文章目錄
- 1512.好數對的數目
- 2845.統計趣味子數組的數目
- 1371.每個元音包含偶數次的最長子字符串
- 區間和的數量統計是一類十分典型的問題:
記錄左邊,枚舉右邊策略 - 前置題目:
統計nums[j]==nums[i]的對數 - 進階版本:
統計子數組和%modulo == k的子數組的數目 - 為什么要使用到這個
哈希表? - 答:對于有限狀態的數量的存儲,并且對于
數量的統計,需要初始化store[0]=1,當然對于長度的統計,那么初始化的情況就是store[0] = -1(存儲的是下標) - 為什么要使用到這個
前綴和? - 答:方便計算這個區間的和的情況,我們所使用的前綴和,就是通過兩個前綴的狀態的差求解出中間狀態的情況!!!!
1512.好數對的數目
1512.好數對的數目

- 典型的
哈希表問題,先更新答案,再更新哈希表
from collections import defaultdict
class Solution:def numIdenticalPairs(self, nums: List[int]) -> int:n = len(nums)store = defaultdict(int)ans = 0for i in range(n):ans += store[nums[i]]store[nums[i]] += 1return ans
2845.統計趣味子數組的數目
2845.統計趣味子數組的數目
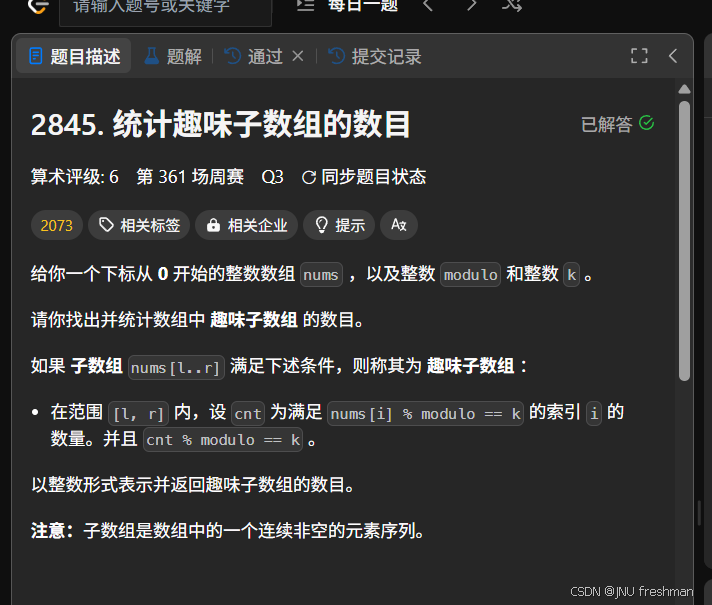
子數組區間和取模的問題,還是采用記錄左邊,枚舉右邊策略- 不過就是要注意,
我們其實是只用枚舉(前綴和-k)%modulo的數是否在左邊出現,更新的時候是前綴和%modulo的數量+1
from collections import defaultdict
class Solution:def countInterestingSubarrays(self, nums: List[int], modulo: int, k: int) -> int:n = len(nums)# 預處理,將滿足的位置變為1,否則就是0 for i in range(n):if nums[i] % modulo == k:nums[i] = 1else:nums[i] = 0 # 哈希表存儲,k == 0 的情況得另外處理,當k!=0的時候,就是一個哈希表+前綴和的問題store = defaultdict(int)# 記錄的是對應的取模的結果的最早的下標# 區間和取模問題store[0] = 1tmp,ans = 0,0for i in range(n):tmp = tmp + nums[i]if tmp >= k:ans += store[(tmp - k) % modulo]store[tmp % modulo ] += 1return ans
思考
- 如果題目求解的是
子數組的和是modulo的倍數的子數組個數,應該如何求解? - 答:那其實就更加簡單了,我們只需記錄
nums[i]%modulo的結果在左邊的數量即可,不過要注意初始化的時候得store[0] = 1
1371.每個元音包含偶數次的最長子字符串
1371.每個元音包含偶數次的最長子字符串
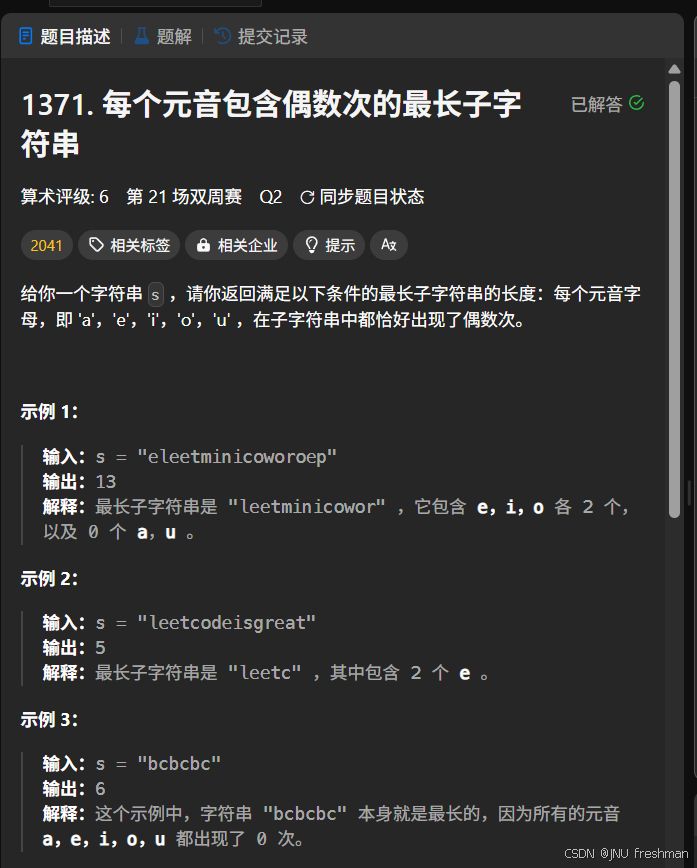
哈希表存儲的是下標,所以初始化的時候注意得是store[0]=-1- 我們只需關注這個
字符串中元音的個數的情況,當然,由于兩個前綴相同的狀態的差的字符串中元音的個數肯定是偶數,所以我們采用前綴和來求解出字符串中元音的個數的狀態,由于涉及到奇數偶數,所以采用異或運算
class Solution:def findTheLongestSubstring(self, s: str) -> int:n = len(s)mapper = {"a" : 1,"e" : 2,"i" : 4,"o" : 8,"u" : 16}# 使用哈希表存儲異或結果出現的第一次的下標seen = {0:-1}# 記錄結果ans = cur = 0for i in range(n):if s[i] in mapper:cur ^= mapper[s[i]]# 判斷當前的cur是否是第一次出現if cur in seen:ans = max(ans,i-seen[cur])else:seen[cur] = ireturn ans







—— 下篇(內含聚合查詢、group by和having子句、聯合查詢、插入查詢結果))

)









