RoboGround 論文
一類中間表征是語言指令,但對于空間位置描述過于模糊(“把杯子放桌上”但不知道放桌上哪里);另一類是目標圖像或點流,但是開銷大;由此 GeoDEX 提出一種兼具二者的掩碼。
相比于 GR-1,通過分割算法,提出了局部 Mask,以及相應的坐標,增強了空間理解。
現有的語言條件下的仿真數據集常常存在物體和環境多樣性不足,或者缺乏廣泛的指令和復雜場景,基于 RoboCasa 引入一種自動化數據生成流程。

數據集
在 Objaverse 中借助 GPT-4o,篩選并識別出1)適合桌面使用的物品;2)與廚房相關的物品;3)排除多件物品組合;再經過人工審核,挑選出 1017 個高質量桌面操作物體。
原有的語言條件數據集:指令格式固定——模型只需要學習指令到任務的映射,無需深入理解指令,導致泛化能力差。
- Appearance——從 4 個視角(正面、背面、左側和右側)渲染每個物體,由此組合成一張綜合圖像,再用 GPT-4 提取特征(顏色、材質、形狀等),隨機選取一個作為物體特征并過濾掉場景中包含該特征的其他物體。然后通過 CLIP 選擇干擾物。(選取一組代表物,通過他們學習別的特征混合的物體)
- Spatial——指定物體以及位置坐標的指令。
- Commonsense——使用 GPT-4 為每個任務提供機器人的視角圖像(左側、右側和手部視角),以及目標物體及其預期位置的詳細信息。(傳統:把紅色的杯子從桌子上拿起來;常識:把杯子從桌子上拿起來)

定位視覺語言模型
- y t = L ( f v ( C L I P ( x v ) ) , x t ) y_t=L(f_v(CLIP(x_v)),x_t) yt?=L(fv?(CLIP(xv?)),xt?) 模型通過一個提示來感知圖像,提示的格式為:“The
<IMAGE>provides an overview of the picture”。其中<IMAGE>標記被替換為投影后的視覺特征,表示為256個標記的序列。 - 在定位頭中,采用預訓練的 SAM 編碼器,解碼器類似 SAM 解碼器架構。在 LLM 的詞匯表中引入
<SEG>提取與定位相關特征。由此生成二進制掩碼: M = D ( f s ( F s e g , E ( x v ) ) ) M=D(f_s(F_{seg},E(x_v))) M=D(fs?(Fseg?,E(xv?)))
其中 f v , f s f_v,f_s fv?,fs? 為投影器, F s e g F_{seg} Fseg? 為<SEG>標記對應的最后一層嵌入。
采用 GR-1 架構。
掩碼為機器人的策略提供了有用的空間引導。與其要求明確地將語義描述定位到具體物體上,策略網絡可以專注于利用這種結構化信息來改進物體定位和動作執行。
視覺特征 Z v ∈ R 197 × D v Z_v \in \mathbb{R}^{197×D_v} Zv?∈R197×Dv? : Z v = V i T M A E ( L i n e a r ( C o n c a t ( x v , M o , M p ) ) ) Z_v=ViTMAE(Linear(Concat(x_v,M_o,M_p))) Zv?=ViTMAE(Linear(Concat(xv?,Mo?,Mp?))), M o M_o Mo? 為目標物體掩碼, M p M_p Mp? 為放置區域掩碼。同時 Z v Z_v Zv? 還包含 CLS 特征 Z C L S v ∈ R 1 × D v Z_{CLS}^v\in R^{1×D_v} ZCLSv?∈R1×Dv? ,一組局部 patch Z v P ∈ R 196 × D Z_v^P \in R^{196×D} ZvP?∈R196×D。
語言輸入通過 CLIP 編碼為 Z t Z_t Zt?,機器人狀態 x t x_t xt? 通過 MLP 投影為 Z s Z_s Zs?,以及一個可學習的動作標記 Z a c t Z_{act} Zact?。
在 GR-1 中,Perceiver 作為一個標記重組器,通過在一組可學習的查詢標記和初始視覺特征之間進行迭代注意力層來減少從初始視覺特征中派生的特征數量。本文將注意力引導至掩碼所在的區域,引入兩組額外標記: Q o Q_o Qo? 用于目標物體, Q p Q_p Qp? 用于放置物體,在每個注意力層中,他們與 Z v P Z_v^P ZvP? 相互作用,注意力通過掩碼 M o M_o Mo? 和 M p M_p Mp? 引導。
實驗結果
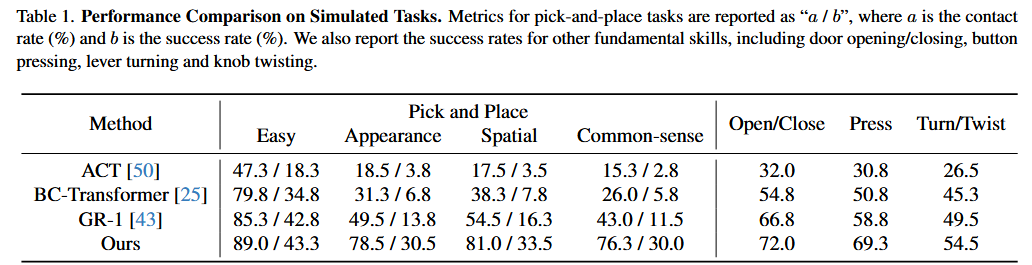
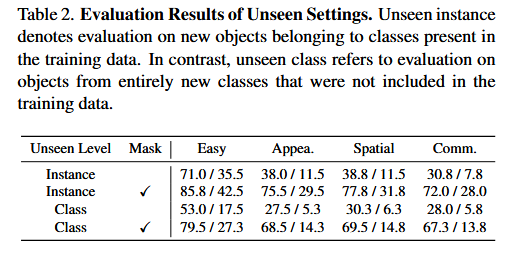
+安裝kubesphere圖形化界面使用和操作)



)







)

)




