1. 問題背景
大模型微調的挑戰:
預訓練模型(如GPT-3、LLaMA)參數量巨大(數十億至萬億級),直接微調所有參數:
-
計算開銷大:需更新全部權重,GPU顯存不足。
-
存儲冗余:每個任務需保存獨立的全量模型副本。
2. LoRA的核心思想

3. 參數初始化策略
| 矩陣 | 初始化方法 | 目的 |
|---|---|---|
| A | 隨機高斯分布(均值為0) | 打破對稱性,提供多樣化的梯度方向,避免所有神經元學習相同特征。 |
| B | 全零初始化 | 確保訓練開始時?ΔW=0ΔW=0,模型行為與預訓練一致,穩定訓練。 |
?
為什么矩陣B初始化為零?
核心目標:訓練穩定性
-
初始狀態一致性:
微調開始時,保證模型行為與預訓練模型完全一致: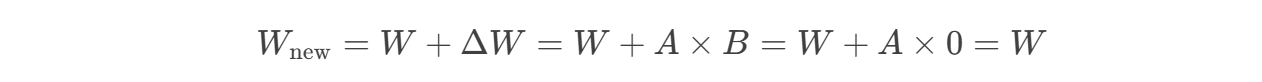
-
類比:如同汽車改裝,先保持原廠配置(W),再逐步加裝新部件(ΔW),避免直接飆車失控。
-
避免的問題
-
性能突變:
若初始?ΔW≠0,模型可能立即偏離預訓練學到的知識(如GPT-3突然忘記如何造句)。 -
梯度爆炸:
隨機初始化的?A 和?B 乘積可能產生數值不穩定的梯度。
實驗支持
-
論文實驗顯示:零初始化?BB?可使初始損失與預訓練模型相差不足0.1%,而非零初始化可能差50%+。
為什么矩陣A隨機初始化?
核心目標:探索多樣性
-
打破對稱性:
隨機高斯初始化(如PyTorch默認的Kaiming初始化)確保:
? ? ? ?![]()
?聯合作用機制
訓練動態示例

類比說明
-
B=0B=0:如同汽車油門初始置零,確保啟動時不突然加速。
-
AA隨機:如同方向盤初始角度各異,確保車輛可靈活轉向不同方向。
4. 為什么有效?
(1) 內在低秩性(Intrinsic Low-Rankness)
-
理論依據:大模型的權重變化矩陣?ΔWΔW?通常是低秩的(少數主成分主導變化)。
-
實驗驗證:在Transformer中,僅調整?r=8?的LoRA即可接近全參數微調效果。
(2) 參數效率
-
參數量對比:
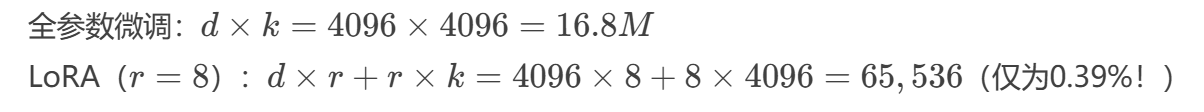
(3) 任務切換便捷性
-
不同任務只需替換輕量的?AA?和?BB(幾MB),共享同一預訓練模型?WW。
5. 實際應用示例
(1) Hugging Face PEFT庫實現
from peft import LoraConfig, get_peft_modelconfig = LoraConfig(r=8, # 秩lora_alpha=16, # 縮放因子 αtarget_modules=["q", "v"], # 應用于Query和Value層的LoRAlora_dropout=0.1, )model = get_peft_model(pretrained_model, config) # 原始模型參數被凍結
(2) 訓練參數量統計
model.print_trainable_parameters() # 輸出示例:trainable params: 262,144 || all params: 6,742,016,000 || trainable%: 0.0039
?LoRA通過低秩分解和增量更新,實現了:
??高效微調:僅訓練0.1%-1%的參數。
??即插即用:無需修改原始模型架構。
??多任務共享:快速切換任務適配器。














)
】)
Android開發中AppCompatActivity和Activity之間的詳細區別)

第 4 版全章節核心考點解析(第4版課程精華版))
