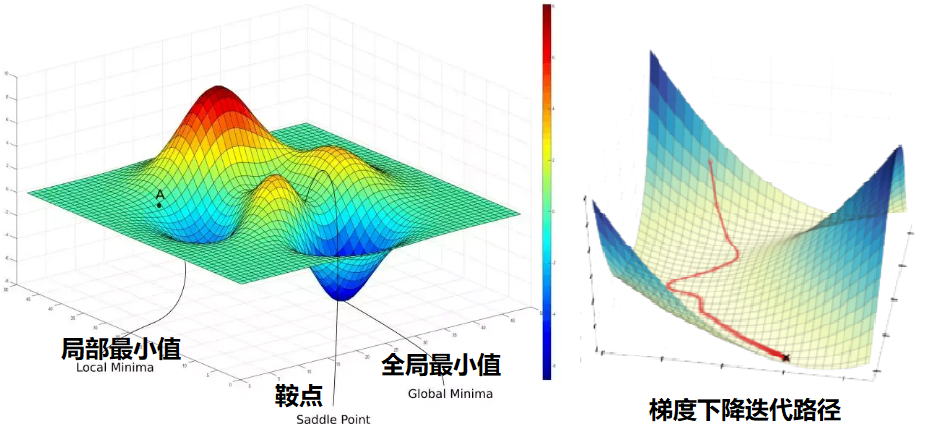
梯度下降法——是一種最優化算法,用于找到函數的局部極小值或全局最小值。它基于函數的梯度(或偏導數)信息來更新參數,目標是通過逐漸調整參數值來最小化目標函數的值。在機器學習算法中,梯度下降是最常采用的方法之一,尤其是在深度學習模型中,BP反向傳播方法的核心就是對每層的權重參數不斷使用梯度下降來進行優化。
梯度下降法的一個直觀的理解,就像一個圓球從山頂滾向山腳的過程:
1. 初始位置:圓球隨機落在山頂的某個位置,就像算法一開始隨機設定參數。
2. 找坡度:圓球會自動朝最陡的下坡方向滾動,這對應算法計算損失函數的梯度(最陡上升方向)并取反,確定參數更新方向。因為梯度方向與等高線垂直,所以圓球總是垂直于山坡滾動。
3. 控制步長:圓球滾動的距離由初始勢能(學習率)決定。步子太大可能直接滾過山腳,太小又會走得很慢,學習率就是用來平衡這個“步子大小”的關鍵。
4. 不斷迭代:每滾一步,圓球都會重新調整方向,直到感覺坡度變緩(梯度接近零),此時認為到達山腳(找到最優解)。但現實中可能因局部陡坡卡住(陷入局部最小值),需要調整策略。
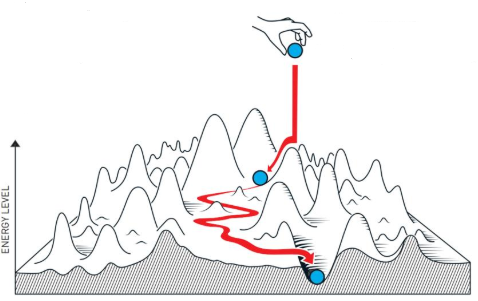
整個過程圓球在復雜地形中“試探著往下走”,通過不斷調整方向和步長逼近最低點,即,梯度下降算法最終找到讓目標函數最小的參數。
一、梯度下降法的數學原理
1.1 什么是梯度
梯度是微積分中的基本概念,也是機器學習解優化問題經常使用的數學工具,要理解梯度,首先我們先溫習一下導數的概念——導數是一元函數的變化率(斜率)。如下求導計算,第一個表達式為求的導數:
???????
??????? ???????
當一個函數有多個變量的時候,想知道在某個位置的變化率(最典型的就是曲面上某個點的變化率)時,需要分別對每個變量求偏導數,也就是求各個方向的變化率:
偏導數寫成向量形式,二元時為

)

)





)
圖像與通道拼接函數-----對圖像進行幾何變換函數remap())


)
![[ linux-系統 ] 常見指令2](http://pic.xiahunao.cn/[ linux-系統 ] 常見指令2)




