在鵝廠后端開發一面,我遇到了如題這樣一個比較寬泛的問題,當時可能只是背了相關概念,對于索引的了解不是很深刻。
最近,我花了很大的功夫去深入了解MySQL的索引。
下面是我的一些思考:
索引,對于InnoDB來說,索引通常是指一棵B+樹(聚簇索引或二級索引)。
- 對于聚簇索引來說,只是葉子節點存放的列包括主鍵和其他列,索引存放的是每個頁中最小主鍵值和頁號
- 對于非聚簇索引來說,葉子節點存放的是 索引列 和主鍵值,非葉子節點存放的是最小主鍵值和頁號+ 索引列的值(保證在B+樹的同一層內節點的目錄項記錄除頁號這個字段以外是唯一的)
原因是:InnoDB的B+樹索引是有序的。對于復合索引(比如索引列a,b),如果有多條記錄a,b值相同,InnoDB需要依靠主鍵值來唯一定位和排序。下面舉一個具體的例子說明:
假設 數據庫建表語句如下:
mysql> CREATE TABLE index_demo(-> c1 INT,-> c2 INT,-> c3 CHAR(1),-> PRIMARY KEY(c1)-> INDEX idx_c2 (c2)-> ) ROW_FORMAT = Compact;
主鍵是C1, 二級索引C2,假設表中的數據是
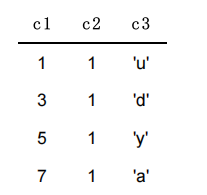
如果二級索引中目錄項記錄的內容只是 索引列 + 頁號 的搭配的話,那么為 c2 列建立索引后的 B+ 樹應該長這樣
如果我們想新插入一行記錄,其中 c1 、 c2 、 c3 的值分別是: 9 、 1 、 ‘c’ ,那么在修改這個為 c2 列建立的二級索引對應的 B+ 樹時便碰到了個大問題:由于 頁3 中存儲的目錄項記錄是由 c2列 + 頁號 的值構成的,頁3 中的兩條目錄項記錄對應的 c2 列的值都是 1 ,而我們新插入的這條記錄的 c2 列的值也是 1 ,那我們這條新插入的記錄到底應該放到 頁4 中,還是應該放到 頁5 中啊?答案是:無法判斷。
為了讓新插入記錄能找到自己在那個頁里,我們需要保證在B+樹的同一層內節點的目錄項記錄除 頁號 這個字段以外是唯一的。所以對于二級索引的內節點的目錄項記錄的內容實際上是由三個部分構成的:
- 索引列的值
- 主鍵值
- 頁號
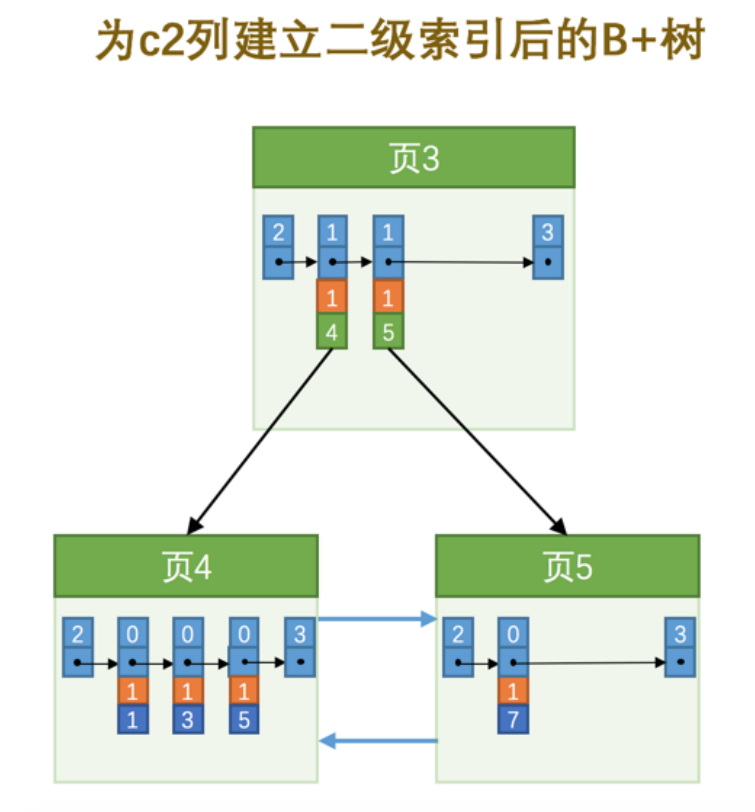
也就是我們把 主鍵值 也添加到二級索引內節點中的目錄項記錄了,這樣就能保證 B+ 樹每一層節點中各條目錄項記錄除 頁號 這個字段外是唯一的,所以我們為 c2 列建立二級索引后的示意圖實際上應該是這樣子的
這樣我們再插入記錄 (9, 1, ‘c’) 時,由于 頁3 中存儲的目錄項記錄是由 c2列 + 主鍵 + 頁號 的值構成的,可
以先把新記錄的 c2 列的值和 頁3 中各目錄項記錄的 c2 列的值作比較,如果 c2 列的值相同的話,可以接著比較
主鍵值,因為 B+ 樹同一層中不同目錄項記錄的 c2列 + 主鍵 的值肯定是不一樣的,所以最后肯定能定位唯一的
一條目錄項記錄,在本例中最后確定新記錄應該被插入到 頁5 中。
索引同層的非葉子結點間,是否也用雙線鏈表維系呢?
是的,如果詢問AI 大模型,大部分都是回答沒有,這顯然是錯誤的,為此我查閱了相關Mysql 源碼的實現storage/innobase/include/fil0fil.h 的第461 行
#define FIL_PAGE_PREV 8 /*!< 如果頁面存在一個“自然”的前驅頁面,則記錄其偏移量。否則,該字段為FIL_NULL。對于BLOB頁面,此字段未設置,因為BLOB頁面是以單鏈表形式存儲的。另請參見FIL_PAGE_NEXT。 */#define FIL_PAGE_NEXT 12 /*!< 如果存在頁面的“自然”后繼節點,則記錄其偏移量。否則為FIL_NULL。相同PAGE_LEVEL的B樹索引頁(FIL_PAGE_TYPE包含FIL_PAGE_INDEX)通過FIL_PAGE_PREV和FIL_PAGE_NEXT按照每頁上最小用戶記錄的排序順序維護為雙向鏈表。 */
相同PAGE_LEVEL的B樹索引頁,(FIL_PAGE_TYPE包含FIL_PAGE_INDEX),通過FIL_PAGE_PREV和FIL_PAGE_NEXT,按照每頁上最小用戶記錄的排序順序,維護為雙向鏈表。
非葉子結點各層的雙向鏈表,連起來起了什么作用呢?
深入了解 源碼后,在storage/innobase/btr/btr0btr.cc 中找到了相關的代碼實現
- 支持范圍掃描操作
// 在進行范圍掃描時會使用這些鏈接:
if (left_page_no != FIL_NULL) {prev_block = btr_block_get(page_id_t(space, left_page_no), block->page.size,RW_X_LATCH, index, mtr);
}if (next_page_no != FIL_NULL) {next_block = btr_block_get(page_id_t(space, next_page_no), block->page.size,RW_X_LATCH, index, mtr);
}
- 維護B樹結構的完整性
// 在頁面分裂時需要維護這些鏈接關系:
btr_page_set_next(lower_page, lower_page_zip, upper_page_no, mtr);
btr_page_set_prev(upper_page, upper_page_zip, lower_page_no, mtr);if (direction != FSP_DOWN) {btr_page_set_next(upper_page, upper_page_zip, next_page_no, mtr);
}
- 優化查詢性能
// 在查詢時可以快速定位到相鄰頁面:
static
void
btr_cur_prefetch_siblings(buf_block_t* block)
{page_t* page = buf_block_get_frame(block);ulint left_page_no = fil_page_get_prev(page);ulint right_page_no = fil_page_get_next(page);// 預讀相鄰頁面以提高性能if (left_page_no != FIL_NULL) {buf_read_page_background(...);}if (right_page_no != FIL_NULL) {buf_read_page_background(...);}
}
- 支持頁面合并操作
// 在刪除操作導致頁面需要合并時:
void
btr_discard_page(btr_cur_t* cursor,mtr_t* mtr)
{// 獲取相鄰頁面號left_page_no = btr_page_get_prev(buf_block_get_frame(block), mtr);right_page_no = btr_page_get_next(buf_block_get_frame(block), mtr);if (left_page_no != FIL_NULL) {// 與左側頁面合并merge_block = btr_block_get(...);}
}
- 數據一致性檢查
// 在驗證索引時會檢查相鄰頁面的記錄順序:
if (!dict_index_is_spatial(index)&& cmp_rec_rec(rec, right_rec,offsets, offsets2, index, false) >= 0) {// 如果相鄰頁面的記錄順序不正確,報錯btr_validate_report2(index, level, block, right_block);
}
每個頁對應一個目錄項,每個目錄項包括下邊兩個部分:
聚簇索引
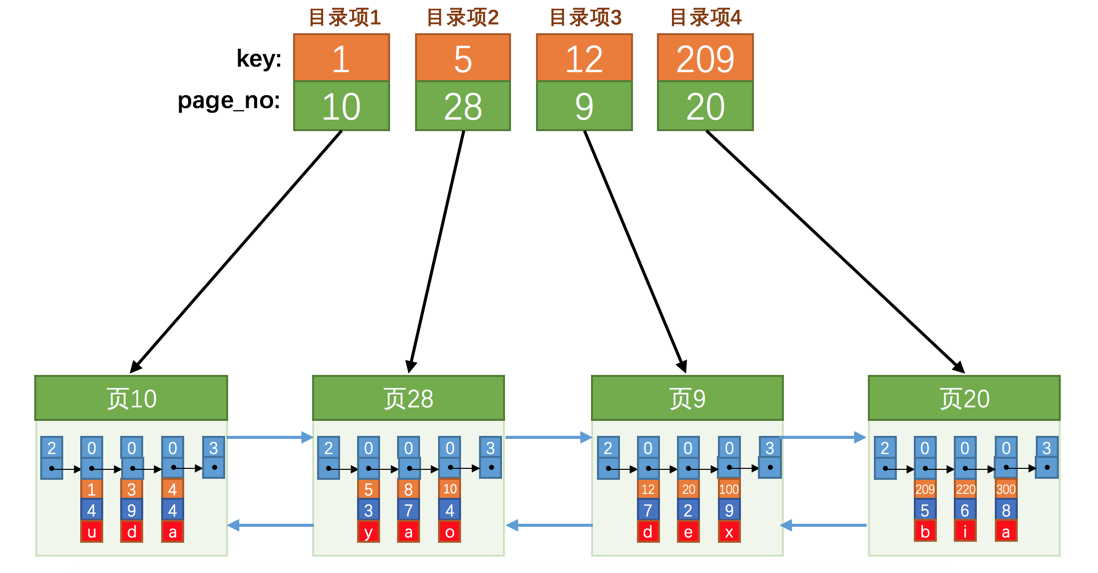
- 頁的用戶記錄中最小的主鍵值,我們用 key 來表示。
- 頁號,我們用page_no 表示。
聚簇索引是一種特殊的B+ 樹
滿足以下 兩個特點:
- 使用記錄主鍵值的大小進行記錄和頁的排序,這包括三個方面的含義
- 頁內的記錄是按照主鍵的大小順序排成一個單向鏈表。
- 各個存放用戶記錄的頁也是根據頁中用戶記錄的主鍵大小順序排成一個雙向鏈表。
- 存放目錄項記錄的頁分為不同的層次,在同一層次中的頁也是根據頁中目錄項記錄的主鍵大小順序排成一個雙向鏈表。
- B+ 樹的葉子節點存儲的是完整的用戶記錄。
所謂完整的用戶記錄,就是指這個記錄中存儲了所有列的值(包括隱藏列)
之前我們說過索引的構造和用戶記錄頁 很相似,那么InnoDB 怎么區分一條記錄是普通的用戶記錄還是目錄項記錄呢?別忘了記錄頭信息里的record_type 屬性,它的各個取值代表的意思如下:
- 0 :普通的用戶記錄
- 1 :目錄項記錄
- 2 :最小記錄
- 3 :最大記錄
參考:《從根上理解MySQL》














Day15!!!C/C++)

——實時語音識別技術)

)