最近在訓練一個基于 Tiny-UNet 的圖像去噪模型時,我遇到了經典但棘手的錯誤:
RuntimeError: CUDA out of memory。本文記錄了我如何從復現、分析,到逐步優化并成功解決該問題的全過程,希望對深度學習開發者有所借鑒。
-
訓練數據:SIDD 小型圖像去噪數據集
-
-
模型結構:簡化版 U-Net(Tiny-UNet)
-
class UNetDenoiser(nn.Module):def __init__(self):super(UNetDenoiser, self).__init__()# Encoderself.enc1 = self.conv_block(3, 64)self.enc2 = self.conv_block(64, 128)self.enc3 = self.conv_block(128, 256)self.pool = nn.MaxPool2d(2)# Bottleneckself.bottleneck = self.conv_block(256, 512)# Decoderself.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.dec3 = self.conv_block(512, 256)self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.dec2 = self.conv_block(256, 128)self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec1 = self.conv_block(128, 64)# Outputself.final = nn.Conv2d(64, 3, kernel_size=1)def conv_block(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True))def forward(self, x):# Encodere1 = self.enc1(x) # [B, 64, H, W]e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2]e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4]# Bottleneckb = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8]# Decoderd3 = self.up3(b) # [B, 256, H/4, W/4]d3 = self.dec3(torch.cat([d3, e3], dim=1))d2 = self.up2(d3) # [B, 128, H/2, W/2]d2 = self.dec2(torch.cat([d2, e2], dim=1))d1 = self.up1(d2) # [B, 64, H, W]d1 = self.dec1(torch.cat([d1, e1], dim=1))return self.final(d1)源代碼:
?# train_denoiser.py import os import math import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms from torchvision.utils import save_image from PIL import Image# --- 數據集定義 --- class DenoisingDataset(Dataset):def __init__(self, noisy_dir, clean_dir, transform=None):self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)])self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)])self.transform = transform if transform else transforms.ToTensor()def __len__(self):return len(self.noisy_paths)def __getitem__(self, idx):noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB")clean_img = Image.open(self.clean_paths[idx]).convert("RGB")return self.transform(noisy_img), self.transform(clean_img)# --- 簡單 CNN 去噪模型 --- # class SimpleDenoiser(nn.Module): # def __init__(self): # super(SimpleDenoiser, self).__init__() # self.encoder = nn.Sequential( # nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(), # nn.Conv2d(64, 64, 3, padding=1), nn.ReLU() # ) # self.decoder = nn.Sequential( # nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), # nn.Conv2d(64, 3, 3, padding=1) # ) # # def forward(self, x): # x = self.encoder(x) # x = self.decoder(x) # return x class UNetDenoiser(nn.Module):def __init__(self):super(UNetDenoiser, self).__init__()# Encoderself.enc1 = self.conv_block(3, 64)self.enc2 = self.conv_block(64, 128)self.enc3 = self.conv_block(128, 256)self.pool = nn.MaxPool2d(2)# Bottleneckself.bottleneck = self.conv_block(256, 512)# Decoderself.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.dec3 = self.conv_block(512, 256)self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.dec2 = self.conv_block(256, 128)self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec1 = self.conv_block(128, 64)# Outputself.final = nn.Conv2d(64, 3, kernel_size=1)def conv_block(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True))def forward(self, x):# Encodere1 = self.enc1(x) # [B, 64, H, W]e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2]e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4]# Bottleneckb = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8]# Decoderd3 = self.up3(b) # [B, 256, H/4, W/4]d3 = self.dec3(torch.cat([d3, e3], dim=1))d2 = self.up2(d3) # [B, 128, H/2, W/2]d2 = self.dec2(torch.cat([d2, e2], dim=1))d1 = self.up1(d2) # [B, 64, H, W]d1 = self.dec1(torch.cat([d1, e1], dim=1))return self.final(d1)# --- PSNR 計算函數 --- def calculate_psnr(img1, img2):mse = torch.mean((img1 - img2) ** 2)if mse == 0:return float("inf")return 20 * torch.log10(1.0 / torch.sqrt(mse))# --- 主訓練過程 --- def train_denoiser():noisy_dir = r"F:\SIDD數據集\archive\SIDD_Small_sRGB_Only\noisy"clean_dir = r"F:\SIDD數據集\archive\SIDD_Small_sRGB_Only\clean"batch_size = 1num_epochs = 50lr = 0.0005device = torch.device("cuda" if torch.cuda.is_available() else "cpu")dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# model = SimpleDenoiser().to(device)# 替換為 UNetmodel = UNetDenoiser().to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=lr)for epoch in range(num_epochs):model.train()total_loss = 0.0total_psnr = 0.0for noisy, clean in dataloader:noisy, clean = noisy.to(device), clean.to(device)denoised = model(noisy)loss = criterion(denoised, clean)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()total_psnr += calculate_psnr(denoised, clean).item()avg_loss = total_loss / len(dataloader)avg_psnr = total_psnr / len(dataloader)print(f"Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB")# 保存模型os.makedirs("weights", exist_ok=True)torch.save(model.state_dict(), "weights/denoiser.pth")print("模型已保存為 weights/denoiser.pth")if __name__ == "__main__":train_denoiser() -
顯卡:8GB 顯存的 RTX GPU
-
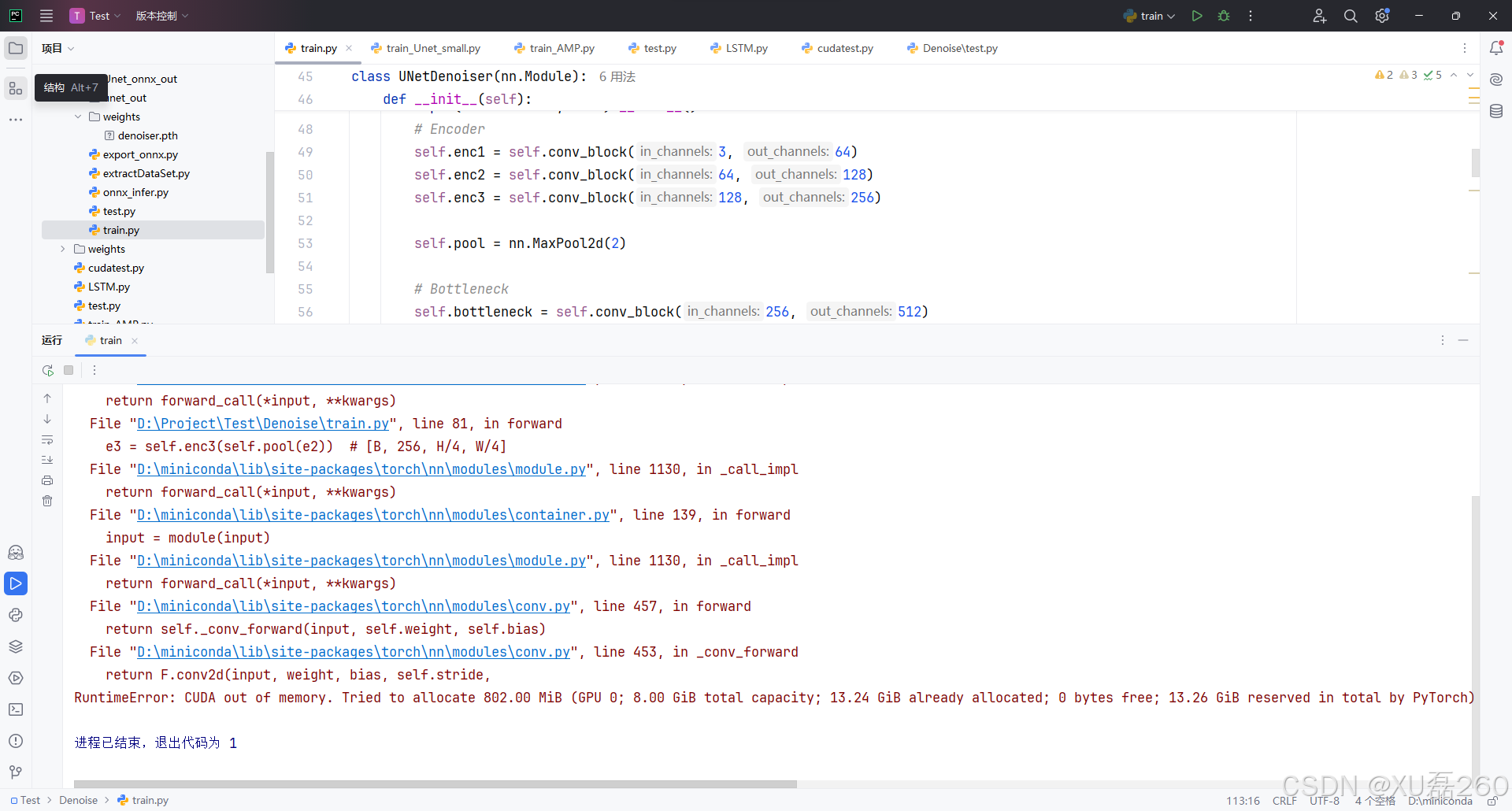
問題定位
我們從報錯堆棧中看到:
e3 = self.enc3(self.pool(e2))
RuntimeError: CUDA out of memory. Tried to allocate 746.00 MiB
說明問題發生在模型第三層 encoder(enc3)前的 pooling 后,這說明:
-
當前的輸入尺寸、batch size 占用了太多顯存;
-
或者模型本身結構太重;
-
又或者顯存未被合理管理(例如碎片化)。
分析與優化過程
第一步:降低 batch size
原始 batch size 設置為 16,直接觸發爆顯存。
我們嘗試逐步調小 batch size:
batch_size = 6 # 從16降低到6
觀察顯存變化,發現仍有波動。為更穩定,設置為 4 或動態適配:
batch_size = min(8, torch.cuda.get_device_properties(0).total_memory // estimated_sample_size)
?發現同樣的錯誤,顯存不知。分析可能是網絡參數太大了,或者訓練過程沒有啟動內存優化。導致的內存不足,這些可以通過策略進行改進,達到訓練的目的。
第二步:開啟 cuDNN 自動優化
torch.backends.cudnn.benchmark = True
cuDNN 會根據不同卷積輸入尺寸自動尋找最優算法,可能減少顯存使用。
第三步:開啟混合精度訓練 AMP(Automatic Mixed Precision)
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler()with autocast():output = model(input)loss = criterion(output, target)scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
-
autocast()自動在部分層使用 float16,提高速度并減小顯存壓力; -
GradScaler確保在 float16 條件下梯度依然穩定。
實測顯存使用降低近 30%,OOM 問題明顯緩解!
但以上訓練的預加載時間太慢,顯卡占有率過低,有點顯卡當前沒有任務----“偷懶”的意思。可能是數據的加載或者顯存抖動造成的。
第四步:優化 DataLoader 性能(間接緩解顯存抖動)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True,num_workers=num_workers, pin_memory=True)-
num_workers?啟用多進程加載數據; -
pin_memory=True啟用固定內存,更快傳輸到 GPU。
雖然不直接節省顯存,但顯著減少顯存峰值抖動(尤其在小 batch 訓練時)。
第五步:檢查圖像輸入尺寸是否太大
原始圖像尺寸為 512×512:
transform = transforms.Compose([transforms.Resize((256, 256)), # 降低分辨率transforms.ToTensor()
])
最終訓練代碼結構
我們將上述策略集成到了 train.py 腳本中(如下),包括:
-
Dataset & Dataloader 加速
-
混合精度訓練
-
cuDNN 優化
-
實時 PSNR 顯示
-
自動保存模型權重
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
from torch.cuda.amp import autocast, GradScaler
from tqdm import tqdm# --- 啟用 cuDNN 自動優化 ---
torch.backends.cudnn.benchmark = True# --- 數據集定義 ---
class DenoisingDataset(Dataset):def __init__(self, noisy_dir, clean_dir, transform=None):self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)])self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)])self.transform = transform if transform else transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor()])def __len__(self):return len(self.noisy_paths)def __getitem__(self, idx):noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB")clean_img = Image.open(self.clean_paths[idx]).convert("RGB")return self.transform(noisy_img), self.transform(clean_img)# --- Tiny UNet 模型 ---
class TinyUNet(nn.Module):def __init__(self):super(TinyUNet, self).__init__()self.enc1 = self.conv_block(3, 16)self.enc2 = self.conv_block(16, 32)self.enc3 = self.conv_block(32, 64)self.pool = nn.MaxPool2d(2)self.bottleneck = self.conv_block(64, 128)self.up3 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec3 = self.conv_block(128, 64)self.up2 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)self.dec2 = self.conv_block(64, 32)self.up1 = nn.ConvTranspose2d(32, 16, kernel_size=2, stride=2)self.dec1 = self.conv_block(32, 16)self.final = nn.Conv2d(16, 3, kernel_size=1)def conv_block(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True))def forward(self, x):e1 = self.enc1(x)e2 = self.enc2(self.pool(e1))e3 = self.enc3(self.pool(e2))b = self.bottleneck(self.pool(e3))d3 = self.up3(b)d3 = self.dec3(torch.cat([d3, e3], dim=1))d2 = self.up2(d3)d2 = self.dec2(torch.cat([d2, e2], dim=1))d1 = self.up1(d2)d1 = self.dec1(torch.cat([d1, e1], dim=1))return self.final(d1)# --- PSNR 計算 ---
def calculate_psnr(img1, img2):mse = torch.mean((img1 - img2) ** 2)if mse == 0:return float("inf")return 20 * torch.log10(1.0 / torch.sqrt(mse))# --- 訓練函數 ---
def train_denoiser():noisy_dir = r"F:\SIDD數據集\archive\SIDD_Small_sRGB_Only\noisy"clean_dir = r"F:\SIDD數據集\archive\SIDD_Small_sRGB_Only\clean"batch_size = 6num_epochs = 50lr = 0.0005num_workers = 4device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")transform = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor()])dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transform)dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True,num_workers=num_workers, pin_memory=True)model = TinyUNet().to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=lr)scaler = GradScaler() # AMP 梯度縮放器os.makedirs("weights", exist_ok=True)for epoch in range(num_epochs):model.train()total_loss = 0.0total_psnr = 0.0for noisy, clean in tqdm(dataloader, desc=f"Epoch {epoch+1}/{num_epochs}"):noisy = noisy.to(device, non_blocking=True)clean = clean.to(device, non_blocking=True)optimizer.zero_grad()with autocast(): # 混合精度推理denoised = model(noisy)loss = criterion(denoised, clean)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()total_loss += loss.item()total_psnr += calculate_psnr(denoised.detach(), clean).item()avg_loss = total_loss / len(dataloader)avg_psnr = total_psnr / len(dataloader)print(f"? Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB")torch.save(model.state_dict(), f"weights/tiny_unet_epoch{epoch+1}.pth")print("🎉 模型訓練完成,所有權重已保存至 weights/ 目錄")if __name__ == "__main__":train_denoiser()
最后得到的訓練文件,這里我設置的50次訓練迭代:
測試模型的推理效果
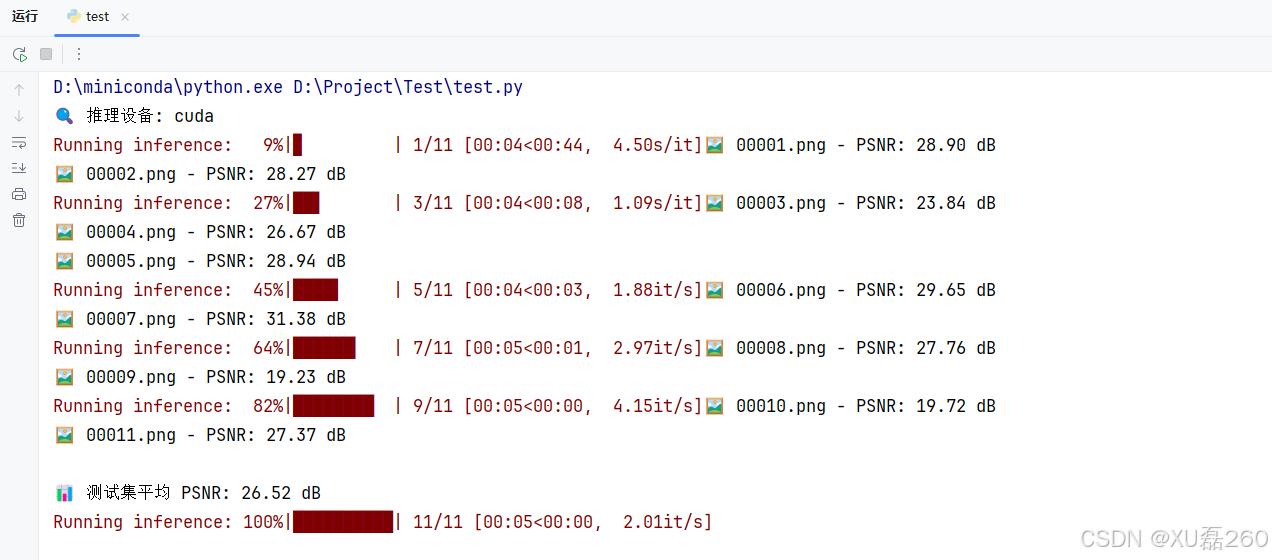
?原去帶噪聲圖片:
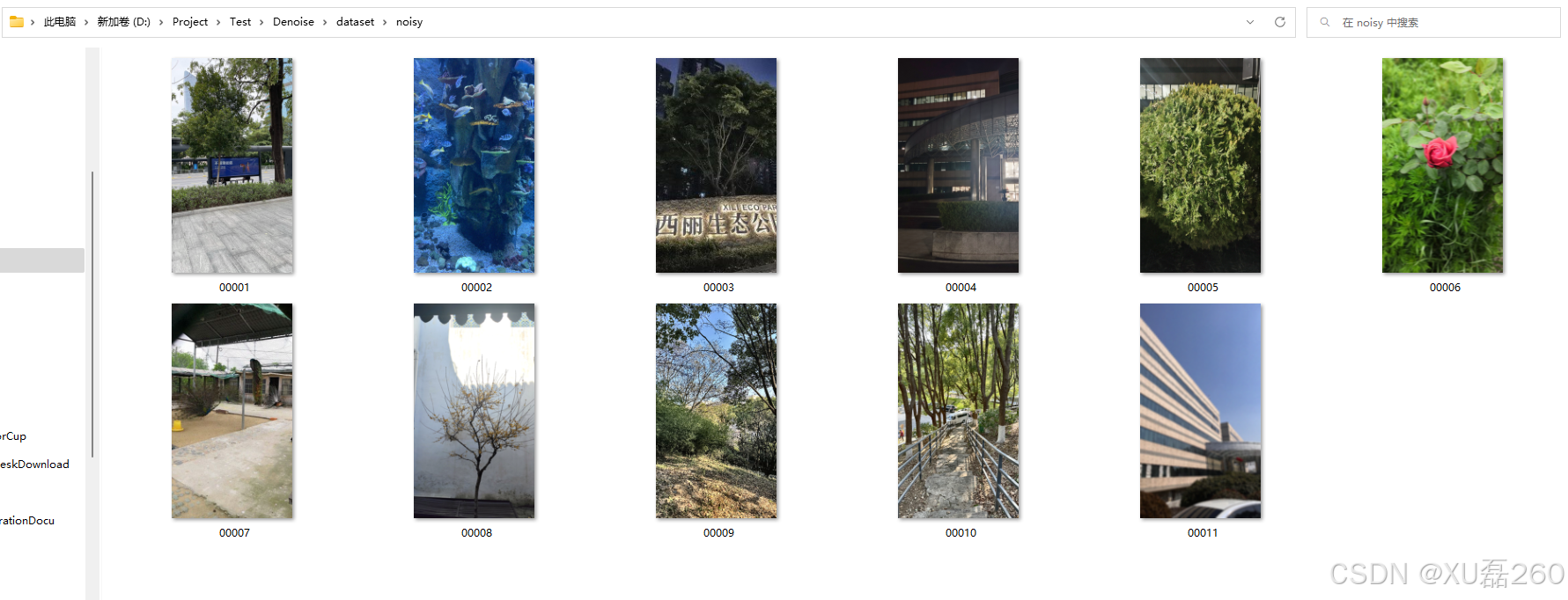
去噪后(可以看到這里仍然有bug,肉眼看效果并不是很好,需要進一步優化,考慮到模型的泛化性):

總結:處理 CUDA OOM 的思路模板
-
先查 batch size,這是最常見爆顯存原因;
-
確認輸入尺寸是否太大或未 resize;
-
啟用 AMP,簡單又高效;
-
合理設計模型結構(Tiny UNet > ResUNet);
-
使用 Dataloader 加速,避免數據傳輸抖動;
-
手動清理緩存防止 PyTorch 持有多余內存;
-
查看 PyTorch 顯存使用報告,加上:
print(torch.cuda.memory_summary())





生成dll木馬)

)
:代理模式思想、靜態模式和動態模式定義與區別、靜態代理模式代碼實現)
流程的自動化)






深入了解AVFoundation-采集:采集系統架構與 AVCaptureSession 全面梳理)
組件)
)
)