1.為什么是微調 ?
微調LLM(Fine-tuning Large Language Models) 是指基于預訓練好的大型語言模型(如GPT、LLaMA、PaLM等),通過特定領域或任務的數據進一步訓練,使其適應具體需求的過程。它是將通用語言模型轉化為專用模型的核心方法。
2.微調適用于哪些場景?
1)領域專業化
- 醫療:微調后的模型可理解醫學論文、生成診斷建議。
- 法律:準確引用法律條文,避免生成錯誤解釋。
2)任務適配
- 文本分類:將生成模型轉為情感分析工具(輸出正面/負面標簽)。
- 代碼生成:訓練模型遵循企業內部的編程規范和API調用規則。
3)風格控制
- 模仿特定作者的寫作風格(如魯迅的文風、科技博客的簡潔性)。
- 生成符合品牌調性的營銷文案(如正式、幽默、口語化)。
4)安全對齊
- 過濾有害內容,避免模型生成暴力、偏見或虛假信息。
- 確保輸出符合倫理規范(如醫療建議需標注“非專業診斷”)。
3.有哪些微調的方法 ?
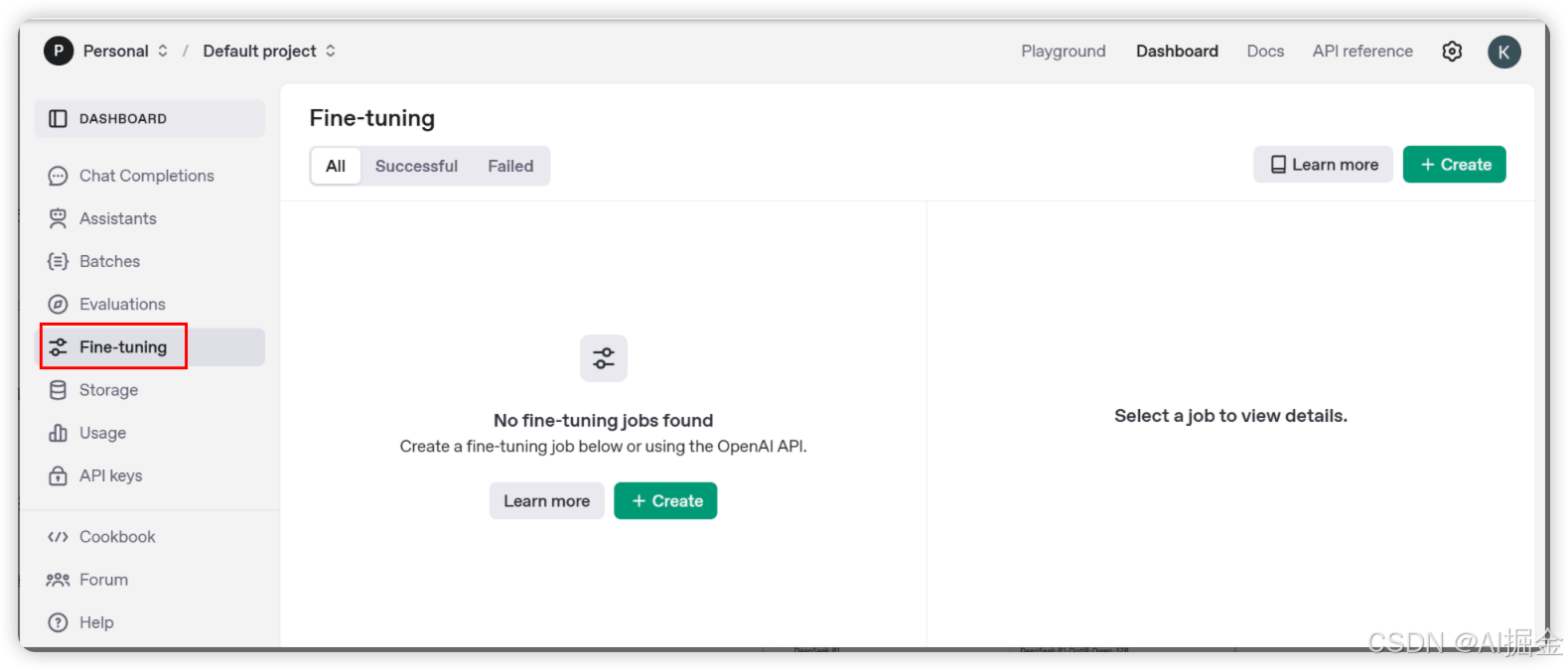
1)是模型供應商提供了商業模型的在線微調能力,比如 OpenAI 的 GPT 3.5 等模型就支持在線微調。這種模式是基于商業大模型的微調,因此微調后模型還是商業大模型,我們去使用時依然要按 token 付費。
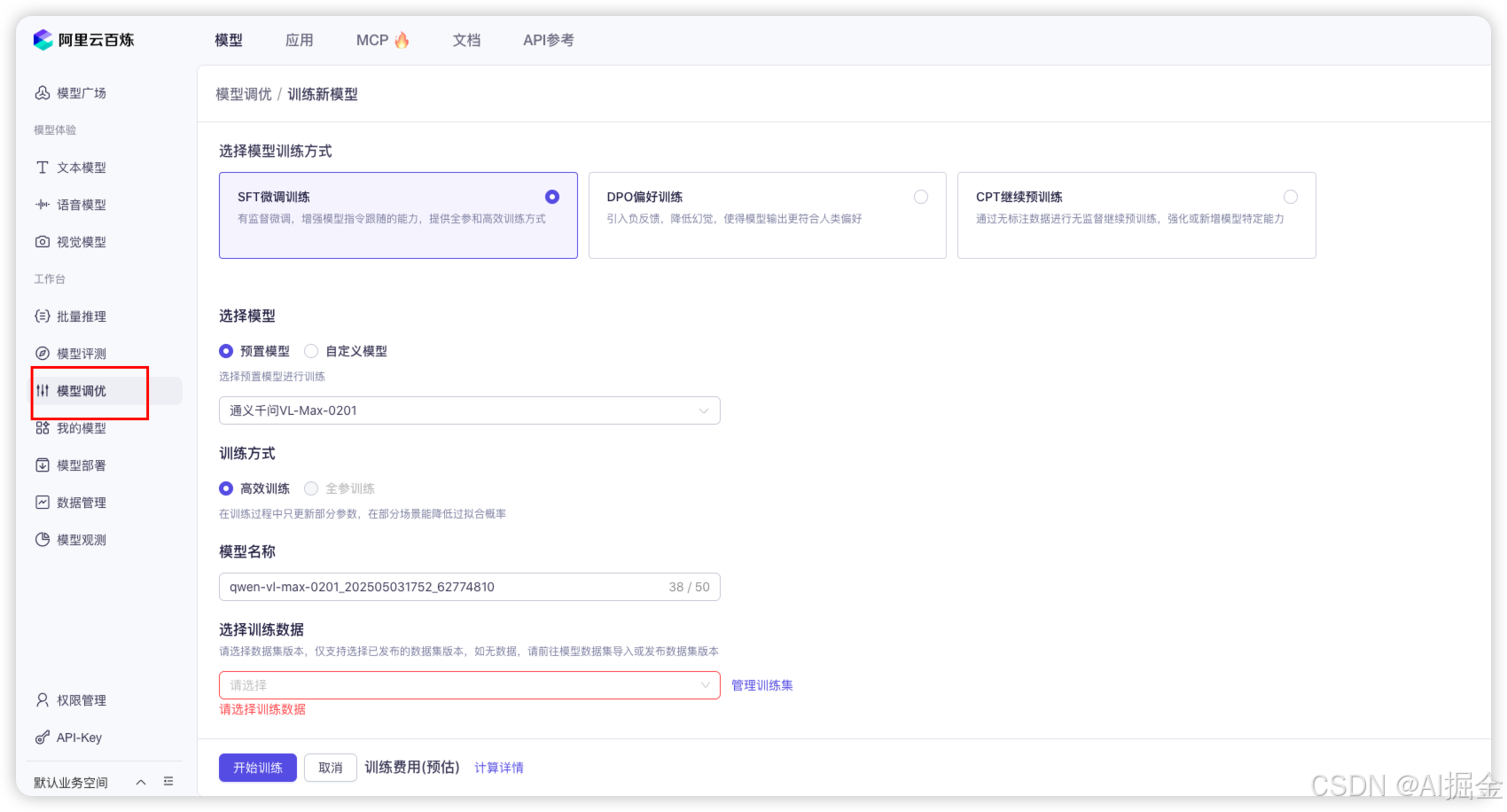
2) 云廠商做的一些模型在線部署、微調平臺。比如阿里云的"阿里云百煉",就具備模型的部署和訓練功能。這種模式我們只需要租用云廠商的 GPU 算力即可。這些模型部署訓練功能都是云廠商為了賣卡或大模型 而推出的增值服務。
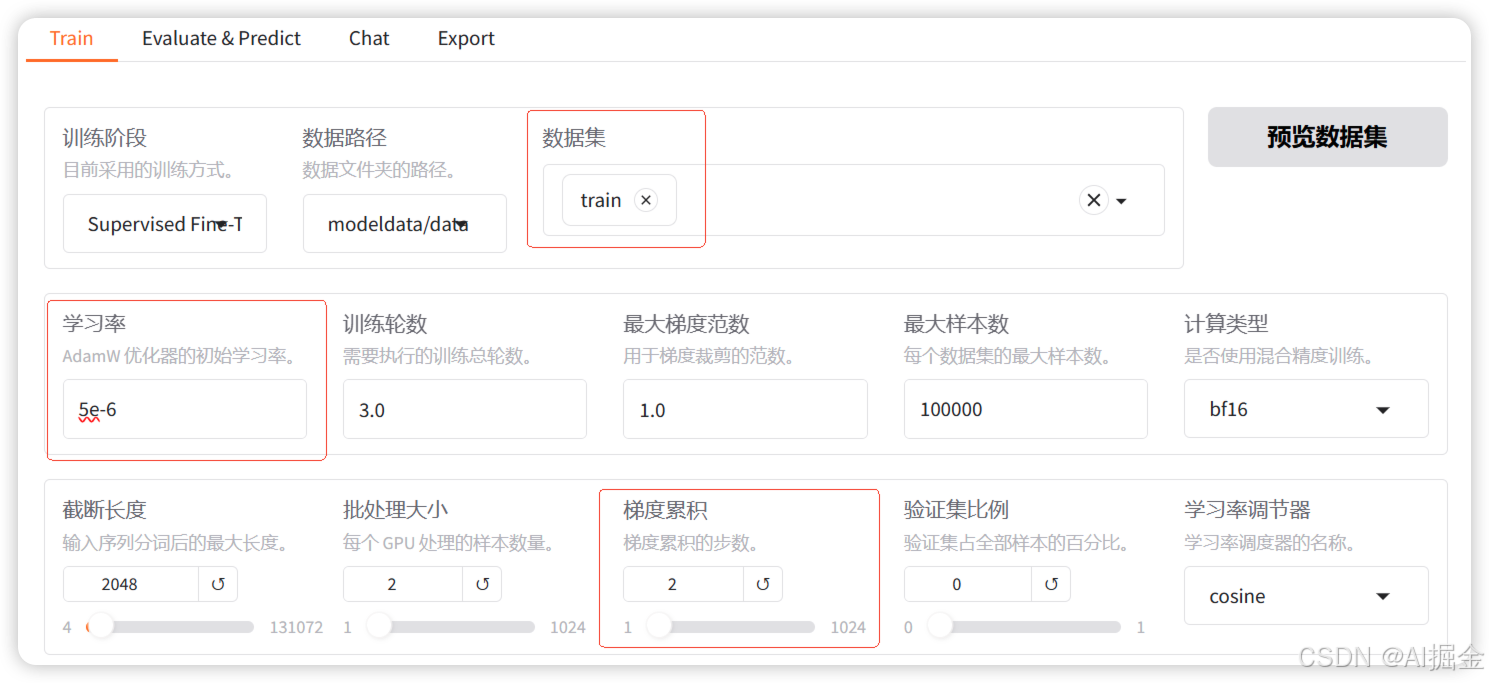
3)如果你或你的公司手里有足夠的卡,希望完全本地私有化部署和微調,此時就可以使用一些開源方案,部署一個微調平臺來進行模型微調。
比如:目前開源社區非常火的一站式微調和評估平臺–LLama-factory。
LLama-factory 是一款整合了主流的各種高效訓練微調技術,適配市場主流開源模型,而形成的一個功能豐富、適配性好的訓練框架。LLama-factory 提供了多個高層次抽象的調用接口,包含多階段訓練、推理測試、benchmark 評測、API Server 等,使開發者開箱即用。同時提供了網頁版工作臺,方便初學者迅速上手操作,開發出自己的第一個模型。
4.微調vs預訓練
- 預訓練(Pre-training)
LLM 最初通過海量通用文本(如書籍、網頁)進行訓練,學習語言的通用規律(語法、語義、常識)。
目標:掌握“通用語言能力”,例如續寫文本、回答問題。
- 微調(Fine-tuning)
在預訓練模型的基礎上,用特定數據(如醫療報告、法律文書、客服對話)進一步訓練,調整模型參數。
目標:讓模型從“通才”變為“專才”,適配特定任務或領域。
5. 微調vs其它技術










)








:pinctrl 子系統詳解與實戰分析)
)