- ??????第1章 對大型語言模型的介紹
- 第2章 分詞和嵌入
- 第3章 解析大型語言模型的內部機制
- 第4章 文本分類
- 第5章 文本聚類與主題建模
- 第6章 提示工程
- 第7章 高級文本生成技術與工具
- 第8章 語義搜索與檢索增強生成
- 第10章 構建文本嵌入模型
- 第11章 面向分類任務的表示模型微調
- 第12章 微調生成模型
當提到大型語言模型(LLMs)時,多模態能力或許并非首先躍入腦海的概念。畢竟,它們本質上是語言模型!但我們很快會發現,如果模型能夠處理文本以外的數據類型,其實用性將得到極大提升。例如,若語言模型能"看一眼"圖片并就其內容回答問題,這種能力將極具價值。如圖9-1所示,能夠同時處理文本和圖像(每種數據類型被稱為一種模態)的模型即被稱為多模態模型。
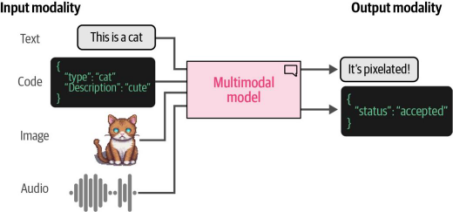
圖9-1. 能夠處理不同類型(或模態)數據的模型(如圖像、音頻、視頻或傳感器數據)被稱為多模態模型。值得注意的是,模型可能具備接收某種模態輸入的能力,但并不一定具備生成該模態輸出的能力
我們已經看到大型語言模型(LLMs)展現出各種新興能力,從泛化能力和推理能力到算術運算和語言學應用。隨著模型變得越來越大且越來越智能,它們的技能集也在持續擴展1。
接收并推理多模態輸入的能力可能進一步增強,并幫助釋放此前被限制的潛力。實際上,語言并非存在于真空中。例如,你的肢體語言、面部表情、語調等都是增強口頭表達的交流方式。同樣的邏輯也適用于LLMs——如果我們能使其具備對多模態信息的推理能力,它們的潛力將得到釋放,我們也將能夠將其用于解決新型問題。
在本章中,我們將探索多種具備多模態能力的LLMs及其在實際應用場景中的意義。首先,我們將通過改進原始Transformer技術,研究圖像如何被轉化為數值表示;接著,我們將展示如何通過這種Transformer擴展LLMs以涵蓋視覺任務。
視覺Transformer
在本書的各章中,我們已經見證了基于Transformer的模型在多種語言建模任務中的成功應用,從分類、聚類到搜索和生成式建模。因此,研究人員嘗試將Transformer的成功經驗推廣到計算機視覺領域也就不足為奇了。
他們提出的方法是視覺Transformer(Vision Transformer, ViT)。與傳統的默認卷積神經網絡(CNN)相比,ViT在圖像識別任務中表現極為出色2。與原始Transformer類似,ViT的目標是將非結構化數據(即圖像)轉換為可用于多種任務的表示形式,例如分類任務(如圖9-2所示)。
ViT依賴于Transformer架構中的一個關鍵組件——編碼器。如第1章所述,編碼器的作用是將文本輸入轉換為數值表示,然后再傳遞給解碼器。不過,在編碼器執行任務之前,文本輸入需要先經過分詞處理(如圖9-3所示)。
1 ?Jason Wei et al.?“Emergent?abilities?of?large?language?models.” arXiv?preprint arXiv:2206.07682?(2022).
2 ?Alexey Dosovitskiy et al. “An?image?is?worth?16x16?words:?Transformers?for?image?recognition?at?scale.” arXiv?preprint arXiv:2010.11929?(2020).
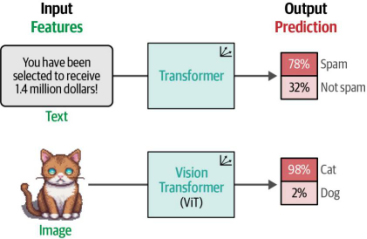
圖9-2原始Transformer模型與視覺Transformer模型均接收非結構化數據,將其轉換為數值表示,并最終用于分類等任務
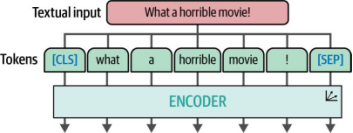
圖9-3. 文本首先通過分詞器(tokenizer)進行分詞處理,隨后被傳入一個或多個編碼器(encoder)中
由于圖像不包含文字,這種分詞流程無法直接應用于視覺數據。為此,Vision Transformer(ViT)的作者們提出了一種將圖像分割為"詞"的詞元方法,使其能夠沿用原始的編碼器架構。
試想一幅貓的圖像。該圖像由若干像素構成,比如512×512像素規格。單個像素承載的信息量微乎其微,但當我們將像素組合成塊時,圖像的細節特征便開始逐漸顯現。
ViT采用了類似的處理原理。與將文本拆分為詞元不同,它將原始圖像轉化為由多個圖像塊組成的集合。具體而言,如圖9-4所示,該模型通過橫向和縱向切割,將輸入圖像分割為若干離散的圖像塊單元。
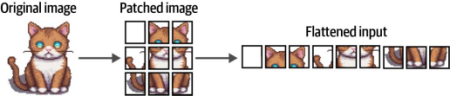
圖9-4. 圖像輸入的“分塊化”過程。該過程將圖像分割為多個子圖像塊
就像我們將文本轉換為文本詞元(tokens)一樣,我們也將圖像轉換為一系列圖像塊(patches)。圖像塊的展平輸入可以被視為一段文本中的詞元。然而與文本詞元不同,我們不能簡單地為每個圖像塊分配一個ID,因為這些圖像塊在其他圖像中很少重復出現(不像文本擁有固定詞匯表)。
取而代之的是,圖像塊通過線性嵌入(linearly embedded)生成數值化表示,即嵌入向量(embeddings)。這些嵌入向量隨后可作為Transformer模型的輸入。通過這種方式,圖像塊被以與文本詞元完全相同的方式進行處理。完整流程如圖9-5所示。
為便于說明,示例中的圖像被分割為3×3的塊,但原始論文實現實際使用了16×16的塊(畢竟這篇論文的標題正是《一張圖像價值16x16個詞》)。
這種方法最有趣之處在于:一旦嵌入向量被傳遞到編碼器,它們就被視作與文本詞元完全相同的存在。從這一刻起,無論是處理文本還是圖像,模型的訓練方式將沒有任何差異。
基于這種相似性,Vision Transformer(ViT)常被用于構建多模態語言模型。其最直接的應用場景之一就是在嵌入模型(embedding models)的訓練過程中發揮作用。
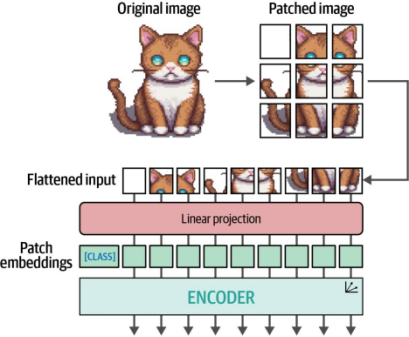
圖9-5. ViT背后的主要算法。將圖像分塊并進行線性投影后,這些圖像塊嵌入會被輸入到編碼器中,并像處理文本詞元一樣進行處理
多模態嵌入模型
在前面的章節中,我們使用嵌入模型來捕捉文本表征(如論文和文檔)的語義內容。我們發現可以利用這些嵌入或其數值表示來查找相似文檔、執行分類任務,甚至進行主題建模。
正如我們之前多次所見,嵌入通常是大型語言模型(LLM)應用背后的重要驅動力。它們是一種高效的方法,能夠捕獲大規模信息并在信息“大海撈針”中快速定位所需內容。
不過到目前為止,我們討論的僅是專注于生成文本表征的嵌入模型。雖然存在專門用于圖像嵌入的模型,但本章我們將探討能夠同時捕獲文本和視覺表征的嵌入模型(如圖9-6所示)。
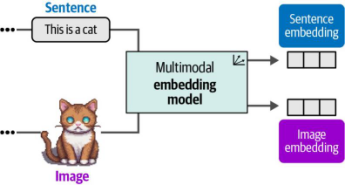
圖9-6. 多模態嵌入模型可在同一向量空間中為多種模態創建嵌入
其優勢在于,由于生成的嵌入向量位于同一向量空間(圖9-7),因此可以對多模態表示進行比較。例如,使用此類多模態嵌入模型,我們可以根據輸入的文本查找相關圖像。例如,若搜索與"小狗圖片"相似的圖像,我們會找到哪些圖像?反過來也成立——哪些文檔與該問題最相關?
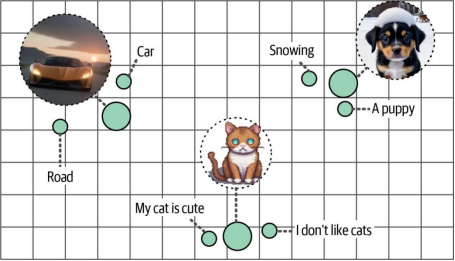
圖9-7. 盡管來自不同模態,但具有相似含義的嵌入向量在向量空間中會彼此接近。
目前有許多多模態嵌入模型,但最著名且應用最廣泛的是對比語言-圖像預訓練模型(CLIP)
CLIP:連接文本與圖像
CLIP 是一種嵌入模型,可同時計算圖像和文本的嵌入向量。生成的嵌入向量位于同一向量空間中,這意味著圖像的嵌入可以與文本的嵌入進行比較3。這種比較能力使 CLIP 及類似模型能夠應用于以下任務:
零樣本分類
通過將圖像的嵌入與其可能類別描述之間的嵌入進行比較,可以確定最相似的類別。
聚類
對圖像和關鍵詞集合同時進行聚類,以發現哪些關鍵詞對應哪些圖像集合
搜索
在數十億文本或圖像中,快速找到與輸入文本或圖像相關的內容。
生成
利用多模態嵌入驅動圖像生成(例如 stable diffusion?)。
CLIP如何生成多模態嵌入?
CLIP的工作過程其實非常直觀。假設你有一個包含數百萬張圖像及其對應標題的數據集(如圖9-8所示)。

圖9-8. 訓練多模態嵌入模型所需的數據類型
3 ?Alec Radford et al.?“Learning?transferable visual?models?from?natural?language?supervision.”?International?Conference on Machine Learning. PMLR, 2021.
4 ?Robin Rombach et?al.?“High-resolution?image?synthesis with?latent?diffusion?models.”?Proceedings?of?the?IEEE/CVF Conference on?Computer?Vision and Pattern Recognition, 2022.
該數據集可用于為每對(圖像及其描述)創建兩種表示形式——圖像本身及其對應的文本描述。為此,CLIP采用文本編碼器對文本進行編碼,并使用圖像編碼器對圖像進行編碼。如圖9-9所示,最終為圖像及其對應的描述分別生成了各自的嵌入表示。
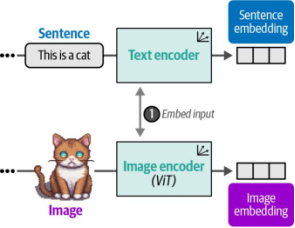
圖9-9. 在訓練CLIP的第一步中,圖像和文本分別通過圖像編碼器和文本編碼器進行嵌入
生成的嵌入對通過余弦相似度進行比較。正如我們在第4章中看到的,余弦相似度是向量之間夾角的余弦值,通過嵌入的點積除以它們的長度乘積計算得出。
在訓練開始時,由于圖像嵌入和文本嵌入尚未被優化到同一向量空間,它們的相似度會較低。在訓練過程中,我們會對嵌入間的相似度進行優化——對于相似的圖文對需要最大化其相似度,對于不相似的圖文對則需要最小小化其相似度(圖9-10)。
在計算相似度后,模型會進行參數更新,并使用新的數據批次和更新后的表示重新開始這一過程(圖9-11)。這種方法被稱為對比學習,我們將在第10章深入探討其工作原理,并創建我們自己的嵌入模型。
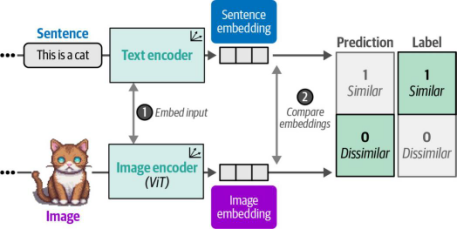
圖9-10. 在CLIP訓練的第二步中,通過余弦相似度計算句子與圖像嵌入之間的相似度
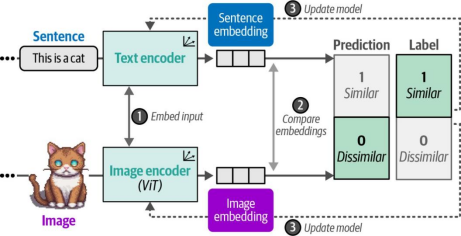
圖9-11. 在CLIP訓練的第三步中,會更新文本編碼器和圖像編碼器以匹配預期的相似性。這種更新會使嵌入向量在輸入內容相似時,在向量空間中的位置更加接近
最終,我們期望貓的圖像嵌入與短語“一張貓的圖片”的嵌入具有相似性。正如我們將在第10章中討論的,為了確保表征盡可能準確,訓練過程中還需要包含不相關的圖像和文本描述作為負樣本。建模相似性不僅需要理解事物之間的相似性來源,還需要厘清它們產生差異和非相似性的根本原因。
OpenCLIP
最終,我們期望貓的圖像嵌入與短語“一張貓的圖片”的嵌入具有相似性。正如我們將在第10章中討論的,為了確保表征盡可能準確,訓練過程中還需要包含不相關的圖像和文本描述作為負樣本。建模相似性不僅需要理解事物之間的相似性來源,還需要厘清它們產生差異和非相似性的根本原因。
?
from urllib.request import urlopenfrom PIL import?Image#?Load?an?AI-generated image of a puppy playing in?the?snowpuppy_path =?"https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/puppy.png"image = Image.open(urlopen(puppy_path)).convert("RGB")caption =?"a puppy?playing?in?the?snow"?
圖9-12. 人工智能生成的小狗雪地嬉戲圖像
由于我們為此圖像提供了標題,因此可以使用OpenCLIP為兩者生成嵌入。
為此,我們需要加載三個模型:
? 分詞器(Tokenizer):用于對文本輸入進行分詞
? 預處理器(Preprocessor):負責對圖像進行預處理和尺寸調整
? 主模型(Main Model):將前兩步的輸出轉換為嵌入向量(Embeddings)
from transformers import CLIPTokenizerFast, CLIPProcessor, CLIPModelmodel_id =?"openai/clip-vit-base-patch32"#?Load a?tokenizer?to preprocess?the?textclip_tokenizer = CLIPTokenizerFast.from_pretrained(model_id)#?Load a processor to preprocess?the?imagesclip_processor = CLIPProcessor.from_pretrained(model_id)#?Main model for generating text?and?image?embeddingsmodel = CLIPModel.from_pretrained(model_id)在加載模型后,預處理輸入會非常簡單。讓我們從分詞器開始,看看預處理輸入時會發生什么:
# Tokenize?our?inputinputs = clip_tokenizer(caption, return_tensors="pt")這會輸出一個包含輸入ID的字典:
{'input_ids': tensor([[49406, 320, 6829, 1629, 530,?518,?2583, 49407]]),?'at-
tention_mask': tensor([[1, 1,?1,?1,?1,?1,?1,?1]])}
要查看這些ID代表的內容,我們可以通過使用名稱貼切的convert_ids_to_tokens函數將它們轉換為詞元:
# Convert our?input?back?to?tokensclip_tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])?這會給出以下輸出:
['<|startoftext|?>',
'a</w>',
'puppy</w>',
'playing</w>',
'in</w>',
'the</w>',
'snow</w>',
'<|endoftext|>']
正如我們之前經常看到的,文本會被拆分成詞元(tokens)。此外,我們現在還看到文本的開頭和結尾被明確標識,以便將其與潛在的圖像嵌入區分開來。您可能還會注意到[CLS]詞元缺失了——在CLIP模型中,[CLS]詞元實際上用于表示圖像嵌入。
現在我們已經對標題進行了預處理,可以創建其嵌入向量:
# Create a?text?embeddingtext_embedding = model.get_text_features(**inputs)text_embedding.shape這會生成一個包含512個值的嵌入向量:
torch.Size([1, 512])
在創建圖像嵌入之前(與文本嵌入類似),我們需要按照模型的要求對圖像進行預處理,比如調整大小和形狀等特征。
我們可以使用之前創建的處理器來完成這一步:
#?Preprocess?imageprocessed_image = clip_processor(text=None, images=image, return_tensors="pt")["pixel_values"]processed_image.shape原始圖像是512×512像素。請注意,圖像預處理將其尺寸縮小到了224×224像素,這是模型期望的輸入尺寸:
torch.Size([1, 3, 224,?224])
圖9-13展示了這種預處理的結果可視化:
import torchimport numpy?as?npimport matplotlib.pyplot as?plt#?Prepare?image for visualizationimg = processed_image.squeeze(0)img = img.permute(*torch.arange(img.ndim?- 1,?-1,?-1))img = np.einsum("ijk->jik",?img)# Visualize preprocessed imageplt.imshow(img)plt.axis("off")
要將此預處理后的圖像轉換為嵌入向量,我們可以像之前一樣調用模型并查看其返回的形狀
# Create?the?image embeddingimage_embedding = model.get_image_features(processed_image)image_embedding.shape這將返回以下形狀:
torch.Size([1, 512])
請注意,所得圖像嵌入向量的形狀與文本嵌入向量的形狀相同。這一點非常重要,因為它允許我們比較兩者的嵌入向量以判斷相似性。
我們可以通過以下方式計算它們的相似度:首先對嵌入向量進行歸一化處理,然后計算點積得到相似度得分:
#?Normalize?the embeddingstext_embedding /= text_embedding.norm(dim=-1, keepdim=TΓue)image_embedding /= image_embedding.norm(dim=-1, keepdim=TΓue)# Calculate?their similaritytext_embedding = text_embedding.detach().cpu().numpy()image_embedding = image_embedding.detach().cpu().numpy()score = np.dot(text_embedding, image_embedding.T)這將給出如下相似度得分:
array([[0.33149648]], dtype=float32)
我們得到的相似性得分為0.33,但若不清楚模型對低分與高分的判定標準,這一結果將難以直接解讀。因此,我們通過圖9-14展示的更多圖像與文本示例進行擴展分析.

圖9-14. 三張圖像與三段文本之間的相似性矩陣
從矩陣中可見,與其他圖像更低的相似性得分相比(例如0.083等極低值),0.33的得分實際上已屬于較高水平。
使用Sentence Transformers加載CLIP模型.Sentence Transformers實現了多個基于CLIP的模型,可大幅簡化嵌入向量的生成過程。只需幾行代碼即可完成:
from sentence_transformers import SentenceTransformer, util# Load?SBERT-compatible CLIP modelmodel = SentenceTransformer("clip-ViT-B-32")# Encode?the?imagesimage_embeddings = model.encode(images)# Encode?the captionstext_embeddings = model.encode(captions)#Compute cosine similaritiessim_matrix = util.cos_sim(image_embeddings, text_embeddings)讓文本生成模型具備多模態能力
傳統意義上的文本生成模型——正如其名——是通過處理文本信息來運作的。諸如Llama 2和ChatGPT等模型,都擅長對文本信息進行推理并生成自然語言回應。
然而,這些模型僅局限于受訓練的單一模態(即文本)。正如之前在探討多模態嵌入模型時所見的,引入視覺能力可以顯著增強模型的功能。
對于文本生成模型,我們希望它能根據輸入的視覺信息進行推理。例如:向模型展示一張披薩的圖片,便能詢問其成分構成;展示埃菲爾鐵塔的照片,便能讓它回答建造時間或地理位置。圖9-15進一步展示了這種跨模態對話能力的具體應用場景。

圖9-15. 多模態文本生成模型(BLIP-2)的示例,該模型能夠對輸入圖像進行推理
為彌合視覺與語言領域之間的差距,研究者嘗試為現有模型引入多模態能力。其中一種方法稱為BLIP-2:通過引導式語言-圖像預訓練實現統一視覺語言理解與生成。BLIP-2是一種易用且模塊化的技術,可為現有語言模型賦予視覺能力.
BLIP-2:彌合模態差距
從頭打造多模態語言模型需要耗費大量計算資源和數據,我們必須使用數十億級別的圖像、文本以及圖文對才能構建這樣一個模型。可想而知,這絕非易事!
與其從頭開始構建架構,BLIP-2通過搭建一座名為"查詢變換器"(Querying Transformer/Q-Former)的橋梁結構,實現了視覺與語言的跨模態連接——這座橋梁巧妙地將預訓練圖像編碼器與預訓練大語言模型(LLM)銜接起來5。
該設計充分體現了技術復用理念:通過調用現有預訓練模型,BLIP-2僅需訓練這座橋梁結構,而無需對圖像編碼器和LLM進行從頭訓練,從而高效利用了現有技術及模型資源!這種創新架構如圖9-16所示。
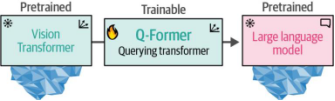
圖9-16. Querying Transformer是視覺(ViT)與文本(LLM)之間的橋梁,也是整個流程中唯一可訓練的組件
為了連接兩個預訓練模型,Q-Former 借鑒了它們的架構。它包含兩個共享注意力層的模塊:
? 圖像Transformer:用于與凍結的視覺Transformer交互以實現特征提取
? 文本Transformer:用于與大語言模型(LLM)交互
如圖9-17所示,Q-Former 分兩個階段進行訓練,每個模態各一個階段:
在第一步中,使用圖像-文檔對訓練Q-Former 使其能夠同時表征圖像和文本。這類圖像-文檔對通常采用圖像描述(如我們在訓練CLIP時所見)。
具體流程如下:
圖像被輸入到凍結的ViT中以提取視覺嵌入,這些嵌入將作為Q-Former視覺Transformer的輸入。而圖像描述則作為Q-Former文本Transformer的輸入。
5 ?Junnan Li et al.?“BLIP-2:?Bootstrapping language-image?pretraining?with?frozen?image?encoders?and?large?language models.”?International?Conference?on Machine Learning. PMLR, 2023.
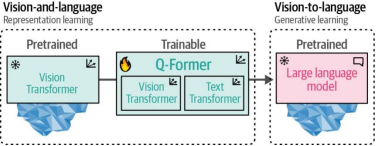
圖9-17. 在第一步中,通過表示學習同時學習視覺和語言的表征。在第二步中,這些表征被轉化為軟視覺提示以輸入大語言模型
通過這些輸入,Q-Former通過以下三個任務進行訓練:
圖像-文本對比學習
該任務試圖對齊圖像與文本的嵌入對,以最大化它們的互信息。
圖像-文本匹配
這是一個分類任務,用于預測圖像與文本對是正例(匹配)還是負例(不匹配)。
基于圖像的文本生成
訓練模型根據從輸入圖像中提取的信息生成文本。
這三個目標被聯合優化,以改進從凍結的ViT中提取的視覺表征。從某種意義上說,我們試圖將文本信息注入凍結的ViT的嵌入中,以便在LLM中使用它們。BLIP-2的這第一步如圖9-18所示。
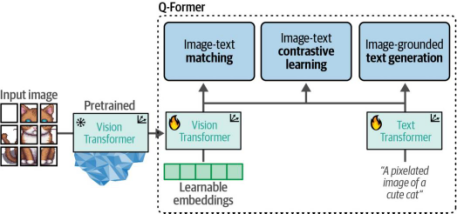
圖9-18 在第一步中,凍結的ViT輸出與其對應的描述文本共同用于訓練,通過三個類對比學習任務來學習視覺-文本表征。
第二步中,從第一步獲得的可學習嵌入已包含與對應文本信息處于相同維度空間的視覺信息。這些可學習嵌入隨后被輸入到大型語言模型(LLM)中。從某種意義上說,這些嵌入作為軟視覺提示,通過Q-Former提取的視覺表征來調節LLM的條件生成。兩者之間還包含一個全連接線性層,以確保可學習嵌入的形狀與LLM的輸入要求一致。這種將視覺轉換為語言的第二步驟如圖9-19所示。
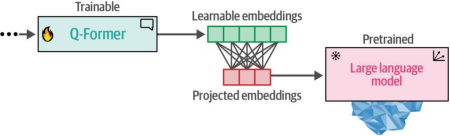
圖9-19. 在步驟2中,來自Q-Former的學習嵌入通過投影層傳輸至大型語言模型(LLM)。這些經過投影的嵌入將作為軟性視覺提示使用
當我們將這些步驟結合起來時,Q-Former能夠在同一維度空間中學習視覺和文本表示,這些表示可作為向大語言模型(LLM)提供的軟提示。因此,LLM將以與您向LLM提供提示時類似的上下文方式接收關于圖像的信息。完整的深入處理過程如圖9-20所示
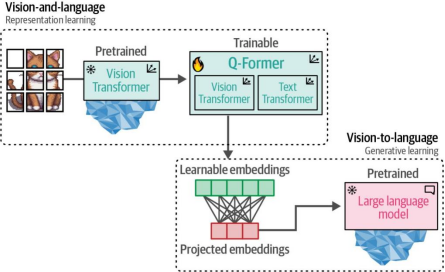
圖9-20. 完整的BLIP-2流程
自BLIP-2發布以來,相繼涌現出許多具有類似架構的視覺大語言模型(Visual LLM)。例如通過文本大語言模型實現多模態能力的LLaVA框架6,以及基于Mistral 7B大語言模型構建的高效視覺大語言模型Idefics27。盡管這些視覺大語言模型采用不同的架構設計,但其核心思路均是通過將預訓練的類CLIP視覺編碼器與文本大語言模型相連接,實現將輸入圖像中的視覺特征投射到語言嵌入空間,使其可作為大語言模型的輸入。這種架構設計與Q-Former類似,旨在彌合圖像與文本之間的表征鴻溝。
6 ?Haotian Liu et?al.?“Visual instruction?tuning.”?Advances?in?Neural?Information?Processing Systems?36?(2024).
7 ?Hugo Lauren?on et?al.?“What?matters?when?building vision-language?models?”?arXiv?preprint?arXiv:2405.02246 (2024).
預處理多模態輸入
既然我們已經了解了BLIP-2的構建方式,這種模型便有許多有趣的用例,包括但不限于圖像描述、視覺問答甚至執行提示工程。
在探討具體用例之前,我們先加載模型并探索如何使用它:
通過使用model.vision_model和model.language_model,我們可以分別查看已加載的BLIP-2模型中所采用的視覺Transformer(ViT)和生成式模型。
我們加載了組成完整流程的兩個組件:處理器和模型。
處理器類似于語言模型的分詞器,其作用是將圖像、文本等非結構化輸入轉換為模型通常期望的表示形式。
預處理圖像
首先,我們來探究處理器對圖像的處理過程。我們首先加載一張非常寬的圖片作為示例:
?
#?Load image?of a supercarcar_path =?"https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/car.png"image = Image.open(urlopen(car_path)).convert("RGB")?
該圖像的尺寸為520 × 492像素,這通常是一種非標準格式。讓我們看看處理器會對它做些什么:
#?Preprocess?the?imageinputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)inputs["pixel_values"].shape?這將得到以下形狀:
torch.Size([1, 3, 224,?224])
結果是一個224 × 224大小的圖像。比原始尺寸小了很多!這也意味著所有原始不同形狀的圖像都會被處理成正方形。因此,在輸入非常寬或高的圖像時需格外小心,因為它們可能會出現變形。
預處理文本
現在讓我們轉而用文本繼續探索這個處理器。首先,我們可以訪問用于對輸入文本進行分詞的分詞器:
blip_processor.tokenizer
這將輸出以下內容:
GPT2TokenizerFast(name_or_path='Salesforce/blip2-opt-2.7b', vocab_size=50265,
model_max_length=1000000000000000019884624838656, is_fast=True, pad-
ding_side='right', truncation_side='right', special_tokens={'bos_token':?'</
s>',?'eos_token':?'</s>',?'unk_token':?'</s>',?'pad_token':?'<pad>'},
clean_up_tokenization_spaces=True), added_tokens_decoder={
1: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normal-
ized=True, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normal-
ized=True, special=True),
}
此處使用的BLIP-2模型采用了GPT2分詞器。正如我們在第2章探討的,不同分詞器處理輸入文本的方式可能存在顯著差異。
為了探究GPT2Tokenizer的工作原理,我們可以用一個簡短的句子進行測試。首先將句子轉換為詞元ID,然后再將這些ID還原為原始詞元:
#?Preprocess?the?texttext?= ?"Her ?vocalization ?was??remarkably ?melodic"token_ids?=?blip_processor(image?,?text=text?, ?return_tensors="pt")token_ids?=?token_ids.to(device?,?torch.float16)["input_ids"][0]# Convert?input?ids back?to?tokenstokens?=?blip_processor.tokenizer.convert_ids_to_tokens(token_ids)得到的詞元如下:
['</s>', ?'Her', ?'?vocal', ?'ization', ?'?was',??'?remarkably',??'?mel',??'odic']
當我們檢查令牌時,您可能會注意到某些令牌開頭有一個奇怪的符號——即?符號。這實際上應該是一個空格。然而,某個內部函數會將特定代碼點的字符偏移256位使其可顯示。因此,原本空格(代碼點32)就變成了?(代碼點288)。出于說明目的,我們將把這些符號轉換為下劃線:
#?Replace?the space?token with?an?underscoretokens ?=??[token.replace("?"?, ?"_?") ?for token?in tokens]這為我們提供了更美觀的輸出:
['</s>', ?'Her', ?'?_vocal',??'ization', ?'?_was',??'?_remarkably',??'?_mel',??'odic']
輸出顯示下劃線表示單詞的起始位置。通過這種方式,可以識別由多個詞元組成的單詞。
用例1:圖像字幕生成
BLIP-2這類模型最直接的應用是為數據集中的圖像生成描述。例如,你可能是一家希望為其服裝生成描述的商店,或者是一位需要快速為1000多張婚禮照片手動標注標簽的攝影師。
圖像字幕的生成過程與模型處理流程高度契合:圖像會被轉換為模型可識別的像素值,這些像素值隨后輸入BLIP-2,生成可供大語言模型(LLM)用于確定合適字幕的軟視覺提示。
讓我們以一張超跑的圖像為例,使用處理器來提取符合預期形狀的像素點:
# Load?an?AI-generated image of a supercarimage = Image.open(urlopen(car_path)).convert("RGB")# Convert an?image?into?inputs and preprocess?itinputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)
下一步是使用BLIP-2模型將圖像轉換為令牌ID。完成這一步后,我們可以將這些ID轉換為文本(即生成的描述):
# Generate?image?ids?to be passed to?the?decoder?(LLM)generated_ids = model.generate(**inputs, max_new_tokens=20)# Generate?text from the?image?idsgenerated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=TΓue?)generated_text = generated_text[0].strip()an orange supercar driving on?the?road?at?sunset
這似乎是對這張圖片的完美描述!
圖像字幕生成是一個很好的入門方法,可以幫助你在進入更復雜的應用場景之前熟悉這個模型。你可以嘗試用一些圖片親自測試,觀察它在哪些場景表現良好,哪些場景存在不足。對于特定領域的圖像(如特定卡通角色或虛構生物的圖片),模型的表現可能會受限,因為它主要基于公開數據進行訓練。
讓我們以一個有趣的例子結束本章節——圖9-21展示的羅夏測驗圖像。這個心理實驗通過墨跡圖測試個體對抽象圖案的感知8,據羅伊·沙費爾(Roy Schafer)在《羅夏測驗中的精神分析解讀:理論與應用》(1954年)中的描述,受試者在墨跡中看到的形象被認為能反映其性格特征。盡管這種測試具有很強的主觀性,但這也正是它的魅力所在!
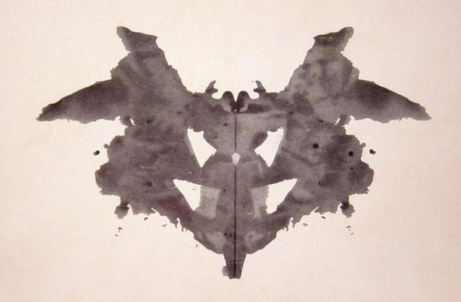
圖9-21. 羅夏墨跡測驗中的一幅圖像。你從中看到了什么?
讓我們以圖9-21展示的圖像作為輸入:
?
#?Load?Rorschach?imageurl =?"https://upload.wikimedia.org/wikipedia/commons/7/70/Rorschach_blot_01.jpg"image = Image.open(urlopen(url)).convert("RGB")# Generate captioninputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)generated_ids = model.generate(**inputs, max_new_tokens=20)generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=TΓue?)generated_text = generated_text[0].strip()?8 ?Roy Schafer. Psychoanalytic Interpretation?in Rorschach?Testing:?Theory?and Application?(1954).
與之前一樣,當我們檢查generated_text變量時,可以看到其生成的說明文字:
一幅黑白墨水繪制的蝙蝠圖像
我完全能理解模型為何會用這樣的描述來為這幅圖像添加說明文字。鑒于這實際上是一個羅夏墨跡測試,您認為這說明了模型的哪些特點?
用例2:基于多模態聊天的提示
雖然圖像描述是一項重要任務,但我們可以進一步擴展其應用場景。
在前面的示例中,我們展示了從單一模態(視覺/圖像)到另一模態(文本/描述)的轉換。
與其遵循這種線性結構,我們可以通過執行所謂的"視覺問答"(Visual Question Answering, VQA)同時呈現兩種模態。在此特定用例中,我們會向模型提供一張圖像及與該圖像相關的提問,要求其進行回答。模型需要同時處理圖像和問題。
為了演示,我們以一輛汽車的圖片為例,要求 BLIP-2 描述該圖像。為此,我們需要像之前幾次一樣對圖像進行預處理:
# Load?an?AI-generated image of a supercarimage = Image.open(urlopen(car_path)).convert("RGB")要執行視覺問答,我們不僅需要提供圖像,還需要給出提示詞(prompt)。若缺少提示詞,模型將如之前一樣僅生成描述性文本。我們將要求模型描述已處理的圖像:
# Visual?question?answeringprompt =?"Question: Write down what you see?in?this?picture. Answer:"#?Process both?the?image and?the promptinputs = blip_processor(image, text=prompt, return_tensors="pt").to(device,torch.float16)# Generate?textgenerated_ids = model.generate(**inputs, max_new_tokens=30)generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=TΓue?)generated_text = generated_text[0].strip()這給出了以下輸出:
一輛跑車在夕陽下的道路上行駛
它正確描述了圖像。然而,這是一個相當簡單的例子,因為我們的問題本質上是讓模型生成一個標題。相反,我們可以以基于聊天的方式提出后續問題。
為此,我們可以向模型提供之前的對話(包括其對問題的回答),然后提出一個后續問題:
# Chat-like promptingprompt =?"Question: Write down what you see in?this?picture. Answer: A?sportscar driving on the road?at?sunset. Question:?What?would?it?cost?me?to?drivethat car? Answer:"# Generate outputinputs = blip_processor(image, text=prompt, return_tensors="pt").to(device,torch.float16)generated_ids = model.generate(**inputs, max_new_tokens=30)generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)generated_text = generated_text[0].strip()這給出了以下答案:
$1,000,000
$1,000,000這個金額非常具體!這顯示出BLIP-2具備更多類聊天行為特征,從而能夠促成更有趣的對話。最后,我們可以通過使用ipywidgets(一款Jupyter筆記本擴展工具,可創建交互式按鈕、文本輸入框等功能)來構建交互式聊天機器人,使這一交互過程更加流暢。
from IPython.display import HTML, display
import ipywidgets as widgetsdef text_eventhandler(*args):question = args[0]["new"]if question:args[0]["owner"].value =?""# Create promptif not?memory:prompt =?" Question:?" +?question?+?" Answer:"else:template =?"Question: {} Answer:?{}."prompt =?"?".join([template.format(memory[i][0], memory[i][1])for i in?range(len(memory))]) +?" Question:?" +?question?+?"?Answer:"# Generate?textinputs = blip_processor(image, text=prompt,?return_tensors="pt")inputs = inputs.to(device, torch.float16)generated_ids = model.generate(**inputs, max_new_tokens=100)generated_text = blip_processor.batch_decode(generated_ids,skip_special_tokens=True)generated_text = generated_text[0].strip().split("Question")[0]# Update memorymemory.append((question, generated_text))#?Assign?to outputoutput.append_display_data(HTML("<b>USER:</b>?" + question))output.append_display_data(HTML("<b>BLIP-2:</b>?" + generated_text))output.append_display_data(HTML("<br>"))#?Prepare widgetsin_text = widgets.Text()in_text.continuous_update = Falsein_text.observe(text_eventhandler,?"value")output = widgets.Output()memory =?[]#?Display chat boxdisplay(widgets.VBox(children=[output, in_text],layout=widgets.Layout(display="inline-flex", flex_flow="column-reverse"),))
看起來我們可以通過對話繼續提出一系列問題。利用這種基于聊天的方法,我們本質上創建了一個能夠理解圖像的聊天機器人!
本章總結
在本章中,我們探討了通過彌合文本與視覺表征之間的鴻溝來實現大型語言模型(LLMs)多模態化的各種方法。首先討論了面向視覺的Transformer——這類模型通過圖像編碼器和圖像塊嵌入技術將圖像轉化為數值表征,使模型能夠處理不同尺度的圖像信息。
接著我們研究了如何通過CLIP構建能將圖像和文本映射為統一數值表征的嵌入模型。分析了CLIP如何利用對比學習在共享空間中對齊圖文表征,從而支持零樣本分類、聚類和檢索等任務,并介紹了開源多模態嵌入工具OpenCLIP的應用價值。
最后探索了如何使文本生成模型具備多模態能力,重點研究了BLIP-2模型的工作原理。這些多模態文本生成模型的核心思想在于將輸入圖像的視覺特征投射到文本嵌入中,以便LLM進行后續處理。演示了該模型在圖像描述生成和多模態對話式交互中的應用,通過融合兩種模態信息生成響應內容。總體而言,本章揭示了多模態技術在LLMs中的強大潛力,并展示了其在圖像描述、檢索和對話系統等領域的應用前景。
在本書第三部分,我們將深入探討模型的訓練與微調技術。第10章將重點講解文本嵌入模型的構建與微調方法——這是驅動眾多語言建模應用的核心技術。下一章將為語言模型的訓練與微調提供入門指導。






 Trae 調試C++ 基本概念)




)





:從.svg 到 SVG Vue 組件的高效蛻變?)

