《LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking》2025年1月發表,來自浙江大學、上海AI實驗室、慕尼黑工大、同濟大學和中科大的論文。
盡管自動駕駛技術取得了顯著進步,但由于推理能力有限,數據驅動的方法仍然難以應對復雜的場景。與此同時,隨著視覺語言模型的普及,知識驅動的自動駕駛系統也得到了長足的發展。本文提出了LeapVAD,這是一種基于認知感知和雙過程思維的新方法。此方法實現了一種人類注意力機制,以識別和關注影響駕駛決策的關鍵交通因素。通過包括外觀、運動模式和相關風險在內的綜合屬性來表征這些對象,LeapVAD實現了更有效的環境表示并簡化了決策過程。此外,LeapVAD整合了一個創新的雙過程決策模塊,模擬了人類駕駛學習過程。該系統由一個通過邏輯推理積累駕駛經驗的分析過程(系統II)和一個通過微調和少量學習完善這些知識的啟發式過程(系統I)組成。LeapVAD還包括反射機制和不斷增長的記憶庫,使其能夠從過去的錯誤中學習,并在閉環環境中不斷提高其性能。為了提高效率,我們開發了一個場景編碼器網絡,該網絡生成緊湊的場景表示,用于快速檢索相關的駕駛體驗。對CARLA和DriveArena這兩款領先的自動駕駛模擬器進行的廣泛評估表明,盡管訓練數據有限,但LeapVAD的性能優于僅使用攝像頭的方法。全面的消融研究進一步強調了其在持續學習和領域適應方面的有效性。
1. 研究背景與動機
-
問題定義:現有自動駕駛技術中,數據驅動方法依賴大量標注數據且缺乏復雜場景下的推理能力,而知識驅動方法(如基于視覺語言模型VLM)雖具備一定推理能力,但評估方法多為開環測試,無法反映動態交互環境。
-
核心挑戰:如何構建一個能夠持續學習、模仿人類認知過程的自動駕駛系統,以應對復雜場景和長尾問題。
-
創新點:提出LeapVAD框架,融合認知感知(人類注意力機制)與雙過程思維(分析過程System-II + 啟發式過程System-I),結合記憶庫和反射機制,實現閉環環境下的持續優化。
2. 方法論
框架組成
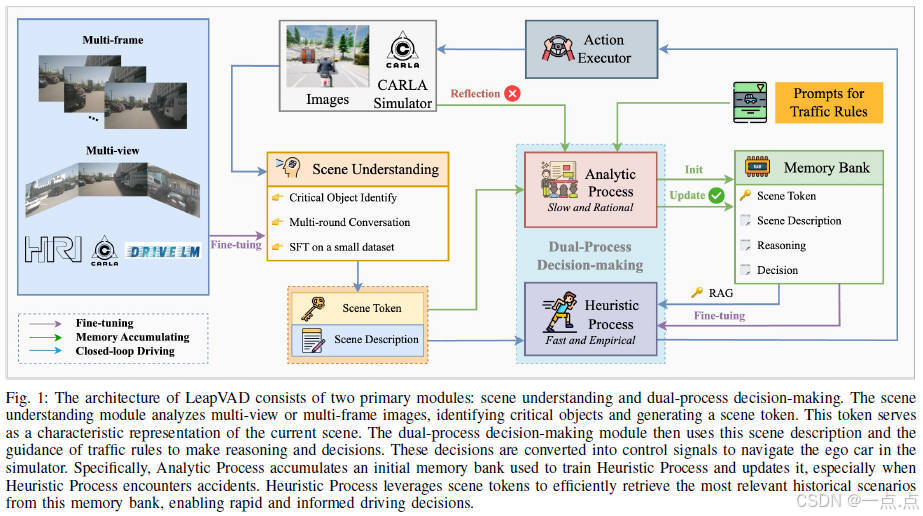
-
場景理解模塊:
-
視覺語言模型(VLM):通過監督微調(SFT)生成關鍵交通對象的語義、空間、運動屬性及行為推理描述(如車輛類別、位置、速度、風險等級)。
-
多幀輸入:支持多視角和多幀數據,捕捉動態屬性(如速度趨勢、運動方向)。
-
數據結構:采用“總結-細化”格式,提升場景描述的全面性。
-
-
場景編碼器:
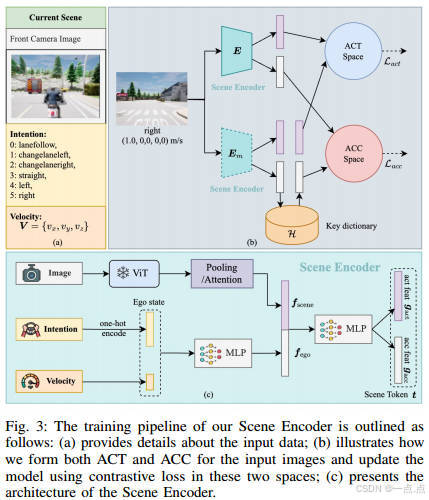
-
目標:生成緊湊的場景標記(Scene Token),用于快速檢索相似歷史場景。
-
對比學習框架:在動作空間(ACT,轉向控制)和加速度空間(ACC,制動控制)中,通過對比學習優化特征表示。
-
動量編碼器:通過動量更新策略(MoCo風格)維護歷史特征字典,支持大規模負樣本對比。
-
-
雙過程決策模塊:
-
分析過程(System-II):
-
基于LLM的邏輯推理,生成高質量駕駛決策(如變道、減速)。
-
通過閉環實驗積累經驗至記憶庫,支持知識遷移。
-
反射機制:事故發生時,分析歷史幀數據(描述、決策、推理),識別錯誤原因并生成修正策略,更新記憶庫。
-
-
啟發式過程(System-I):
-
基于輕量級LLM(如Qwen-1.8B),利用記憶庫中的經驗進行快速決策。
-
少樣本提示(Few-shot Prompting):通過檢索相似場景的樣本,減少幻覺(Hallucination)并提升泛化能力。
-
-
-
控制器:
-
元動作生成:輸出高層指令(如“加速AC”“左變道LCL”)。
-
PID控制:通過軌跡規劃和跟蹤,將元動作轉化為底層控制信號(轉向、油門、剎車)。
-
3. 實驗與驗證
實驗平臺
-
CARLA:Town05短途與長途基準測試,評估駕駛分數(DS)、路線完成率(RC)、違規分數(IS)。
-
DriveArena:高保真仿真環境,驗證跨域泛化能力。
主要結果
-
CARLA性能:
-
Town05短途:LeapVAD以僅1/73的數據量(41K vs. 3M)達到接近SOTA(94.95 vs. 88.19 DS),較前作LeapAD提升5.3%。
-
Town05長途:DS提升42.6%,顯著優于純視覺方法。
-
-
DriveArena性能:
-
記憶庫(CARLA訓練)跨域遷移有效,ADS(駕駛分數)達45.52%,優于端到端方法(如VAD、UniAD)。
-
消融實驗
-
VLM選擇:Qwen-VL-7B在場景理解和推理能力上優于LLaVA和InternVL2。
-
場景標記設計:“池化+狀態”方案(Precision@1達87.52%)優于文本嵌入(OpenAI Embedding)。
-
記憶庫容量:容量越大(如4096),性能提升越顯著。
-
少樣本提示:3-shot設置效果最佳,較零樣本提升顯著。
4. 創新與貢獻
-
雙過程思維:模仿人類駕駛學習過程(新手→專家),結合邏輯推理(System-II)與快速反應(System-I)。
-
高效場景表示:通過對比學習生成場景標記,提升檢索效率與決策一致性。
-
持續學習機制:反射機制與動態記憶庫實現閉環優化,支持跨域知識遷移(如CARLA→DriveArena)。
-
數據效率:僅需少量標注數據(41K)即可達到SOTA性能,顯著降低數據依賴。
5. 局限與未來方向
-
實時性:分析過程(System-II)依賴大模型推理,可能影響實時性,需進一步優化輕量化。
-
復雜場景泛化:極端天氣、密集交通等場景的泛化能力需驗證。
-
硬件部署:當前實驗基于仿真環境,實際車載部署的算力與延遲問題待解決。
6. 結論
LeapVAD通過融合認知感知與雙過程思維,構建了一個高效、可解釋的自動駕駛框架。其核心創新在于模仿人類駕駛的持續學習機制,結合場景編碼與記憶庫技術,顯著提升了復雜場景下的決策魯棒性和數據效率。實驗證明該方法在仿真環境中具有優越性能,為知識驅動自動駕駛提供了新的研究方向。
如果此文章對您有所幫助,那就請點個贊吧,收藏+關注 那就更棒啦,十分感謝!!!?




DictServer(中譯英字典)| ChatServer(簡單聊天室))










)



