馬不停蹄地來到了第十二章:計算性能……
感覺應該是講并行計算方面的,比如GPU、CPU、CUDA那些。
第十二章:計算性能
12.1 編譯器和解釋器
這里先提出了命令式編程和符號式編程的概念。
命令式編程VS符號式編程
目前為止,本書講的主要是命令式編程,通過直接的方式改變程序的狀態,比如"+"、"print"這些,而符號式編程主要通過一些接口,主要關注任務的目的。
問了下ai:命令式編程主要關注每一步要做什么,改變程序狀態一步步實現具體功能,達到預期結果;而符號式式編程關注數學符號和邏輯表達式的操作,主要用于邏輯推理。
命令式編程效率不高,因為編譯器一步步執行這些操作,卻不關注程序整體架構,比如一個函數可能連續調用兩次,如果在一個或多個GPU上執行,則開銷可能會非常大,并且每走一步都要保留以后可能不會用到的值……總之走一步看一步總是很麻煩的。
考慮另一種符號式編程,它不會馬上計算每一步,只在完全定義了整個過程后才執行計算,深度學習的TensorFlow框架就使用了這種編程。
符號式編程流程:
①定義計算流程
②將流程編譯成可執行程序
③給定輸入,調用編譯好的程序執行
而非命令式編程的一步步執行,所以這允許了大量優化,因為編譯器在執行之前就可以看到完整的代碼,在發現之后不需要某個變量后編譯器就可以釋放它的內存。
但之前我們一般都是用更好使用更好調試的命令式編程,因為無論是打印中間變量還是使用調試工具命令式編程都更簡單。
符號式編程優點在效率高,程序容易移植,甚至可以將python程序移植到與python無關的格式中,使其在非python環境下運行。
混合編程
深度學習編程框架們有使用符號式也有使用命令式的,目前主流的Pytorch(命令式)和Tensorflow(混合式)都有向對方靠攏的趨勢。
作者這里拿Pytorch舉例(我的書是Pytorch版本的,電子版有Tensorflow版本)。
先構建一個普通MLP:
import torch
from torch import nn
from d2l import torch as d2l# 生產網絡的工廠模式
def get_net():net = nn.Sequential(nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, 2))return netx = torch.randn(size=(1, 512)命令式編程版本:
net = get_net()
net(x)符號式編程:
net = torch.jit.script(net)
net(x)測試兩種編程方法的性能:
#@save
class Benchmark:"""用于測量運行時間"""def __init__(self, description='Done'):self.description = descriptiondef __enter__(self):self.timer = d2l.Timer()return selfdef __exit__(self, *args):print(f'{self.description}: {self.timer.stop():.4f} sec')net = get_net()
with Benchmark('無torchscript'):for i in range(1000): net(x)net = torch.jit.script(net)
with Benchmark('有torchscript'):for i in range(1000): net(x)結果
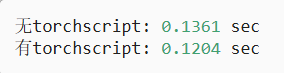
并且符號式編程要求先定義并編譯程序,編譯程序的好處之一是可以將模型及其參數序列化保存到磁盤,這樣保存的訓練好的模型可以遷移到其他設備,與其他前端編程語言結合。
(看到這里想到前幾天做的情感計算實驗,文件就是有前端有后端,后端訓練模型并保存,前端只需調用模型就行,這樣提高了計算效率)
12.2 異步計算
Python是單線程的,它不擅長處理并行和異步代碼。
(怪不得并行計算課的代碼要用C語言實現……)
在深度學習框架中,Tensorflow采用異步編程模式提高性能,Pytorch則采用Python自有的調度器實現不同性能的權衡,GPU操作默認情況下是異步的,調用一個使用GPU的函數時,操作會在特定設備上排隊,但之后控制權會立刻返還給使用者,不需要等待GPU完成這個任務再執行后續代碼。這允許我們并行執行更多運算。
異步編程通過主動減少計算需求和相互依賴,開發更高效的程序。
作者再次做了個實驗比較Pytorch(GPU上)和Numpy中矩陣相乘花費的時間:
with d2l.Benchmark('numpy'):for _ in range(10):a = numpy.random.normal(size=(1000, 1000))b = numpy.dot(a, a)with d2l.Benchmark('torch'):for _ in range(10):a = torch.randn(size=(1000, 1000), device=device)b = torch.mm(a, a)結果:
![]()
因為Numpy的矩陣乘法是在CPU上執行,而Pytorch在GPU上,默認情況是異步的。
其實,Pytorch可以看作分為前端和后端,用戶通過Python調用Pytorch,這是前端,而執行計算的后端主要由C++實現。用戶調用Pytorch后,操作被傳到后端執行,后端有自己的多線程,所以Pytorch支持異步計算。
注意:如果要按上述方式工作,后端必須跟蹤整個計算圖中各步驟直接依賴關系,因此不可以并行化相互依賴的工作。
這就是為什么編程時要主動減少相互依賴的操作。
作者舉了一個很直觀的例子:
比如這樣一段代碼:
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z內部是這樣運行的:
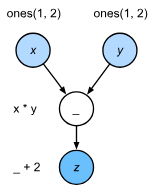
兩個構造矩陣的操作可以并行實現,意思是前端只需要將任務返回后端隊列,Python前端等待C++后端線程完成計算結果,而不需要實際計算,這樣任務就可以并行計算。(前端Python的性能對計算任務沒有什么影響)
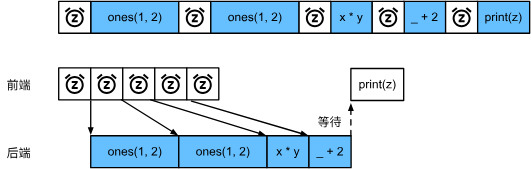
總而言之,異步產生了一個相當靈活的前端。
電子書上還有一個直觀的例子:

12.3 自動并行
?深度學習框架會在后端自動構建計算圖。
比如上面那個例子中,初始化兩個張量這個步驟,系統就可以選擇并發運行它們。
模擬并行計算
在有多個計算設備的情況下,選擇并發運行就可以大大提高效率,接下來作者用代碼模擬了系統內部并發和不并發執行任務:
def run(x):return [x.mm(x) for _ in range(50)]
假設這個是我們的任務,也就是讓 x 自乘50次。
然后設置兩個 x ,分別放在兩個GPU設備上。
devices = d2l.try_all_gpus()
x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])torch.cuda.synchronize函數會等待當前設備計算執行結束才往后執行。
于是可以寫出串行代碼:
with d2l.Benchmark('GPU1 time'):run(x_gpu1)torch.cuda.synchronize(devices[0])with d2l.Benchmark('GPU2 time'):run(x_gpu2)torch.cuda.synchronize(devices[1])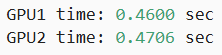
刪除倆任務之間的torch.cuda.synchronize,就可以實現倆GPU并行。
并行代碼:
with d2l.Benchmark('GPU1 & GPU2'):run(x_gpu1)run(x_gpu2)torch.cuda.synchronize()![]()
可以看出,總執行時間小于兩部分執行時間的總和。
所以可以看出,深度學習框架中會默認讓兩個任務并行執行,提高計算效率。
模擬設備間通信
然后作者又用代碼模擬了一個設備之間的通信。
之前我們可以將一個數據遷移到另一個設備上,那么數據可不可以邊計算邊遷移呢?
def copy_to_cpu(x, non_blocking=False):return [y.to('cpu', non_blocking=non_blocking) for y in x](利用Pytorch中的to函數將某個數據遷移設備)
按照之前的樣子,寫一個串行執行倆步驟的代碼:
with d2l.Benchmark('在GPU1上運行'):y = run(x_gpu1)torch.cuda.synchronize()with d2l.Benchmark('復制到CPU'):y_cpu = copy_to_cpu(y)torch.cuda.synchronize()
這樣的話效率不高,但是想想其實可以邊運算邊遷移,將運算完的部分先遷移過去。
這時候就要to函數中的non_blocking參數了,當這個參數為true時,就可以在不需要同步時調用同步,從而實現一邊運算一邊遷移。
并行代碼:
with d2l.Benchmark('在GPU1上運行并復制到CPU'):y = run(x_gpu1)y_cpu = copy_to_cpu(y, True)torch.cuda.synchronize()![]()
這樣做就可以讓系統先將運算完的部分先遷移,減少運行時間。
這兩個任務看著簡單,但在實際應用中要通過Python實現還是非常復雜的,比如一個簡單的兩層感知機在兩個GPU和一個CPU下運行的例子:
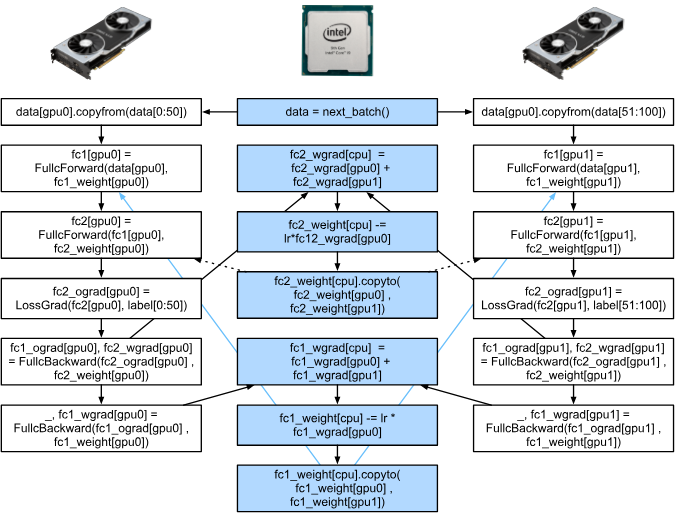
手動調度其實是非常復雜的,這就體現了基于圖的計算后端優化的優勢了。
12.4 硬件
這一節主要是講計算機組成方面的內容,理解計算機內部的組成對于實現高性能的算法有很大幫助。
首先,計算機是由以下關鍵部分組成的:
- 中央處理器(CPU):運行計算機的大部分功能,如操作系統,也能夠執行給定的程序。
- 主存(RAM,也叫內存):用于存儲計算結果,使CPU可以較快訪問到數據。
- 以太網連接:網絡。
- 高速擴展總線:用于連接GPU,通常用更高級的方式拓撲連接。
- 持久性存儲設備(輔存):固態硬盤(SSD)、硬盤驅動器(HDD),用高速擴展總線連接,提高傳輸速率。
接下來我們一一講解這些組成。
1. 高速擴展總線
其中高速擴展總線由多個直連到CPU的通道組成,將CPU與網絡、GPU、存儲連接到一起。
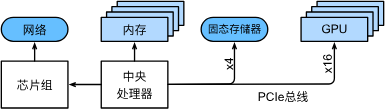
在計算機上執行代碼時,需要將數據移到處理器(CPU或GPU)上計算,然后將結果移到主存或輔存上,為了保證無縫銜接,就要擁有一個較快的高速擴展總線;如果是在多臺設備上運行,就要有一個較快的以太網連接。
2. 內存
在讀取內存方面有兩種方式,一種是隨機讀取,直接跳到指定位置,只讀取需要的部分數據;一種是突發讀取,以連續的快速讀取完成更大片的數據的訪問。在數據連續存儲的情況下,突發讀取效率快得多。
GPU對內存存取速率的要求更高,內存也比CPU小。
3. 存儲器
對于存儲器,關鍵特性是帶寬和延遲。
硬盤驅動器(HDD)比較古早,最大的優點是便宜,眾多缺點之一是災難性故障和高讀取延遲。
主要原因是磁盤轉速就那么快,如果太快會因為施加在盤片的離心力過大而破碎,性能很難有較大提升,對于較大數據集很難存儲。
固態驅動器(SDD)就可以持久并且更快存儲信息,它的設計方式使它必須滿足一些條件:
- 以塊的方式存儲信息。而塊只能作為一個整體寫入,需要耗費大量時間,按位寫入時性能會非常差。
- 存儲單元磨損較快,所以不適合用于交換分區文件和大型日志文件。
- 帶寬大幅增加,必須與高速擴展總線相連。
還有一種存儲器是云存儲,虛擬機的存儲在數量和速度上可以與用戶需求相匹配。
4. CPU
中央處理器是計算機的核心。
它的關鍵組成部分有處理器核心(用于執行機器代碼)、總線(用于連接不同組件)、緩存cache(緩解內存到核心間的傳輸速率)、向量處理單元(用于輔助高性能線性代數和卷積計算)。
每個處理器都由復雜的組件構成,前端加載指令并嘗試預測用哪條路徑,然后指令從匯編代碼解碼為微指令(更低級別的操作),最后才由實際核心處理。
通常執行指令的核心可以同時執行多個操作,所以高效的程序可以在每個時間周期執行多條獨立指令。
在這里我們可以知道為什么對任務進行向量化,而不是單個單個求解效率會高很多。
為了滿足需求,CPU需要在同一個時鐘周期內執行許多操作,這種執行方式是通過向量處理單元實現的,處理單元可以執行單指令多數據(SIMD)操作。
比如八個任務要求將兩個整數相加,就可以在一個時鐘周期完成:
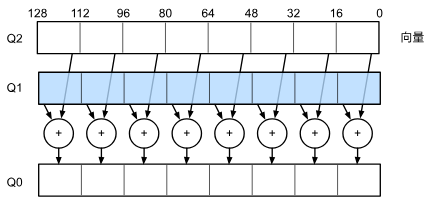
(這張圖的意思是八對整數加法,先將八個整數排成向量,將倆向量相加)
然后書里講了高速緩存Cache的內容,但這部分內容在計組和操作系統課里講過,就簡略帶過。
總之Cache主要是緩解CPU核心處理速度過快,而主存到CPU數據傳輸相對過慢的情況,在兩者中間加入速度介于兩者之間的緩存,就可以大大緩解這種速度差。
CPU要從主存中讀取數據時,先將主存中的一片數據讀入Cache,如果將來CPU又要用到這些數據,或者要用到這些數據旁邊的數據,就可以直接從Cache中查找。
5. GPU和其他加速卡
GPU對于深度學習非常非常重要。
雖然對于訓練(需要反向傳播,要求高精度)來說可能沒什么,但對于推斷(只需前向傳播,不需要存儲中間數據),我們需要更大的內存和處理能力。
在之前說過向量化能夠提高運算效率,當然矩陣化就更好了。利用多個張量核,可以優化矩陣運算的數值精確度。
GPU不太擅長的主要在于稀疏數據和中斷。
6. 網絡和總線
單個設備不足時就要用到多個設備運算。
平常人們最常用的網絡應該是wifi,但是在深度學習中wifi提供的帶寬和延遲相對一般,下面介紹幾種深度學習中更好用的互連方式。
- PCIe(高速擴展總線):一種專用總線,適合大批量數據傳輸。
- 以太網:連接計算機時最常用的方式,比上面那位慢,但優點是按照成本低,覆蓋距離長。
- 交換機:一種連接多個設備的方式,每一對設備都能同時進行點對點連接。
- NVLink:PCIe的替代品,適用于帶寬非常高的互連,純粹的強大。
(ps:看完這些仿佛又回到了計網……)
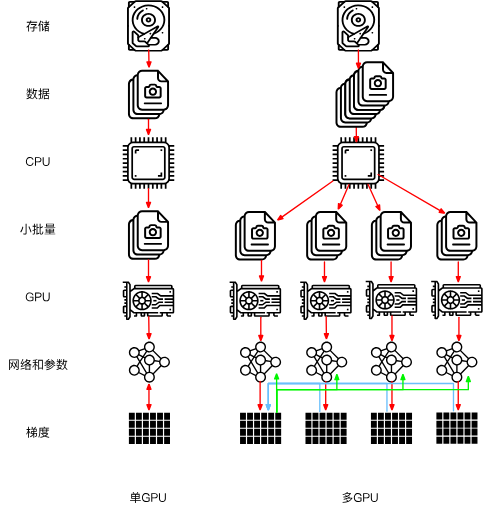
12.5 多GPU訓練
這一節主要講如何用多個GPU并行進行神經網絡的訓練。
有三種思路,第一種是將不同層分配給不同GPU,第二種是將每一層任務拆解到不同GPU,第三種是跨多個GPU對數據進行拆分。
- 第一種:網絡并行。可以處理更大的網絡,并且每個GPU的內存占用都能得到很好的控制。然而,GPU接口之間的密集同步很難實現,每個GPU間可能需要大量數據傳輸,總之不太好辦。
- 第二種,按層并行。是我們并行計算課實驗的內容,比如將矩陣拆分到不同處理單元進行計算,或者按通道劃分給不同GPU,這樣就可以處理不斷變大的網絡了。但是,這需要很多同步操作,因為每一層都依賴上一層輸出結果,需要傳輸的數據量不比第一種方法小,總之也不太好辦。
- 第三種,數據并行。對數據進行拆分,每個GPU處理小批量數據的部分訓練,最后匯總梯度,這種方法最簡單并且可以用于任何情況,只需要在每個小批量處理后同步。只不過添加更多GPU并對訓練更大的模型沒什么幫助。
三種方法的比較圖如下:
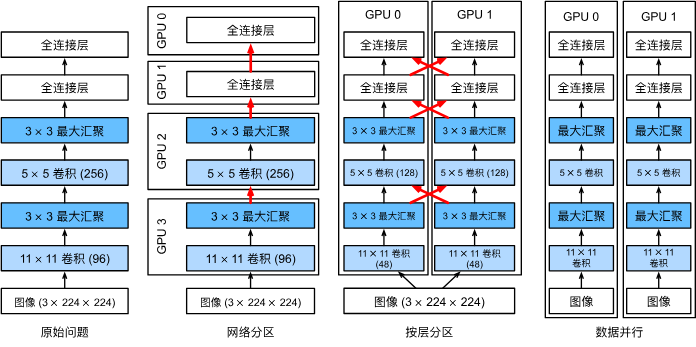
另外,GPU的內存對訓練很重要,內存大會很方便,在早期是個很棘手的問題,不過現在已經解決。
因為數據并行最好用且最實用,所以我們將按照數據并行的方法實現并行計算。
數據并行時系統內部大致如下(2個GPU的情況):
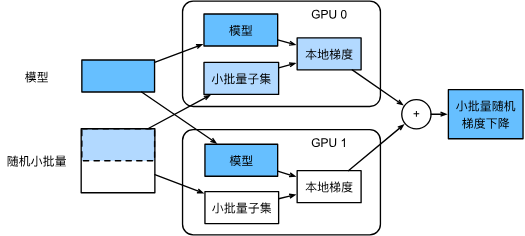
如圖,隨機小批量數據被分為2個部分,在不同GPU上計算梯度,最后匯總在一起。
k個GPU并行訓練過程:
- 小批量數據被均勻分成k個部分,每個部分都被分給不同GPU。
- 每個GPU計算各自部分的損失和梯度。
- 將所有GPU上的梯度匯總,獲得當前小批量的梯度。
- 聚合梯度再一次被分成k個部分,分給每個GPU更新參數。
實際中需要將小批量擴大成k的倍數,以便均勻分配,如果會顯著增大數據量大小,那么相應可能還要提高學習率(關于為什么可以提高學習率,問了ai但是沒有結果,我猜測是因為批量增大,方差更小,數據更穩定,學習率就可以提高),批量規范化也要調整,每個GPU獨自進行批量歸一化。
然后就是如何用代碼實現,這里介紹了幾種關鍵的技術:
1. 數據同步
這里需要構建一個函數,模擬兩個GPU同步的過程,也就是兩個設備計算出的梯度相加。
def allreduce(data):for i in range(1, len(data)):data[0][:] += data[i].to(data[0].device)for i in range(1, len(data)):data[i][:] = data[0].to(data[i].device)運行結果示例:

2. 數據分發
這里直接借用了Pytorch框架中的函數,將數據分發給每個設備:
split = nn.parallel.scatter(data, devices)其中data是需要分配的數據,devices是設備列表,返回的split是分發結果。
構建一個數據分發的函數:
#@save
def split_batch(X, y, devices):"""將X和y拆分到多個設備上"""assert X.shape[0] == y.shape[0]return (nn.parallel.scatter(X, devices),nn.parallel.scatter(y, devices))然后我們就可以利用構建的這兩個輔助函數構造多GPU的數據并行訓練函數。
之前說過只要沒有互相依賴的關系,系統就會自動并行計算,所以不需要添加什么并行計算的代碼,直接用循環讓各個設備計算自己的部分就行了。
單個批量訓練:
def train_batch(X, y, device_params, devices, lr):X_shards, y_shards = split_batch(X, y, devices)# 在每個GPU上分別計算損失ls = [loss(lenet(X_shard, device_W), y_shard).sum()for X_shard, y_shard, device_W in zip(X_shards, y_shards, device_params)]for l in ls: # 反向傳播在每個GPU上分別執行l.backward()# 將每個GPU的所有梯度相加,并將其廣播到所有GPUwith torch.no_grad():for i in range(len(device_params[0])):allreduce([device_params[c][i].grad for c in range(len(devices))])# 在每個GPU上分別更新模型參數for param in device_params:d2l.sgd(param, lr, X.shape[0]) # 在這里,我們使用全尺寸的小批量隨后的train函數和之前沒什么區別,都是對每個批量執行上面的批量訓練函數。
12.6 多GPU的簡潔實現
也可以使用深度學習框架中的API實現,內部原理和上面差不多。
比起之前的訓練函數,主要添加的步驟只有利用API在所有設備上設置模型。
def train(net, num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)# 在多個GPU上設置模型net = nn.DataParallel(net, device_ids=devices)trainer = torch.optim.SGD(net.parameters(), lr)loss = nn.CrossEntropyLoss()timer, num_epochs = d2l.Timer(), 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])for epoch in range(num_epochs):net.train()timer.start()for X, y in train_iter:trainer.zero_grad()X, y = X.to(devices[0]), y.to(devices[0])l = loss(net(X), y)l.backward()trainer.step()timer.stop()animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))print(f'測試精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/輪,'f'在{str(devices)}')即net = nn.DataParallel(net, device_ids=devices)這一步。
這一個API的具體作用有:
- 將訓練數據均勻分給每一個設備。
- 將模型復制到每一個設備。
- 每個GPU獨立進行向前向后傳播。
- 向前傳播時將所有結果匯總到默認第一個GPU上計算損失。
- 向后傳播時將所有梯度同步到默認第一個GPU上更新模型參數。
另外,代碼中的X, y = X.to(devices[0]), y.to(devices[0])這步,可能是DataParallel會自動將所有在第一個GPU設備上的數據分給其他GPU。
總之,DataParallel會解決一切的(合十)。
12.7 參數服務器
在硬件的那一節我們講到了設備間不同互連方式,它們的帶寬差距可能很大,因此速率差距也很大。
下面會介紹一些提高計算效率的其他方法。
1. 數據并行訓練
之前說道,三種并行方法中數據并行是最簡單直接有效的,我們可以對它進行改良衍生變體。
比如最后先將所有梯度聚合在第一個GPU上,進行參數更新后又將參數重新廣播給GPU們:
實際上不一定要在第一個GPU上聚合,可以在CPU上聚合,甚至可以依舊分配給不同GPU,在不同設備上聚合。
雖然聽起來很夢幻,但它確實是可以實現的。
作者在這里舉了一個具體的例子,比較了三種做法(在GPU上聚合、在CPU上聚合,分配給不同設備進行聚合)。
這個例子中的連接設備大概是,一個GPU可以同時為所有其他GPU發送不同數據,但不能兩個GPU同時發送數據。
這時候第三種做法就很有優勢了,每個GPU輪流將梯度分塊分給各個GPU,在每個GPU上完成各自的聚合后再返還給各個GPU,可以實現高效的數據傳遞。
三種方法比較如下:
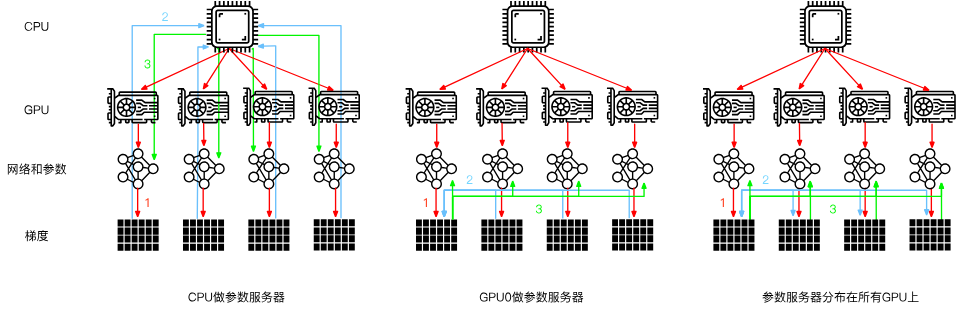
2. 環同步
有一些定制網絡連接方式。
比如一些連接,每個GPU通過PCIe連接到CPU,每個GPU還有6個NVLink連接。
大概長這樣:
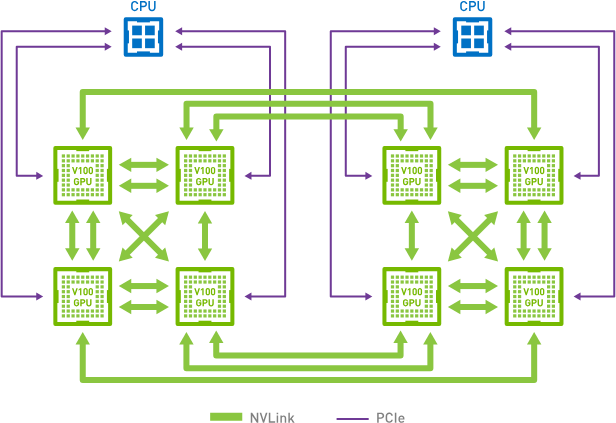
我們可以將這個結構分成環,下面是兩種分法:
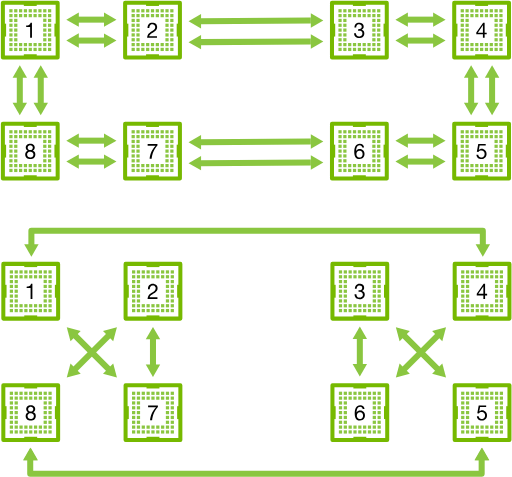
(不管看成哪樣的環,總之可以看成一個環)
這樣梯度就可以按環傳播,從第一個設備開始,它將它的梯度傳給 2 設備,然后 2 設備計算自己的梯度和傳來的梯度,相加之和給第 3 個設備……最后所有梯度相加的結果返回給第 1 個設備。
但這樣很低效,因為計算實際是按照設備數量線性遞增的。
然后我們就想到可以用之前那種方法,將梯度分塊,每次每個設備傳遞部分梯度塊。
流程如下:
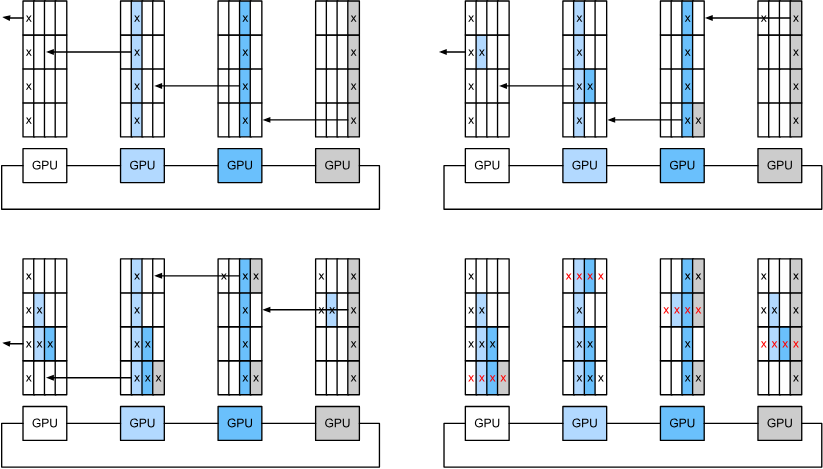
雖然傳遞數據的時間還是隨著節點數線性增加,但是計算可以同步完成,大大提高了效率。
3. 多機訓練
在多臺機器上訓練。其實和之前差不多,只不過每個機器中又有多個GPU,每次計算完這個批量的梯度之和都要將梯度整合后返回中心的參數服務器。
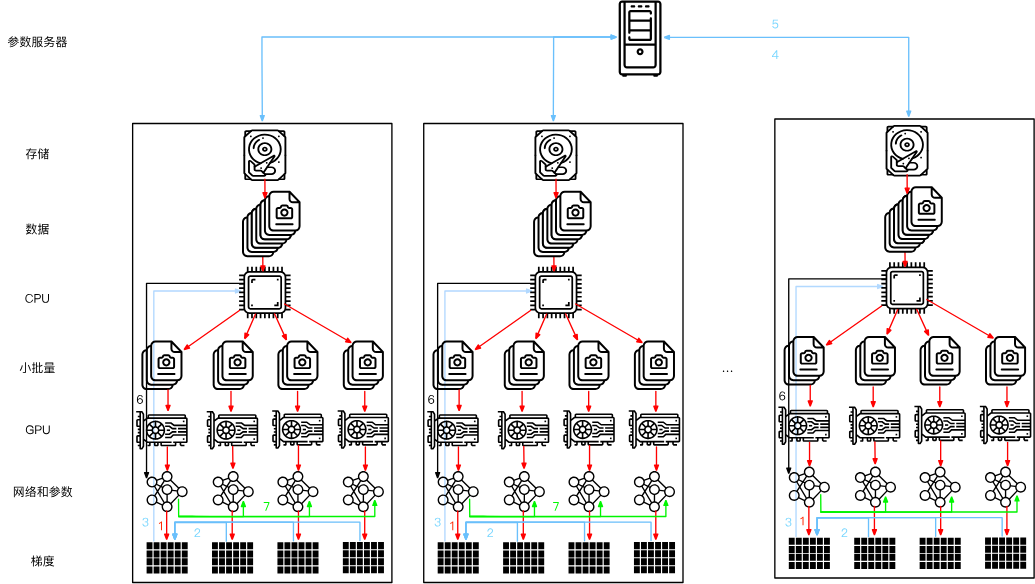
這其中很重要的是同步,就是參數服務器接受多個機器的結果的過程。
但每個服務器的帶寬有限,數據傳輸的時間開銷會隨著機器數目的增加而線性增長。
可以增加參數服務器數量解決。
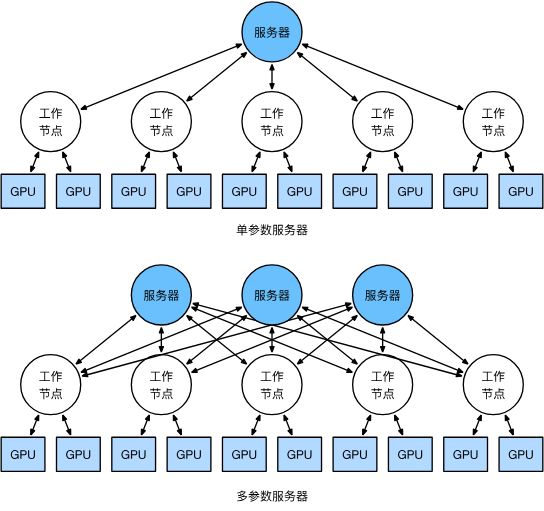
4. 鍵-值存儲
在許多工作節點和GPU中,梯度 i 的計算可定義為:

其中是梯度 i 在工作節點 k ,GPU j 中拆分的梯度。
這樣就可以假設 i 是鍵,gi 就是值。
定義兩個操作push(累計梯度)和pull(取得聚合梯度),i 可以代表層。
-
push(key,value)將特定的梯度值從工作節點發送到公共存儲,在那里通過某種方式(相加)來聚合值;
-
pull(key,value)從公共存儲中取得某種方式(組合來自所有工作節點的梯度)的聚合值。
通過將所有復雜操作轉化成這兩個操作,就可以方便解釋。




)

---鏈式棧)



: 電源管理體系完整梳理:I2C、Regulator、PMIC與Power-Domain框架)

—矩陣)
)





