acc", None)if acc is not None and val_acc is not None:self.add_acc_scalars(step, acc, val_acc)# add lrlearning_rate = kwargs.pop("lr", None)if learning_rate is not None:self.add_lr_scalars(step, learning_rate)from torch.utils.tensorboard import SummaryWriterclass TensorBoardCallback:def __init__(self, log_dir, flush_secs=10):"""Args:log_dir (str): dir to write log.flush_secs (int, optional): write to dsk each flush_secs seconds. Defaults to 10."""self.writer = SummaryWriter(log_dir=log_dir, flush_secs=flush_secs)def draw_model(self, model, input_shape):self.writer.add_graph(model, input_to_model=torch.randn(input_shape))def add_loss_scalars(self, step, loss, val_loss):self.writer.add_scalars(main_tag="training/loss", tag_scalar_dict={"loss": loss, "val_loss": val_loss},global_step=step,)def add_acc_scalars(self, step, acc, val_acc):self.writer.add_scalars(main_tag="training/accuracy",tag_scalar_dict={"accuracy": acc, "val_accuracy": val_acc},global_step=step,)def add_lr_scalars(self, step, learning_rate):self.writer.add_scalars(main_tag="training/learning_rate",tag_scalar_dict={"learning_rate": learning_rate},global_step=step,)def __call__(self, step, **kwargs):# add lossloss = kwargs.pop("loss", None)val_loss = kwargs.pop("val_loss", None)if loss is not None and val_loss is not None:self.add_loss_scalars(step, loss, val_loss)# add accacc = kwargs.pop("acc", None)val_acc = kwargs.pop("val_acc", None)if acc is not None and val_acc is not None:self.add_acc_scalars(step, acc, val_acc)# add lrlearning_rate = kwargs.pop("lr", None)if learning_rate is not None:self.add_lr_scalars(step, learning_rate)后續代碼與前幾篇文章代碼差不多,不過多贅述。

)

的調用)
——添加記憶)






)





三者區別▲)

