目錄
1.?插入查詢結果
2?聚合查詢 (行與行之間運算)
count 計算查詢結果的行數
sum 求和
avg 求平均值
max 最大值 min 最小值
【小結】
3. group by 子句? 分組
where 條件
having 條件
4. 聯合查詢(多表查詢)
內連接
外連接
【小結】
自連接
子查詢
合并查詢
總結
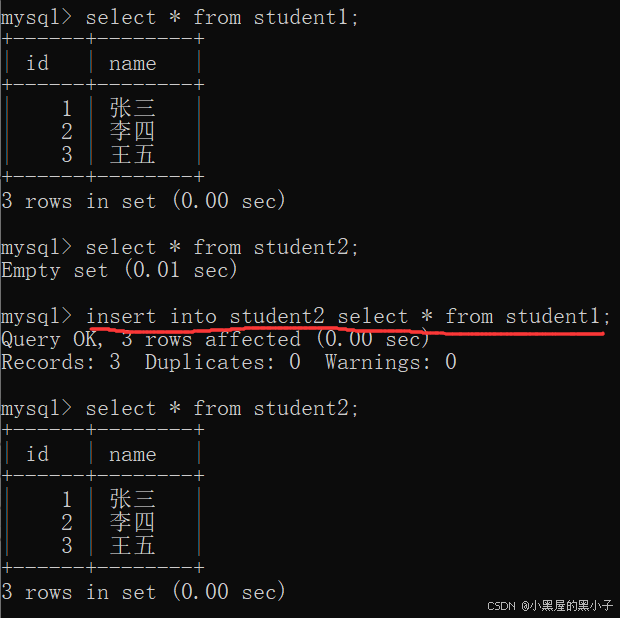
1.?插入查詢結果
查詢搭配插入使用。把查詢語句的查詢結果,作為插入的數值。
查詢結果集合的列數、類型,和插入的表的列數,類型要相匹配 —— 表結構相同
詢結果
2?聚合查詢 (行與行之間運算)
聚合查詢,是針對行和行之間進行運算的。表達式查詢,是針對列和列之間進行運算的。
sql中提供了一些"聚合函數”通過聚合函數來完成上述行之間的運算。聚合函數 ,sql提供的 庫函數。
| 函數 | 說明 |
| count([distinct] expr) | 返回查詢到的數據的 數量(查詢結果的行數) |
| sum([distinct] expr) | 返回查詢到的數據的 總和,不是數字沒有意義 |
| avg([distinct] expr) | 返回查詢到的數據的 平均值,不是數字沒有意義 |
| max([distinct] expr) | 返回查詢到的數據的 最大值,不是數字沒有意義 |
| min([distinct] expr) | 返回查詢到的數據的 最小值,不是數字沒有意義 |
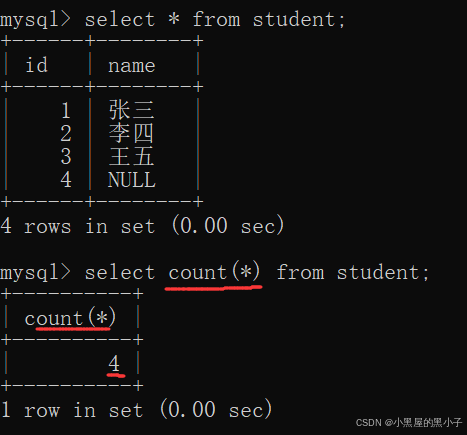
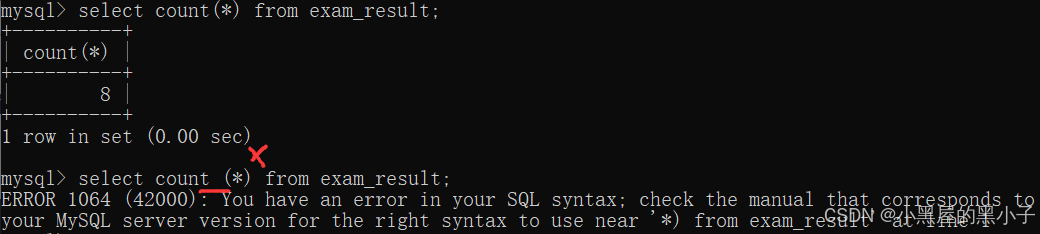
count 計算查詢結果的行數
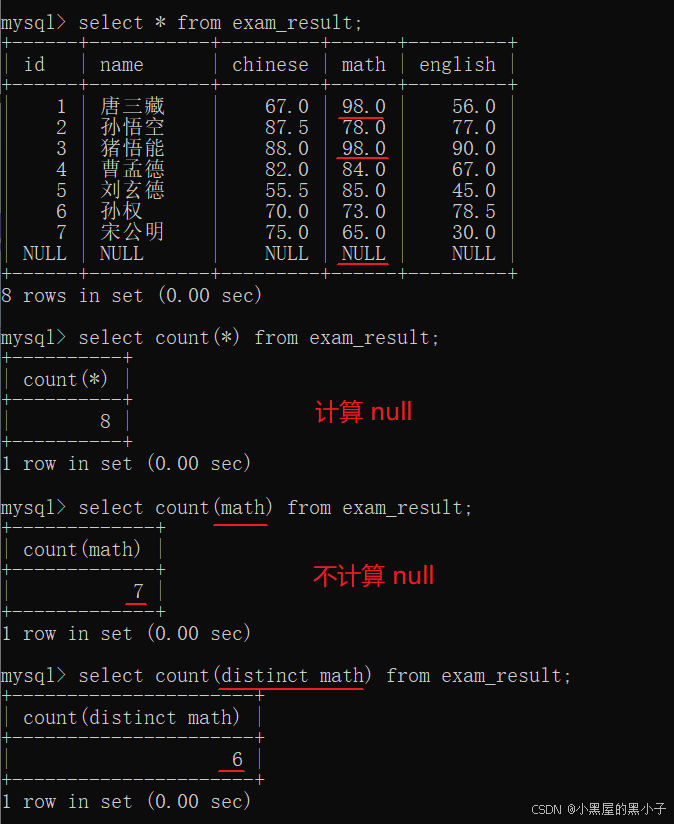
- 這個操作可以理解為,先執行select *,再針對結果集合進行統計(看看具體有幾行)。
- 4 rows in set? (0.00 sec) 這里已經能看到行數了,為什么還要使用count呢。
- 這里顯示行數是mysql客戶端內置的功能。如果是通過代碼來操作mysql服務器就沒這個功能。
- 另外,count(*)得到的結果還可以參與各種算術運算,還可以搭配其他sql使用。
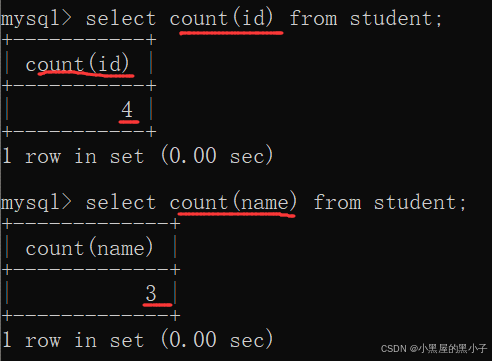
指定列進行的count
- 注意這里name 計數的是3個, name為 NULL 的數據不會計入結果。
- 如果當前的列里面有null,select * 和 指定列 兩種方式計算的count是不同的。
- 指定具體列,是可以進行去重的。而select * 不支持。

?很多語言中,函數名和后面()中間的空格是不做要求的。但在有的語言中就是例外,例如sql中。
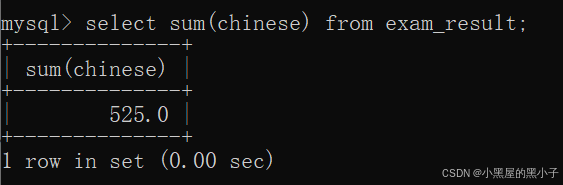
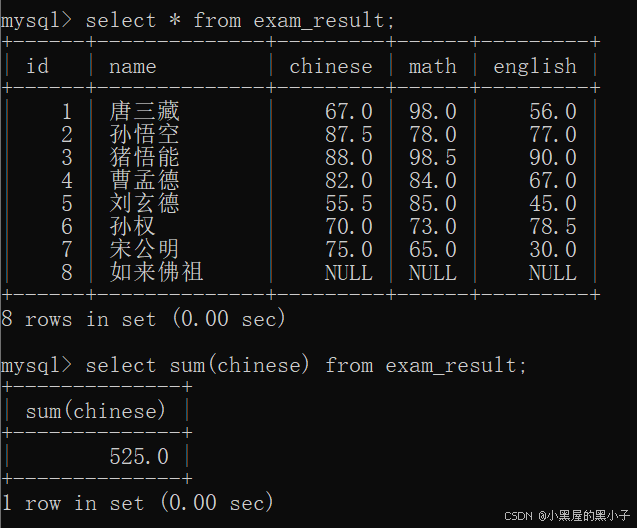
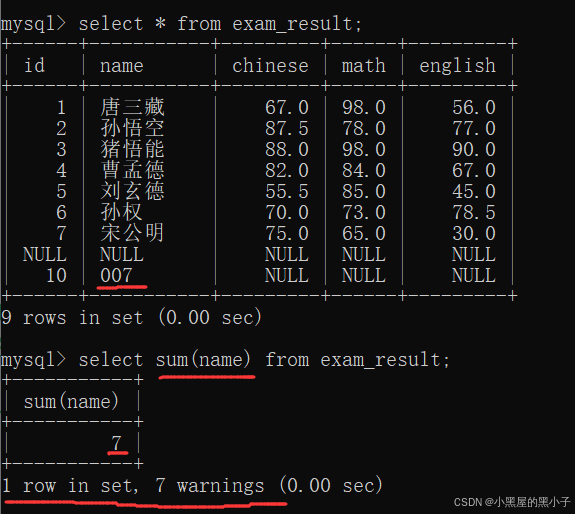
sum 求和
把這一列的若干行,進行求和(算術運算)只能針對數字類型使用。雖然字符串可以相加,但不是"算術運算"。
- 如果計算該列數據中有null,sum操作會自動跳過查詢結果為null的行。原因:null和其他數值進行運算,結果還是null,這樣sum操作就沒意義了。
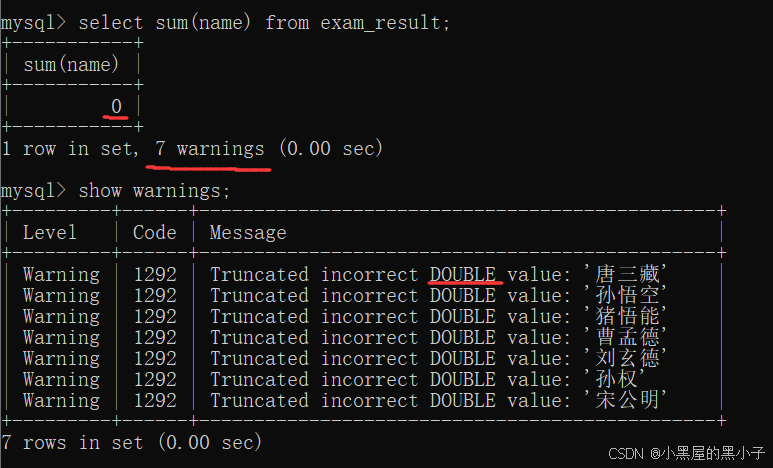
- 字符串可以相加,但不是"算術運算"。
- 這里進行字符串的相加,沒有直接報錯,只是出現了 7 個警告,有問題但不嚴重。
- 通過 show warnings 語句查看警告。我們看到在進行相加時,mysql會嘗試把這一列給轉成double類型,如果轉成了,就可以進行運算。如果沒轉成,就會警告。
這里‘007’被轉化為了double類型,參加了算數運算。
- sum()中可以指定表達式,也可以進行去重操作。
- select chinese + math + english .....把對應的列相加,得到一個臨時表
- 再把這個臨時表的結果進行,行和行相加。
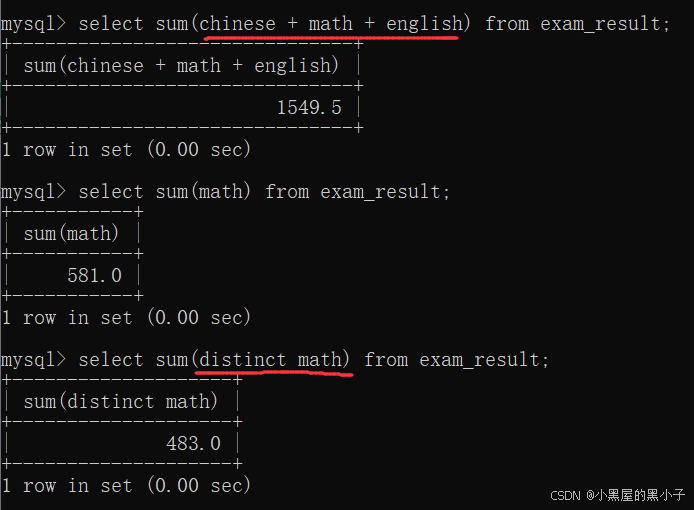
avg 求平均值
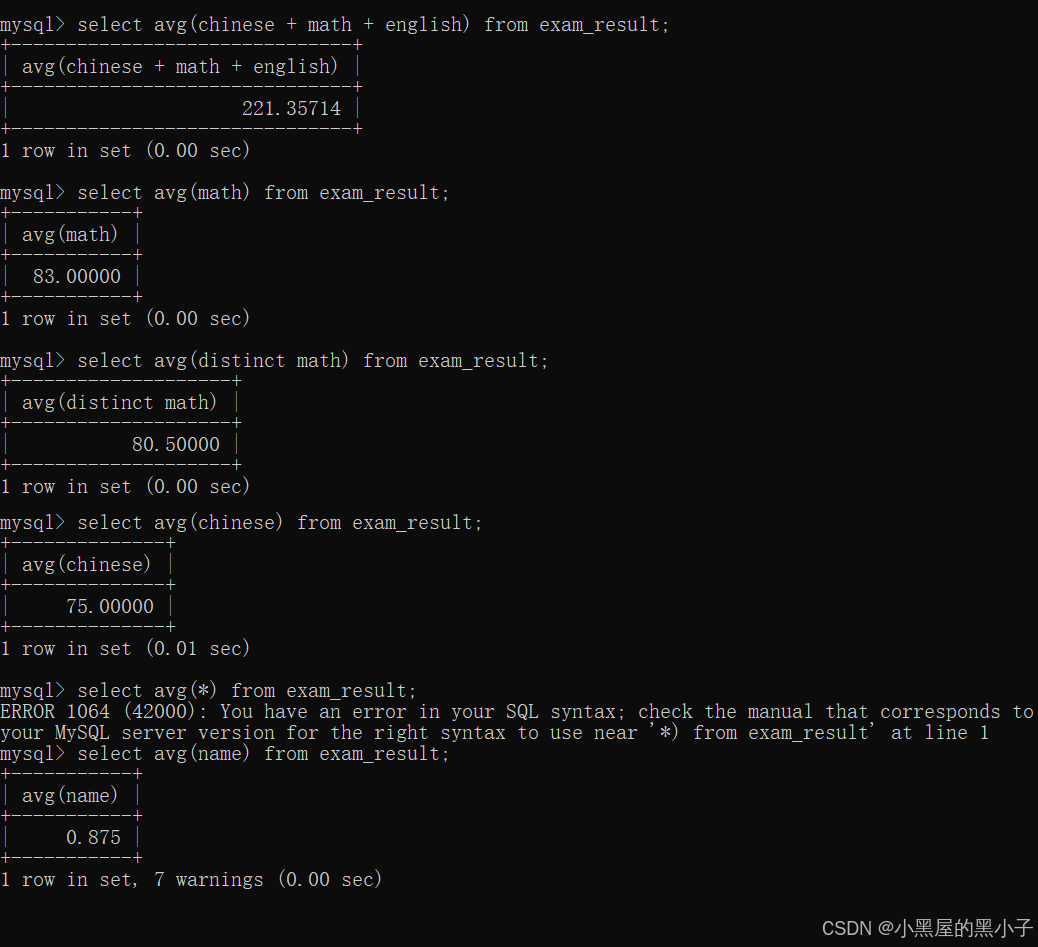
max 最大值 min 最小值
?都可以進行表達式、去重、不計算null等操作。
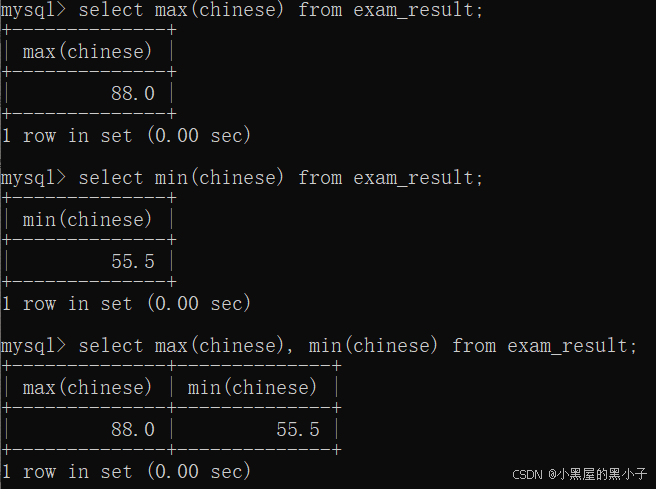
【小結】
- 都可以進行表達式、去重、不計算null等操作。
- sql是有一定的"統計計算”能力的,就像excel一樣。
- 能不能在聚合函數里面再添加一個聚合函數?sql表達邏輯的能力是有限的,如果有這樣的需求,可以使用java操作sql,復雜邏輯用java來表達, sql只是做簡單的查詢和統計。
- 這樣算平均薪資是不合理的。
- 這些聚合函數,默認都是針對這個表里的列中所有數據進行了聚合。
- 有時候需要分組聚合,(按照指定的字段,把記錄分成若干組,每一組分別使用聚合函數)
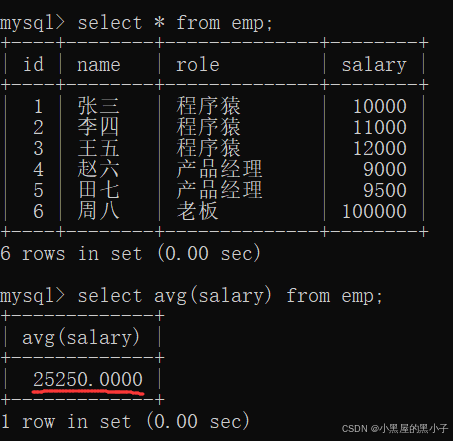
3. group by 子句? 分組
- 使用group by進行分組,針對每個分組,再分別進行聚合查詢。
- 針對指定的列進行分組,指把列里值相同的行,分到同一個組。得到若干個組,針對這些組分別使用聚合函數。
- select 指定的列,要么是帶有聚合函數的,要么是指定的group by的列。不能指定一個非聚合,非group by的列。
- role這一列,是group by指定的列。每一組所有的記錄的role,—定是相同的。
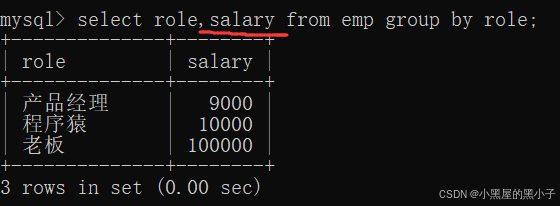
如果進行分組的時候,不進行聚合:
- 如果針對分組之后,不使用聚合函數,此時的結果就是查詢出每一組中的某個代表數據(沒有ordor by 約束的查詢結果,不具備有序性)。
- 往往還是要搭配聚合函數使用,否則這里的查詢結果,就是沒有意義的。
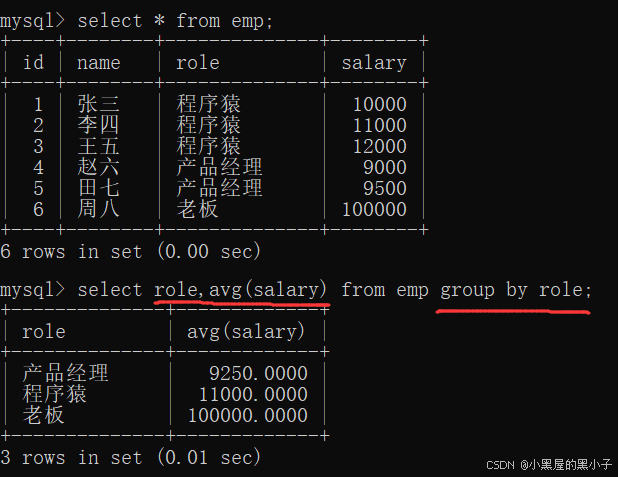
使用 group by 分組的時候,可以搭配條件篩選
需要先區分清楚,該條件是分組之前的條件,還是分組之后的條件。
where 條件
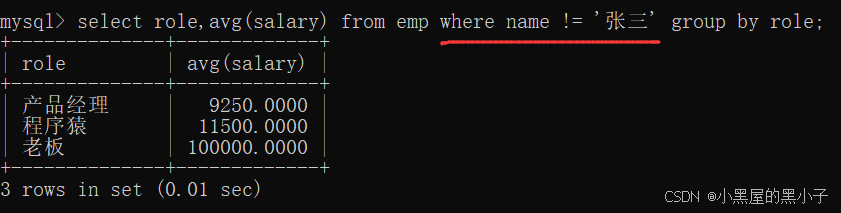
1、分組前篩選,使用 where 條件
查詢每個崗位的平均薪資,但是排除張三同學。
直接使用where即可。where子句一般寫在group by 的前面。
整個sql語句的執行順序:先執行where 條件 篩選,再進行分組,然后執行聚合函數。
having 條件
2、分組后篩選,使用 having 條件
求每個崗位的平均薪資,但是排除平均薪資超過2w的結果。
使用having描述條件。having子句一般寫在group by的后面。
整個sql語句執行順序:先進行分組,執行聚合函數,然后執行 haveing 條件 篩選

?3、在group by 分組,可以一個sql同時完成這兩類條件的篩選。查詢每個崗位的平均薪資,排除張三同學,并保留平均值<2w的結果。

分組前篩選、分組后篩選,還是兩種條件都具備,具體內容具體分析。
4. 聯合查詢(多表查詢)
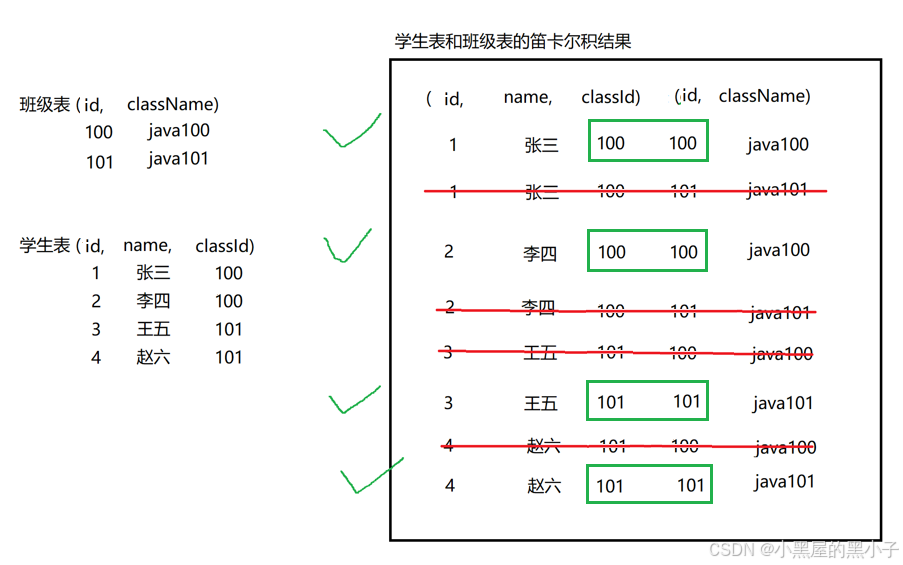
實際開發中往往數據來自不同的表,所以需要多表聯合查詢。多表查詢是對多張表的數據取笛卡爾積。
- 前面的查詢,都是針對一個表。相比之下,有些查詢則是一次性需要從多個表中進行查詢獲取記錄。聯合查詢就是把多個表聯合到一起進行查詢。
- 聯合查詢步驟:先經過笛卡爾積運算,通過連接條件篩選出有效數據,結合需求進一步篩選要查詢的記錄。
- 聯合查詢關鍵思路,在于理解"笛卡爾積"工作過程。笛卡爾積,是一種排列組合,把兩張表的記錄,盡可能的排列組合出N種情況。
- 笛卡爾積通過排列組合的方式,得到的一個更大的表。
- 笛卡爾積的列數,是兩個表的列數相加。笛卡爾積的行數,是兩個表的行數相乘
- 由于笛卡爾積簡單無腦的排列組合方式,把所有可能的情況都窮舉了一遍。包含一些合法的數據也包含非法的,無意義的數據。
- 進行多表查詢時,使用sql的條件篩選出有效的數據。通過觀察上述笛卡爾積表得出這個條件就是,where 班級表的id = 學生表的classld 也叫連接條件。
- 注意這里兩個表并沒有使用外鍵約束進行關聯的,而是通過邏輯上的關系(業務字段匹配)關聯的,例如某某學生屬于哪個班級,是客觀的實際情況。笛卡爾積窮舉出所有可能,使用連接條件(邏輯上的關系)篩選出有效數據。
- 關聯查詢可以對關聯表使用別名。
笛卡爾積在日常開發中,要非常克制的使用。
- 有時候使用起來非常的方便快捷。
- 一旦表的數據量大或者表數目多,得到的笛卡爾積就非常龐大。如果針對大表進行笛卡爾積(多表查詢),就會生成大量的臨時結果,這個過程非常消耗時間。數據庫服務器在這樣的情況下就可能卡死。
- 如果多表查詢涉及到的表數目比較多時,sql就會非常復雜,可讀性也大大降低了。
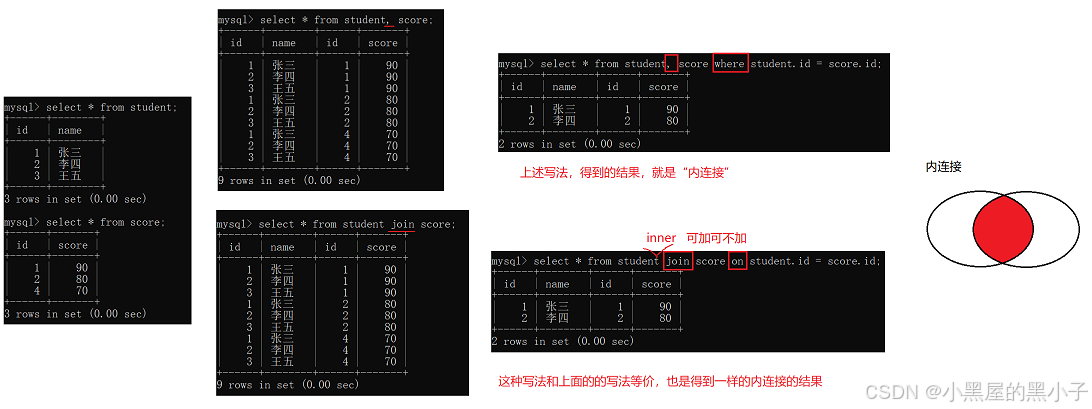
內連接
語法:
- select 字段 from 表1 別名1 , 表2 別名2 where 連接條件 and 其他條件;
- select 字段 from 表1 別名1 [inner] join 表2 別名2 on 連接條件 and 其他條件;
- 兩個sql語句是等價,一個使用? ?, ...... where ......;? ?一個使用? [inner] join ...... on......;
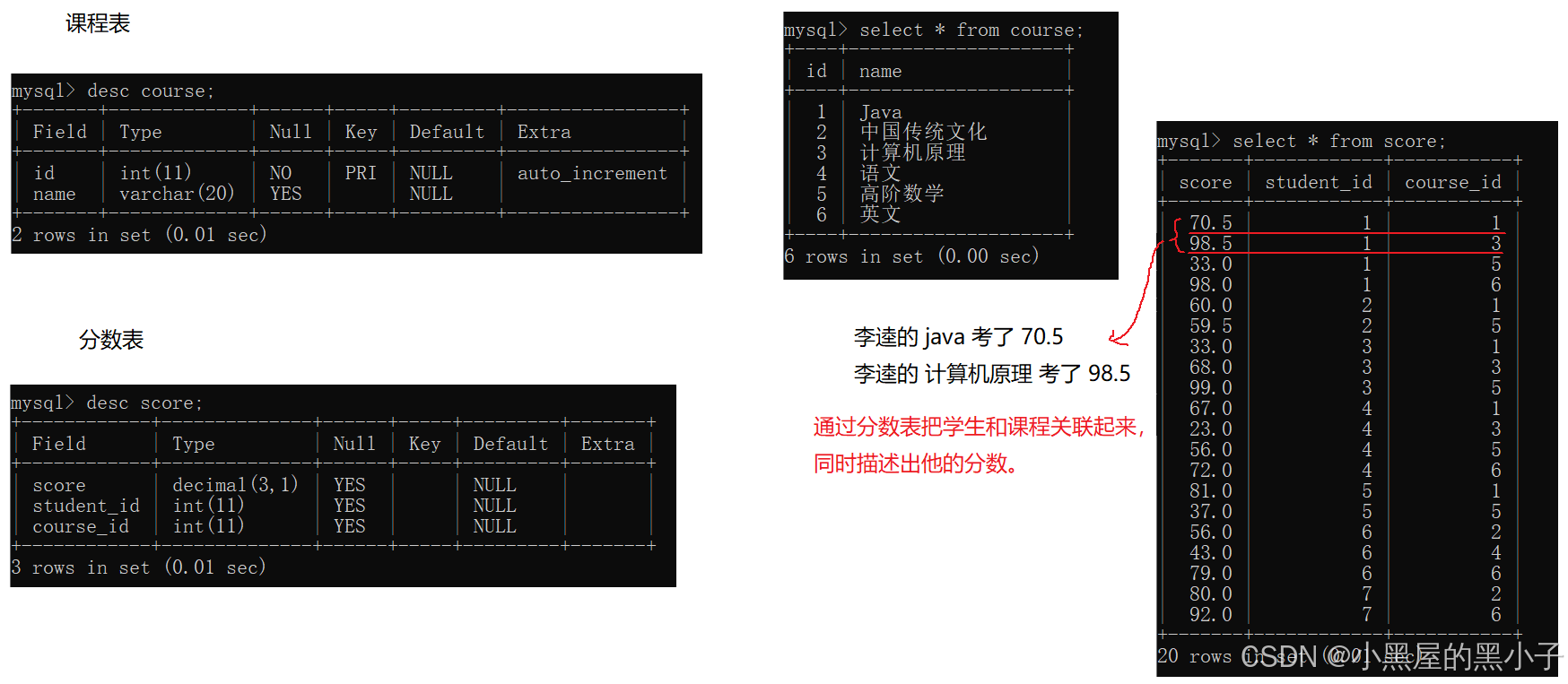
先創建幾個表:學生表、班級表、課程表、分數表(學生和課程之間的關聯表)
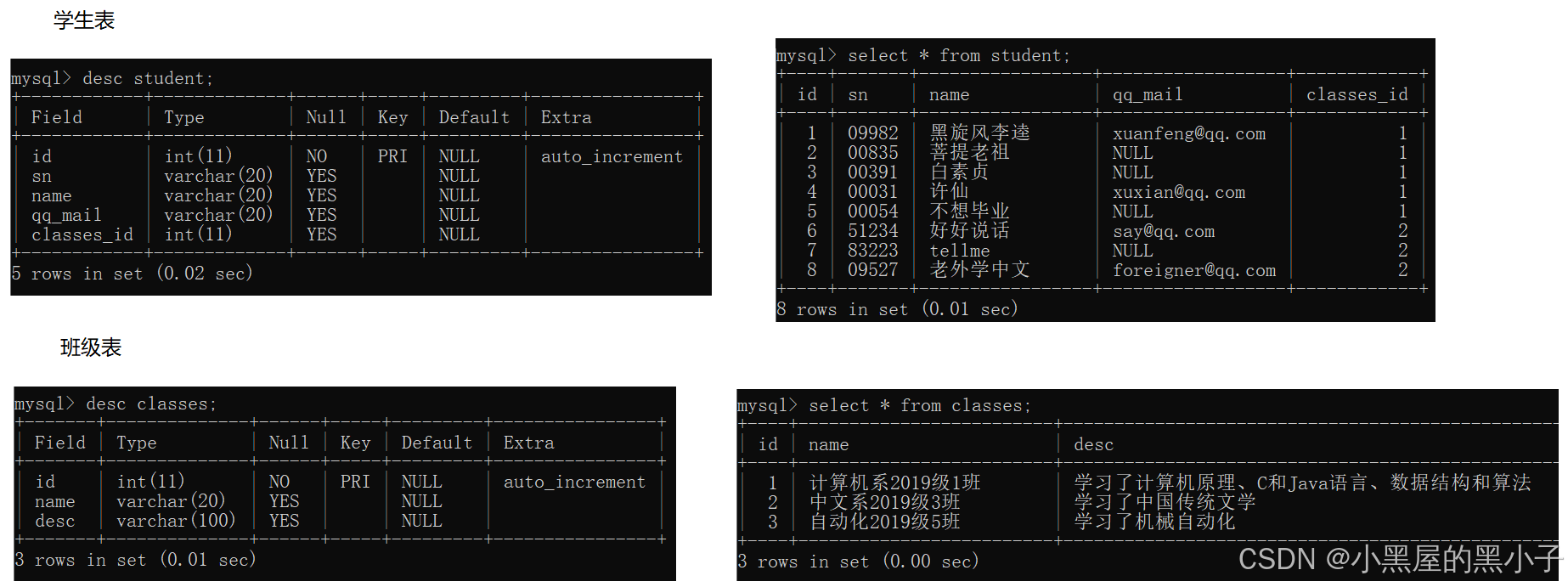
【案例1】查詢‘許仙’同學的 成績。
兩個表:student和score。怎么進行聯合查詢。
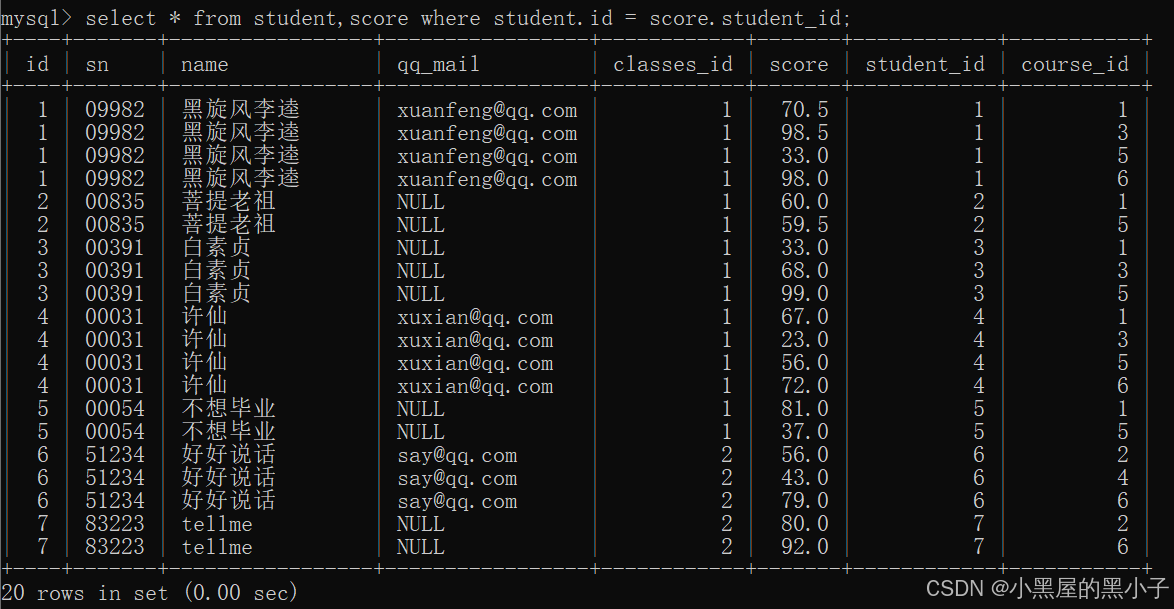
1、先把這兩個表,進行笛卡爾積。
- sql中直接通過表名中間 , 隔開就可以可以排列組合得到笛卡爾積。
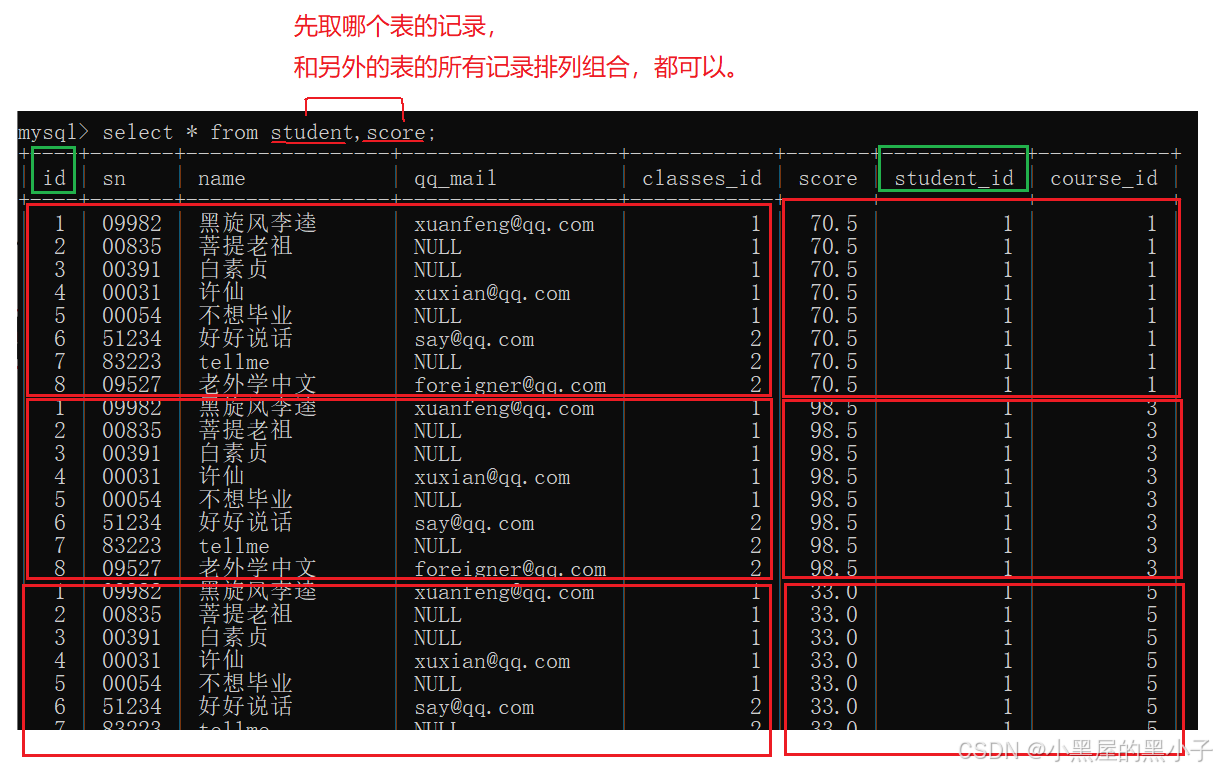
2、加上連接條件,篩選出有效數據
- 學生表的 id = 分數表的 student_id?
- 為了避免不同表中可能存在有列名相同的列當做連接條件。同時笛卡爾積后列變多,可能區分不了是哪個表中的列。
- 所以連接條件寫作:表名.列名。類似于java中的對象訪問字段。
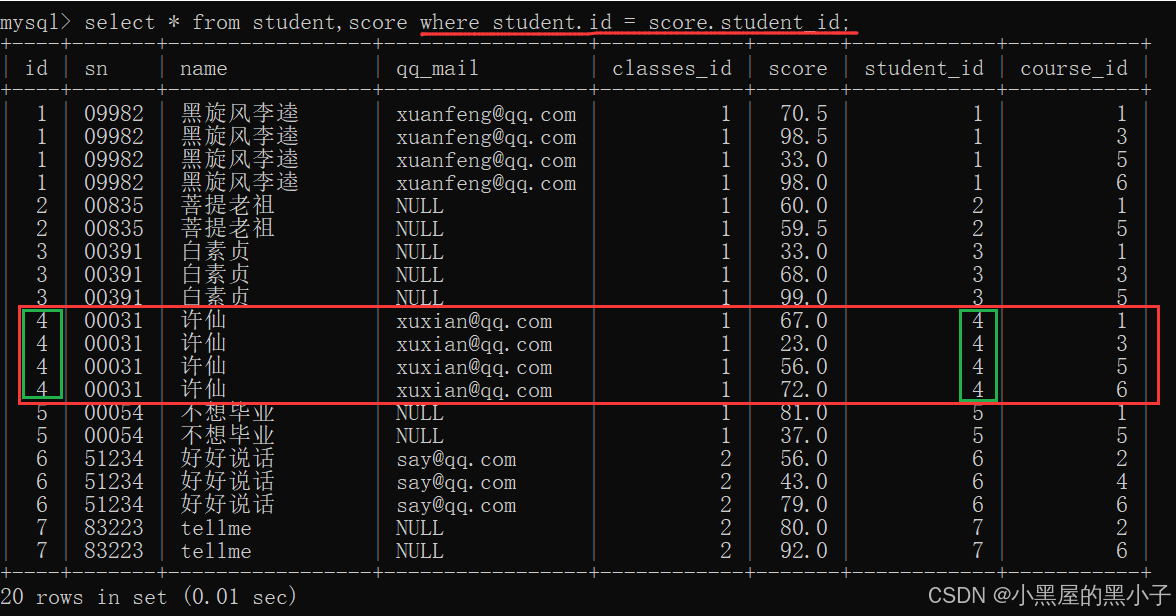
3、結合需求,進一步添加條件,針對結果進行篩選
此處是查詢許仙的成績,就可以再加上一個 student.name = '許仙'
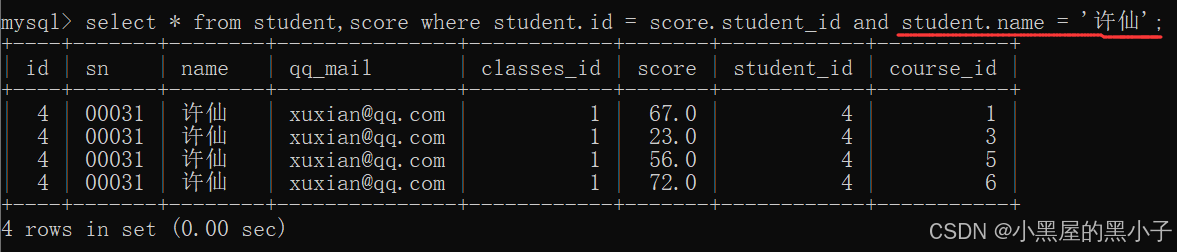
4、針對查詢到的列進行精簡,只保留需求中的列

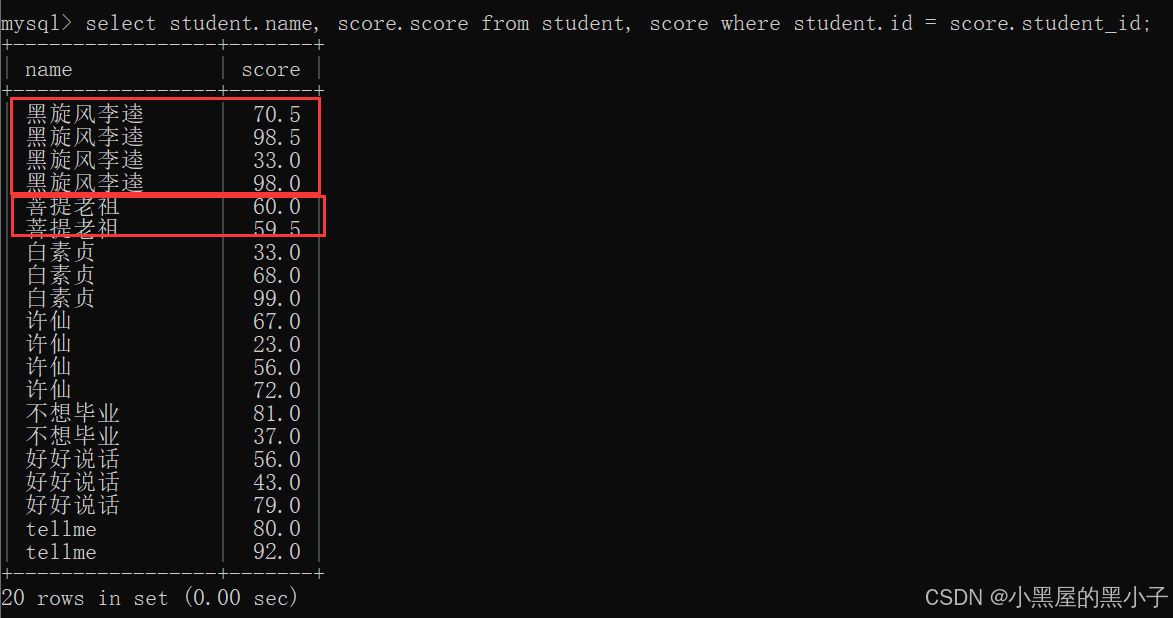
【案例2】查詢所有同學的總成績,及同學的個人信息。
分析:
- 之前是通過表達式查詢來完成總成績的計算(列與列之間運算)。
- 這里同學的成績是按照行來組織的,使用聚合查詢(行與行之間運算),聚合函數sum完成總成績的計算,同時搭配group by子句 按照同學進行分組。
- 基于多表查詢和聚合查詢綜合運用。
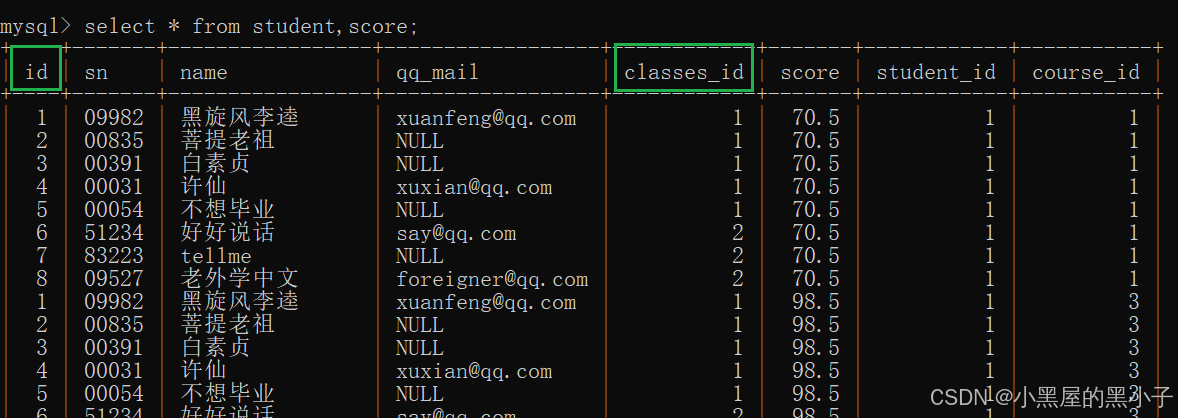
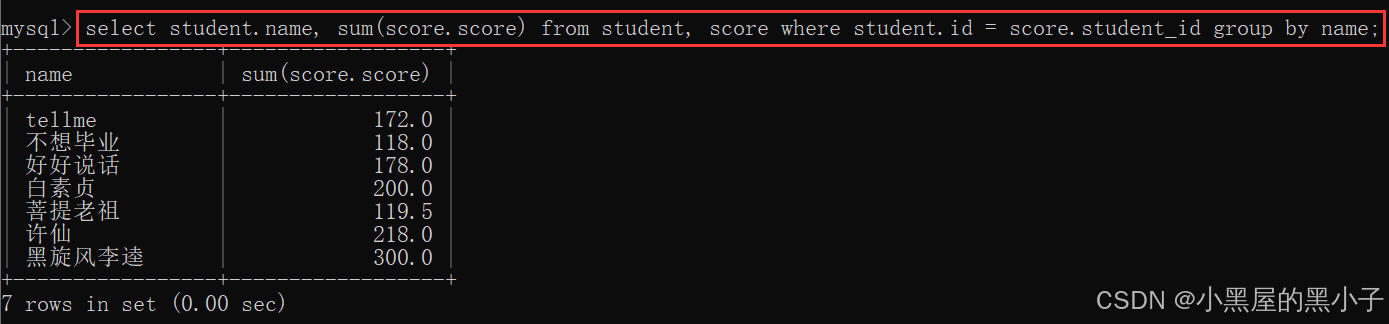
1、先進行笛卡爾積
2、指定連接條件
student.id = class.student_id?
3、先精簡列
4、針對上述結果,再進行group by聚合查詢。
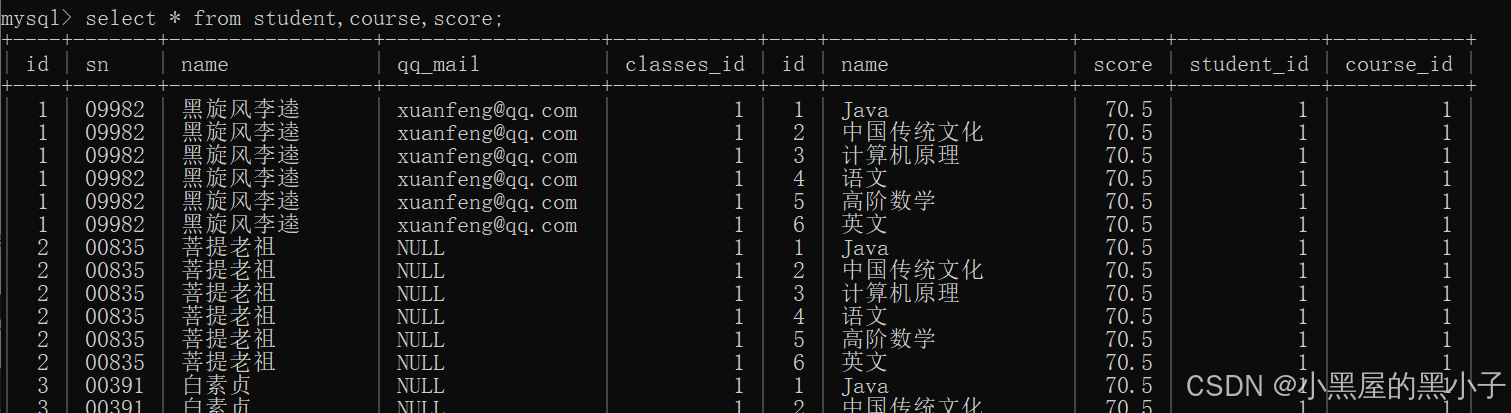
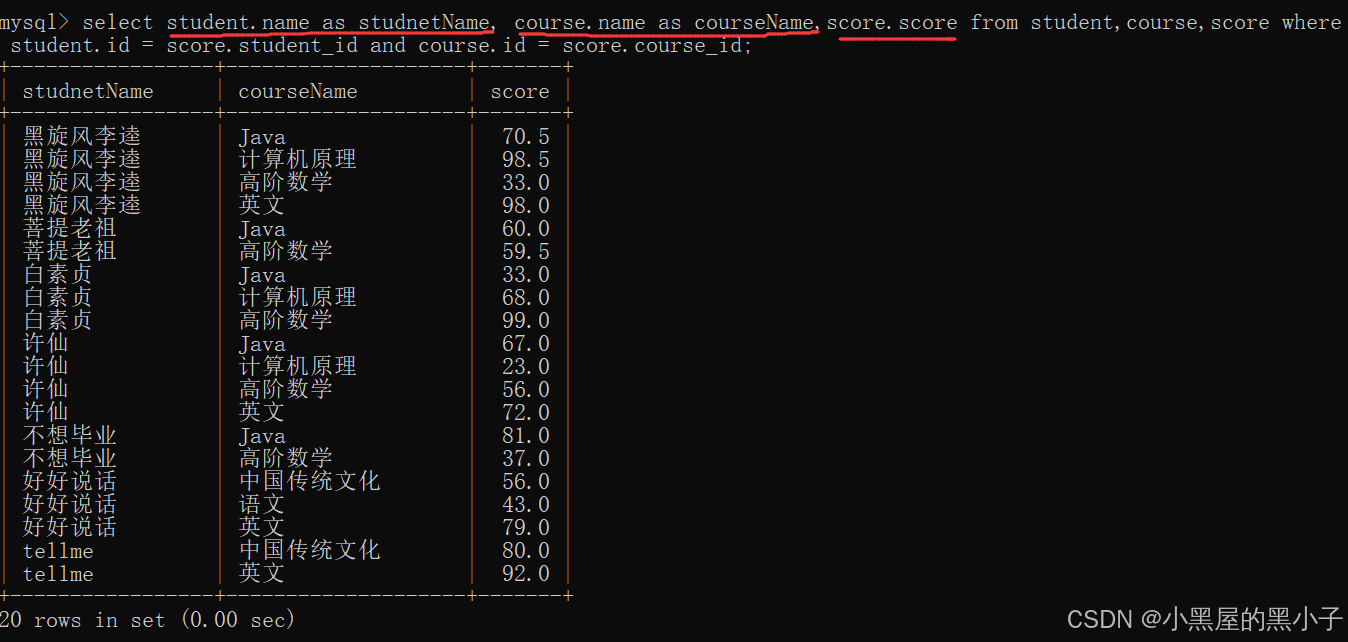
【案例3】查詢每個同學,每門課程的課程名字和分數。
三張表:student,course,score
1、先進行笛卡爾積
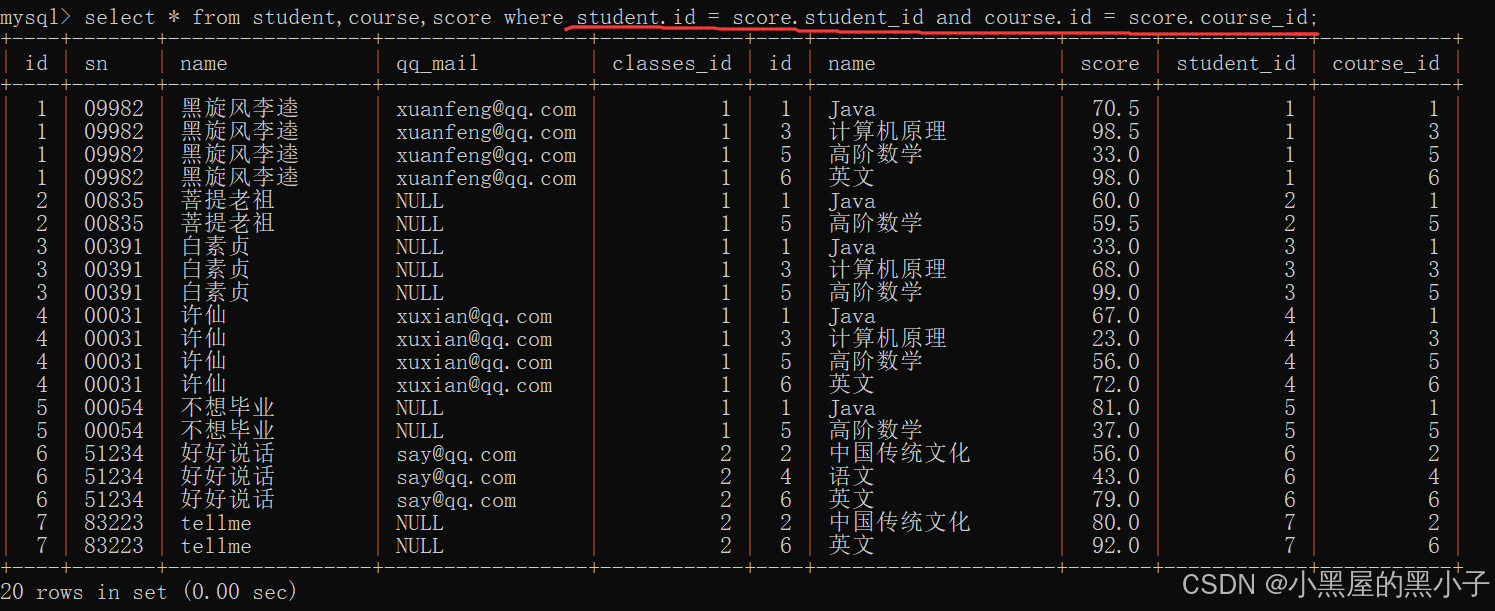
2、指定連接條件,篩選數據
三個表,涉及到兩個連接條件。分數表把學生和課程關聯起來,同時描述出他的分數。
3、精簡列

外連接
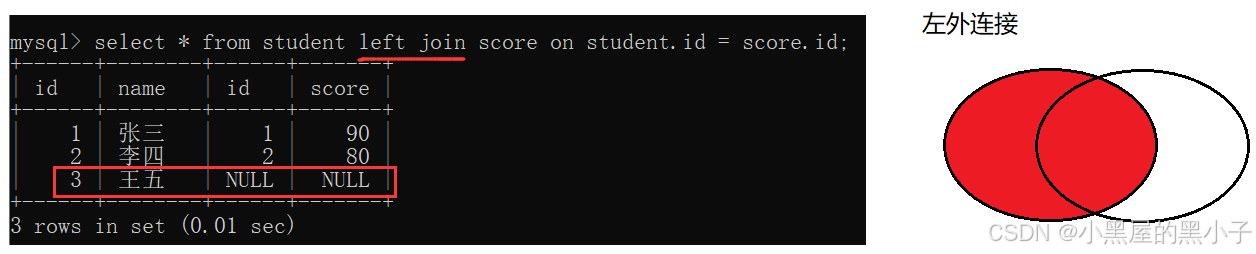
外連接分為左外連接和右外連接。如果聯合查詢,左側的表完全顯示就說是左外連接;右側的表完全顯示就說是右外連接。
語法:
-- 左外連接,表1完全顯示
- select 字段名 from 表名1 left join 表名2 on 連接條件;
-- 右外連接,表2完全顯示
- select 字段 from 表名1 right join 表名2 on 連接條件;
如果這兩個表,里面的記錄都是存在對應關系,內連接和外連接的結果是一致的。
- student 中的每一條記錄,都可以在score表中找到對應。
- 每一個score中的記錄,也可以在student中找到對應。

如果兩個表,里面存在不對應的記錄,內連接和外連接就會出現差別。
這種情況很少出現,因為在插入數據的時,一般都會進行嚴格的校驗,但不否認不會存在這樣的情況。例如王五同學缺考了,沒有成績。

內連接
左外連接,left join
- 左外連接,就是以左側表為基準。
- 保證左側表的每個數據都會出現在最終結果里。
- 如果左表中的記錄在右側表中不存在,對應的列就填成null
右外連接,right join
- 右外連接,是以右側表為基準。
- 保證右側表的每個數據都會出現在最終結果里。
- 如果右表中的記錄在左側表中不存在,對應的列就填成null

【小結】
- 多表查詢運行過程中會產生大量的中間數據。在日常開發中,要非常克制的使用。使用時要盡可能明確,是針對多大規模的表使用以及產生的結果規模。
- 即使使用,大多數情況下都是使用內連接。外連接只是針對特殊情況,給出的特殊處理方式。
自連接
- 自連接是指在同一張表連接自身進行查詢。自己和自己進行笛卡爾積。(特殊技巧)
- 特殊情況下特殊用法:sql中的條件都是列和列之間進行比較。但是有的需求可能涉及到行和行比較。所以可以使用自連接,把行的關系轉換成列的關系。
【案例】顯示所有“計算機原理”成績比“Java”成績高的成績信息
此處course_id 為 1 的是Java的成績,為 3 的是計算機原理的成績,看哪個同學的計算機原理的成績比Java的成績高,但是它們處在不同的行中,無法直接進行比較。?我們使用自連接方式,把行的關系轉換成列的關系。
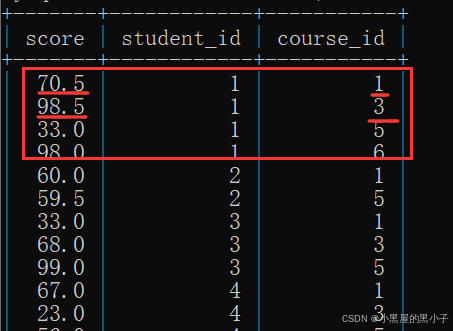
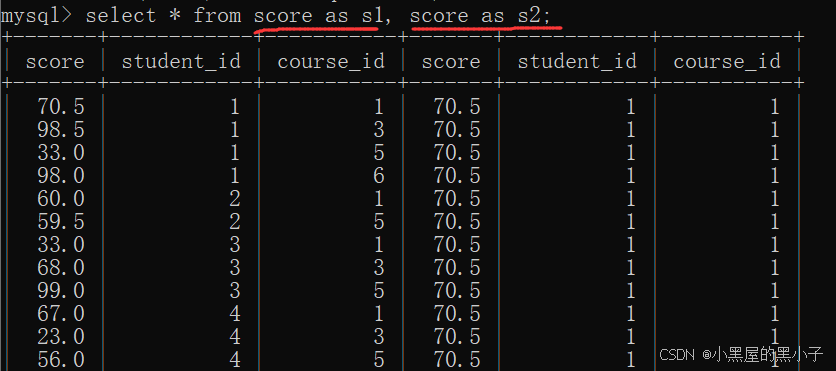
1、自己與自己進行笛卡爾積
- score, score 這樣寫報錯了,原因:score不是唯一的表/別名。
- 利用別名,使兩個表名區別開。
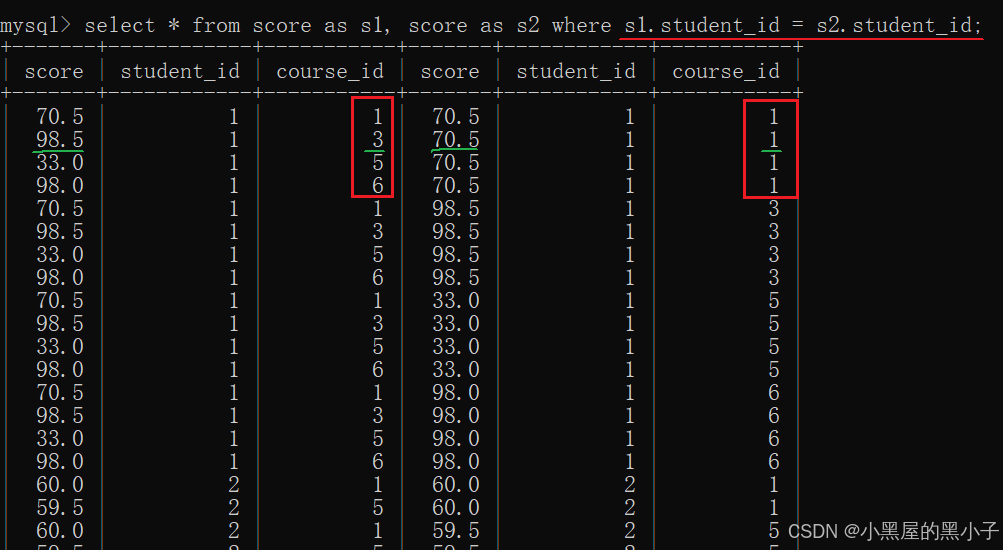
2、指定連接條件,篩選數據
- 這里可以按照學生id進行篩選,也可以使用課程id進行篩選。主要看關注的是學生信息還是課程信息。
- 此處關注的是學生信心,按照學生信息去篩選。
3、結合需求,進一步添加條件,針對結果進行篩選
- 得到的結果,左側表分數列是計算機原理;右側分數列是java。而且是不同學生的。
4、結合需求,再添加條件,針對結果進行篩選
得到計算機課程成績大于java課程成績的信息。
5、精簡列
- 如果想要學生姓名,就可以拿這個表和學生表做笛卡爾積
- 如果想要課程名字,就可以拿這個表和課程表做笛卡爾積




子查詢
- 子查詢是指嵌入在其他sql語句中的select語句,也叫嵌套查詢。本質上是在"套娃"。
- 把多個簡單的SQL拼成一個復雜的SQL。一個大的復雜的東西,不方便看也不好理解。
- 違背了一貫的編程原則:平時寫代碼都講究,把大的拆分成小的,把復雜的拆分成多個簡單的。
- 在開發中并不建議使用子查詢,應該使用多個簡單sql替代。但是還是要了解一下的。
1、單行子查詢:返回一行記錄的子查詢
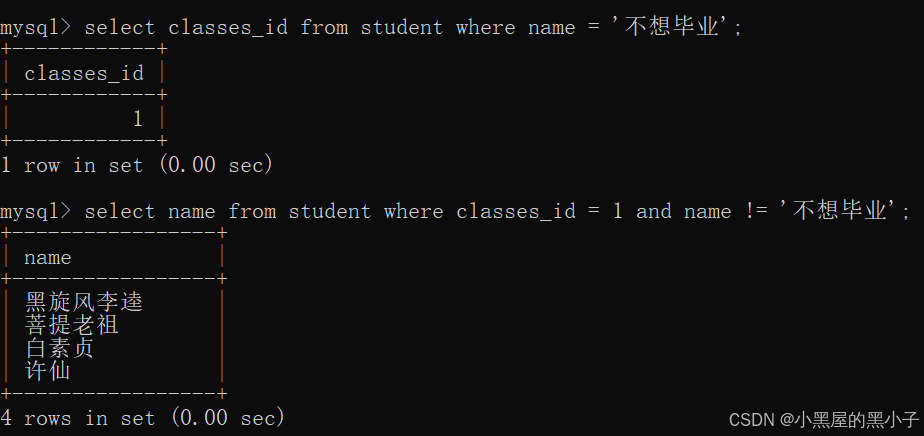
【案例】查詢與“不想畢業” 同學的同班同學:
- 先找到“不想畢業”同學,所在的班級classes_id 為 1;
- 然后找到班級classes_id 為 1 的其他同學,就找到“不想畢業”同學的同班同學。
通過子查詢方式一步完成:
這里嵌套的select 語句,返回結果必須是一行的記錄。這里直接把嵌套select 語句當成一個數值使用。

2、多行子查詢:返回多行記錄的子查詢
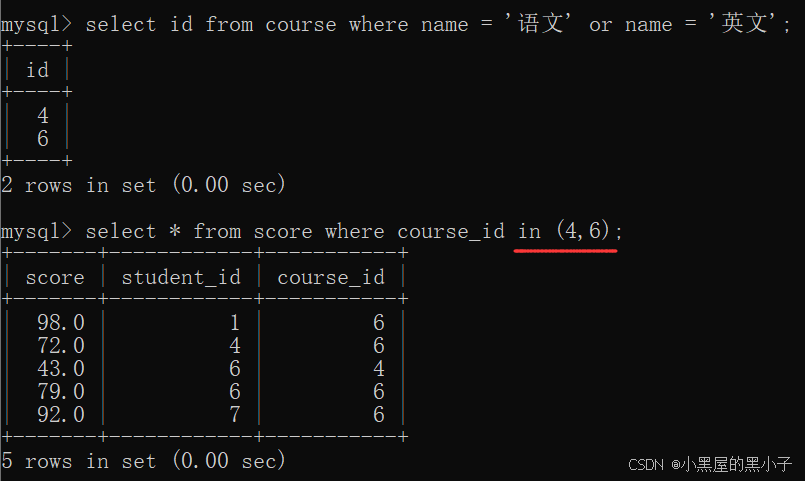
【案例】查詢“語文”或“英文”課程的成績信息
使用聯合查詢方法:兩個表,course,score

使用多行子查詢,搭配 in 關鍵字使用。in?表示某個值是否存在這個集合中。
- 先通過課程名字,找到課程id。
- 再通過課程id在分數表中進行查詢
通過子查詢方式一步完成:
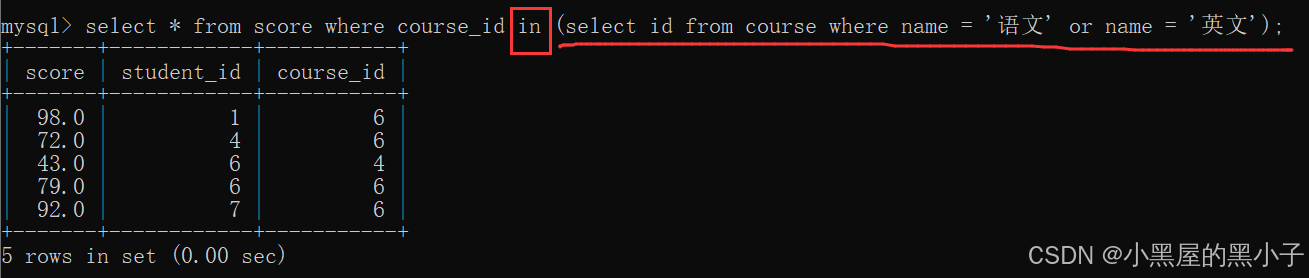
多行子查詢,也可以搭配 exists?關鍵字使用。相比于 in 關鍵字,搭配 exists 更復雜,運行效率還比較低。唯一的優勢是節省內存空間,僅此而已。但是內存并不是影響代碼的瓶頸的設備。這里不做過多介紹,可自行了解。
合并查詢
- 在實際應用中,為了合并多個select的執行結果,可以使用集合操作符 union,union all 關鍵字。把多個sql查詢的結果集合,合并到一起。
- 使用union?和 union all時,合并的兩個sql的結果集的列,需要匹配。列的個數和類型,要一致的(列名不需要一致) —— 表結構相同。
- union 該操作符用于取得兩個結果集的并集。當使用該操作符時,會自動去掉結果集中的重復行(去重)。
- union all 則不會去掉結果集中的重復行。
- MySQL中的 union 是聯合/合并的意思。在 C語言的自定義數據類型章節中講述過,union 是聯合體的意思,作用給一個內存空間賦予了多種解釋方式。極致的省內存。Java中沒有聯合體。
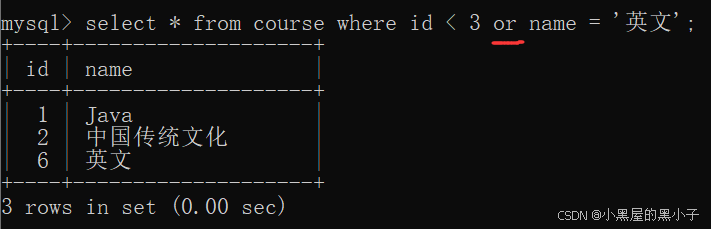
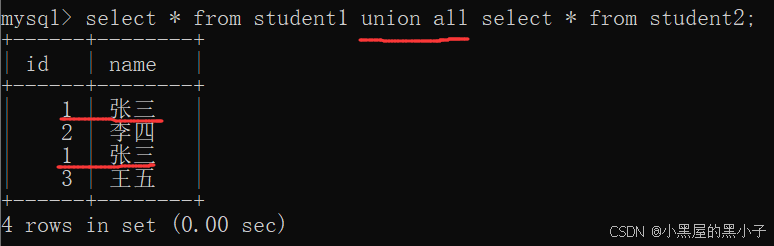
【案例】查詢id小于3,或者名字為“英文”的課程:
- 使用 or 操作符,但只能針對一個表。
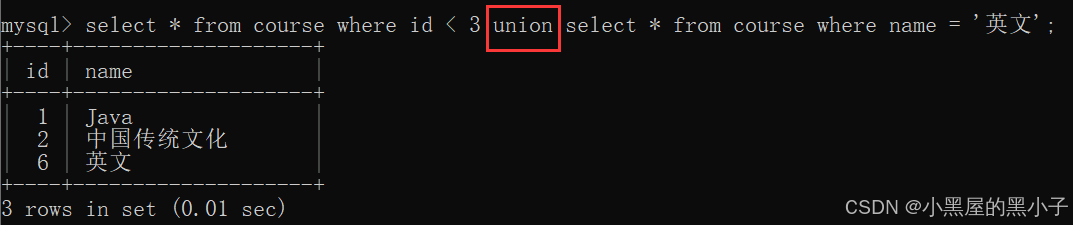
- 使用 union 操作符 進行合并查詢。
- 允許把兩個表不同的表,查詢結果合并在一起。
- 合并的兩個sql的結果集的列,需要匹配。列的個數和類型,要一致的(列名不需要一致)。
- 最終查詢出的臨時表的列名與第一個表的列名相同。
- 使用union all 操作符合并查詢,不會去掉結果集中的重復行。

總結
插入查詢結果:
insert into student2 select * from student1;
insert into student2(name, email)? select name, qq_mail from student1;
聚合查詢:
1、聚合函數:count、sum、avg、max、min
2、分組查詢:group by? ? ? ? ? ?分組前篩選 where...group by...? ? ? 分組后篩選group by...having...
聯合查詢:
3、內連接:
select ... from 表1, 表2 where 條件
-- inner可以缺省
select ... from 表1 [inner]?join 表2 on 條件 where 其他條件
4、外連接:
左外連接:select ... from 表1 left join 表2 on 條件 where 其他條件
右外連接:select ... from 表1 right?join 表2 on 條件 where 其他條件
5、自連接:
select ... from 表1,表1 where 條件
select ... from 表1 join 表1 on 條件
6、子查詢:
-- 單行子查詢
select ... from 表1 where 字段1 = (select ... from ...);
-- 多-行子查詢
select ... from 表1 where 字段1 in?(select ... from ...);
7、合并查詢
-- UNION:去除重復數據
select ... from ... where 條件? union? select ... from ... where 條件
-- UNION ALL:不去重
select ... from ... where 條件? union all? select ... from ... where 條件
-- 使用UNION和UNION ALL時,前后查詢的結果集中,字段類型與個數需要一致。
SQL查詢中各個關鍵字的執行先后順序: from > on > join > where > group by > with > having > select > distinct > order by > limit???????
?
好啦Y(^o^)Y,本節內容到此就結束了。下一篇內容一定會火速更新!!!
后續還會持續更新MySQL方面的內容,還請大家多多關注本博主,第一時間獲取新鮮的知識。
如果覺得文章不錯,別忘了一鍵三連喲!?

)












 Trae 調試C++ 基本概念)




)