首先回顧狀態價值函數和動作價值函數的定義:
狀態價值函數 v π ( s ) v_\pi(s) vπ?(s)是從狀態 s s s出發,直至一幕結束后獲得的回報的期望值
動作價值函數 q π ( s , a ) q_\pi(s,a) qπ?(s,a)是從狀態 s s s出發,采取動作 a a a后,直至一幕結束后獲得的回報的期望值
以下面這張回溯圖為例:
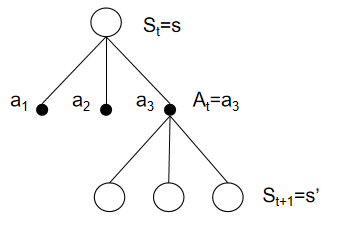
從狀態 s s s出發有三個動作可以選,選擇的概率為 π ( a i ∣ s ) \pi(a_i|s) π(ai?∣s),一旦選擇了動作 a i a_i ai?,后續獲得的回報為 q π ( s , a i ) q_\pi(s,a_i) qπ?(s,ai?),而狀態價值函數是從狀態 s s s出發回報的期望值,因此需要按動作被選擇的概率對動作價值進行加權求和,即:
v π ( s ) = π ( a 1 ∣ s ) q π ( s , a 1 ) + π ( a 2 ∣ s ) q π ( s , a 2 ) + π ( a 3 ∣ s ) q π ( s , a 3 ) v_\pi(s)=\pi(a_1|s)q_\pi(s,a_1)+\pi(a_2|s)q_\pi(s,a_2)+\pi(a_3|s)q_\pi(s,a_3) vπ?(s)=π(a1?∣s)qπ?(s,a1?)+π(a2?∣s)qπ?(s,a2?)+π(a3?∣s)qπ?(s,a3?)
更一般地,狀態價值與動作價值的關系為:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v_\pi(s)=\sum_{a\in\mathcal{A}}\pi(a|s)q_\pi(s,a) vπ?(s)=a∈A∑?π(a∣s)qπ?(s,a)
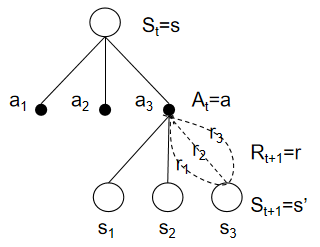
在采取動作 a a a后,智能體會以一定概率獲得一個獎勵 r r r,并轉移到下一個狀態 s ′ s' s′,這個概率記作 p ( s ′ , r ∣ s , a ) p(s',r|s,a) p(s′,r∣s,a)。 q π ( s , a ) q_\pi(s,a) qπ?(s,a)和下一個狀態 s ′ s' s′的狀態價值之間存在以下關系:
q π ( s , a ) = ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] q_\pi(s,a)=\sum_{s'\in S}\sum_{r\in R}p(s',r|s,a)[r+\gamma v_\pi(s')] qπ?(s,a)=s′∈S∑?r∈R∑?p(s′,r∣s,a)[r+γvπ?(s′)]
這個關系通過下面的回溯圖很容易理解,因為動作價值是期望值,而獎勵 R t + 1 R_{t+1} Rt+1?和下一個狀態 S t + 1 S_{t+1} St+1?都是隨機變量,求期望值需要對隨機變量不同取值按概率加權求和。
聯立上面兩個式子就得到狀態價值函數的貝爾曼方程:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] v_\pi(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in S}\sum_{r\in R}p(s',r|s,a)[r+\gamma v_\pi(s')] vπ?(s)=a∈A∑?π(a∣s)s′∈S∑?r∈R∑?p(s′,r∣s,a)[r+γvπ?(s′)]
同樣可以得到動作價值函數的貝爾曼方程:
q π ( s , a ) = ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r + γ ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) ] q_\pi(s,a)=\sum_{s'\in S}\sum_{r\in R}p(s',r|s,a)[r+\gamma \sum_{a'\in\mathcal{A}}\pi(a'|s')q_\pi(s',a')] qπ?(s,a)=s′∈S∑?r∈R∑?p(s′,r∣s,a)[r+γa′∈A∑?π(a′∣s′)qπ?(s′,a′)]




簡介)




Excel 公式的使用)
 兩大主流游戲引擎的核心使用方法)


)





