大模型分類:
技術架構: Encoder Only Bert
Decoder Only 著名的大模型都是
Encoder - Decoder T5
是否開源: 開源陣營: Llama DeepSeek Qwen
閉源陣營: ChatGpt Gemini Claude
語言模型發展階段: 基于規則統計 n-gram:上下文比較短,數據稀疏,泛化能力差
神經網絡語言模型:泛化能力差(解決) 數據稀疏(解決) RNN,LSTM
Transformer: Bert,GPT
LLM:參數以 10 億計
評估指標: BLEU 精準率,需要有參考答案
ROUGE 召回率 需要有參考答案
PPL
大模型演進路線: Encoder-only 雙向注意力機制,完形填空,閱讀理解,Pre-train+下游任務fine-tuning
Decoder-only gpt:
gpt2:
gpt3:
Encoder-Decoder : T5


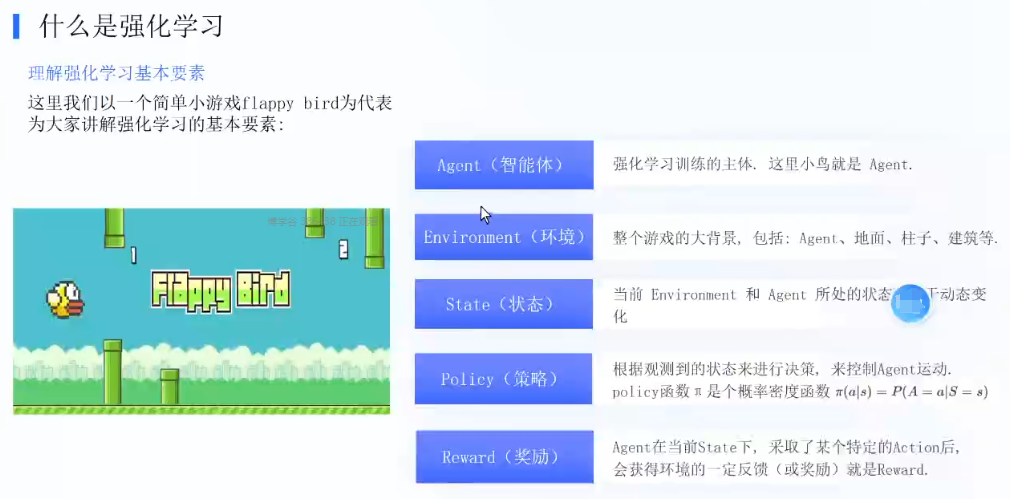
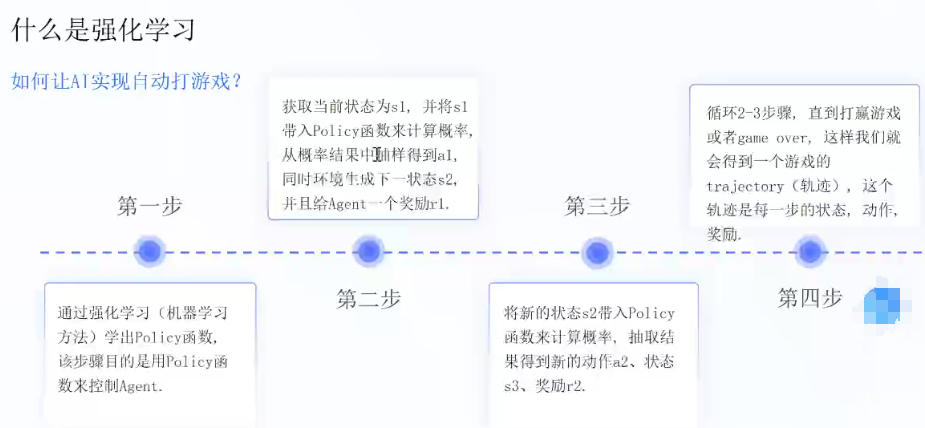
RLHF解決的是什么問題? 對齊問題,訓練一個獎勵模型

位置編碼:
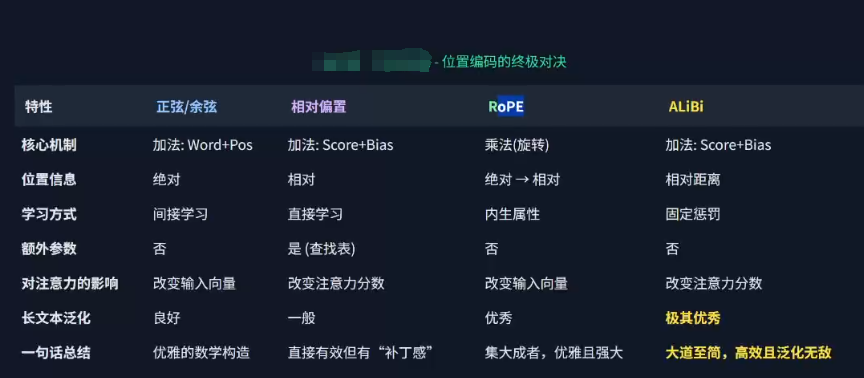
總結:
強化學習:
ChatGPT SFT :人類價值觀對齊,
RLHF: 訓練獎勵模型, 人的參與是為了準備訓練獎勵模型的語料
強化學習:Agent,Environment,state,Policy,Reward
PPO:
不同大模型的差異:
位置編碼: 傳統Transformer,相對位置編碼,旋轉位置編碼(用的最多),ALiBi
注意力機制:
LN:層歸一化:
前饋神經網絡:MOE








)


)







![牛客:HJ24 合唱隊[華為機考][最長遞增子集][動態規劃]](http://pic.xiahunao.cn/牛客:HJ24 合唱隊[華為機考][最長遞增子集][動態規劃])