Scrapy-Redis 介紹
Scrapy-Redis是一個基于Redis實現的 Scrapy 分布式爬蟲組件。Scrapy 本身是一個強大的 Python爬蟲框架,但它默認是單進程單線程的,在面對大規模數據抓取任務時效率不高。Scrapy-Redis則解決了這一問題,它允許你將 Scrapy爬蟲擴展到多個機器上運行,從而實現分布式爬蟲的功能。
Scrapy-Redis 主要提供了以下幾個核心功能:
1.調度器(Scheduler):Scrapy-Redis 提供了一個基于 Redis 的調度器,用于管理待爬取的請求隊列。不同的爬蟲實例可以從這個共享的隊列中獲取請求,避免了請求的重復抓取。
2.去重過濾器(DupeFilter):使用 Redis 的集合(set)數據結構實現了請求去重的功能,確保每個請求只被處理一次。
3.管道(Pipeline):支持將爬取到的數據存儲到 Redis 中,方便后續的處理和分析。
4.分布式爬蟲:多個爬蟲實例可以同時從 Redis 中獲取任務,并行地進行數據抓取,大大提高了爬蟲的效率。
Scrapy-Redis 使用步驟
1. 安裝 Scrapy-Redis
pip install scrapy-redis
2. 創建 Scrapy 項目
scrapy startproject myproject
cd myproject
scrapy genspider myspider example.com
3. 配置 Scrapy 項目
在 settings.py 文件中進行以下配置:
# ///
# 啟用 Redis 調度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 確保所有爬蟲共享相同的去重過濾器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 允許暫停和恢復爬蟲,請求隊列會保存在 Redis 中
SCHEDULER_PERSIST = True
# 配置 Redis 服務器地址
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
# REDIS_URL = 'redis://localhost:6379' # 或者這樣
# 配置管道,將數據存儲到 Redis 中
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300
}
# ///
4. 修改爬蟲代碼
在 myspider.py 中,讓你的爬蟲繼承自 RedisSpider:
import scrapy
from scrapy_redis.spiders import RedisSpiderclass MySpider(RedisSpider):name = 'myspider'# 從 Redis 中獲取起始 URL 的鍵名redis_key = 'myspider:start_urls'def parse(self, response):# 解析響應內容item = {'url': response.url}yield item
5. 啟動 Redis 服務器
確保你的 Redis 服務器已經啟動:
redis-server
6. 向 Redis 中添加起始 URL
使用 Redis 客戶端向 Redis 中添加起始 URL:
redis-cli lpush myspider:start_urls http://example.com
7. 啟動爬蟲
在項目目錄下啟動爬蟲:
scrapy crawl myspider
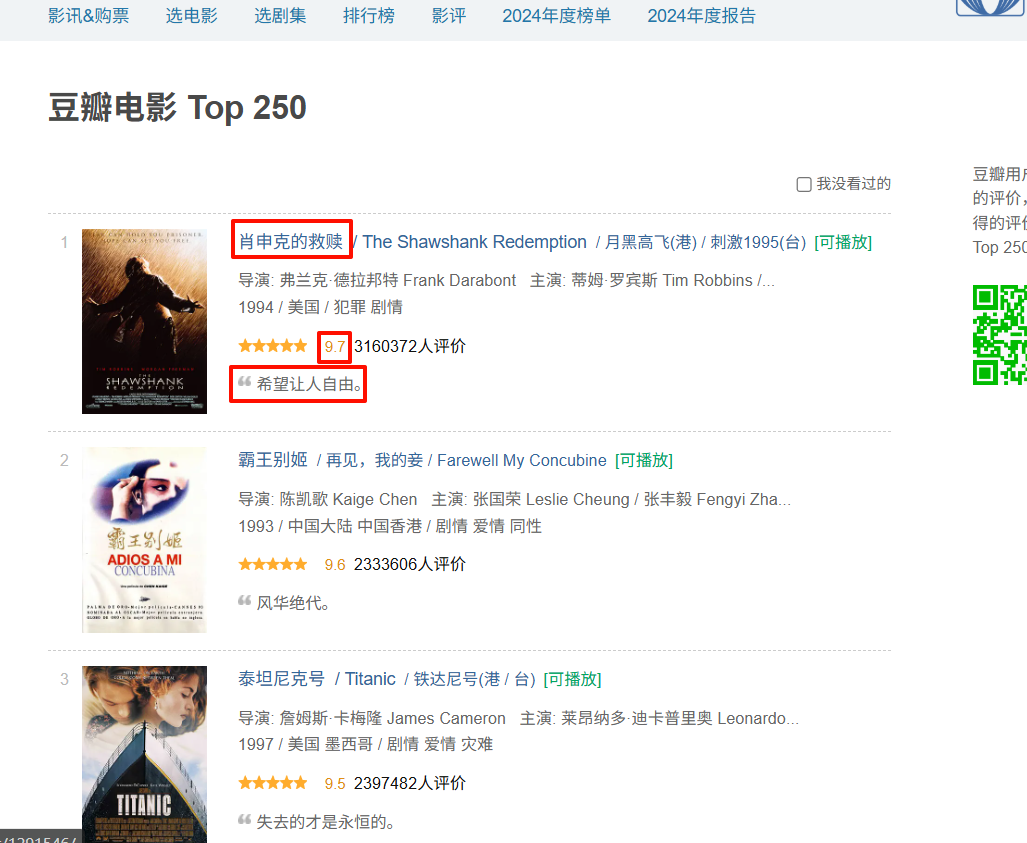
爬取目標
目標網址:https://movie.douban.com/top250?start=0&filter=
爬取豆瓣電影的Top250
Redis 中的起始 URL 列表(douban:start_urls)添加第一頁的URL
lpush douban:start_urls https://movie.douban.com/top250?start=0&filter=

順便配置一下記錄數據的爬取時間的管道
from datetime import datetimeclass DoubanScrapyPipeline:def process_item(self, item, spider):item['crawled_time'] = datetime.now().strftime("%Y-%m-%d %H:%M:%S")item['spider'] = spider.namereturn item
爬蟲代碼
class DoubanSpider(RedisSpider):name = 'douban'# 從 Redis 中獲取起始 URL 的鍵名redis_key = 'douban:start_urls'def parse(self, response: HtmlResponse, **kwargs):print(f"Extracted URL: {response.url}")# 解析響應內容li_list = response.xpath('//ol[@class="grid_view"]/li')for li in li_list:item = dict()item['title'] = li.xpath('.//span[@class="title"]/text()').get()item['rating'] = li.xpath('.//span[@class="rating_num"]/text()').get()item['quote'] = li.xpath('.//p[@class="quote"]/span/text()').get()yield item
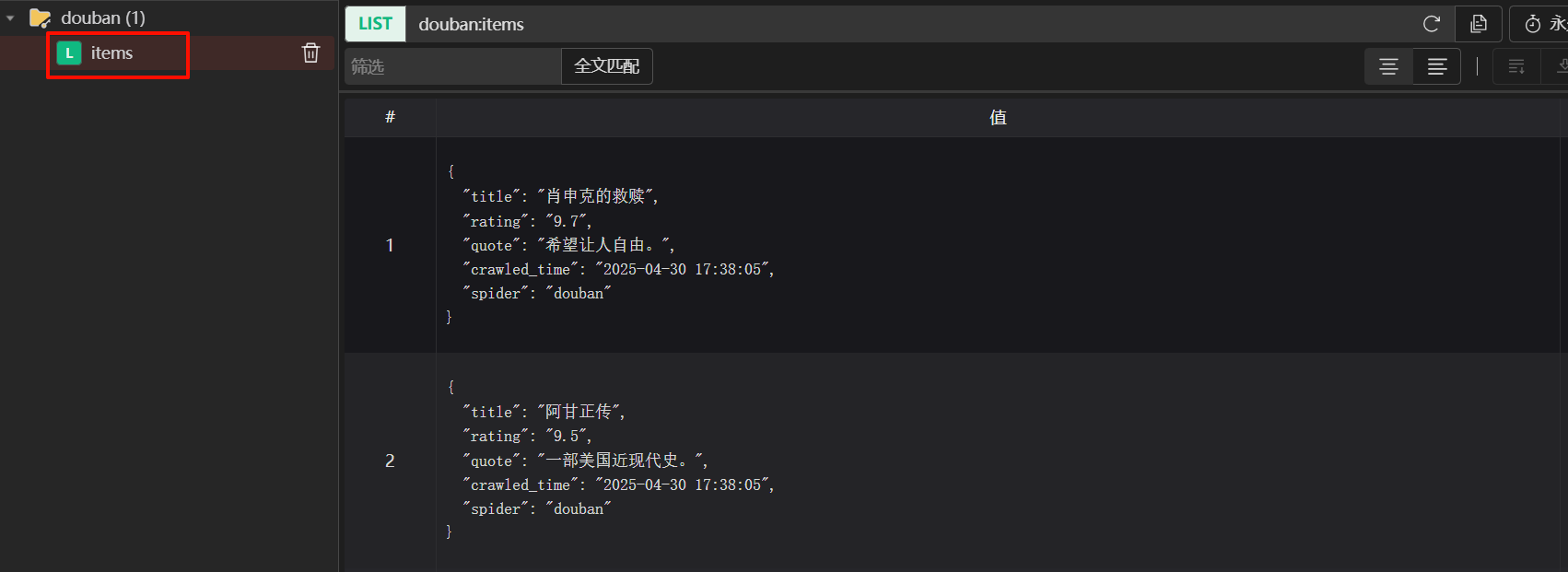
運行爬蟲之后,redis中就會多一個items
——實時語音識別技術)

)
















