一、 基本原理
Mean Shift是一種基于密度的非參數聚類算法,不需要預先指定簇的數量,而是通過尋找數據空間中密度最大的區域來自動確定聚類中心, 適合圖像分割和目標跟蹤等。
算法步驟
-
初始化:對每個數據點作為起點。
-
迭代:計算當前點的鄰域內所有點的加權均值,將當前點移動到該均值位置。
-
終止:當移動距離小于閾值或達到最大迭代次數時停止。
-
聚類:合并收斂到同一位置的點為一個簇。
數學描述
核函數:通常使用高斯核,衡量數據點之間的權重:
![]()
其中?? 是帶寬(bandwidth)
均值漂移向量:點?x的漂移方向為:
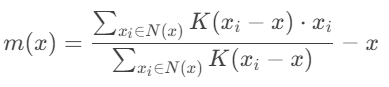
其中?N(x)?是?x?的鄰域(由帶寬決定)
二、特點
優點
-
無需指定簇數:自動發現數據中的聚類結構。
-
適應任意形狀:可以識別非球形分布的簇。
-
魯棒性:對噪聲和異常值不敏感。
缺點
-
計算復雜度高:每輪迭代需要計算所有點的鄰域關系,時間復雜度O(n2)。
-
帶寬選擇敏感:
bandwidth對結果影響大,需謹慎選擇。 -
不適合高維數據:維度災難可能導致效果下降。
三、Python 實現
from sklearn.cluster import MeanShift
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt# 生成數據
X, _ = make_blobs(n_samples=500, centers=3, cluster_std=0.8, random_state=42)# Mean Shift 聚類
ms = MeanShift(bandwidth=1.5) # bandwidth是關鍵參數
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_# 可視化
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', alpha=0.5)
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], c='red', marker='x', s=100)
plt.title("Mean Shift Clustering")
plt.show()參數說明
-
bandwidth:決定鄰域大小的關鍵參數,使用estimate_bandwidth()輔助確定。若值太小,會導致過多小簇;若太大,會合并所有數據為單一簇。可通過以下方法估計:from sklearn.cluster import estimate_bandwidth bandwidth = estimate_bandwidth(X, quantile=0.2) # quantile影響鄰域范圍 -
bin_seeding:對大規模數據,先采樣再聚類,bin_seeding設置為True,僅用離散化的種子點加速計算
應用實例:圖像分割
from skimage import io, color
from sklearn.cluster import MeanShift# 加載圖片
image = io.imread("example.jpg")
image_rgb = color.rgba2rgb(image) # 轉換為RGB
h, w, _ = image_rgb.shape
X = image_rgb.reshape(-1, 3) # 將像素轉換為特征向量# Mean Shift聚類
ms = MeanShift(bandwidth=0.1, bin_seeding=True)
ms.fit(X)
segmented = ms.labels_.reshape(h, w) # 還原為圖像尺寸# 顯示分割結果
plt.imshow(segmented, cmap='tab20')
plt.axis('off')
plt.show()項目)








)
)



框架流程)


)

