繼續微調
微調視頻的代碼如下:
# 此Python文件用于對SmolVLM2進行視頻字幕任務的微調
# 導入所需的庫
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
import torch
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
from transformers import AutoProcessor, BitsAndBytesConfig, AutoModelForImageTextToText
from datasets import load_dataset
from transformers import TrainingArguments, Trainer
from torch.nn.utils.rnn import pad_sequence# 設置是否使用LoRA和QLoRA以及選擇模型
# 設置SOCKS代理
os.environ['http_proxy'] = 'http://127.0.0.1:1080'
os.environ['https_proxy'] = 'socks5://127.0.0.1:1080'
os.environ['socks_proxy'] = 'socks5://127.0.0.1:1080'USE_LORA = False
USE_QLORA = False
SMOL = False
model_id = "HuggingFaceTB/SmolVLM2-500M-Video-Instruct" if SMOL else "/mnt/share/toky/LLMs/SmolVLM2-2.2B-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
import torchif torch.cuda.is_available():print("CUDA is available!")
else:print("CUDA is not available. Please check your CUDA installation.")
# 根據設置加載模型
"""根據USE_QLORA和USE_LORA的值來加載模型。若使用 QLoRA 或 LoRA,會配置相應的參數并加載模型;若不使用,則直接加載模型并將視覺模型的參數凍結。最后打印模型占用的 GPU 內存。"""
if USE_QLORA or USE_LORA:lora_config = LoraConfig(r=8,lora_alpha=8,lora_dropout=0.1,target_modules=['down_proj', 'o_proj', 'k_proj', 'q_proj', 'gate_proj', 'up_proj', 'v_proj'],use_dora=False if USE_QLORA else True,init_lora_weights="gaussian")lora_config.inference_mode = Falseif USE_QLORA:bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16)model = AutoModelForImageTextToText.from_pretrained(model_id,quantization_config=bnb_config if USE_QLORA else None,_attn_implementation="flash_attention_2",device_map="auto")model.add_adapter(lora_config)model.enable_adapters()model = prepare_model_for_kbit_training(model)model = get_peft_model(model, lora_config)print(model.get_nb_trainable_parameters())
else:model = AutoModelForImageTextToText.from_pretrained(model_id,torch_dtype=torch.bfloat16,_attn_implementation="flash_attention_2",)model = model.to("cuda") # 確保模型被移動到GPU# 如果只想微調LLM,凍結視覺模型參數for param in model.model.vision_model.parameters():param.requires_grad = Falsepeak_mem = torch.cuda.max_memory_allocated()
print(f"The model as is is holding: {peak_mem / 1024 ** 3:.2f} of GPU RAM")# 加載并預處理數據集
"""使用load_dataset加載數據集,將訓練集按 0.5 的比例劃分為訓練集和測試集,"""
ds = load_dataset("/mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback", name='real')
split_ds = ds["train"].train_test_split(test_size=0.5)
train_ds = split_ds["train"]
del split_ds, ds# 打印數據集示例
print(f"prompt: {train_ds[0]['text prompt']}, video: {train_ds[0]['video link']}")
"""僅保留訓練集。打印數據集的一個示例,并獲取<image>標記的 ID。"""
image_token_id = processor.tokenizer.additional_special_tokens_ids[processor.tokenizer.additional_special_tokens.index("<image>")
]# 數據整理函數
def collate_fn(examples):"""函數用于將多個樣本整理成一個批次。它將每個樣本的消息轉換為模型輸入,對輸入 ID、注意力掩碼和標簽進行填充,處理視頻像素值,最后返回一個包含整理后數據的字典。"""instances = []for example in examples:prompt = example["text prompt"]user_content = [{"type": "text", "text": "Caption the video."}]user_content.append({"type": "video", "path": example["video link"]})messages = [{"role": "user", "content": user_content},{"role": "assistant", "content": [{"type": "text", "text": f"{prompt}"}]}]instance = processor.apply_chat_template(messages, add_generation_prompt=False,tokenize=True, return_dict=True, return_tensors="pt").to("cuda").to(model.dtype)instances.append(instance)input_ids = pad_sequence([inst["input_ids"].squeeze(0) for inst in instances],batch_first=True,padding_value=processor.tokenizer.pad_token_id).to("cuda") # 確保在GPU上attention_mask = pad_sequence([inst["attention_mask"].squeeze(0) for inst in instances],batch_first=True,padding_value=0).to("cuda") # 確保在GPU上labels = pad_sequence([inst["input_ids"].squeeze(0).clone() for inst in instances],batch_first=True,padding_value=-100).to("cuda") # 確保在GPU上labels[labels == image_token_id] = -100out = {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}# 處理視頻像素值pvs = [inst["pixel_values"].squeeze(0) for inst in instances if "pixel_values" in inst]if pvs:max_frames = max(pv.shape[0] for pv in pvs)max_h = max(pv.shape[-2] for pv in pvs)max_w = max(pv.shape[-1] for pv in pvs)else:max_h = max_w = processor.video_size['longest_edge']max_frames = 1padded_pixel_values_list = []for ex in instances:pv = ex.get("pixel_values", None).squeeze(0)if pv is None:shape_pv = (max_frames, 3, max_h, max_w)padded_pv = torch.zeros(shape_pv, dtype=torch.float32).to("cuda") # 確保在GPU上else:f, c, h, w = pv.shapepadded_pv = torch.zeros((max_frames, c, max_h, max_w),dtype=pv.dtype,device=pv.device)padded_pv[:f, :, :h, :w] = pvpadded_pixel_values_list.append(padded_pv)out["pixel_values"] = torch.stack(padded_pixel_values_list, dim=0).to("cuda") # 確保在GPU上return out# 訓練設置
model_name = model_id.split("/")[-1]
training_args = TrainingArguments(num_train_epochs=1,per_device_train_batch_size=2,gradient_accumulation_steps=1,warmup_steps=50,learning_rate=1e-4,weight_decay=0.01,logging_steps=25,save_strategy="steps",save_steps=250,save_total_limit=1,optim="paged_adamw_8bit", # for 8-bit, keep paged_adamw_8bit, else adamw_hfbf16=True,output_dir=f"./{model_name}-video-feedback",hub_model_id=f"{model_name}-video-feedback",remove_unused_columns=False,report_to="tensorboard",dataloader_pin_memory=False
)# 初始化Trainer并進行訓練
trainer = Trainer(model=model,args=training_args,data_collator=collate_fn,train_dataset=train_ds,
)
trainer.train()
# 將訓練好的模型推送到Hugging Face Hub
trainer.push_to_hub()# 測試示例
messages = [{"role": "user","content": [{"type": "text", "text": "Caption the video."},{"type": "video","path": "https://huggingface.co/datasets/hexuan21/VideoFeedback-videos-mp4/resolve/main/p/p000304.mp4"}]}]inputs = processor.apply_chat_template(messages, add_generation_prompt=True,tokenize=True, return_dict=True, return_tensors="pt").to("cuda").to(model.dtype)generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=64)
generated_texts = processor.batch_decode(generated_ids,skip_special_tokens=True,
)print(generated_texts[0])
在服務器終端配置了好久DaiLi,但是久了還是會報錯,應該是網絡不穩定:
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<00:00, 2.00it/s]
The model as is is holding: 4.20 of GPU RAM
prompt: It is an interior of a furniture store, with tables and chairs arranged in a showroom setting., video: https://huggingface.co/datasets/hexuan21/VideoFeedback-videos-mp4/resolve/main/p/p110224.mp42%|▎ | 25/1000 [07:15<3:40:58, 13.60s/it]{'loss': 2.6556, 'grad_norm': 5.4375, 'learning_rate': 4.8e-05, 'epoch': 0.03}5%|▌ | 50/1000 [13:40<6:01:04, 22.80s/it]{'loss': 0.3066, 'grad_norm': 1.9296875, 'learning_rate': 9.8e-05, 'epoch': 0.05}8%|▊ | 75/1000 [20:59<3:27:40, 13.47s/it]{'loss': 0.273, 'grad_norm': 1.8515625, 'learning_rate': 9.747368421052632e-05, 'epoch': 0.07}8%|▊ | 82/1000 [22:01<2:26:58, 9.61s/it]Traceback (most recent call last):File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connectionpool.py", line 464, in _make_requestself._validate_conn(conn)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1093, in _validate_connconn.connect()File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connection.py", line 741, in connectsock_and_verified = _ssl_wrap_socket_and_match_hostname(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connection.py", line 920, in _ssl_wrap_socket_and_match_hostnamessl_sock = ssl_wrap_socket(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/util/ssl_.py", line 460, in ssl_wrap_socketssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls, server_hostname)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/util/ssl_.py", line 504, in _ssl_wrap_socket_implreturn ssl_context.wrap_socket(sock, server_hostname=server_hostname)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/ssl.py", line 513, in wrap_socketreturn self.sslsocket_class._create(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/ssl.py", line 1104, in _createself.do_handshake()File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/ssl.py", line 1375, in do_handshakeself._sslobj.do_handshake()
ssl.SSLEOFError: [SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)During handling of the above exception, another exception occurred:Traceback (most recent call last):File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connectionpool.py", line 787, in urlopenresponse = self._make_request(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connectionpool.py", line 488, in _make_requestraise new_e
urllib3.exceptions.SSLError: [SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)The above exception was the direct cause of the following exception:Traceback (most recent call last):File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/adapters.py", line 667, in sendresp = conn.urlopen(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/connectionpool.py", line 841, in urlopenretries = retries.increment(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/urllib3/util/retry.py", line 519, in incrementraise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
urllib3.exceptions.MaxRetryError: SOCKSHTTPSConnectionPool(host='cdn-lfs-us-1.hf.co', port=443): Max retries exceeded with url: /repos/b8/3e/b83ea2bda2d9360fb510c71dcb4ba6823a277e191b811453f0920bbed536814a/4686c53313c509ea510071b69a6413ad6373ec276437df8a1f31210e2712210a?response-content-disposition=inline%3B+filename*%3DUTF-8%27%27p108061.mp4%3B+filename%3D%22p108061.mp4%22%3B&response-content-type=video%2Fmp4&Expires=1745570852&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc0NTU3MDg1Mn19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy11cy0xLmhmLmNvL3JlcG9zL2I4LzNlL2I4M2VhMmJkYTJkOTM2MGZiNTEwYzcxZGNiNGJhNjgyM2EyNzdlMTkxYjgxMTQ1M2YwOTIwYmJlZDUzNjgxNGEvNDY4NmM1MzMxM2M1MDllYTUxMDA3MWI2OWE2NDEzYWQ2MzczZWMyNzY0MzdkZjhhMWYzMTIxMGUyNzEyMjEwYT9yZXNwb25zZS1jb250ZW50LWRpc3Bvc2l0aW9uPSomcmVzcG9uc2UtY29udGVudC10eXBlPSoifV19&Signature=uL3PDB2RUzJoXXskLGjquF7ADrZTbHuOomk4eGVBJQfi0SqM9vNErxHc8IcvbtEIvAY1Wmmz9etfXu0WbI-EPcVekP3mFfqlOExQsI4tMpAgzsz45Wc0YdMBr6bXt730~LtujvQYcl4gpxOL2ufefcEG0soGA5PvGnLPskweGEfPJQmNJ5niOrQj1AFwwtdHH0fvLuzLklYWpZs22w5qBiB0rMHQQ-zWJbHQsMbB1KDwN48FVILPC5OIHKWkqJRNjb5MhwSMLo~HvapYC18zd3An9iWoeHb~vJyYBVZc~z-0g6FPUMrJNdRp1aDosNp3h5DLsmr0XpQ0SmHYc2B4ug__&Key-Pair-Id=K24J24Z295AEI9 (Caused by SSLError(SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)')))During handling of the above exception, another exception occurred:Traceback (most recent call last):File "/mnt/share/toky/Projects/SmolVLM2_Test/Smol_VLM_Video_FT.py", line 196, in <module>trainer.train()File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/transformers/trainer.py", line 2245, in trainreturn inner_training_loop(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/transformers/trainer.py", line 2514, in _inner_training_loopbatch_samples, num_items_in_batch = self.get_batch_samples(epoch_iterator, num_batches, args.device)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/transformers/trainer.py", line 5243, in get_batch_samplesbatch_samples.append(next(epoch_iterator))File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/accelerate/data_loader.py", line 561, in __iter__next_batch = next(dataloader_iter)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 701, in __next__data = self._next_data()File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 757, in _next_datadata = self._dataset_fetcher.fetch(index) # may raise StopIterationFile "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 55, in fetchreturn self.collate_fn(data)File "/mnt/share/toky/Projects/SmolVLM2_Test/Smol_VLM_Video_FT.py", line 106, in collate_fninstance = processor.apply_chat_template(messages, add_generation_prompt=False,File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/transformers/models/smolvlm/processing_smolvlm.py", line 451, in apply_chat_templatereturn super().apply_chat_template(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/transformers/processing_utils.py", line 1394, in apply_chat_templatevideo, metadata = load_video(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/transformers/image_utils.py", line 847, in load_videofile_obj = BytesIO(requests.get(video).content)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/api.py", line 73, in getreturn request("get", url, params=params, **kwargs)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/api.py", line 59, in requestreturn session.request(method=method, url=url, **kwargs)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/sessions.py", line 589, in requestresp = self.send(prep, **send_kwargs)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/sessions.py", line 724, in sendhistory = [resp for resp in gen]File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/sessions.py", line 724, in <listcomp>history = [resp for resp in gen]File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/sessions.py", line 265, in resolve_redirectsresp = self.send(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/sessions.py", line 703, in sendr = adapter.send(request, **kwargs)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/requests/adapters.py", line 698, in sendraise SSLError(e, request=request)
requests.exceptions.SSLError: SOCKSHTTPSConnectionPool(host='cdn-lfs-us-1.hf.co', port=443): Max retries exceeded with url: /repos/b8/3e/b83ea2bda2d9360fb510c71dcb4ba6823a277e191b811453f0920bbed536814a/4686c53313c509ea510071b69a6413ad6373ec276437df8a1f31210e2712210a?response-content-disposition=inline%3B+filename*%3DUTF-8%27%27p108061.mp4%3B+filename%3D%22p108061.mp4%22%3B&response-content-type=video%2Fmp4&Expires=1745570852&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc0NTU3MDg1Mn19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy11cy0xLmhmLmNvL3JlcG9zL2I4LzNlL2I4M2VhMmJkYTJkOTM2MGZiNTEwYzcxZGNiNGJhNjgyM2EyNzdlMTkxYjgxMTQ1M2YwOTIwYmJlZDUzNjgxNGEvNDY4NmM1MzMxM2M1MDllYTUxMDA3MWI2OWE2NDEzYWQ2MzczZWMyNzY0MzdkZjhhMWYzMTIxMGUyNzEyMjEwYT9yZXNwb25zZS1jb250ZW50LWRpc3Bvc2l0aW9uPSomcmVzcG9uc2UtY29udGVudC10eXBlPSoifV19&Signature=uL3PDB2RUzJoXXskLGjquF7ADrZTbHuOomk4eGVBJQfi0SqM9vNErxHc8IcvbtEIvAY1Wmmz9etfXu0WbI-EPcVekP3mFfqlOExQsI4tMpAgzsz45Wc0YdMBr6bXt730~LtujvQYcl4gpxOL2ufefcEG0soGA5PvGnLPskweGEfPJQmNJ5niOrQj1AFwwtdHH0fvLuzLklYWpZs22w5qBiB0rMHQQ-zWJbHQsMbB1KDwN48FVILPC5OIHKWkqJRNjb5MhwSMLo~HvapYC18zd3An9iWoeHb~vJyYBVZc~z-0g6FPUMrJNdRp1aDosNp3h5DLsmr0XpQ0SmHYc2B4ug__&Key-Pair-Id=K24J24Z295AEI9 (Caused by SSLError(SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)')))8%|▊ | 82/1000 [22:04<4:07:05, 16.15s/it]數據集問題
代碼中使用的數據集是TIGER-Lab/VideoFeedback
示例
| id | images | text prompt | video link | visual quality | temporal consistency | dynamic degree | text-to-video alignment | factual consistency | conversations |
| 6000476 | [ "6000476_00.jpg", "6000476_01.jpg", "6000476_02.jpg", "6000476_03.jpg", "6000476_04.jpg", "6000476_05.jpg", "6000476_06.jpg", "6000476_07.jpg", "6000476_08.jpg", "6000476_09.jpg", "6000476_10.jpg", "6000476_11.jpg", "6000476_12.jpg", "6000476_13.jpg", "6000476_14.jpg", "6000476_15.jpg" ] | An eagle sitting on top of a lush cactus devouring a snake, all framed by a backdrop of mountains. is a companion hybrid of the Valley of Mexico | https://huggingface.co/datasets/hexuan21/VideoFeedback-videos-mp4/resolve/main/6/6000476.mp4 | 1 | 1 | 3 | 3 | 1 | [ { "from": "human", "value": "\nSuppose you are an expert in judging and evaluating the quality of AI-generated videos, \nplease watch the following frames of a given video and see the text prompt for generating the video, \nthen give scores from 5 different dimensions:\n(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color\n(2) temporal consistency, the consistency of objects or humans in video\n(3) dynamic degree, the degree of dynamic changes\n(4) text-to-video alignment, the alignment between the text prompt and the video content\n(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge\n\nFor each dimension, output a number from [1,2,3,4], \nin which '1' means 'Bad', '2' means 'Average', '3' means 'Good', \n'4' means 'Real' or 'Perfect' (the video is like a real video)\nHere is an output example:\nvisual quality: 4\ntemporal consistency: 4\ndynamic degree: 3\ntext-to-video alignment: 1\nfactual consistency: 2\n\nFor this video, the text prompt is \"An eagle sitting on top of a lush cactus devouring a snake, all framed by a backdrop of mountains. is a companion hybrid of the Valley of Mexico \",\nall the frames of video are as follows: \n\n<image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> \n" }, { "from": "gpt", "value": "visual quality: 1\n temporal consistency: 1\n dynamic degree: 3\n text-to-video alignment: 3\n factual consistency: 1\n" } ] |
| 1002546 | [ "1002546_00.jpg", "1002546_01.jpg", "1002546_02.jpg", "1002546_03.jpg", "1002546_04.jpg", "1002546_05.jpg", "1002546_06.jpg", "1002546_07.jpg", "1002546_08.jpg", "1002546_09.jpg", "1002546_10.jpg", "1002546_11.jpg", "1002546_12.jpg", "1002546_13.jpg", "1002546_14.jpg", "1002546_15.jpg" ] | a carpet of flowers of various colors under the morning sun | https://huggingface.co/datasets/hexuan21/VideoFeedback-videos-mp4/resolve/main/1/1002546.mp4 | 1 | 1 | 3 | 1 | 1 | [ { "from": "human", "value": "\nSuppose you are an expert in judging and evaluating the quality of AI-generated videos, \nplease watch the following frames of a given video and see the text prompt for generating the video, \nthen give scores from 5 different dimensions:\n(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color\n(2) temporal consistency, the consistency of objects or humans in video\n(3) dynamic degree, the degree of dynamic changes\n(4) text-to-video alignment, the alignment between the text prompt and the video content\n(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge\n\nFor each dimension, output a number from [1,2,3,4], \nin which '1' means 'Bad', '2' means 'Average', '3' means 'Good', \n'4' means 'Real' or 'Perfect' (the video is like a real video)\nHere is an output example:\nvisual quality: 4\ntemporal consistency: 4\ndynamic degree: 3\ntext-to-video alignment: 1\nfactual consistency: 2\n\nFor this video, the text prompt is \"a carpet of flowers of various colors under the morning sun \",\nall the frames of video are as follows: \n\n<image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> <image> \n" }, { "from": "gpt", "value": "visual quality: 1\n temporal consistency: 1\n dynamic degree: 3\n text-to-video alignment: 1\n factual consistency: 1\n" } ] |
| 2000505 | [ "2000505_00.jpg", "2000505_01.jpg", "2000505_02.jpg", "2000505_03.jpg", "2000505_04.jpg", "2000505_05.jpg", "2000505_06.jpg", "2000505_07.jpg", "2000505_08.jpg", "2000505_09.jpg", "2000505_10.jpg", "2000505_11.jpg", "2000505_12.jpg", "2000505_13.jpg", "2000505_14.jpg", "2000505_15.jpg" ] | rayman eating ice cream, globox stretching | https://huggingface.co/datasets/hexuan21/VideoFeedback-videos-mp4/resolve/main/2/2000505.mp4 | 2 | 2 | 2 | 3 | 1 | [ { "from": "human", "value": "\nSuppose you are an expert in judging and evaluating the quality of AI-generated videos, |
?本地數據集解析與對應關系
在/mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/annotated/本地文件中:

這里的test-xxx.parquet里面封裝的就是數據集的prompt還有一些文本信息,不過是以二進制形式存儲的,所以直接打開看不懂。
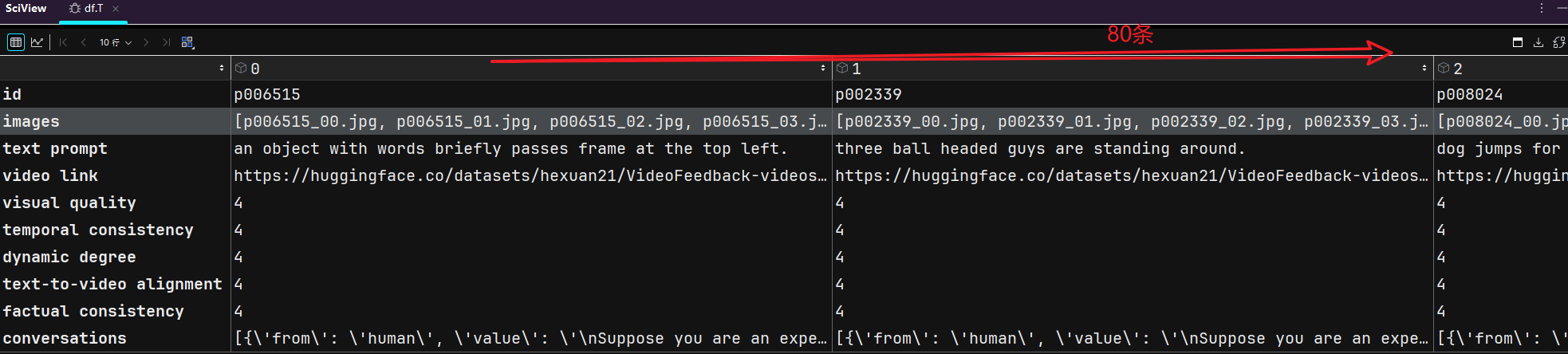
對應著frames_real_test里面的80個文件夾。
相當于另外一個文件夾下的data_real.json轉成了test-xxx.parquet
/mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/annotated/test-xxx.parquet
而/mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/annotated/train-00000-of-00001.parquet里面的id可以在TIGER-Lab\VideoFeedback\train\data_real.json下面找到
本來代碼里面指定是讀取real文件夾下的,但是發現微調使用的數據集貌似是annotated下面的,但是我是把real直接復制了一份在annotated下,所以說train-00000-of-00001.parquet里面的id指向TIGER-Lab\VideoFeedback\train\data_real.json也就不奇怪了。記得在hg上annotated文件夾下的數據更多,30多個G。
總結一下:
- /mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/real/test-00000-of-00001.parquet指向/mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/test/data_real.json
- /mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/real/train-00000-of-00001.parquet指向/mnt/share/toky/Datasets/TIGER-Lab/VideoFeedback/train/data_real.json
自己造數據集√
一些過程prompt:
要求如下:(1)把/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/test/目錄下的4文件夾,壓縮成zip文件,四個文件夾分別是【frames_annotated、frames_real、videos_annotated、videos_real】,把frames_real和videos_real分別壓縮成frames_real_test.zip和videos_real_test.zip,放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/real/下面
(2)把兩個json文件轉為parquet文件,兩個json文件分別是【 "data_real.json", "data_annotated.json"】,把 "data_real.json"轉成"test-00000-of-00001.parquet",放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/real/下面, "data_annotated.json"轉成"test-00000-of-00001.parquet",放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/annotated/下面;
(3)把/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/train/目錄下的4文件夾,壓縮成zip文件,四個文件夾分別是【frames_annotated、frames_real、videos_annotated、videos_real】,把frames_real和videos_real分別壓縮成frames_real_train.zip和videos_real_train.zip,放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/real/下面(4)把兩個json文件轉為parquet文件,兩個json文件分別是【 "data_real.json", "data_annotated.json"】,把 "data_real.json"轉成"train-00000-of-00001.parquet",放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/real/下面, "data_annotated.json"轉成"train-00000-of-00001.parquet",放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/annotated/下面;
(5)對了,還需要記得把在test和train下面壓縮的frames_annotated文件夾、videos_annotated文件夾分別壓縮成frames_real_annotated.zip和videos_real_annotated.zip放在/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/annotated/下面;
代碼路徑:
\mnt\share\toky\Projects\GenSurgery\toky_process_dataset\process_parquet.py
但是看到在加載的時候還是不匹配,原來在README.md文件里還有配置信息。
從hugging face 上下載的數據集這個配置文件里面還有這樣的信息:【---
language:
- en
license: apache-2.0
size_categories:
- 10K<n<100K
task_categories:
- video-classification
pretty_name: VideoFeedback
tags:
- video
dataset_info:
- config_name: annotatedfeatures:- name: iddtype: string- name: imagessequence: string- name: text promptdtype: string- name: video linkdtype: string- name: visual qualitydtype: int64- name: temporal consistencydtype: int64- name: dynamic degreedtype: int64- name: text-to-video alignmentdtype: int64- name: factual consistencydtype: int64- name: conversationslist:- name: fromdtype: string- name: valuedtype: stringsplits:- name: testnum_bytes: 1348268num_examples: 680- name: trainnum_bytes: 65281005num_examples: 32901download_size: 45128599dataset_size: 66629273
- config_name: realfeatures:- name: iddtype: string- name: imagessequence: string- name: text promptdtype: string- name: video linkdtype: string- name: visual qualitydtype: int64- name: temporal consistencydtype: int64- name: dynamic degreedtype: int64- name: text-to-video alignmentdtype: int64- name: factual consistencydtype: int64- name: conversationslist:- name: fromdtype: string- name: valuedtype: stringsplits:- name: trainnum_bytes: 8072782num_examples: 4000- name: testnum_bytes: 162240num_examples: 80download_size: 3963450dataset_size: 8235022
configs:
- config_name: annotateddata_files:- split: trainpath: annotated/train-*- split: testpath: annotated/test-*
- config_name: realdata_files:- split: testpath: real/test-*- split: trainpath: real/train-*
---】根據報錯信息改了- config_name: real下面的byte大小和樣本數量,沒報這個錯了,但是:
Traceback (most recent call last):File "/mnt/share/toky/Projects/SmolVLM2_Test/Smol_VLM_Video_FT.py", line 79, in <module>ds = load_dataset("/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback", name="real", split="test")File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/load.py", line 2062, in load_datasetbuilder_instance = load_dataset_builder(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/load.py", line 1782, in load_dataset_builderdataset_module = dataset_module_factory(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/load.py", line 1519, in dataset_module_factory).get_module()File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/load.py", line 836, in get_modulebuilder_configs, default_config_name = create_builder_configs_from_metadata_configs(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/load.py", line 649, in create_builder_configs_from_metadata_configsbuilder_config_cls(File "<string>", line 12, in __init__File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 26, in __post_init__super().__post_init__()File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/builder.py", line 125, in __post_init__if invalid_char in self.name:
TypeError: argument of type 'NoneType' is not iterable報錯:TypeError: argument of type 'NoneType' is not iterable
def __post_init__(self):# The config name is used to name the cache directory.for invalid_char in INVALID_WINDOWS_CHARACTERS_IN_PATH:if invalid_char in self.name:raise InvalidConfigName(f"Bad characters from black list '{INVALID_WINDOWS_CHARACTERS_IN_PATH}' found in '{self.name}'. "f"They could create issues when creating a directory for this config on Windows filesystem.")解決:
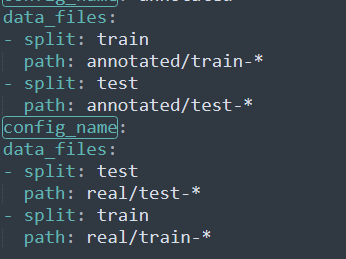
這里的config_name不知道啥時候被改了,有點蠢,找了半天Bug = =
Traceback (most recent call last):File "/mnt/share/toky/Projects/SmolVLM2_Test/Smol_VLM_Video_FT.py", line 80, in <module>ds = load_dataset("/mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback", name="real")File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/load.py", line 2084, in load_datasetbuilder_instance.download_and_prepare(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/builder.py", line 925, in download_and_prepareself._download_and_prepare(File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/builder.py", line 1019, in _download_and_prepareverify_splits(self.info.splits, split_dict)File "/mnt/share/toky/CondaEnvs/LM/lib/python3.10/site-packages/datasets/utils/info_utils.py", line 77, in verify_splitsraise NonMatchingSplitsSizesError(str(bad_splits))
datasets.exceptions.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=72025, num_examples=20, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='train', num_bytes=14634, num_examples=7, shard_lengths=None, dataset_name='cholec80_video_feedback')}, {'expected': SplitInfo(name='test', num_bytes=215668, num_examples=60, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='test', num_bytes=6289, num_examples=3, shard_lengths=None, dataset_name='cholec80_video_feedback')}]解決:
再次修改README.md
推送模型到hf
在將訓練好的模型推送到Hugging Face Hub時候遇到問題。
print("開始訓練")
trainer.train()
# 將訓練好的模型推送到Hugging Face Hub
print("將訓練好的模型推送到Hugging Face Hub")trainer.push_to_hub()
print("開始測試")這里遇到了網絡問題,==》解決網絡問題,然后可以在代碼里進行huggingface的登錄,就可以發布模型了,如下所示:

微調通過!
/mnt/share/toky/CondaEnvs/LM/bin/python /mnt/share/toky/Projects/SmolVLM2_Test/Smol_VLM_Video_FT.py
CUDA is available!
You are attempting to use Flash Attention 2.0 with a model not initialized on GPU. Make sure to move the model to GPU after initializing it on CPU with `model.to('cuda')`.
Loading checkpoint shards: 100%|██████████| 2/2 [00:01<00:00, 1.94it/s]
The model as is is holding: 4.20 of GPU RAM
prompt: The current surgical phase is CalotTriangleDissection, Grasper, Hook tool exists., video: /mnt/share/toky/Datasets/Toky_Generate/Cholec80VideoFeedback/train/videos_real/t04_0000000.mp4
開始訓練
100%|██████████| 2/2 [00:16<00:00, 8.18s/it]
{'train_runtime': 16.3717, 'train_samples_per_second': 0.183, 'train_steps_per_second': 0.122, 'train_loss': 5.189296722412109, 'epoch': 1.0}
將訓練好的模型推送到Hugging Face Hub
model.safetensors: 0%| | 0.00/4.49G [00:00<?, ?B/s]
events.out.tfevents.1745563185.YAN-Machine.3092909.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]events.out.tfevents.1745563339.YAN-Machine.3093802.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]events.out.tfevents.1745564448.YAN-Machine.3101448.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]Upload 25 LFS files: 0%| | 0/25 [00:00<?, ?it/s]events.out.tfevents.1745564612.YAN-Machine.3103220.0: 0%| | 0.00/8.49k [00:00<?, ?B/s]
events.out.tfevents.1745563185.YAN-Machine.3092909.0: 100%|██████████| 8.48k/8.48k [00:06<00:00, 1.37kB/s]events.out.tfevents.1745564448.YAN-Machine.3101448.0: 100%|██████████| 8.48k/8.48k [00:06<00:00, 1.37kB/s]events.out.tfevents.1745564612.YAN-Machine.3103220.0: 100%|██████████| 8.49k/8.49k [00:06<00:00, 1.35kB/s]events.out.tfevents.1745563185.YAN-Machine.3092909.0: 100%|██████████| 8.48k/8.48k [00:06<00:00, 1.29kB/s]
events.out.tfevents.1745564448.YAN-Machine.3101448.0: 100%|██████████| 8.48k/8.48k [00:06<00:00, 1.28kB/s]
events.out.tfevents.1745564612.YAN-Machine.3103220.0: 100%|██████████| 8.49k/8.49k [00:06<00:00, 1.28kB/s]
events.out.tfevents.1745563339.YAN-Machine.3093802.0: 100%|██████████| 8.48k/8.48k [00:06<00:00, 1.26kB/s]
model.safetensors: 1%| | 47.0M/4.49G [00:12<12:43, 5.82MB/s]
events.out.tfevents.1745565384.YAN-Machine.3118167.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]events.out.tfevents.1745565415.YAN-Machine.3119073.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]events.out.tfevents.1745565621.YAN-Machine.3121507.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]events.out.tfevents.1745565791.YAN-Machine.3125459.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 20.8kB/s]
events.out.tfevents.1745565384.YAN-Machine.3118167.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 12.9kB/s]
events.out.tfevents.1745565415.YAN-Machine.3119073.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 13.5kB/s]events.out.tfevents.1745565621.YAN-Machine.3121507.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 8.54kB/s]events.out.tfevents.1745565809.YAN-Machine.3126720.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 23.0kB/s]events.out.tfevents.1745565929.YAN-Machine.3132618.0: 100%|██████████| 9.11k/9.11k [00:00<00:00, 24.5kB/s]events.out.tfevents.1745567917.YAN-Machine.225857.0: 0%| | 0.00/8.48k [00:00<?, ?B/s]events.out.tfevents.1745567569.YAN-Machine.4178102.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 21.3kB/s]events.out.tfevents.1745567917.YAN-Machine.225857.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 19.7kB/s]
events.out.tfevents.1745568389.YAN-Machine.544916.0: 100%|██████████| 9.31k/9.31k [00:00<00:00, 23.9kB/s]events.out.tfevents.1745570989.YAN-Machine.2231864.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 22.5kB/s]events.out.tfevents.1745571185.YAN-Machine.2416517.0: 0%| | 0.00/12.3k [00:00<?, ?B/s]events.out.tfevents.1745571108.YAN-Machine.2336285.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 21.4kB/s]
events.out.tfevents.1745571185.YAN-Machine.2416517.0: 100%|██████████| 12.3k/12.3k [00:00<00:00, 33.9kB/s]events.out.tfevents.1745673540.YAN-Machine.3385759.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 23.4kB/s]events.out.tfevents.1745722006.YAN-Machine.1838916.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 23.5kB/s]
events.out.tfevents.1745724618.YAN-Machine.1883932.0: 100%|██████████| 8.48k/8.48k [00:00<00:00, 21.4kB/s]events.out.tfevents.1745725130.YAN-Machine.1897854.0: 0%| | 0.00/8.83k [00:00<?, ?B/s]events.out.tfevents.1745725239.YAN-Machine.1900454.0: 0%| | 0.00/8.83k [00:00<?, ?B/s]events.out.tfevents.1745725400.YAN-Machine.1904120.0: 0%| | 0.00/8.83k [00:00<?, ?B/s]events.out.tfevents.1745725130.YAN-Machine.1897854.0: 100%|██████████| 8.83k/8.83k [00:00<00:00, 24.1kB/s]
events.out.tfevents.1745725239.YAN-Machine.1900454.0: 100%|██████████| 8.83k/8.83k [00:00<00:00, 24.0kB/s]
events.out.tfevents.1745725400.YAN-Machine.1904120.0: 100%|██████████| 8.83k/8.83k [00:00<00:00, 23.6kB/s]
events.out.tfevents.1745725837.YAN-Machine.1913951.0: 100%|██████████| 8.83k/8.83k [00:00<00:00, 22.1kB/s]training_args.bin: 100%|██████████| 5.37k/5.37k [00:00<00:00, 14.8kB/s]
model.safetensors: 100%|██████████| 4.49G/4.49G [20:29<00:00, 3.65MB/s]Upload 25 LFS files: 100%|██████████| 25/25 [20:31<00:00, 49.25s/it]
開始測試
User: Caption the video.You are provided the following series of three frames from a 0:00:03 [H:MM:SS] video.Frame from 00:00:
Frame from 00:01:
Frame from 00:02:Assistant: A woman in a white shirt is standing at a podium with a microphone, speaking into it. She is holding a microphone in her hand.
---鏈式棧)



: 電源管理體系完整梳理:I2C、Regulator、PMIC與Power-Domain框架)

—矩陣)
)










