REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology
NAACL-HLT 2024
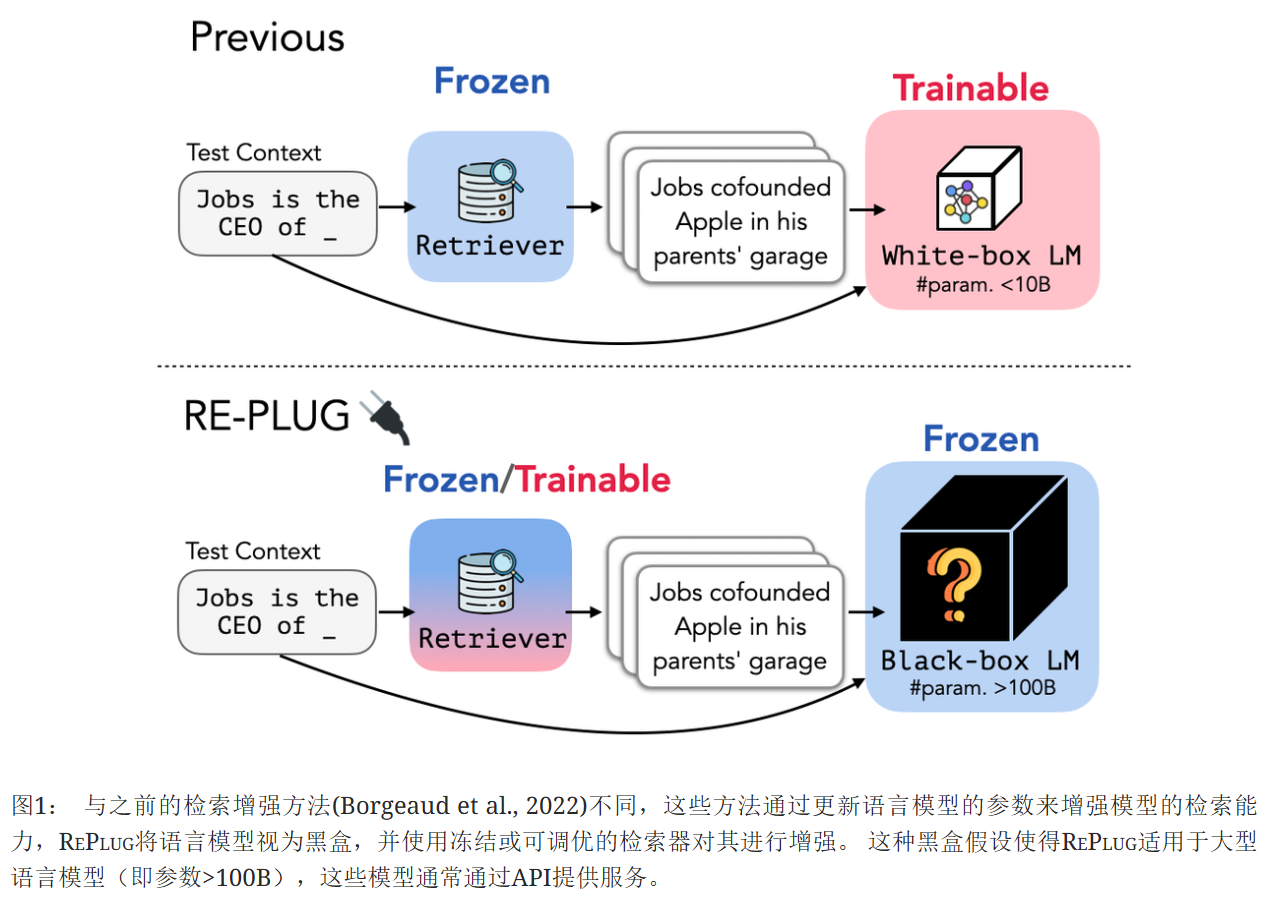 在這項工作中,我們介紹了RePlug(Retrieve and?Plug),這是一個新的檢索增強型語言模型框架,其中語言模型被視為黑盒,檢索組件被添加為一個可調優的即插即用模塊。?給定一個輸入上下文,RePlug首先使用一個現成的檢索模型從外部語料庫中檢索相關的文檔。?檢索到的文檔被添加到輸入上下文的前面,并輸入到黑盒語言模型中以進行最終預測。?由于語言模型上下文長度限制了可以添加的文檔數量,我們還引入了一種新的集成方案,該方案使用相同的黑盒語言模型并行編碼檢索到的文檔,使我們能夠輕松地用計算換取準確性。?如圖1所示,RePlug非常靈活,可以與任何現有的黑盒語言模型和檢索模型一起使用。
在這項工作中,我們介紹了RePlug(Retrieve and?Plug),這是一個新的檢索增強型語言模型框架,其中語言模型被視為黑盒,檢索組件被添加為一個可調優的即插即用模塊。?給定一個輸入上下文,RePlug首先使用一個現成的檢索模型從外部語料庫中檢索相關的文檔。?檢索到的文檔被添加到輸入上下文的前面,并輸入到黑盒語言模型中以進行最終預測。?由于語言模型上下文長度限制了可以添加的文檔數量,我們還引入了一種新的集成方案,該方案使用相同的黑盒語言模型并行編碼檢索到的文檔,使我們能夠輕松地用計算換取準確性。?如圖1所示,RePlug非常靈活,可以與任何現有的黑盒語言模型和檢索模型一起使用。
還介紹了RePlug LSR(RePlug?with?LM-Supervised?Retrieval),這是一種訓練方案,它可以進一步改進RePlug中的初始檢索模型,并利用來自黑盒語言模型的監督信號。?核心思想是使檢索器適應語言模型,這與之前的工作(Borgeaud et al., 2022)相反,后者使語言模型適應檢索器。?我們使用了一個訓練目標,該目標更傾向于檢索能夠提高語言模型困惑度的文檔,同時將語言模型視為一個凍結的黑盒評分函數。
REPLUG
新的檢索增強型LLM范式,其中語言模型被視為黑盒,檢索組件被添加為一個可能可調優的模塊。
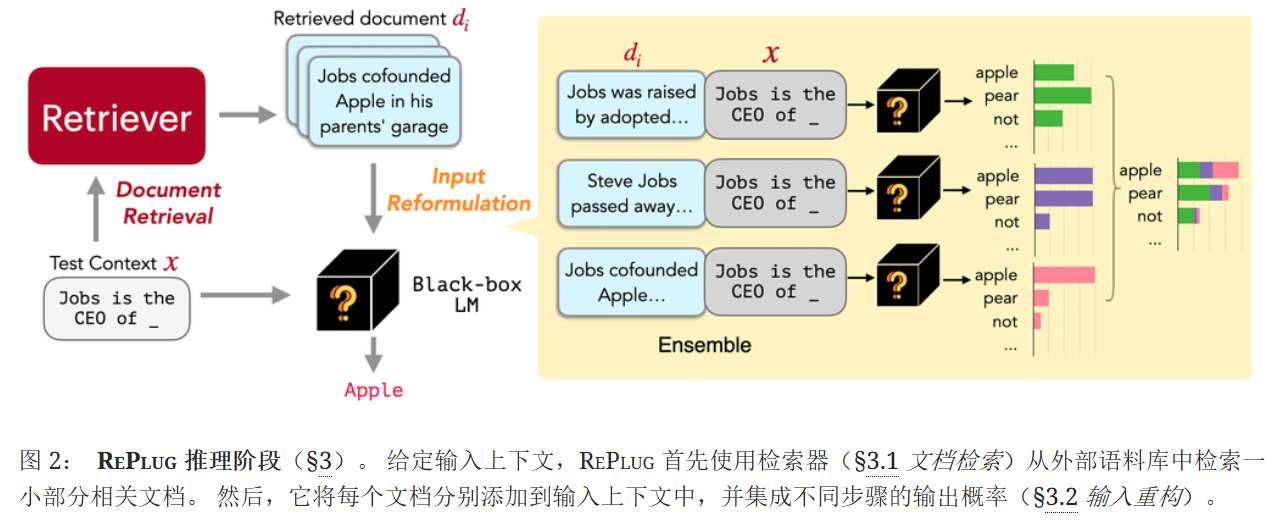
給定一個輸入上下文,RePlug首先使用檢索器從外部語料庫中檢索一小組相關文檔。 把每個檢索到的文檔與輸入上下文串聯起來,通過LLM并行處理,并集成預測概率
文檔檢索
使用基于雙編碼器架構的稠密檢索器,編碼器把輸入內容和文檔進行編碼:對待編碼內容的token的最后一個隱藏層表示進行平均池化,實現編碼映射
使用余弦相似度計算嵌入的相似度
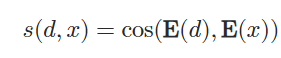
輸入重構
考慮到語言模型的上下文窗口大小,將所有top-k文檔添加到問題x前面的方案從根本上受到我們能夠包含的文檔數量(即k)的限制。
?為了解決這個限制,我們采用了一種如下所述的集成策略。?
假設𝒟′?𝒟包含k個與x最相關的文檔,將每個文檔d∈𝒟′添加到x前面,分別將此連接傳遞給LM,然后集成所有k次的輸出概率。?形式上,給定輸入上下文x及其前k個相關文檔𝒟′,下一個符元y的輸出概率計算為加權平均集成:
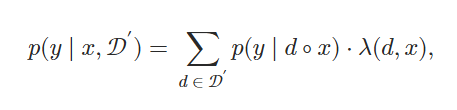
其中°表示兩個序列的連接,權重λ?(d,x)基于文檔d和輸入上下文x之間的相似度得分:
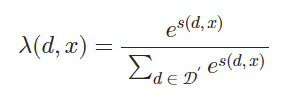
雖然這種集成方法需要運行LLM的生成總共k次,但是在每個檢索到的文檔和輸入上下文之間執行交叉注意力,因此相對把所有的k個內容添加到x前面來說,并不會產生額外的計算成本開銷
REPLUG LSR:稠密檢索器訓練
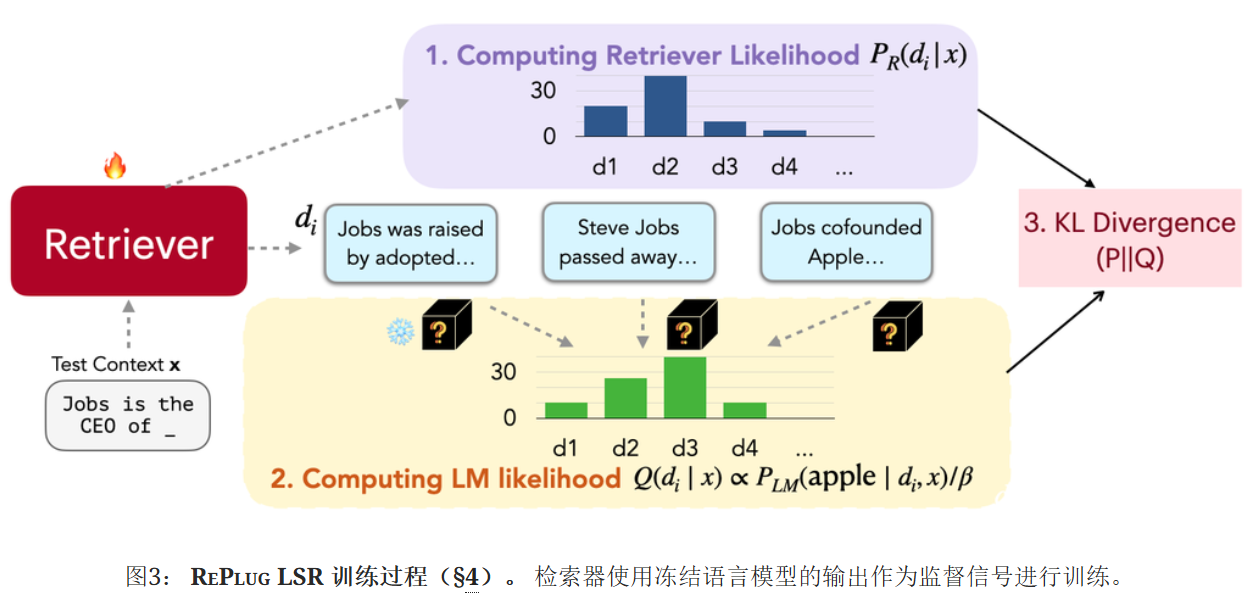
進一步提出了RePlug LSR(使用LM監督檢索的RePlug),它調整了RePlug中的檢索器,利用LM本身來提供關于應該檢索哪些文檔的監督。
可以看作是調整檢索文檔的概率,以匹配語言模型輸出序列困惑度的概率。
也就是說希望檢索器找到導致困惑度得分更低的文檔
檢索器的訓練包括四個步驟:
檢索文檔并計算檢索似然;通過語言模型對檢索到的文檔進行評分;通過最小化檢索似然和LM的評分分布之間的KL三度來更新檢索模型參數;異步更新數據存儲索引。
1.計算檢索似然
從給定輸入上下文x的語料庫𝒟中檢索k相似度得分最高的文檔𝒟′?𝒟。?然后計算每個檢索到的文檔d的檢索似然:
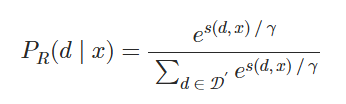
γ是一個控制softmax溫度的超參數。?理想情況下,檢索似然是通過對語料庫𝒟中的所有文檔進行邊緣化計算的,但在實踐中這是不可行的。?因此,我們通過僅對檢索到的文檔𝒟′進行邊緣化來近似檢索似然。
2.計算語言模型似然
使用LM作為評分函數來衡量每個文檔在多大程度上可以改善LM的困惑度。?具體來說,我們首先計算P_L?M?(y∣d,x),即給定輸入上下文x和文檔d時,真實實況輸出y的LM概率。概率越高,文檔di在改善LM的困惑度方面就越好。?然后,我們計算每個文檔d的語言模型似然值,如下所示:
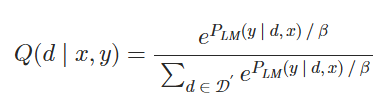
其中β是另一個超參數。
3.損失函數
給定輸入上下文x和相應的真實續寫y,計算檢索似然值和語言模型似然值。?密集檢索器通過最小化這兩個分布之間的KL散度進行訓練:
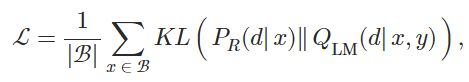
?是一組輸入上下文。?在最小化損失時只能更新檢索模型參數
4.數據存儲索引的異步更新
因為檢索器中的參數在訓練過程中被更新,之前計算的文檔嵌入不再是最新的。每T個訓練步驟重新計算文檔嵌入并使用新的嵌入重建高效的搜索索引。?然后我們使用新的文檔嵌入和索引進行檢索,并重復訓練過程。
訓練設置
使用Contriever作為RePlug的檢索器
對RePlug LSR,還是使用Contriever檢索器,使用GPT3作為監督語言模型來計算語言模型似然
訓練數據:
使用從Pile訓練數據(Gao等人,2020)中采樣的80萬個,每個包含256個符元的序列作為我們的訓練查詢。?每個查詢被分成兩部分:前128個符元用作輸入上下文x,后128個符元用作真實延續y。?對于外部語料庫D,我們從Pile訓練數據中采樣了3600萬個,每個包含128個符元的文檔。?為避免簡單的檢索,我們確保外部語料庫文檔與從中采樣訓練查詢的文檔不重疊。
訓練細節
預先計算外部語料庫D的文檔嵌入,并創建一個FAISS索引以進行快速相似性搜索。
給定一個查詢x,從FAISS索引中檢索前20個文檔,并使用0.1的溫度計算檢索似然和語言模型似然。
使用Adam優化器訓練檢索器,學習率為2e-5,批量大小為64,預熱比例為0.1。每3000步重新計算一次文檔嵌入,并對檢索器進行總共25000步的微調。
實驗
對語言建模和下游任務(MMLU,開放域問答)進行了評估
1.語言建模
數據集:Pile數據集(Gao et?al., 2020)是一個語言建模基準,包含來自網頁、代碼和學術論文等不同領域的文本資源。?遵循先前的工作,我們報告每個子集域的每UTF-8編碼字節比特數(BPB)作為指標。
基線:將GPT-3和GPT-2系列語言模型作為基線。?來自GPT-3的四個模型(Davinci、Curie、Baddage和Ada)是只能通過API訪問的黑盒模型。
在基線上添加了RePlug和RePlug LSR。?我們隨機下采樣Pile訓練數據(128個符元的3.67億個文檔),并將它們用作所有模型的檢索語料庫。?由于Pile數據集已努力對訓練集、驗證集和測試集中的文檔進行去重(Gao et al., 2020),因此我們沒有進行額外的過濾。?對于RePlug和RePlug LSR,我們使用長度為128符元的上下文進行檢索,并采用集成方法在推理過程中整合前10個檢索到的文檔。
結果:
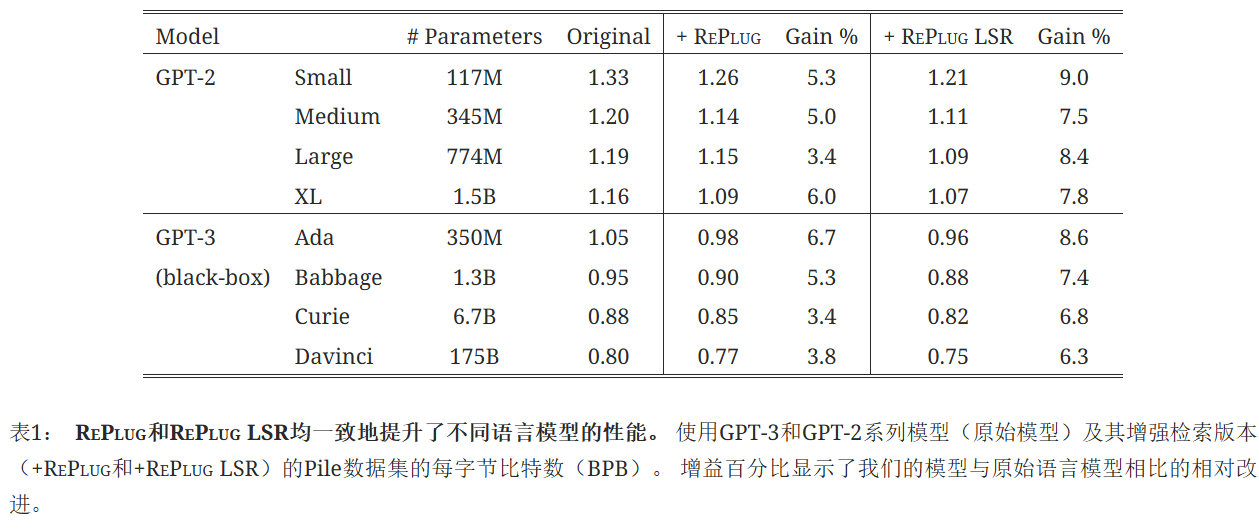
RePlug和RePlug LSR都顯著優于基線。?這表明,僅僅向凍結的語言模型(即黑盒設置)添加檢索模塊就能有效提高不同大小的語言模型在語言建模任務上的性能。?此外,RePlug LSR始終比RePlug有較大優勢。?具體來說,RePlug LSR在8個模型上的平均結果比基線提高了7.7%,而RePlug提高了4.7%。?這表明進一步使檢索器適應目標語言模型是有益的。
2.MMLU
數據集:MMLU一個多項選擇問答數據集,涵蓋了來自57個任務的考試題,包括數學、計算機科學、法律、美國歷史等。?這57個任務被分為4個類別:人文科學、STEM、社會科學和其他。?遵循?Chung等人 (2022a)?的方法,我們在5-shot上下文學習環境中評估?RePlug。
基線:第一組基線是包括Codex、PaLM和 Flan-PaLM在內的最先進的大語言模型 (LLM)。(這三個模型在MMLU排行榜上位列前三。)第二組基線由檢索增強型語言模型組成。只包含Atlas因為沒有其他檢索增強型LLM在MMLU數據集上進行過評估。?Atlas同時訓練檢索器和語言模型,我們認為這是一個白盒檢索LM設置。
只將RePlug和RePlug LSR添加到Codex,因為其他模型如PaLM和Flan-PaLM不對公眾開放。?我們使用測試問題作為查詢,從維基百科(2018年12月)中檢索10個相關的文檔,并將每個檢索到的文檔添加到測試問題前面,從而產生10個單獨的輸入。?然后將這些輸入分別饋送到語言模型中,并將輸出概率進行集成。
結果:
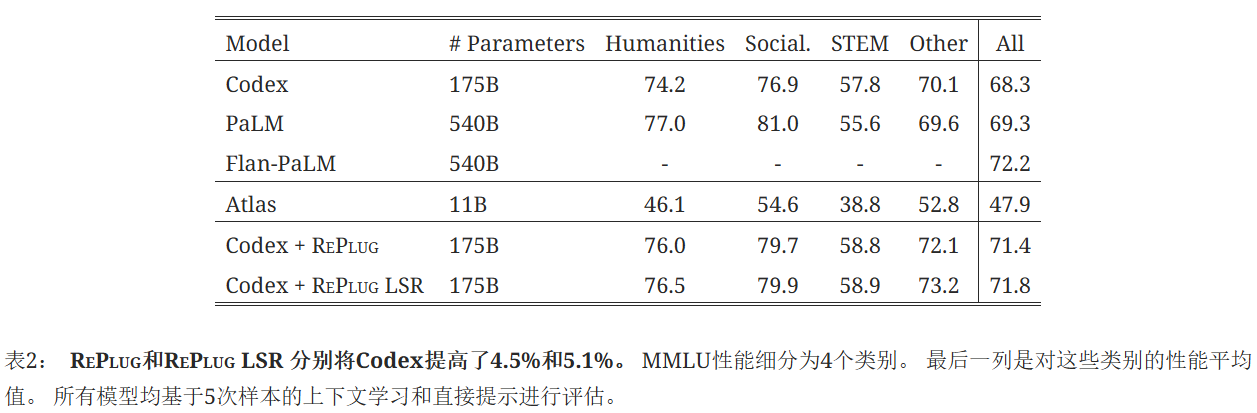
RePlug?和?RePlug LSR?分別將原始 Codex 模型的性能提高了 4.5% 和 5.1%。?此外,RePlug LSR?大大優于之前的基于檢索的語言模型 Atlas,證明了我們提出的黑盒檢索語言模型設置的有效性。?盡管我們的模型略微遜于 Flan-PaLM,但這仍然是一個不錯的結果,因為 Flan-PaLM 的參數數量是它的三倍。?我們預計,如果我們能夠訪問該模型,RePlug LSR?可以進一步改進 Flan-PaLM。即使在 STEM 類別中,RePlug LSR?也比原始模型高出 1.9%。?這表明檢索可以提高語言模型的解決問題的能力。
3.開放域問答
數據集:NQ和TriviaQA是兩個開放域問答數據集,包含從維基百科和網絡收集的問題和答案。考慮了少樣本設置,其中模型只提供幾個訓練示例;以及全數據設置,其中模型提供所有訓練示例。
基線:第一組模型由強大的大型語言模型組成,包括Chinchilla、PaLM和Codex。?所有這些模型都在少樣本設置下使用上下文學習進行評估,其中Chinchilla和PaLM使用64個樣本進行評估,Codex使用16個樣本進行評估。第二組用于比較的模型包括檢索增強型語言模型,例如RETRO、R2-D2和Atlas。所有這些檢索增強型模型都在訓練數據上進行了微調,無論是在少樣本設置下還是使用全訓練數據。?具體來說,Atlas在少樣本設置下使用64個示例進行了微調。
在Codex中添加了RePlug和RePlug LSR,并使用維基百科(2018年12月)作為檢索語料庫,以在16樣本的上下文學習中評估模型。?與語言建模和MMLU中的設置類似,我們使用我們提出的集成方法結合前10個檢索到的文檔。
結果:
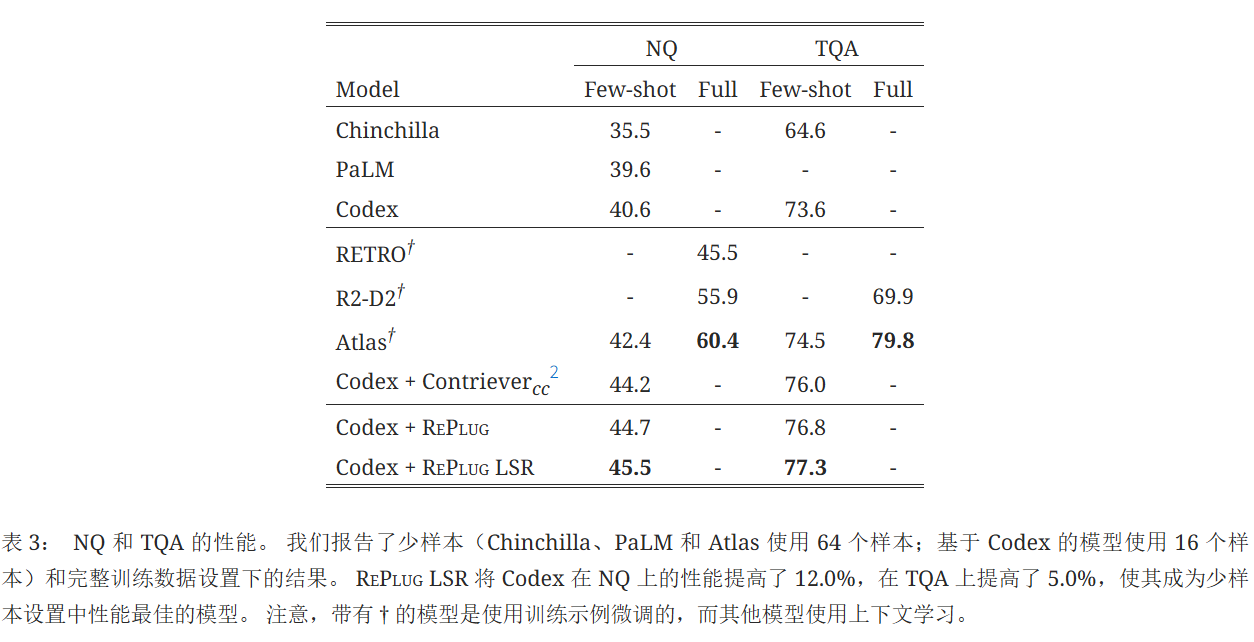
RePlug LSR在NQ上將原始Codex的性能顯著提高了12.0%,在TQA上提高了5.0%。?它優于之前的最佳模型Atlas(使用64個訓練示例進行了微調),在少樣本設置下達到了新的最先進水平。?但是,這個結果仍然落后于在完整訓練數據上微調的檢索增強型語言模型的性能。?這可能是由于訓練集中存在近似重復的測試問題(例如,Lewis等人 (2021)?發現NQ中32.5%的測試問題與訓練集重疊)。

案例教程:Excel數據生成統計圖表,自動清洗數據+轉換可視化圖表+零代碼,完全免費教程)





)



)






)
 設置)