數據一致性巡檢總結:基于分桶采樣的設計與實現
背景
在分布式系統中,緩存(如 Redis)與數據庫(如 MySQL)之間的數據一致性問題是一個常見的挑戰。由于緩存的引入,數據在緩存和數據庫之間可能存在延遲、更新失敗或邏輯錯誤,導致數據不一致。這種不一致可能會影響業務的正確性和用戶體驗。
為了解決這一問題,我們設計并實現了一套基于分桶采樣的數據一致性巡檢機制。該機制通過分桶采樣、分批處理、數據一致性校驗、采樣結果存儲、報警機制以及數據維護機制,能夠有效發現緩存與數據庫之間的數據不一致問題,同時優化數據存儲和查詢效率,保障業務的正確性與穩定性。
一、設計思想
- 分桶采樣
- 將數據劃分為多個桶(
BUCKET_SIZE),每個桶包含一定范圍的數據。 - 根據單次需要采樣的數量(
sampleCount)和單次拉取數據量(batchSize),計算得到總批次數,通過總批次數(totalBatches)生成唯一索引(generateUniqueIndexes),到不同桶中隨機采樣數據。 - 分桶采樣的優點在于:
- 降低數據重復采樣的概率,確保采樣數據的獨立性。
- 提高采樣效率,避免全量掃描數據庫。
- 常規的數據庫
Rand()函數存在性能問題。
- 將數據劃分為多個桶(
- 本地聚合與存儲
- 采樣數據在本地內存中聚合,通過
ConcurrentHashMap存儲采樣結果,減少頻繁訪問 Redis。 - 采樣結果通過 Redis 的
SortedSet存儲,score為觸發采樣的時間戳,value中存儲的是不一致率以及不一致的訂單信息,便于前端頁面根據范圍查詢。
- 采樣數據在本地內存中聚合,通過
- 數據一致性校驗
- 針對每個訂單號,分別校驗緩存(Redis)與數據庫(DB)中數據一致性。
- 可以排除指定字段校驗,例如
datachangeLasttime。 - 校驗結果包括:
- 對象級別一致性:校驗單個對象(如訂單、訂單詳情)的字段值是否一致。
- 列表級別一致性:校驗列表數據(如乘客信息、推薦信息)的條目數量和內容是否一致。
- 報警機制
- 如果發現數據不一致,觸發報警機制,通過郵件通知相關人員。
- 報警內容包括:
- 數據庫名、表名、不一致率。
- 不一致訂單的詳細信息(訂單號、DB 數據、Redis 數據、不一致類型)。
- 數據維護機制
- 定期將舊數據從熱緩存遷移到冷緩存,并清理過期數據。
- 通過冷熱數據分離策略,優化存儲和查詢效率。
- 觸發采樣的方式
- 定時任務觸發:系統通過定時任務定期觸發數據一致性巡檢,確保數據一致性問題能夠被及時發現。
- 前端主動觸發:提供了前端接口,允許管理員根據需要手動觸發數據一致性巡檢。
二、實現細節
1. 分桶采樣
int totalBatches = totalCheckCount / batchSize;
if (totalCheckCount % batchSize != 0) {totalBatches++;
}
List<Integer> uniqueIndexes = generateUniqueIndexes(totalBatches).stream().toList();
- 根據總數據量和批次大小計算總批次數。
- 生成唯一索引(
generateUniqueIndexes),確保每批次采樣的數據獨立且不重復。
2. 采樣數據的獲取
// 獲取數據 SQL 針對 ID 取余 SELECT orderNumber FROM scm_grabticket_order WHERE Status IN ('O', 'L') AND id % ? = ? LIMIT ?
List<String> orderNumberList = orderDao.sampleEffectiveOrderNumber(BUCKET_SIZE, bucketIndex, batchSize);
- 每批次從數據庫中采樣有效訂單號(
sampleEffectiveOrderNumber)。 - 采樣邏輯基于分桶索引(
bucketIndex)和批次大小(batchSize),確保采樣數據的獨立性和代表性。
3. 數據一致性校驗
checkConsistencyByOrderNumber(channelEnum, orderNumber, samplingResultMapForNewCache, DataConsistencyQueryType.NEW_CACHE);
-
針對每個訂單號,分別校驗新舊緩存與數據庫的一致性。
-
校驗邏輯包括:
-
對象級別一致性
checkObjectConsistencyAndStoreResult(orderNumber, samplingResult, dbValue, redisValue);- 比較單個對象的字段值是否一致,排除指定字段(
CHECK_CONSISTENCY_EXCLUDE_FIELDS)。
- 比較單個對象的字段值是否一致,排除指定字段(
-
列表級別一致性
checkListConsistencyAndStoreResult(orderNumber, samplingResult, dbValue, redisValue);- 比較列表數據的條目數量和內容是否一致,記錄僅存在于 DB 或 Redis 中的數據。
-
4. 采樣結果的存儲
storeSampleResultToRedis(dbNameEnum, createTime, samplingResultMapForOldCache, DataConsistencyQueryType.NEW_CACHE);
- 將采樣結果存儲到 Redis 的
SortedSet中,score為觸發采樣的時間戳。 - 存儲邏輯包括:
- 設置采樣結果的創建時間(
createTime)和不一致率(inconsistencyRatio)。 - 數據保留時間為 15 天(
LocalDateTime.now().plusDays(15))。
- 設置采樣結果的創建時間(
5. 報警機制
dataInConsistencyAlert(samplingResultMapForNewCache, samplingResultMapForOldCache, dbNameEnum);
- 如果發現數據不一致,觸發報警機制。
- 報警內容包括:
- 數據庫名、表名、不一致率。
- 不一致訂單的詳細信息(最多展示 5 條)。
6. 數據維護機制
定期遷移數據到冷緩存
為了優化存儲和查詢效率,防止 Redis 數據內存占用過大,系統實現了一個數據維護機制,定期將舊數據從熱緩存遷移到冷緩存,并清理過期數據。
public void maintainInConsistencyData(DBNameEnum dbNameEnum) {long fifteenDaysAgo = DateUtils.localDateTimeToLongAccurateMinute(LocalDateTime.now().minusDays(15));long sixMonthsAgo = DateUtils.localDateTimeToLongAccurateMinute(LocalDateTime.now().minusMonths(6));for (TableNameIndexEnum value : TableNameIndexEnum.values()) {for (DataConsistencyQueryType dataConsistencyQueryType : dataConsistencyQueryTypes) {// 1. 從熱數據中查詢 15 天以外的數據,備份到冷數據中backUpOldData(dbNameEnum, value.getTableNameEnum(), dataConsistencyQueryType, fifteenDaysAgo);// 2. 清理冷數據中半年以外的數據removeOldDataFromColdStore(dbNameEnum, value.getTableNameEnum(), dataConsistencyQueryType, sixMonthsAgo);}}
}
- 備份舊數據:將 15 天以前的數據從熱緩存遷移到冷緩存。
- 清理過期數據:刪除冷緩存中 6 個月以前的數據。
- 數據精簡:遷移到冷緩存時,會清除詳細的不一致訂單信息,只保留統計數據。
觸發方式
數據維護機制的觸發方式有兩種:
- 定時任務調度:系統會定期自動觸發數據維護任務,確保數據定期得到整理和優化。
- 前端主動觸發:提供了前端接口,允許管理員手動觸發數據維護任務,以應對特殊情況或緊急需求。
這種雙重觸發機制既保證了數據維護的自動化,又提供了靈活的人工干預途徑。
三、前端展示
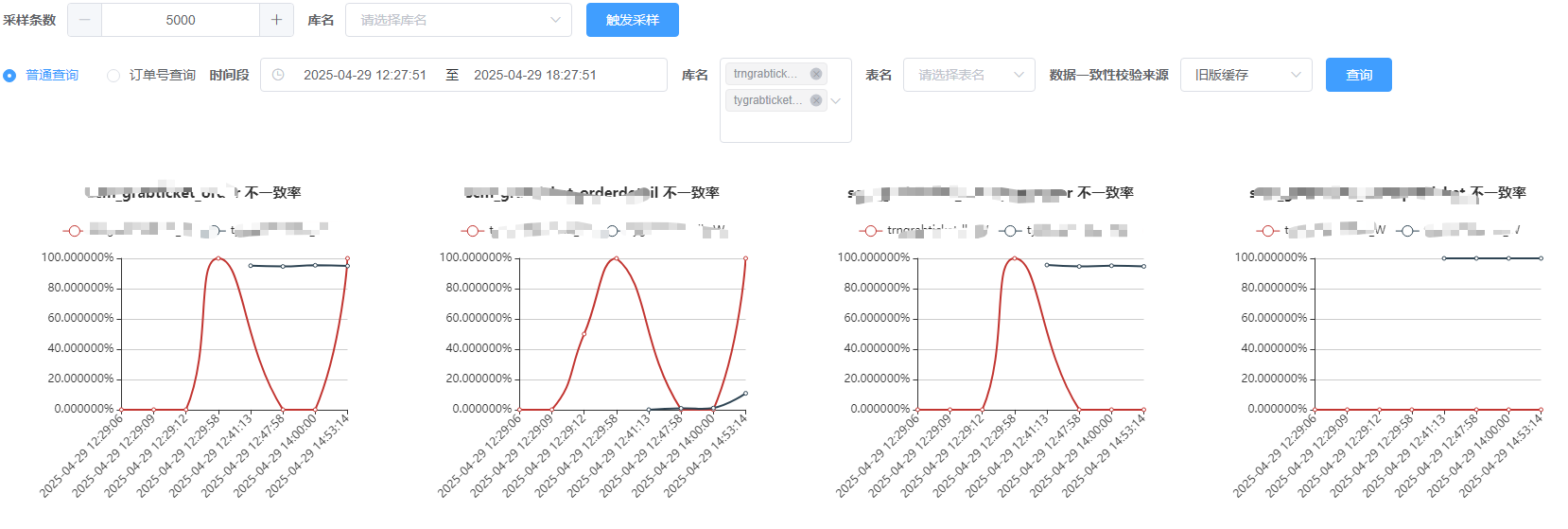
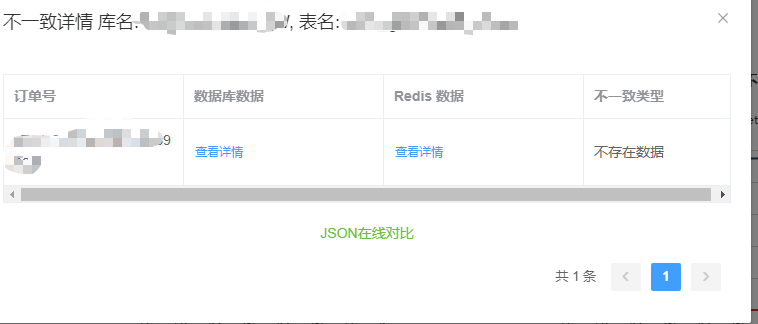
四、總結
本文總結了基于分桶采樣的數據一致性巡檢設計與實現,涵蓋了分桶采樣、分批處理、數據一致性校驗、采樣結果存儲和報警機制等關鍵點。同時,介紹了數據維護機制,包括定期將舊數據遷移到冷緩存以及清理過期數據的策略。系統通過定時任務和前端主動觸發兩種方式來執行數據維護,既保證了自動化又提供了靈活性。





![[逆向工程]如何理解小端序?逆向工程中的字節序陷阱與實戰解析](http://pic.xiahunao.cn/[逆向工程]如何理解小端序?逆向工程中的字節序陷阱與實戰解析)
)
:集群核心配置)



 聯合查詢)







