目錄
增加
查詢
基本查詢
where子句
結果排序
篩選分頁結果
修改(更新)
刪除
普通刪除
截斷表
插入查詢結果
聚合函數
分組查詢
這一節的內容是對表內容的增刪查改,其中重點是表的查詢
增加
語法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...
這里面帶[]的是可以省略的。values左邊是要插入的列,右邊是對應列的值?
我們先創建一張表
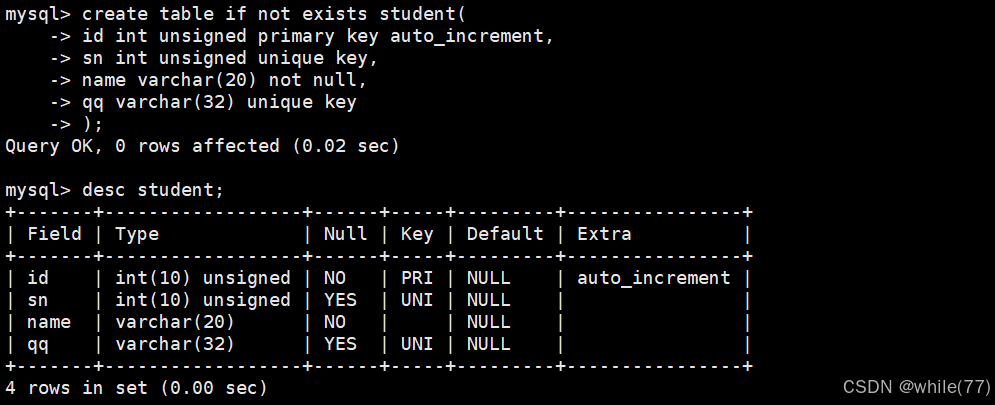
全列插入與指定列插入
values左側是要插入的列,右側是對應列的數值。values左側省略就是全列插入,左側有值就是指定列插入。
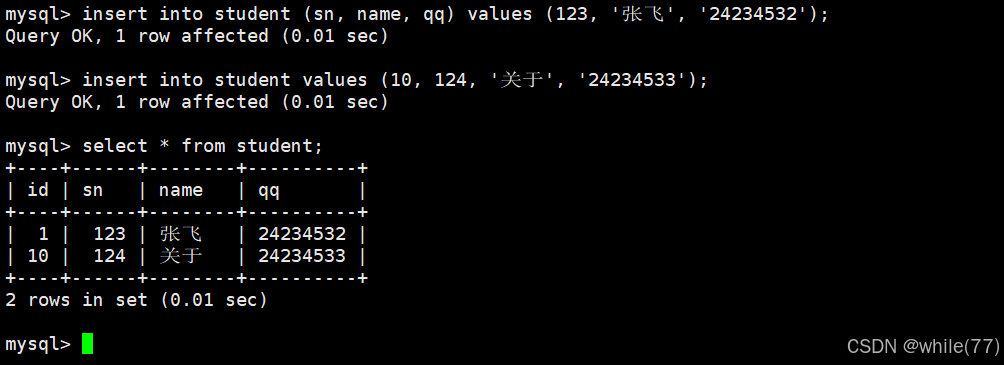
單行插入與多行插入
單行插入是指一次插入一行數據,多行插入是指一次插入多行數據
上面的都是單行插入,現在來看看多行插入
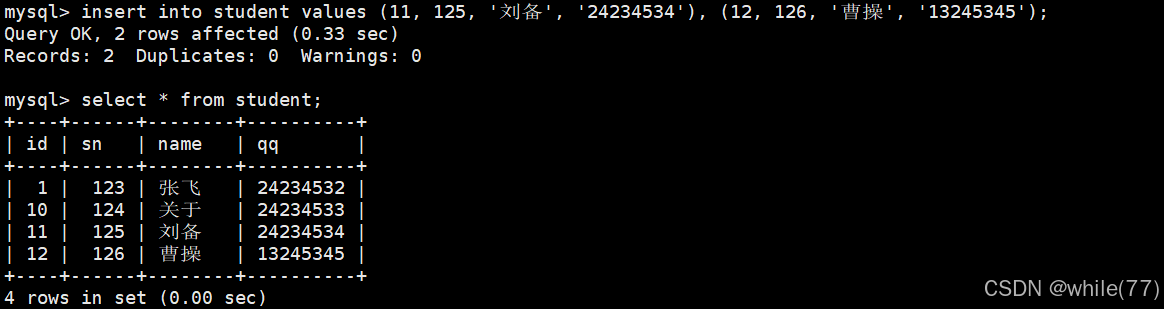
無論是單行插入,還是多行插入,都是可以全列插入或指定列插入的。
插入否則更新
我們前面介紹過主鍵和唯一鍵,當我們向表中插入數據時,是有可能會觸發主鍵/唯一鍵沖突的。此時可以選擇性地進行同步更新操作。語法:
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...
此時是若沒有發生沖突,就插入,若發生了沖突,就更新。注意,更新時也不能讓主鍵/唯一鍵沖突
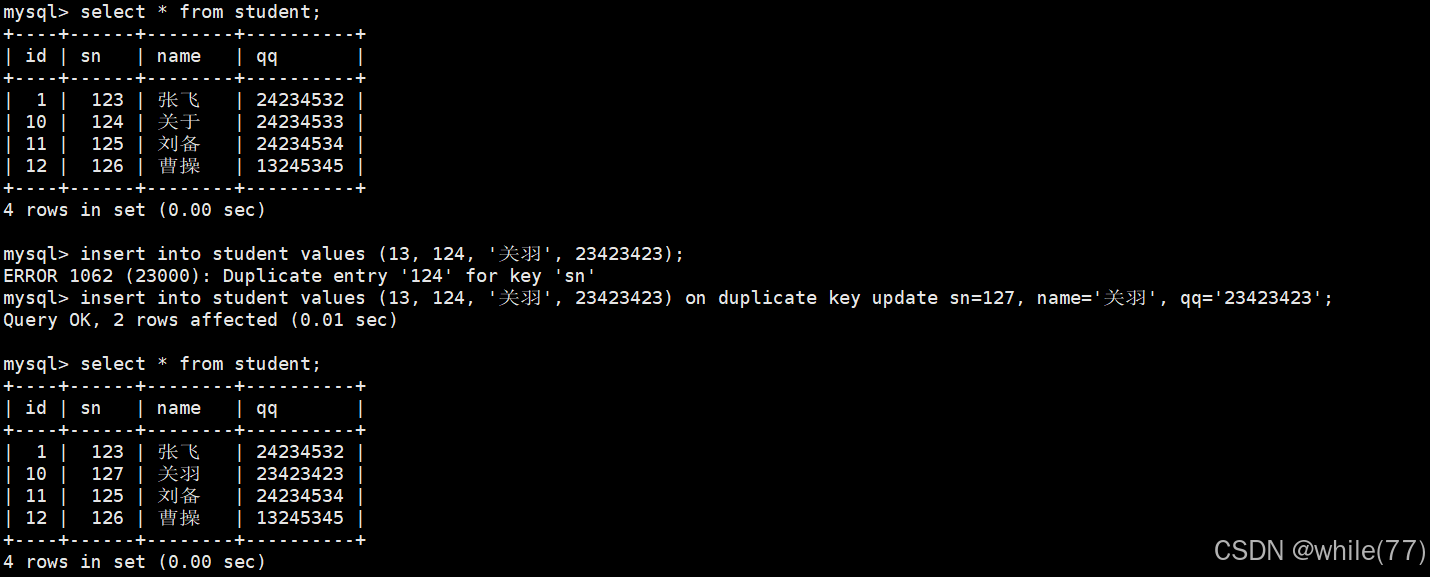
可以看到,前面和后面也并不一定要一樣。
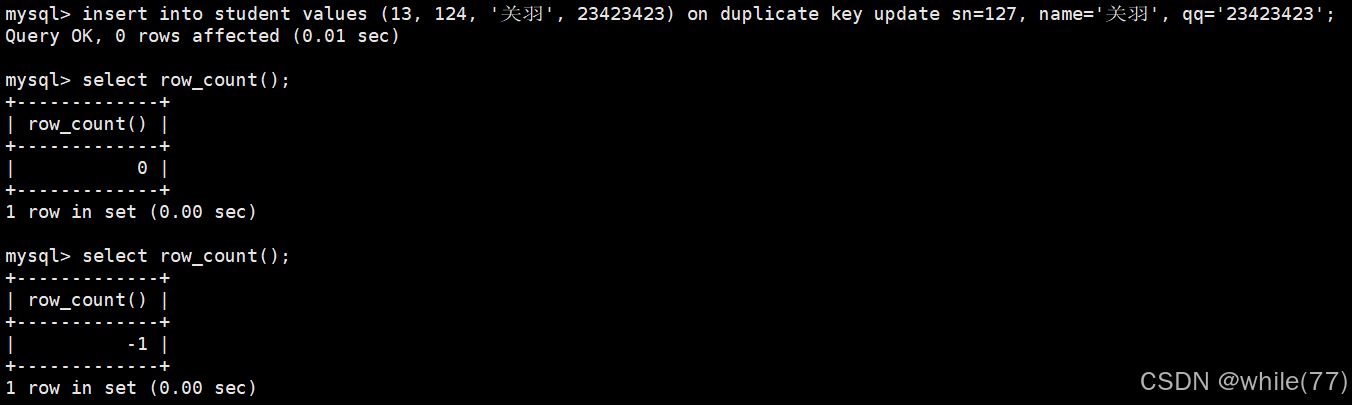
我們可以托命令執行后的語句來判斷命令執行的結果
| ?命令執行后語句 | 代表含義 |
| 0 rows affected | 表中有數據沖突,但沖突數據的值和update的值相等 |
| 1 rows affected | 表中沒有數據沖突,數據被插入 |
| 2 rows affected | 表中有沖突數據,并且數據已經被更新 |
我們也可以使用row_count函數來查看前一個SQL語句影響的行數來判斷執行結果。返回值:
| 返回值 | 含義 |
| 正整數 | 操作影響的行數或查詢結果的行數 |
| 0 | 沒有行受到影響,或查詢返回空結果 |
| -1 | 通常表示錯誤或操作不支持行計數 |
| -2 | 某些驅動中表示行數未知 |
?
替換
在上面的插入否則更新中,可以看到,是將沖突的數據修改成我們指定是數據,而現在說的替換,是將原先沖突的數據刪除,再重新插入
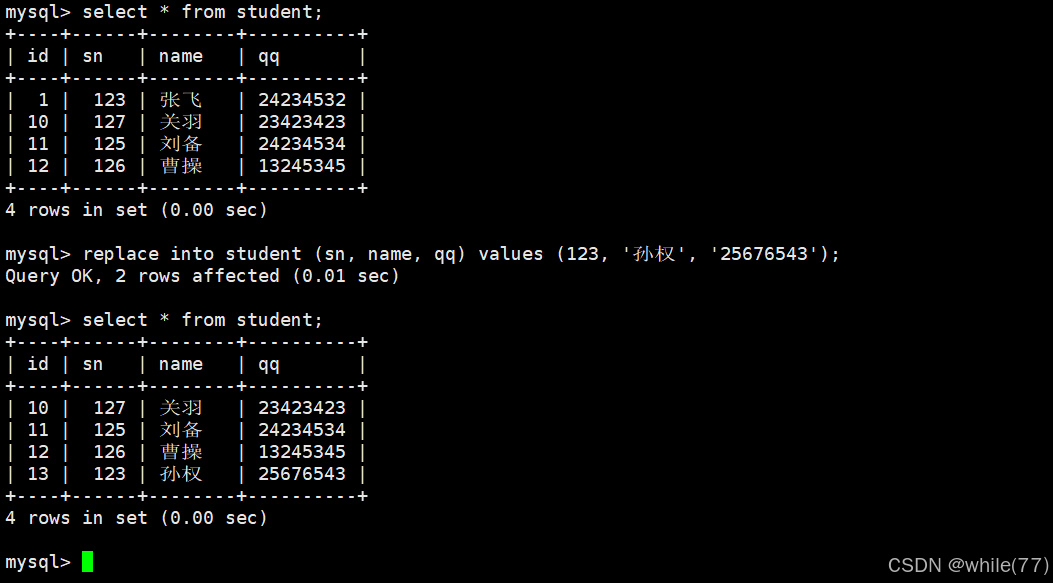
從這里的id值就可看出是先刪除再插入
同樣可以根據命令執行后的語句判斷命令執行結果
| 命令執行后語句 | 代表含義 |
| 1 rows affected | 表中沒有數據沖突,數據被插入 |
| 2 rows affected | 表中有數據沖突,刪除后重新插入 |
查詢
這是最關鍵的步驟。語法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]LIMIT ...
distinct是去重。后面跟*或者指定列,*表示的是對全部的列進行查詢。from是對那個表進行查詢。where是篩選條件。order by是排序。limit是限定篩選出的結果條數。
我們先創建一個表,方便我們后面進行操作

并向其中插入一些數據
基本查詢
全列查詢
全列查詢就是select的后面跟*
通常不建議使用 * 進行全列查詢:
1. 查詢的列越多,意味著需要傳輸的數據量越大
2. 可能會影響到索引的使用
指定列查詢
指定列查詢就是select后面跟列的名稱
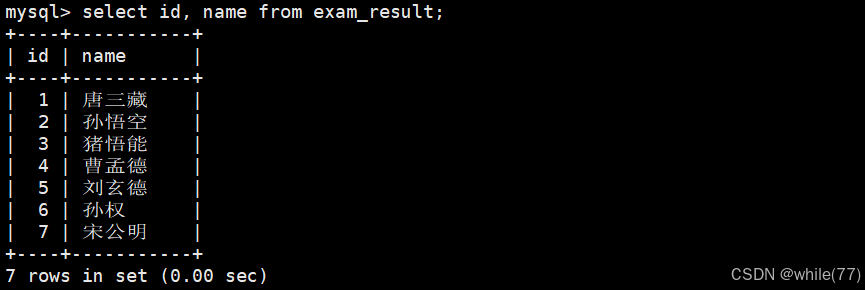
查詢字段為表達式
select后面跟的就是要被執行的表達式,這個表達式可以是select自帶的各種表達式,也可以是1+1等

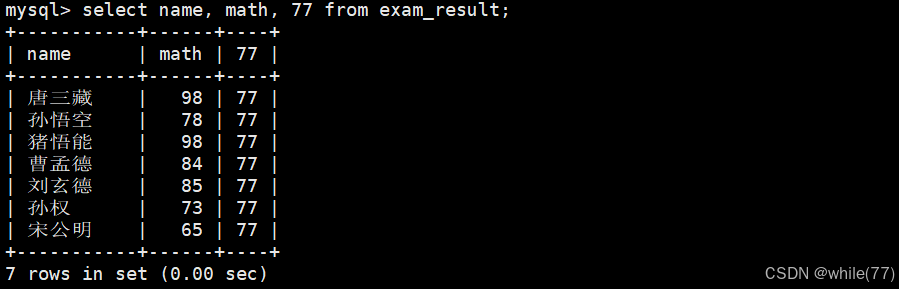
像這樣就是給篩選出的信息每一行加上77
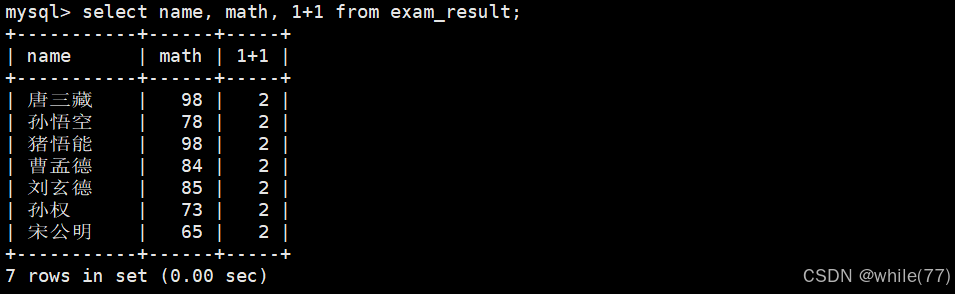
既然可以計算1+1,那么就一定可以計算幾行之和,因為幾行之和也是一個表達式
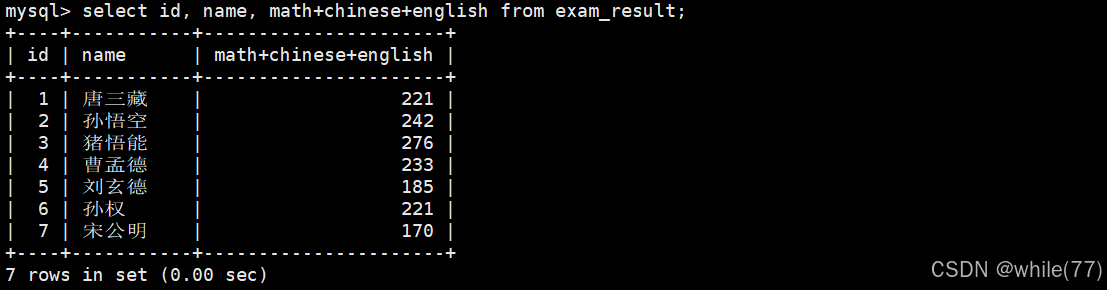
可以給篩選出來的一列取別名
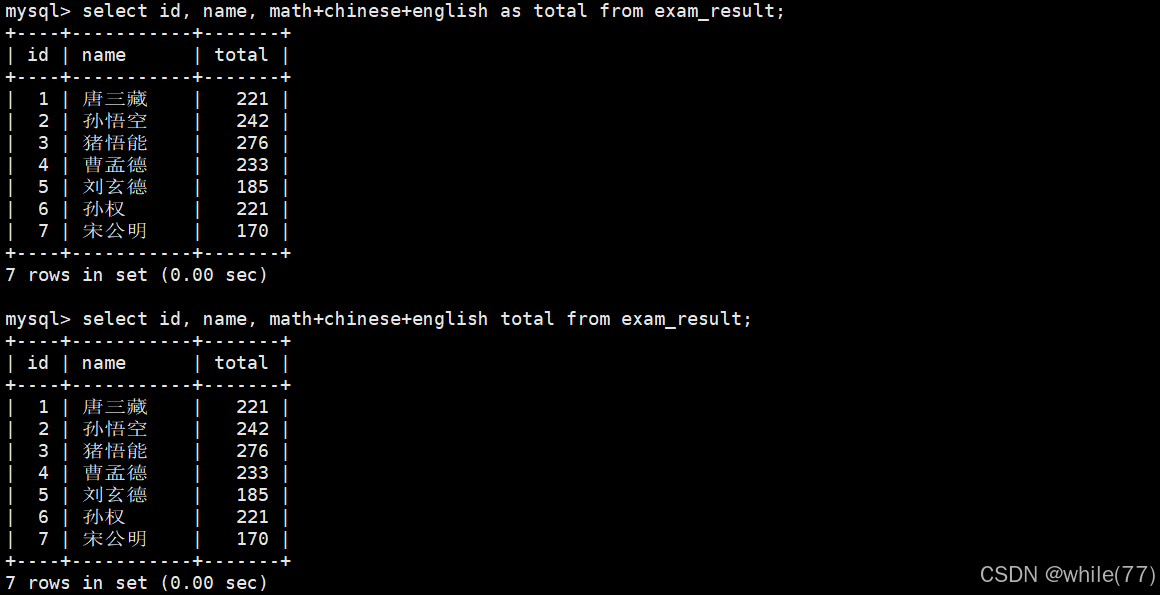
as是可以省略的
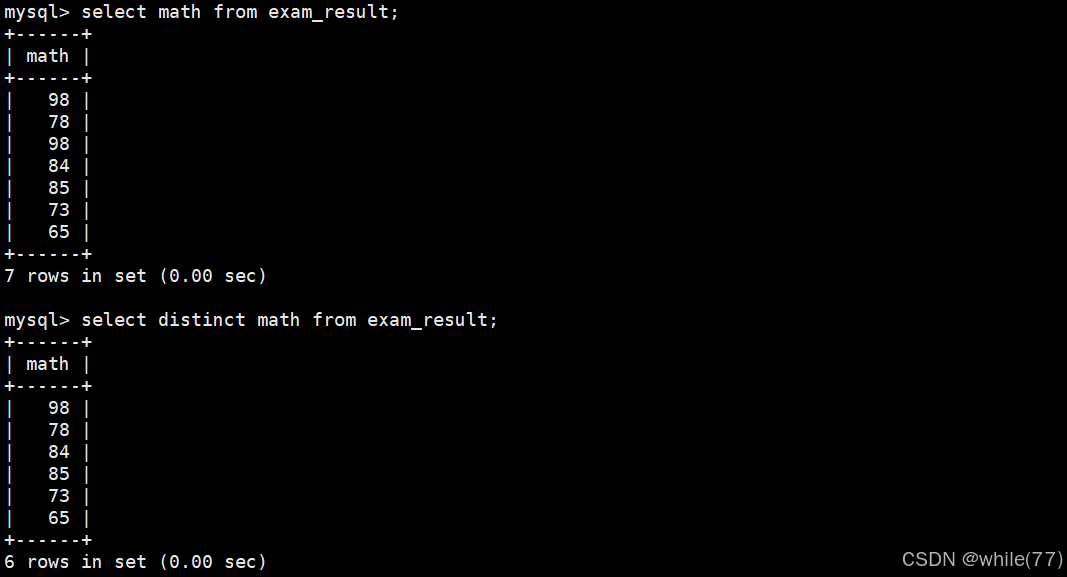
結果去重
可以在select的后面加上一個distinct進行結果去重
where子句
where子句是用來進行條件篩選的。剛剛是對表整體的信息進行篩選,是篩選出要顯示的列,而where子句是篩選出要顯示的行。where子句一般需要配合運算符進行使用。
比較運算符:

邏輯運算符:

解釋一下上面的NULL不安全。在MySQL中,0、'\0'是不等于NULL的,=是不能用于判斷一個值是否等于NULL的。

不等于的兩個都是NULL不安全的。更喜歡使用is null或者is not null來判斷一個值是否是空
我們使用一些案例來看一下where子句如何寫
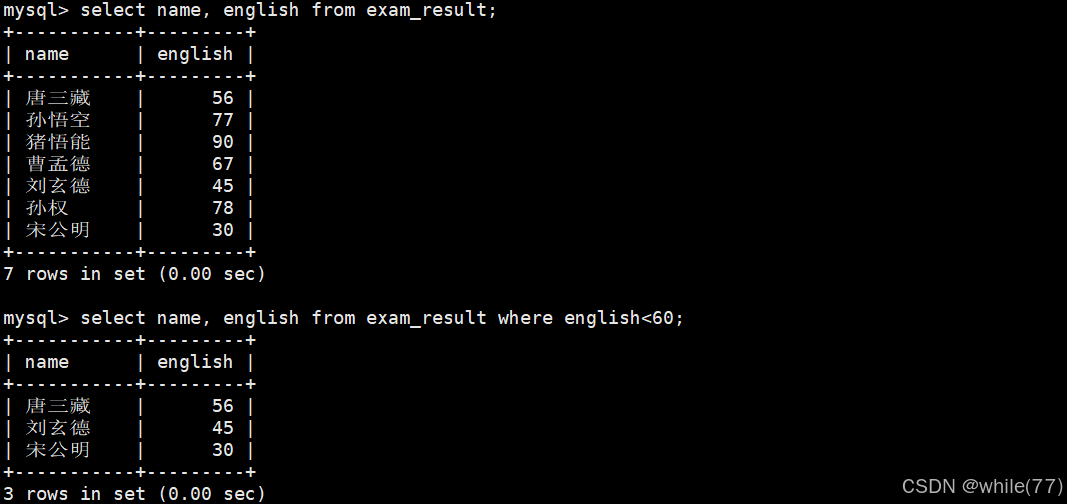
英語不及格的同學及其英語成績
語文成績在[80, 90]分的同學及語文成績
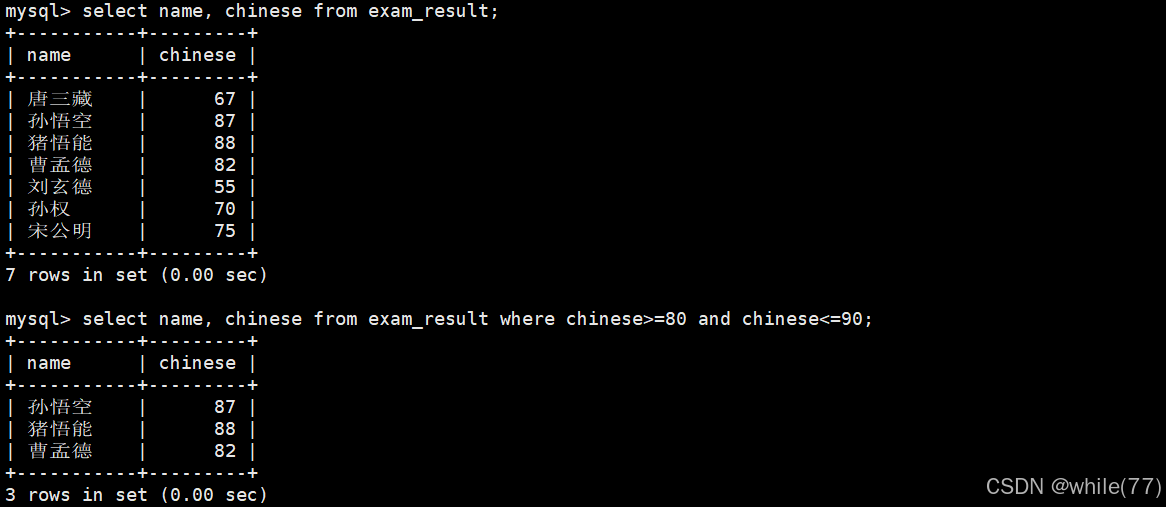
也可以使用between

數學成績是 58 或者 59 或者 98 或者 99 分的同學及數學成績

也可以使用in,in是滿足任意一個就為真

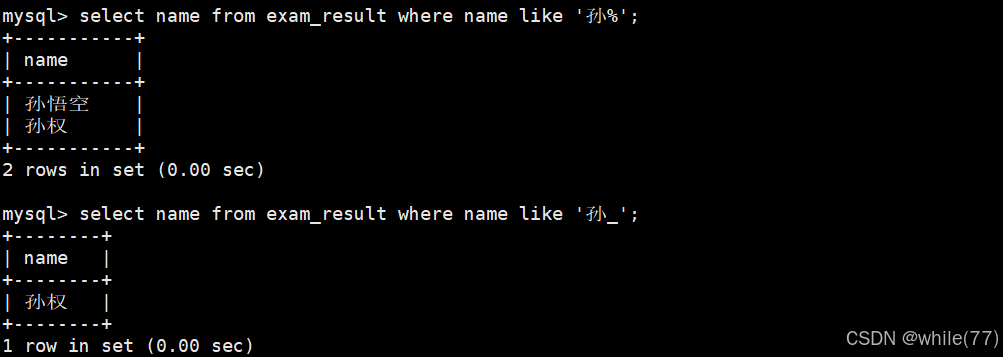
姓孫的同學及孫某同學
剛剛的都是比較是否相等、范圍比較、判斷是否在集合當中,有時候匹配時并不能確定非常細節的字段含義,可能只給了一個很模糊的搜索字段關鍵字,此時就可以使用like。%表示匹配任意多個字符(包括0個),_表示匹配任意一個字符。
語文成績好于英語成績的同學
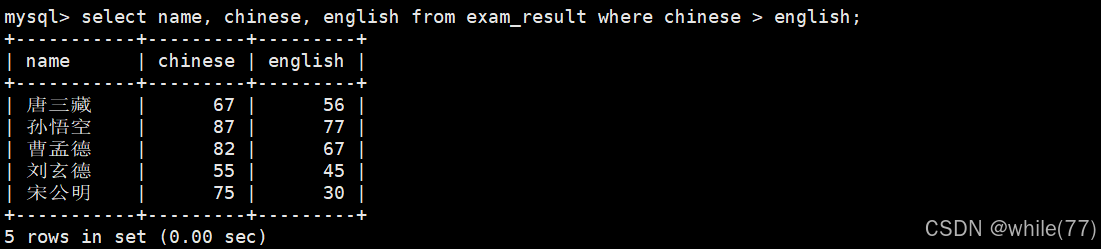
所以,可以一個列與數字比較、一個列與字符串比較、模糊匹配,也可以列與列之間比較
總分在200分以下的同學
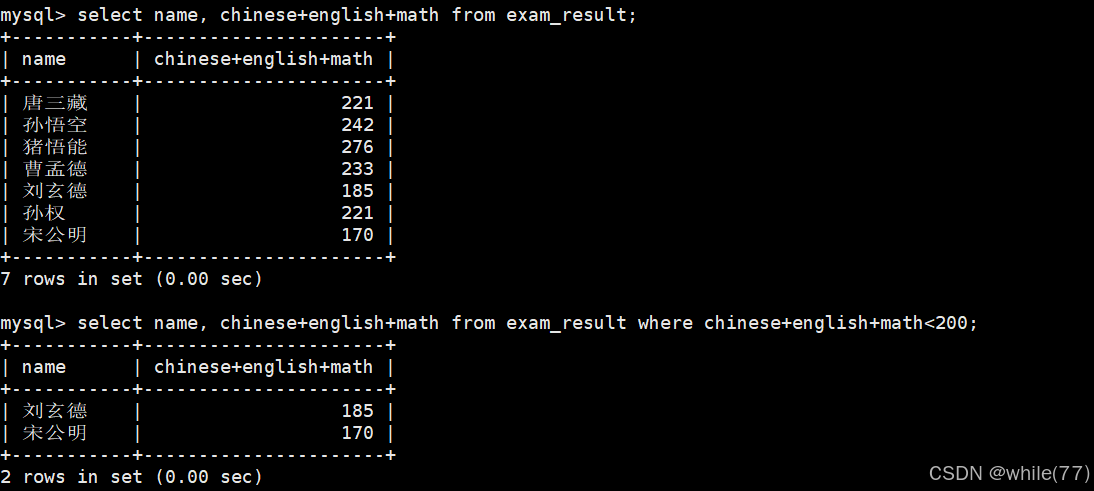
所以,where子句后面是可以跟表達式的。上面的太長了,我們試試給它們取別名。
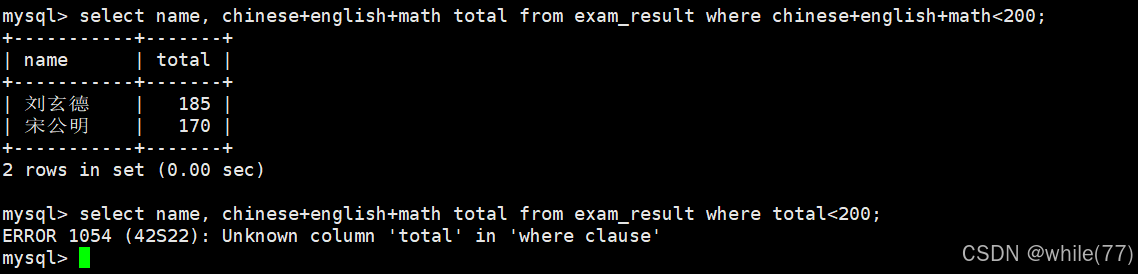
為什么第一句可以,第二句就不行呢?這就需要考慮在select語句中的執行順序了。

數字代表執行順序。所以,在執行到where時還沒有執行到重命名,自然不認識重命名后的值。總結:不能在篩選時進行重命名,因為這屬于是顯示的范疇了。重命名應該是在篩選完了,最后顯示時才弄。
語文成績大于80,并且不姓孫的同學
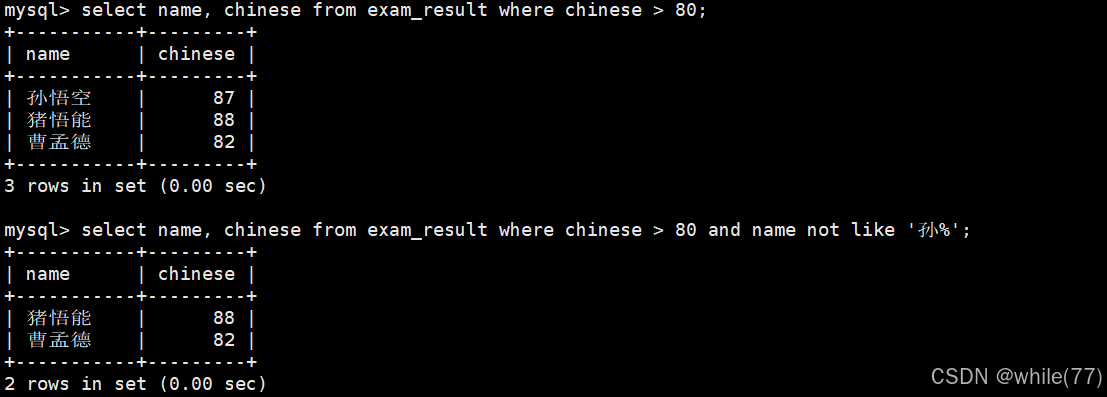
孫某同學,否則要求總成績 > 200 并且 語文成績 < 數學成績 并且 英語成績 > 80

MySQL支持將條件使用一個括號括起來,表示一個條件

NULL的查詢
我們創建一張表,并向其中插入一些包含NULL的值


id為5的name是插入了一個空串
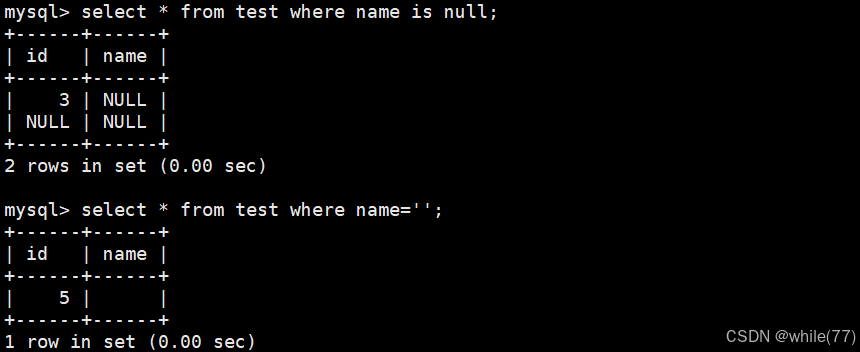
可以看到,空串和null是不同的
結果排序
可以使用order by子句來對查詢出的結果進行排序。asc是升序,desc是降序,默認情況下是升序。注意:沒有 ORDER BY 子句的查詢,返回的順序是未定義的,永遠不要依賴這個順序。沒有使用order by子句時,是根據表中的原始數據進行羅列的,永遠不要依賴這個順序,即使這個順序本身就是有序的。
同樣使用幾個案例來熟悉一下order by子句
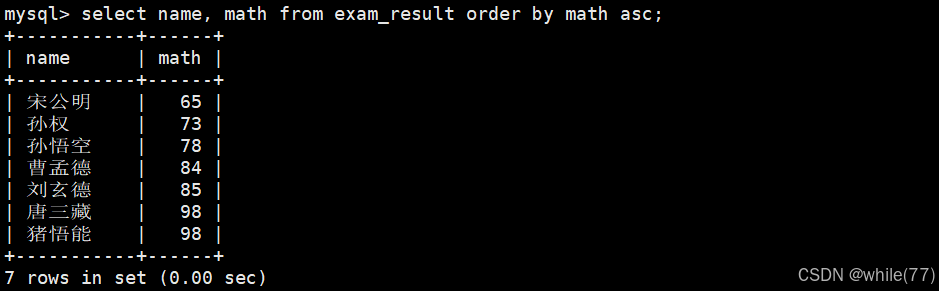
同學及數學成績,按數學成績升序顯示
同學的姓名,排序顯示
我們找一個包含NULL的列的表,看看NULL在排序中的數值大小
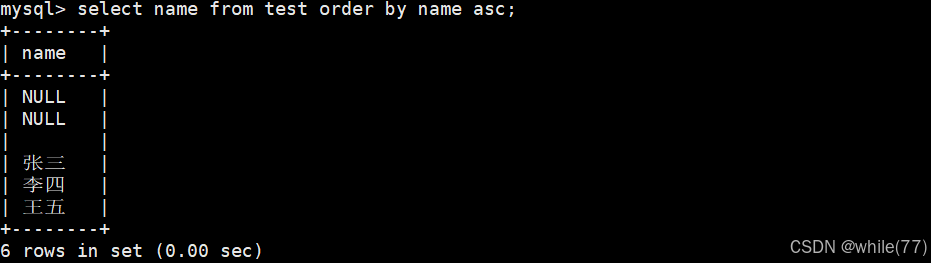
NULL視為比任何值都小
查詢同學各門成績,依次按 數學降序,英語升序,語文升序的方式顯示
這里的意思是,當數學成績相同時,按英語升序排序,當英語成績也相同時,按語文升序排序
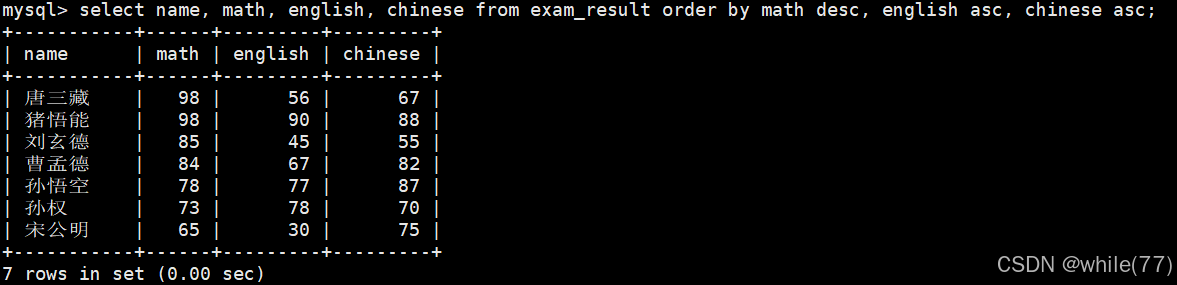
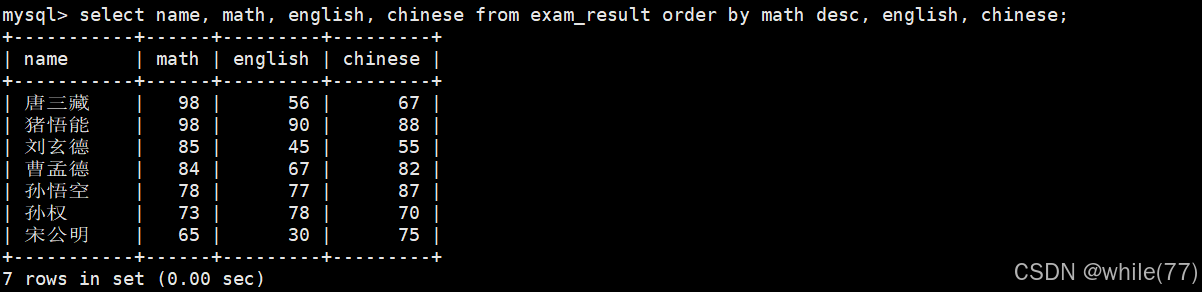
因為默認情況下是升序的,所以可以將一些升序去掉
查詢同學及總分,由高到低
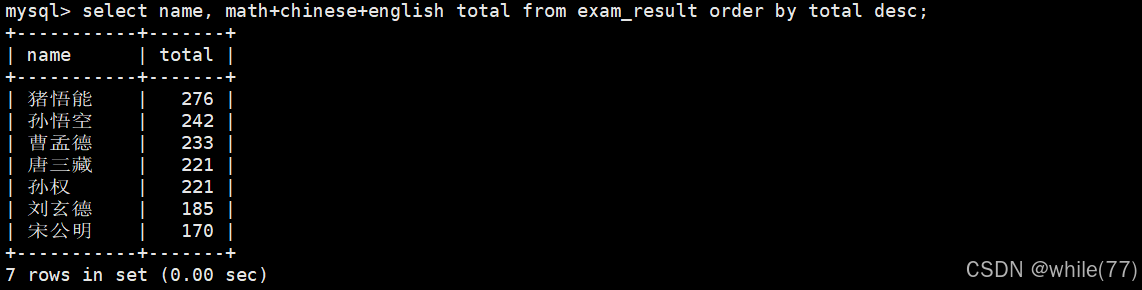
可以看到,使用order by進行結果排序時是可以使用別名的。只有當數據篩選好了之后,才可以進行排序

查詢姓孫的同學或者姓曹的同學數學成績,結果按數學成績由高到低顯示

篩選分頁結果
MySQL中limit子句用于限制select語句返回的結果數量
- 起始下標為0,也就是說select的結果的第一行下標為0
- 從0開始,篩選n條結果
select ... from table_name [where ...] [order by ...] limit n; - 從s開始,篩選n條結果,s是下標,n是步長
select ... from table_name [where ...] [order by ...] limit s, n;
所以,limit 3等同于limit 0, 3 - 從s開始,篩選n條結果,s是下標,n是步長,比第二種用法更明確,建議使用
select ... from table_name [where ...] [order by ...] limit n offset s;
建議:對未知的表進行查詢時,最好加一條LIMT1,辟免因為表中數據過大查詢全表數據導致數據庫卡死
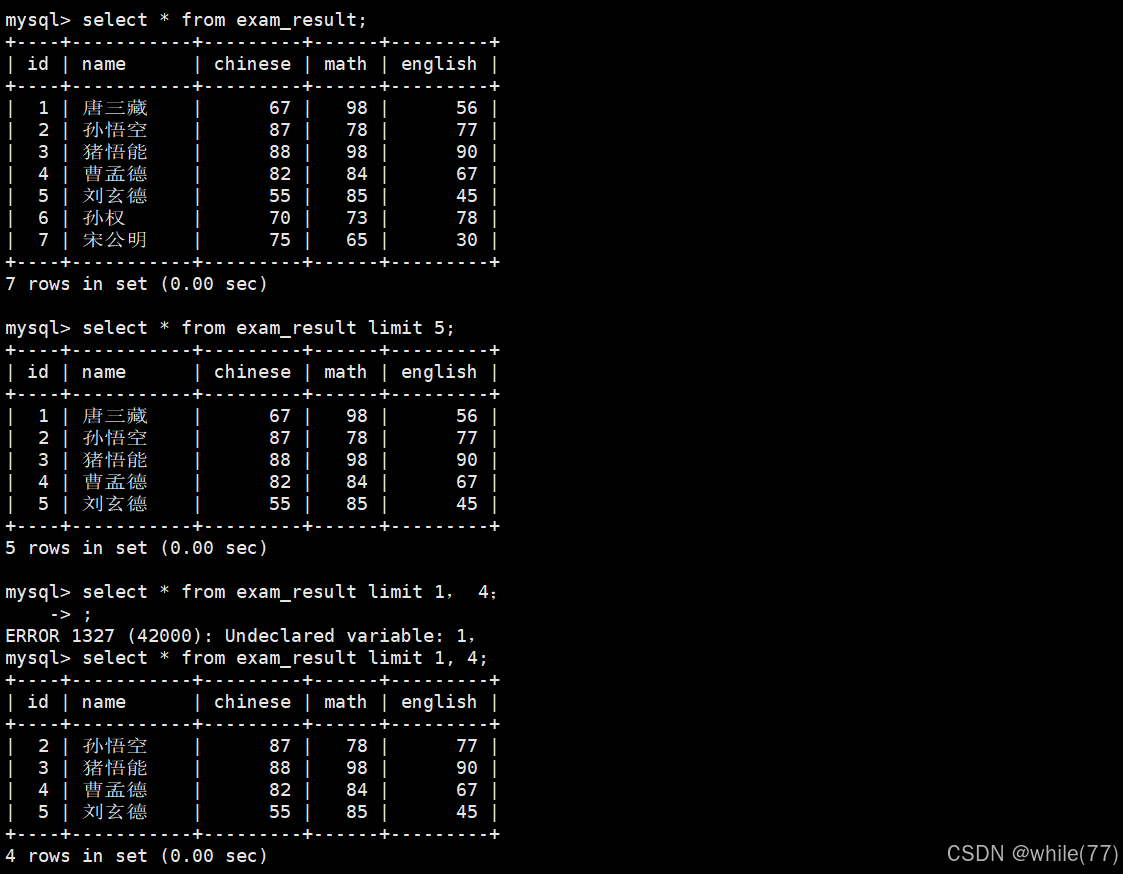
limit可實現簡單的分頁功能
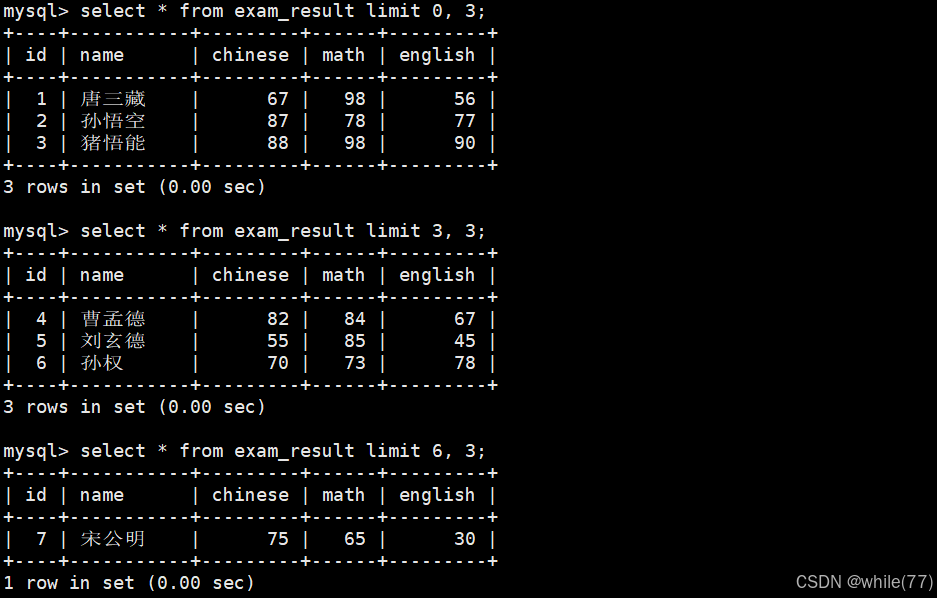
獲取班級總分第一
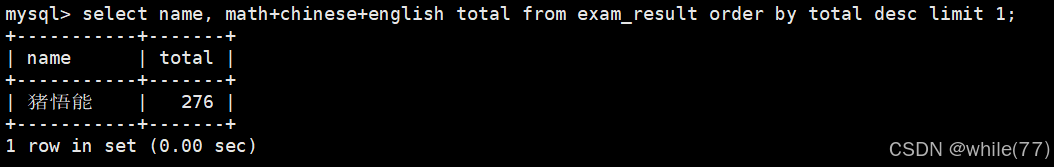
將班級總分大于200分的同學分成3個等級,每個等級最多兩個同學
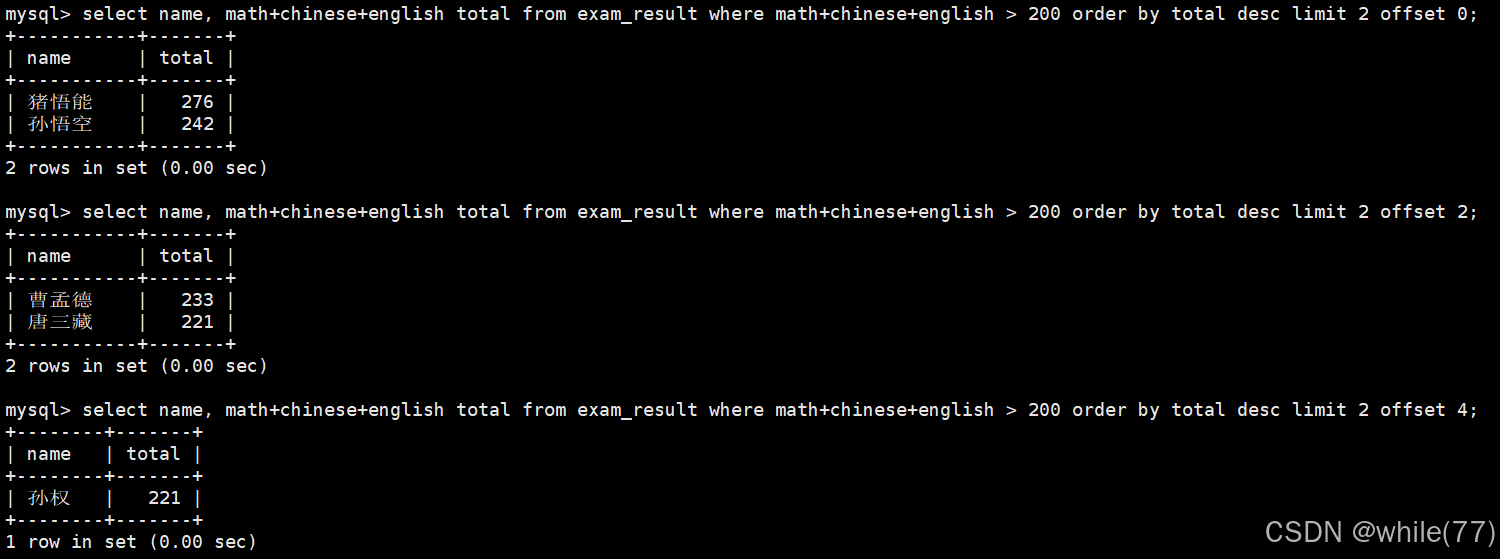
只有當數據準備好了,才要進行顯示,limit的本質就是對顯示的限制

修改(更新)
語法
UPDATE table_name SET column = expr [, column = expr ...]
????????[WHERE ...] [ORDER BY ...] [LIMIT ...]
將指定列的值修改成什么,左側是列名,右側是表達式。一般需要通過where來限定行,否則會將這個表中所有的這一列都修改成這個值
對查詢到的結果進行列值更新
將孫悟空同學的數學成績變更為 80 分
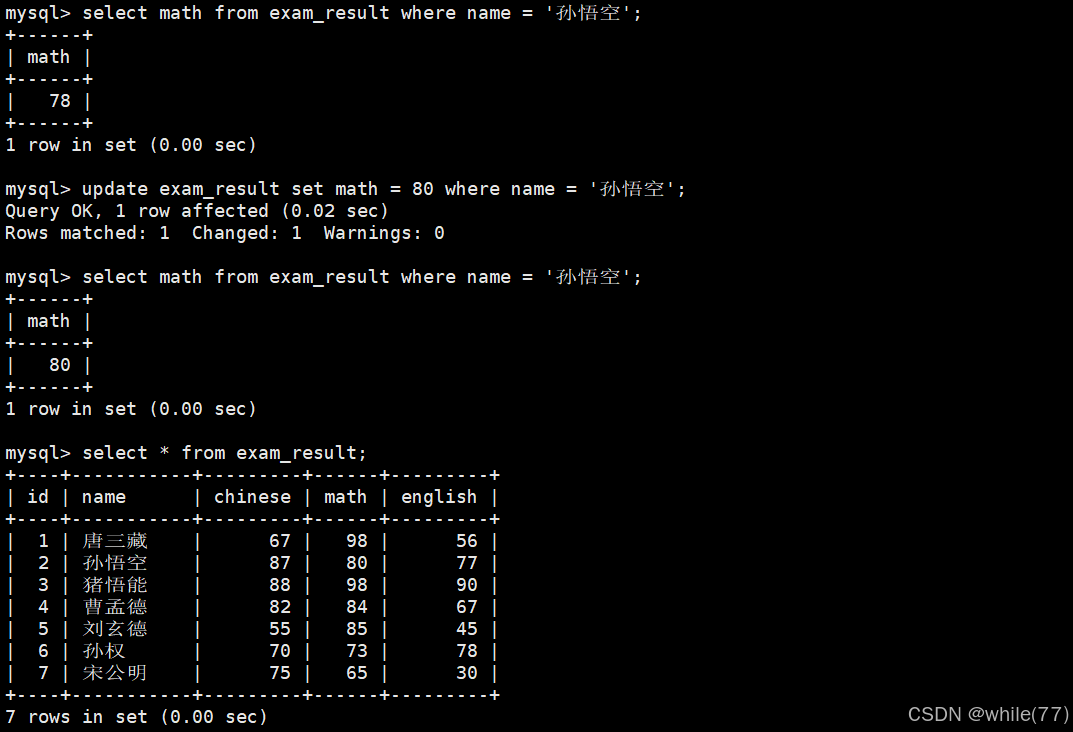
可以看到,此時只有孫悟空的數學變成了80,若沒有where會將這個表中math這一列所有的值都修改成80
將曹孟德同學的數學成績變更為 60 分,語文成績變更為 70 分
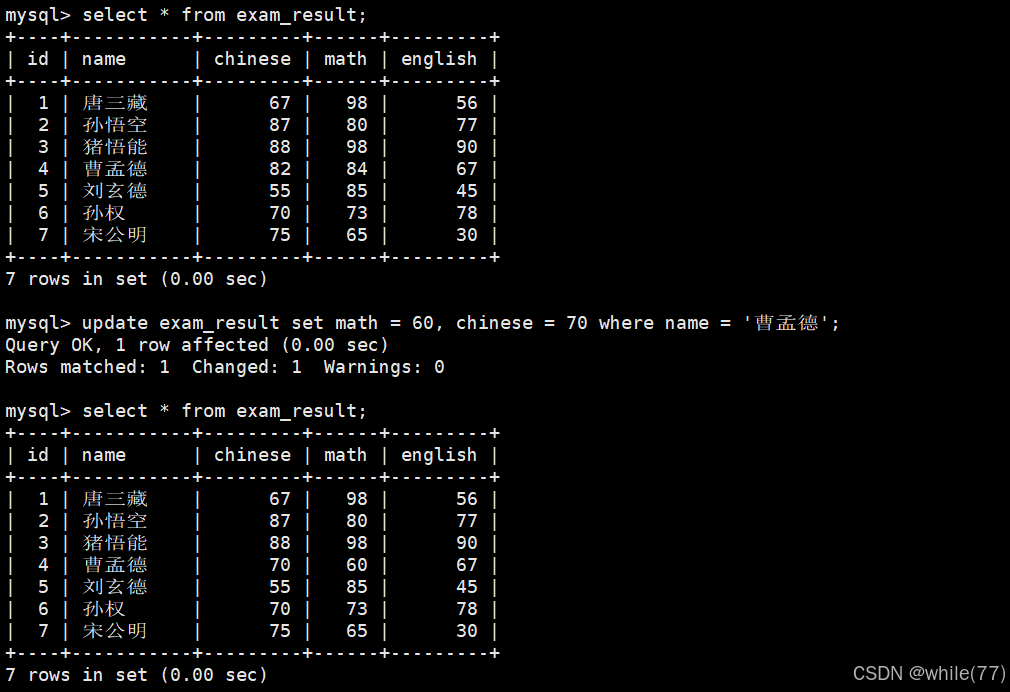
將總成績倒數前三的 3 位同學的數學成績加上 30 分
MySQL是不支持+=的
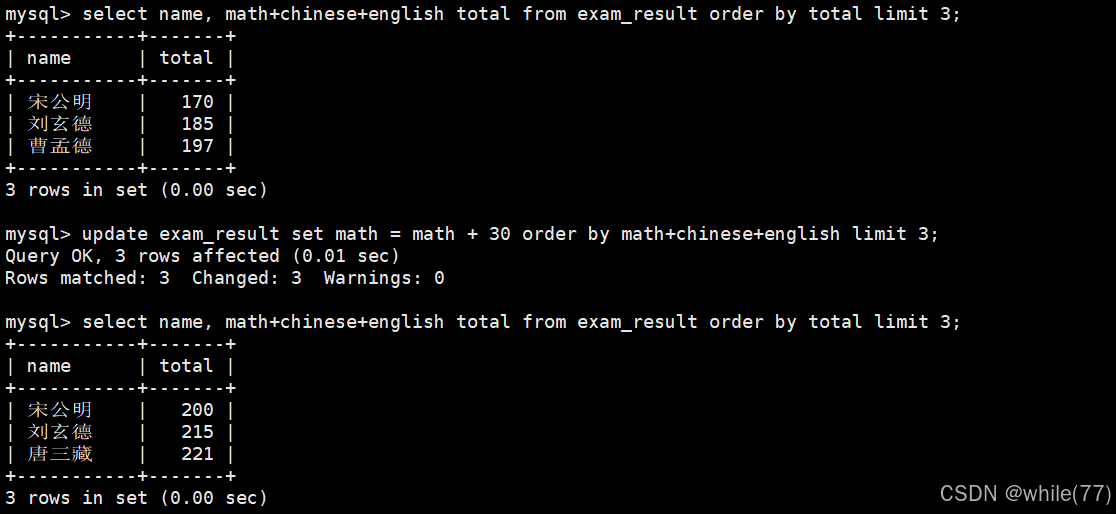
將所有同學的語文成績更新為原來的 2 倍
注意:更新全表的語句慎用
刪除
普通刪除
語法
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
delete from table_name,這樣是刪除整張表的數據,表的結構不變。若想要將表刪除,需要使用drop
刪除孫悟空同學的考試成績
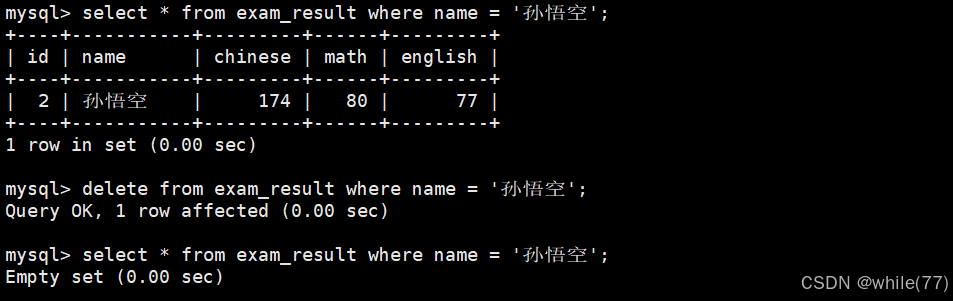
刪除成績倒數第一的同學
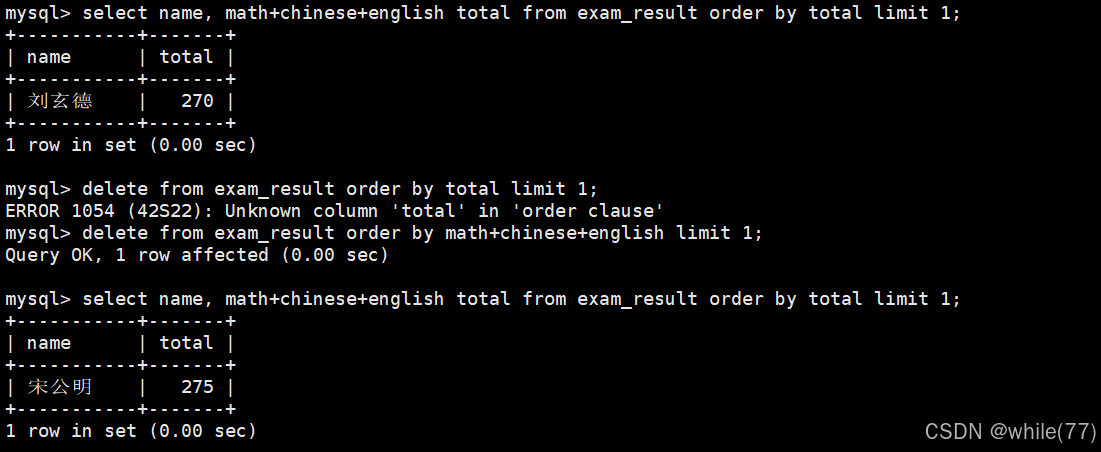
刪除整張表的數據
注意:刪除整張表的數據要慎用
我們先創建一個測試表

并向其中插入一些數據
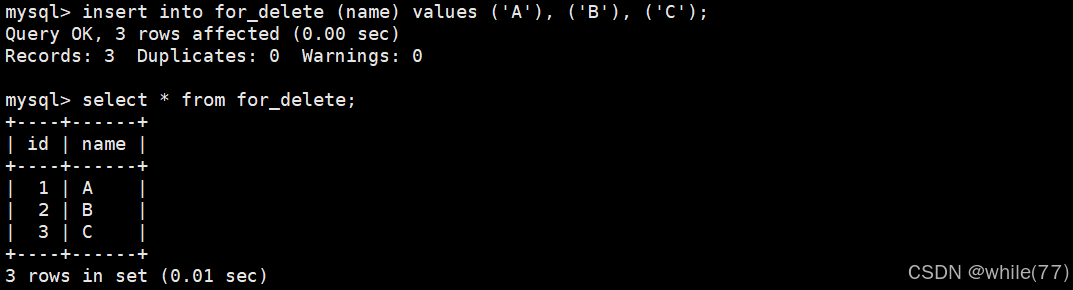

id會自增是因為維護了計數器
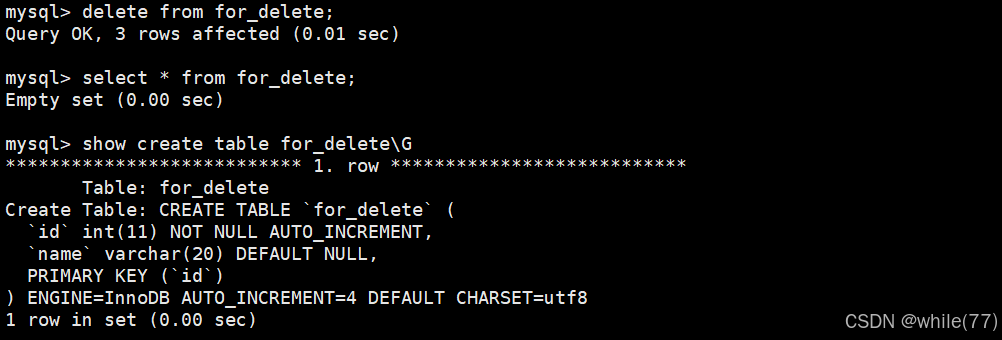
會發現使用這種方式將表內的數據清除后,計數器并沒有變化
截斷表
這是另外一種將表內容清空的方式
TRUNCATE [TABLE] table_name
注意:這個操作一定要慎用
先準備一個測試表

并向其中插入一些數據
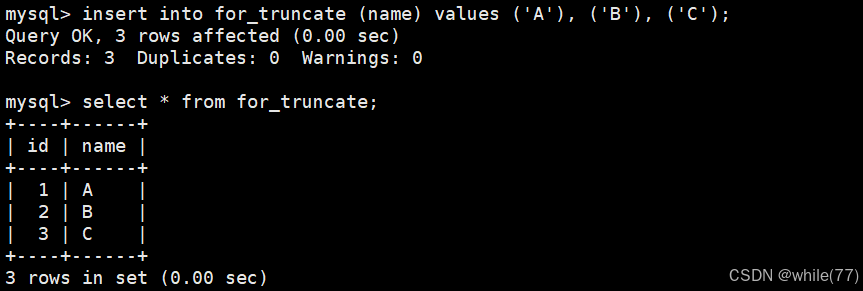
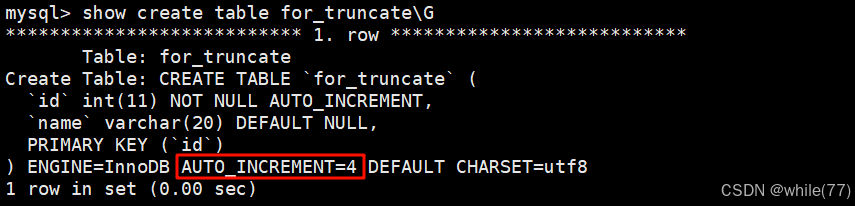
現在使用truncate將表清空
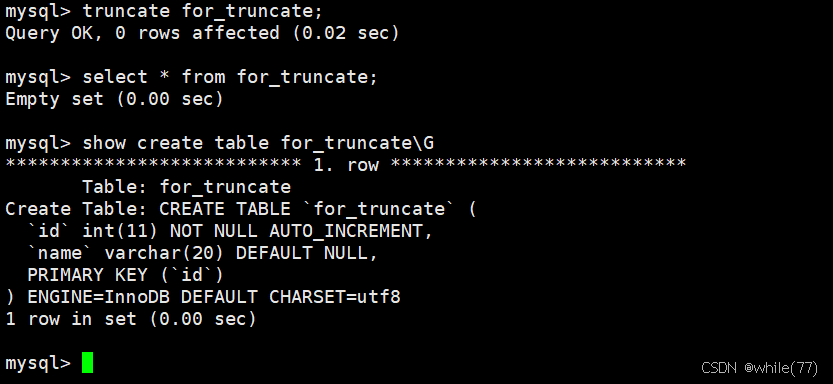
這種清空表的方式,同樣不會改變表的結構,但是會將計數器重新置位
truncate與delete的區別
- truncate只能對整表操作,不像delete一樣針對部分數據操作
- truncate會重置auto_increment項
- truncate不走事物,直接將表的內容清空,delete會先變成事物,再將表的內容清空,所以,truncate更快
插入查詢結果
INSERT INTO table_name [(column [, column ...])] SELECT ...
將從其他表中查詢到的結果插入到insert后面的表中。屬于是SQL語句的組合使用
刪除表中的重復數據
我們先創建一個測試表,并向這個表中插入一些數據
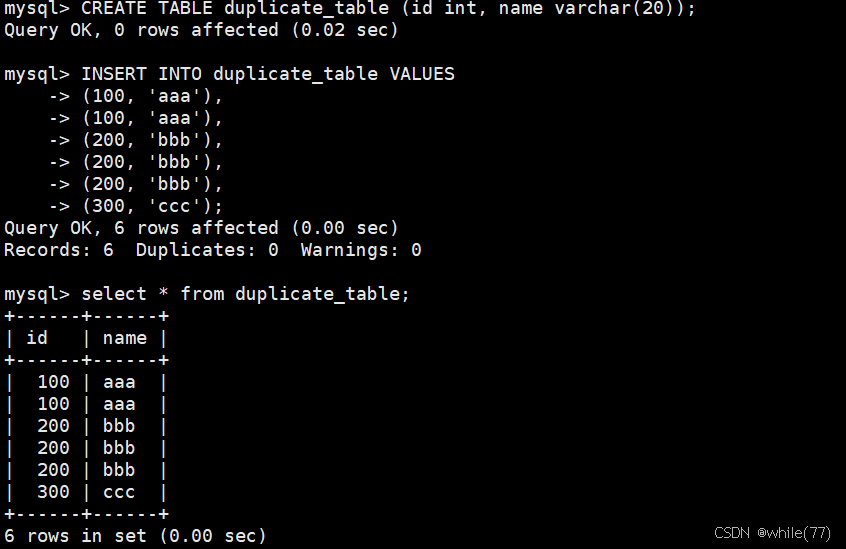
此時可能會想到
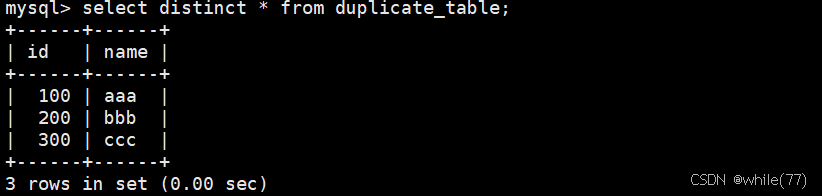
這樣明顯是不行的,因為這樣只是查詢時去重,表內的數據是沒有去重的
我們此時想去重,可以再創建一張新表,將現在這張表查詢去重后的結果插入到新表中。再將原來的表重命名,并將新表的名字改成原來表的名字
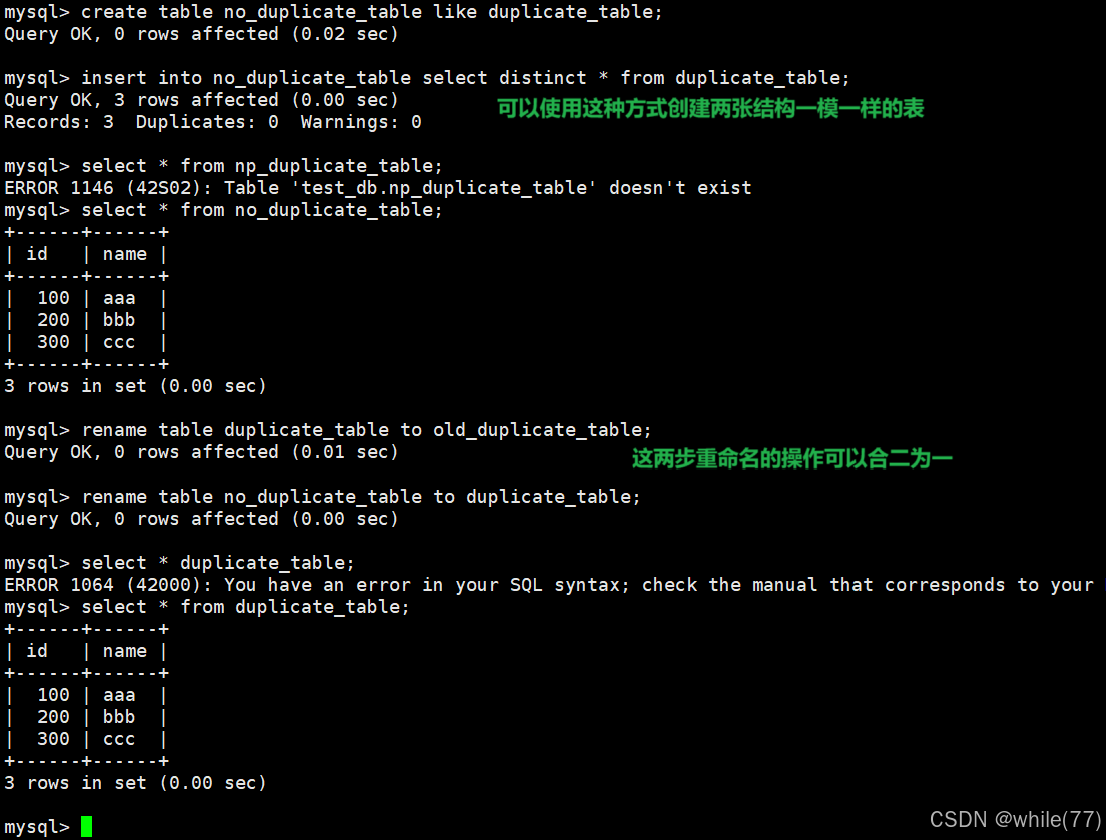
為什么最后要使用rename的方式進行,而不是直接修改目標表呢?
MySQL建一個數據庫就是建一個文件夾,創建一個表就是創建一個文件(在C/C++中就是open/fopen),就是學指令時的touch。重命名調用的就是rename這樣的系統調用,mv也一樣。現在想將一個文件以原子的方式上傳Linux的某目錄下,這個文件可能比較大,不會一下上傳完成,若直接上傳到這個目錄下不一定是原子的。一般會將這個為文件上傳到一個臨時目錄下,全部上傳完成后,再將這個文件move到指定的目錄下面,因為move是原子的。就是單純地相等一切都就緒了,然后統一放入、更新、生效等。
聚合函數
| 函數 | 說明 |
| COUNT([DISTINCT] expr)? | 返回查詢到的數據的數量 |
| SUM([DISTINCT] expr) | 返回查詢到的數據的總和,不是數字沒有意義 |
| AVG([DISTINCT] expr) | 返回查詢到的數據的平均值,不是數字沒有意義 |
| MAX([DISTINCT] expr) | 返回查詢到的數據的最大值,不是數字沒有意義 |
| MIN([DISTINCT] expr) | 返回查詢到的數據的最小值,不是數字沒有意義 |
?聚合是有條件的,一定要保證列的數據類型是可以被聚合的
計算班級共有多少同學
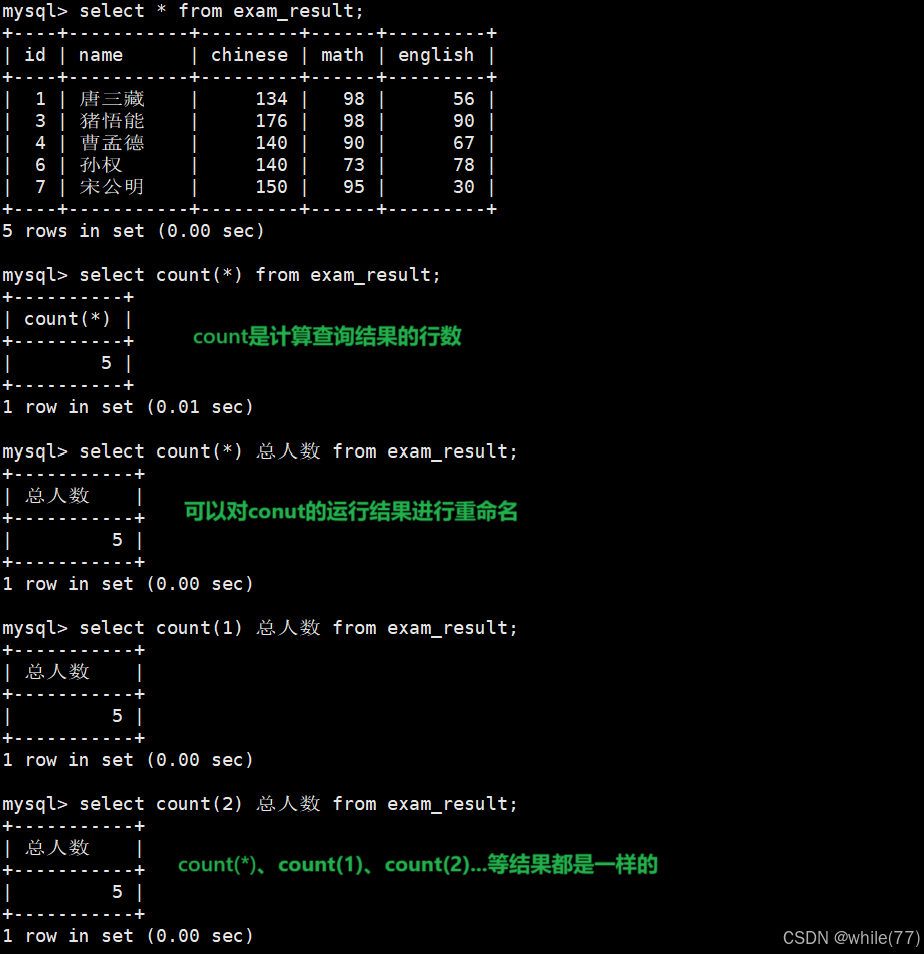
統計本次考試的數學成績個數
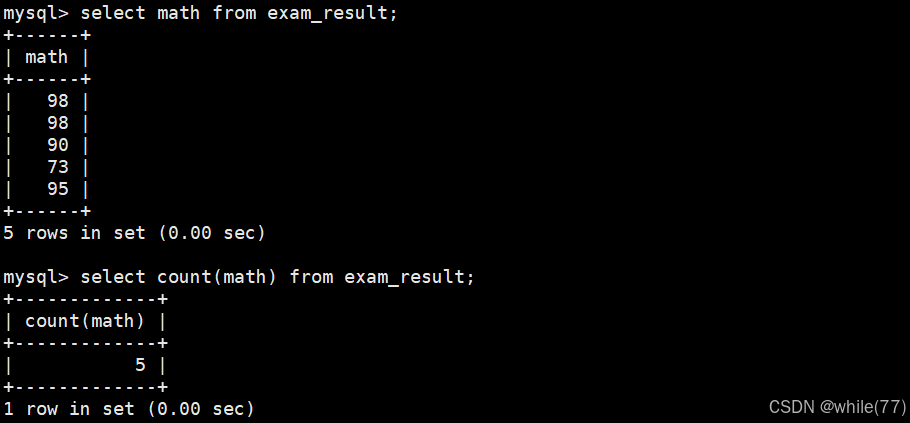
因為數學成績中有重分的,所以直接統計肯定是不行的,需要去重

這樣是對聚合后的結果進行了去重,聚合后的結果就是一個數字,沒有必要去重
我們應該是對math去重,去重后再讓其聚合

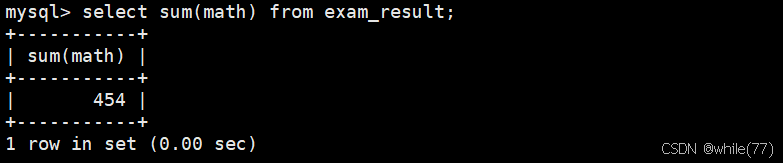
統計數學成績總分
統計英語成績不及格的人數

統計數學成績的平均分
方法一

方法二

獲取英語的最高分

如果我們向要同時獲取英語最高峰和這個最高分的名字

像這樣是會報錯的。聚合是需要先將數據篩選出來,并且保證數據能夠被聚合才能使用的,name的數據類型不允許被聚合,此時需要先分組再聚合。若想知道英語最高分是誰,應該orderby+limit
分組查詢
在select中使用group by 子句可以對指定列進行分組查詢
select column1, column2, .. from table group by column;
分組的目的是為了分組之后,方便進行聚合統計。是先將數據拿到,然后分組,分組完成后進行聚合統計。如我們想統計一下班級中男生、女生的數學最高分是多少,此時就可以將男生、女生分成不同組,再進行聚合統計
我們可以將分組,理解成"分表"。也就是說,將根據某一條件分組后的每一個結果,都看成是一個表。并且我們前面查詢后的結果等,雖然只是表內的一部分數據,我們也可以看成是一張完整的表
我們先導入我們要進行實驗的數據庫

傳輸完成后就能看到當前目錄下就有了.sql文件
![]()
再使用這個語句就可以將這個.sql里面的SQL在MySQL中執行一遍
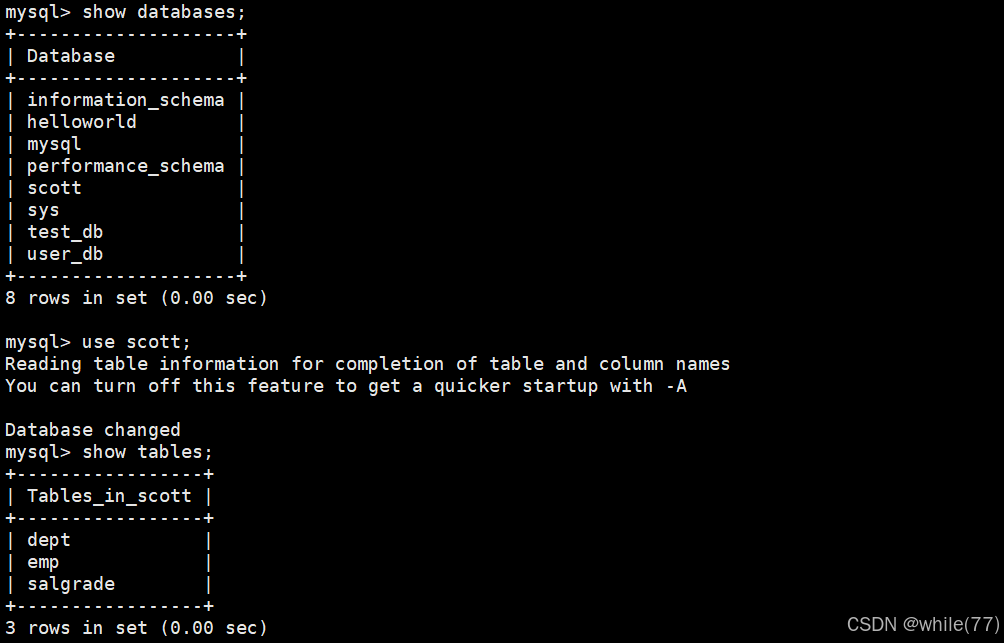
此時就多了一個數據庫。這個數據庫中有3個表。dept是部門信息表,emp是員工信息表,salgrade是員工薪資等級表
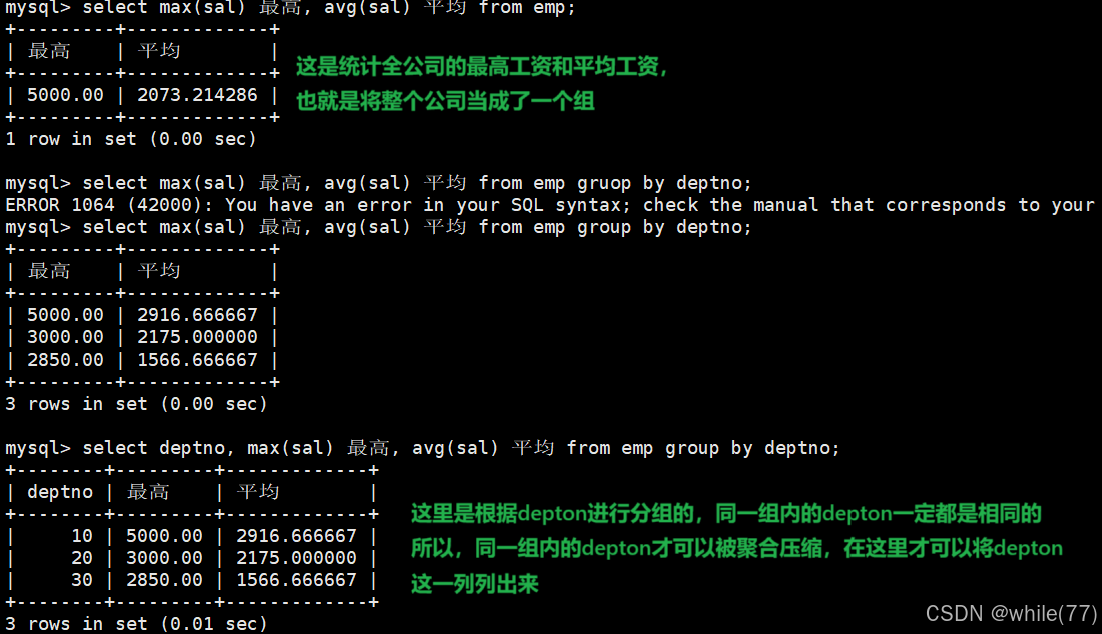
顯示每個部門的平均工資和最高工資
我們需要根據部門將表劃分成多個部分,然后針對每一個部分進行統計
顯示每個部門的每種崗位的平均工資和最低工資
我們需要先根據部門進行分組,再針對每個部門的不同崗位進行分組,然后再統計
group by后面是可以跟多個列名稱的,表示根據多個條件進行分組
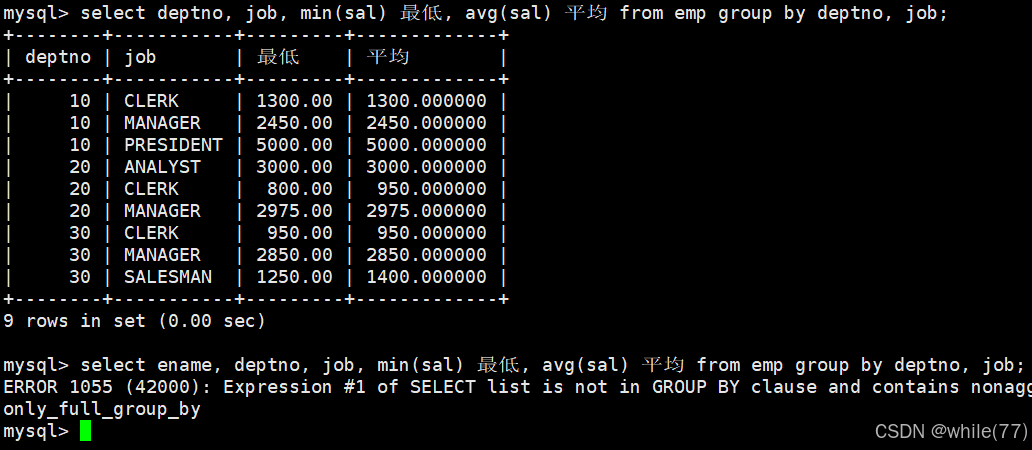
會發現加上員工的名稱就會報錯,因為分到最下面,部門、崗位是相同的,這兩個可以進行聚合壓縮,但是組內每個人的姓名是不同的,不能進行聚合壓縮。當我們涉及到聚合壓縮時,只有出現在group by后面的列名稱和聚合函數可以放在select后面。
顯示平均工資低于2000的部門和他的平均工資
第一:需要先聚合統計出每個部門的平均工資
第二:對聚合統計的結果進行判斷
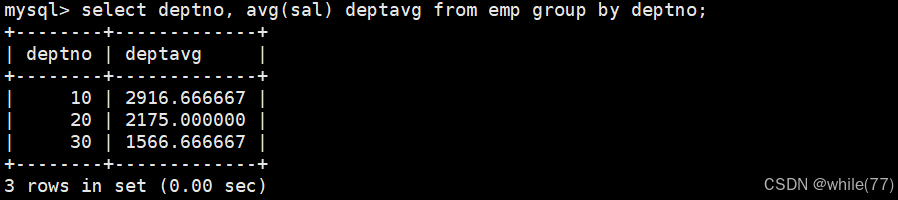
這是聚合出來的結果,接下來需要對聚合的結果進行判斷。對聚合的結果進行判斷就需要使用having。前面的先執行,然后再執行having,所以是可以使用別名的
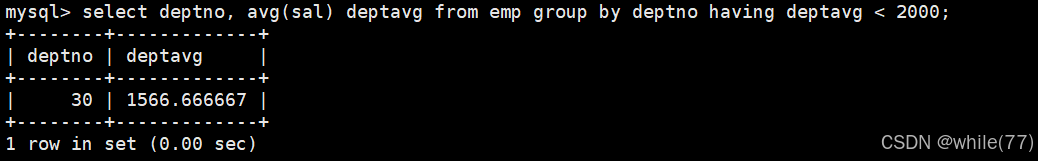
having是對聚合統計后的數據進行條件篩選的
having? vs? where
having和where都可以進行條件篩選,但是兩者是完全不同的條件篩選

我們將上面SQL語句的having改成where會發現就不行了

會發現having完全是可以充當where的功能的。因為我們前面說了,我們將分組后的結果當成一張表,而emp本身就是一張表
假設我們現在要:顯示平均工資低于2000的部門和他的平均工資,且員工SMITH不參與


所以,having和where都是進行條件篩選,但是條件篩選的階段是不同的
最后再強調一遍:不要單純的認為,只有磁盤上表結構導入到mysql,真實存在的表,才叫做表;中間篩選出來的,包括最終結果,在我看來,全部都是邏輯上的表!
引用、內聯函數、nullptr宏)





)




)

---鏈式棧)



: 電源管理體系完整梳理:I2C、Regulator、PMIC與Power-Domain框架)

—矩陣)