文章目錄
- 1、隨機快速排序
- 1.1 什么是隨機快排
- 1.2 隨機快排的好處
- 2、隨機選擇算法
前言: 快速排序就是每次劃分前,通過一種方法將一個基準值的位置確定好,再進入不同的部分重復相同的工作以此確定好每個值的位置以達到有序。如果你之前并不了解快速排序請看快速排序。
1、隨機快速排序
1.1 什么是隨機快排
隨機快速排序顧名思義也是一種快速排序,它和普通的快排不同在有以下的優化。
- 通過隨機選取一個基準值,保證應對快排在有序情況下的最壞效率問題。
- 通過三路劃分的方式,假設基準值為x,每一趟劃分都會確保區間為<x ==x >x。
隨機快排的思路:
- 通過數組下標控制范圍,在這個范圍內通過隨機函數選擇一個隨機數。
- 選好隨機數后以此數為基準值,通過三路劃分的方式劃分區間為<x ==x >x。
- 通過下標控制邊界,通過函數遞歸重復1和2。
?
第一步:選隨機數。 由于采用的是C++語言,用的是rand函數,下面先看用法再看快排相關的。
#include <ctime>
#include <cstdlib>
srand(time(0)); //確保每次運行rand的隨機序列不同
int num = rand(); // 會返回0到32767之間的整數
//如果生成[a,b)區間的話,而[a,b]就在后面加1
int num = a + rand() % (b-a) // a + rand() % (b-a+1)////那么快排中選取一個隨機數就是(當然這里也可以用下標)
int x = nums[l + rand() % (r - l + 1)];
?
第二步:確定好基準值后進行以基準值分割區域
int first = 0, last = 0;
void partition(vector<int>& nums, int l, int r, int x){first = l, last = r;int i = l;while (i <= last){if (nums[i] < x) swap(nums[i++], nums[first++]);else if (nums[i] > x) swap(nums[i], nums[last--]);else i++;}}
選定全局first(下圖F)和last(下圖L)作為等于x區域的左邊界和右邊界,用i來遍歷數組,x代表所選隨機數。其中F左邊的區域代表小于x的,L右邊的區域代表大于x的。F和i開始一起。
- 當nums[i] < x時,交換i和F的數,并且i和F向右走,使得F左邊都是小于x的數。
- 當nums[i] > x時,交換i和L的數,這時只有L向左走(因為交換后i位置可能還是大于x的數),保證L右邊都是大于x的數。
- 當nums[i] == x時,i直接向右走,此時F左邊依舊是小于x的數,L右邊依舊是大于x的數。
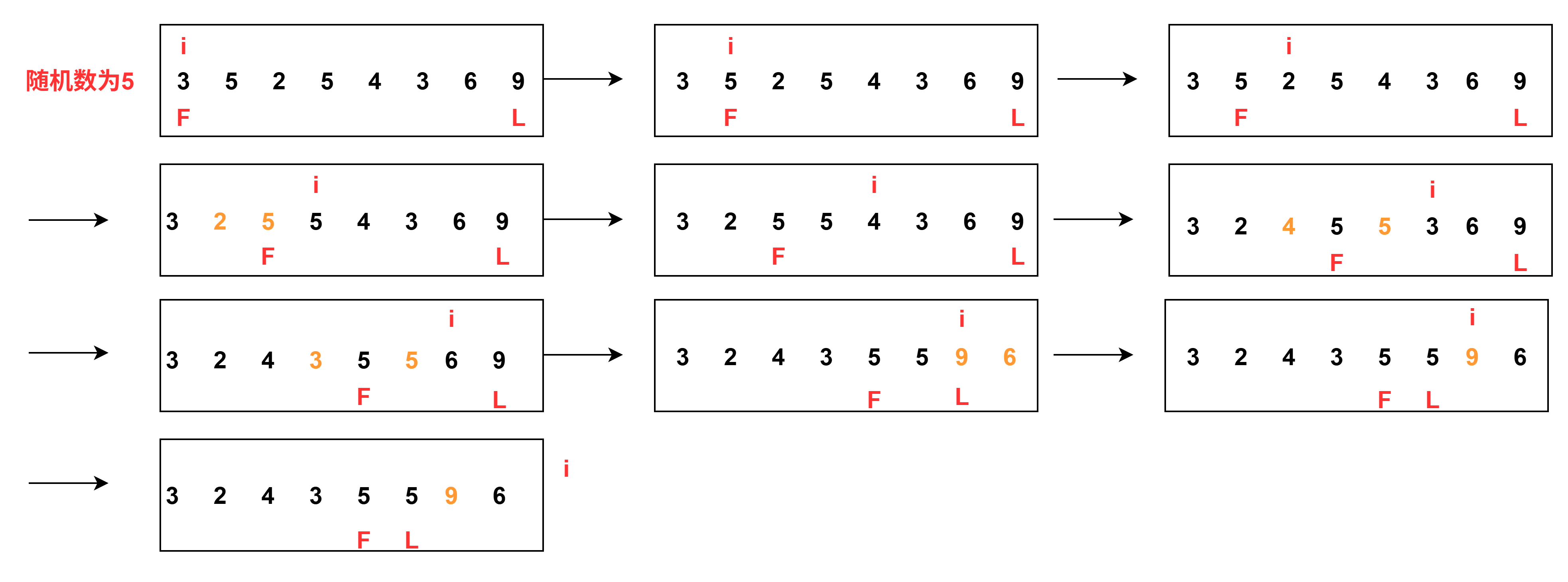
?
第三步:通過下標控制邊界,通過函數遞歸重復1和2
void RandomQuickSort(vector<int>& nums, int l, int r)
{if (l >= r) return;int x = nums[l + rand() % (r - l + 1)];partition(nums, l, r, x);RandomQuickSort(nums, l, first - 1);RandomQuickSort(nums, last + 1, r);
}
下面通過一道題進行隨機快排的測試。
排序數組

完整代碼
class Solution {
public:int first = 0, last = 0;void partition(vector<int>& nums, int l, int r, int x){first = l, last = r;int i = l;while (i <= last){if (nums[i] < x) swap(nums[i++], nums[first++]);else if (nums[i] > x) swap(nums[i], nums[last--]);else i++;}}void RandomQuickSort(vector<int>& nums, int l, int r){if (l >= r) return;int x = nums[l + rand() % (r - l + 1)];partition(nums, l, r, x);RandomQuickSort(nums, l, first - 1);RandomQuickSort(nums, last + 1, r);}vector<int> sortArray(vector<int>& nums) {RandomQuickSort(nums, 0, nums.size() - 1);return nums;}
};
隨機快排的時間復雜度為O(N*LogN),空間復雜度為O(LogN)。
?
1.2 隨機快排的好處
接下來我們看看為什么隨機快排需要挑選隨機數以及三路劃分。
我們先來看看什么是快排效率最差的情況。
- 最差情況:當對一個有序數組進行快排,比如[1 2 3 4 5 6 7],如果依據上面partition的做法,普通的按照最后一個數為基準值,那么每次都得拿最后一個數和前面每一個數進行比較(比如第一趟7和前面每一個數都比了一遍),那么時間復雜度就是O(N^2)。如果通過隨機選取一個基準值,那么就可以極大概率降低每次都抽到最后一個數的情況。
為什么要用三路劃分?
- 如果給定一組數3 3 3 4 3 3 3,如果按照之前快排的挖坑法,第一次排序后還是3 3 3 4 3 3 3,因為其采用的是劃分為>=x 和 <=x的區域,而通過三路劃分則可以劃分為3 3 3 3 3 3 4。(這兩個方法都可以實現有序,只是在一些場景下我們要求嚴格的<x =x >x進行劃分,通過三路劃分就更好。比如下面隨機選擇算法的這道題)
?
2、隨機選擇算法
隨機選擇算法主要用于在無序數組中快速定位第k大的元素。其通過分區策略和隨機化選擇,最終時間復雜度能達到O(N)。
它的原理如下:
- 通過確定隨機數后進行三路劃分,得到<x ==x >x三個范圍,并且這個x所在位置和有序的情況是一樣的(因為快排所做的就是讓每個基準值放在對應有序的位置)。
- 因為第k大的元素,反過來就是len-k小的元素,在有序情況下這個元素就是對應所在下標位置。
- 因此,假設對應k位置的值為val,那么val大于x,就說明還需要道x的右邊區域查找(也就是再細分區域),如果val小于x,就說明要道x的左邊區域繼續查找。如果等于x就說明第k大的元素就是x。
數組中的第K個最大元素

完整代碼
class Solution {
public:int first = 0, last = 0;int findKthLargest(vector<int>& nums, int k) {//找第k大的,就是找nums.size-k小的return findKthSmall(nums, nums.size() - k);}int findKthSmall(vector<int>& nums, int i){int ans = 0;int l = 0, r = nums.size() - 1;while (l <= r){int x = nums[l + rand() % (r - l + 1)];//將x對應的有序位置進行確定partition(nums, l, r, x);//看nums[i]和x的大小關系,確定nums[i]的位置if (nums[i] > x) l = last + 1;else if (nums[i] < x) r = first - 1;else{ans = nums[i];break;}}return ans;}//三路劃分, 一定要注意劃分范圍是 >x ==x >x 不然不行void partition(vector<int>& nums, int l, int r, int x){first = l, last = r;int i = l;while (i <= last){if (nums[i] < x) swap(nums[i++], nums[first++]);else if (nums[i] > x) swap(nums[i], nums[last--]);else ++i;}}
};
為什么只能用三路劃分?partition用挖坑法行嗎?
如果是3 3 3 4 3 3 3這樣一組數找第一大的,如果采用挖坑法只能劃分<=x >=x兩個范圍,對于隨機到3而言,第一趟劃分就是不變,就無法通過比較對應i位置的大小確定第一大的數的位置。因此一定得保證劃分范圍是 >x ==x >x 。
算法中有很多精妙又美麗的思想傳統,請務必堅持下去!!









)



)





