DAY 58 經典時序預測模型2
知識點回顧:
- 時序建模的流程
- 時序任務經典單變量數據集
- ARIMA(p,d,q)模型實戰
- SARIMA摘要圖的理解
- 處理不平穩的2種差分
- n階差分---處理趨勢
- 季節性差分---處理季節性
建立一個ARIMA模型,通常遵循以下步驟:
1. 數據可視化:觀察原始時間序列圖,判斷是否存在趨勢或季節性。
2. 平穩性檢驗:
? ? - 對原始序列進行ADF檢驗。
? ? - 如果p值 > 0.05,說明序列非平穩,需要進行差分。
3. 確定差分次數 d:
? ? - 進行一階差分,然后再次進行ADF檢驗。
? ? - 如果平穩了,則 d=1。否則,繼續差分,直到平穩。
4. 確定 p 和 q:
? ? - 對差分后的平穩序列繪制ACF和PACF圖。
? ? - 根據昨天學習的規則(PACF定p,ACF定q)來選擇p和q的值。
5. 建立并訓練ARIMA(p, d, q)模型。
- 模型評估與診斷:查看模型的摘要信息,檢查殘差是否為白噪聲。
- AIC用來對比不同模型選擇,越小越好
- 關注系數是否顯著,通過p值或者置信區間均可
- 殘差的白噪聲檢驗+正態分布檢驗
7. 進行預測(需要還原回差分前的結構)
作業:對太陽黑子數量數據集用arima完成流程
#太陽黑子數量數據集from statsmodels.datasets import sunspots
df_sun = sunspots.load_pandas().data['SUNACTIVITY']
df_sun.head()df_sun.plot(figsize=(12, 6))#平穩性檢驗
# 引入ADF檢驗的函數
from statsmodels.tsa.stattools import adfuller # --- 新增:使用ADF檢驗來判斷平穩性 ---print("開始進行ADF平穩性檢驗...")# 執行ADF檢驗
# adfuller()函數會返回一個包含多個結果的元組
adf_result = adfuller(df_sun)# 提取并展示主要結果
adf_statistic = adf_result[0]
p_value = adf_result[1]
critical_values = adf_result[4]print(f"ADF統計量 (ADF Statistic): {adf_statistic:.4f}")
print(f"p值 (p-value): {p_value:.4f}")
print("臨界值 (Critical Values):")
for key, value in critical_values.items():print(f' {key}: {value:.4f}')print("\n--- 檢驗結論 ---")
# 根據p值進行判斷
if p_value < 0.05:print(f"p-value ({p_value:.4f}) 小于 0.05,我們強烈拒絕原假設(H?)。")print("結論:該序列是平穩的 (Stationary)。")
else:print(f"p-value ({p_value:.4f}) 大于或等于 0.05,我們無法拒絕原假設(H?)。")print("結論:該序列是非平穩的 (Non-stationary)。")# 也可以通過比較ADF統計量和臨界值來判斷,結論是一致的
if adf_statistic < critical_values['5%']:print("\n補充判斷:ADF統計量小于5%的臨界值,同樣表明序列是平穩的。")
#--- 檢驗結論 ---
# p-value (0.0531) 大于或等于 0.05,我們無法拒絕原假設(H?)。
# 結論:該序列是非平穩的 (Non-stationary)。import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 中文顯示設置
plt.rcParams['font.sans-serif'] = ['SimHei'] # 設置中文字體
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示為方塊的問題
#差分
df_sun_diff = df_sun.diff().dropna()
plt.plot(df_sun_diff)
plt.title('一階差分后的數據')
plt.show()
# 一階差分后的ADF檢驗
adf_result_diff = adfuller(df_sun_diff)
print(f'一階差分后數據的ADF檢驗結果:')
print(f' ADF Statistic: {adf_result_diff[0]}')
print(f' p-value: {adf_result_diff[1]}') # p-value會變得非常小,說明數據變平穩了
# d = 1# 繪制ACF和PACF圖
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
plot_pacf(df_sun_diff, lags=44)
plt.title('差分后數據的PACF')
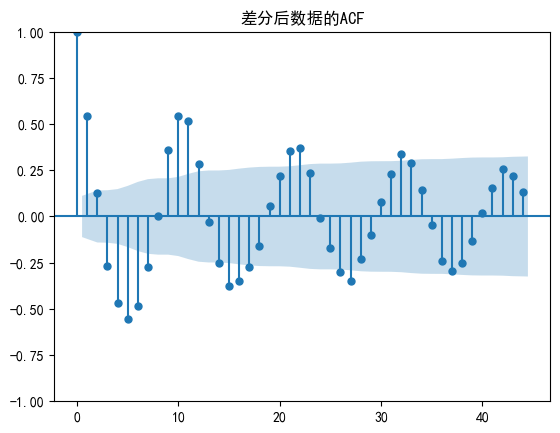
plt.show()plot_acf(df_sun_diff, lags=44)
plt.title('差分后數據的ACF')
plt.show() #p 8 ; q 1 or 0from statsmodels.tsa.arima.model import ARIMA
import warnings
warnings.filterwarnings("ignore")
# 建立ARIMA模型
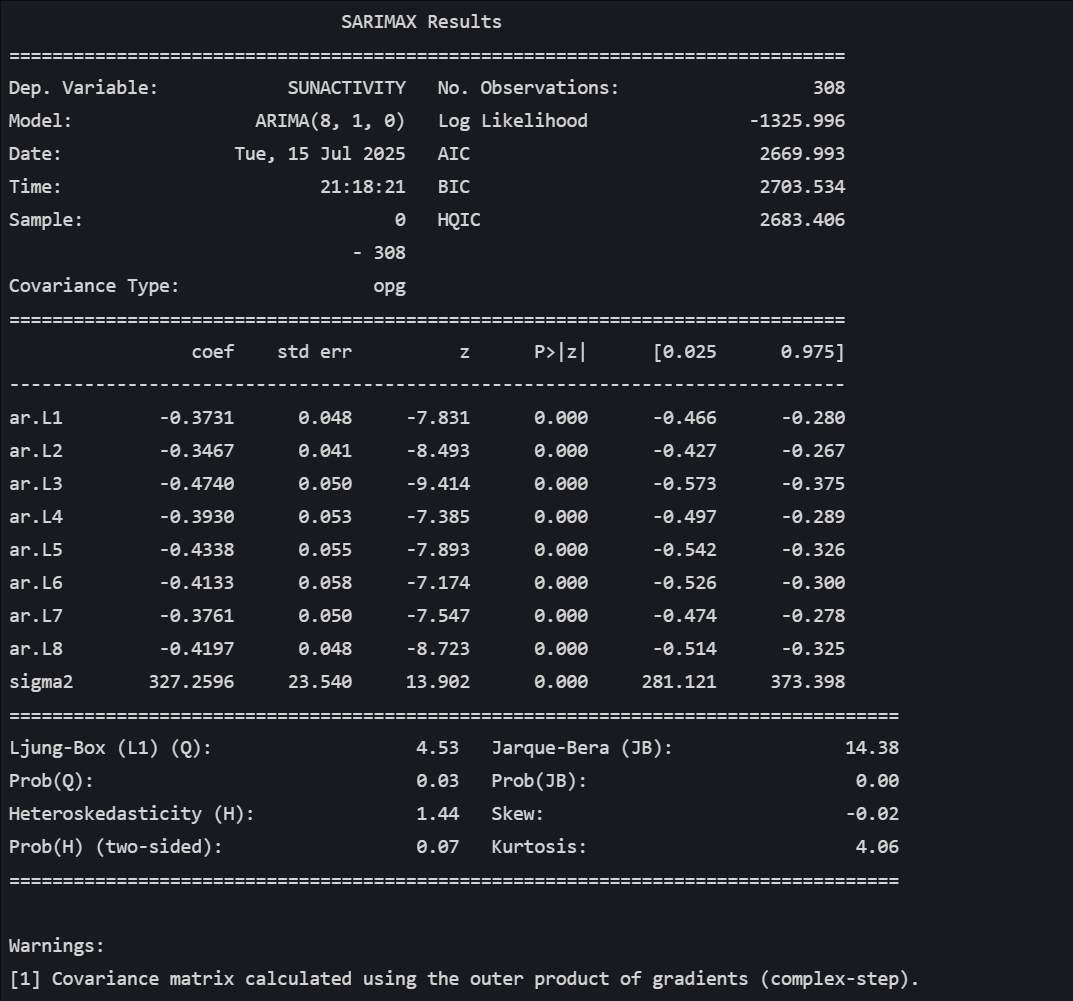
model = ARIMA(df_sun_diff, order=(8, 1, 0))
arima_result = model.fit()# 打印模型摘要
print(arima_result.summary())# 讓我們預測未來33年
forecast_steps = 33
forecast = arima_result.get_forecast(steps=forecast_steps)
pred_mean = forecast.predicted_mean
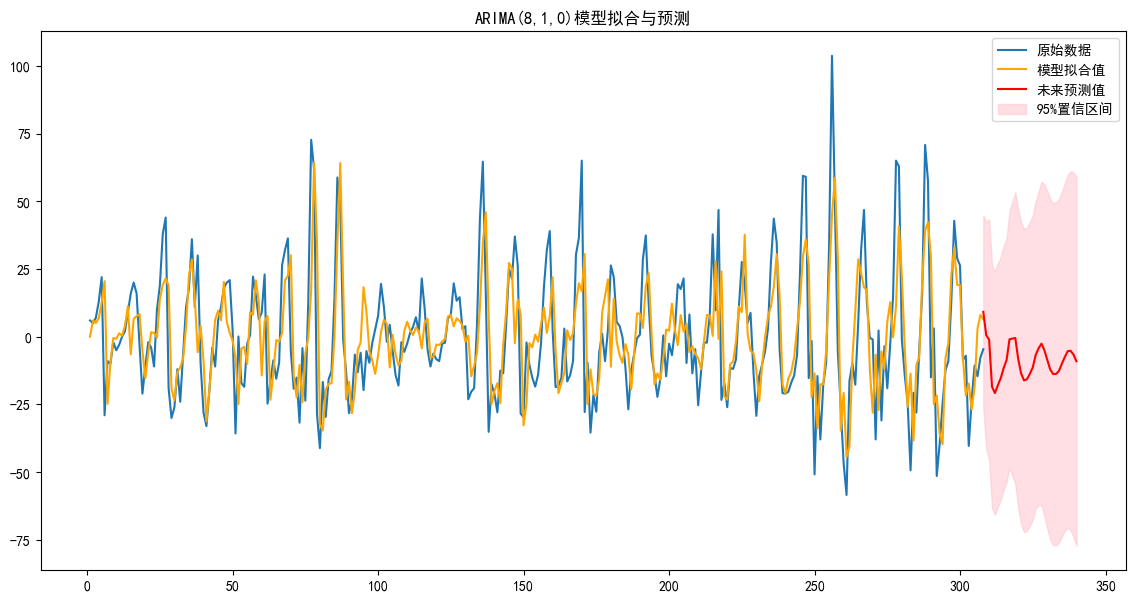
conf_int = forecast.conf_int()# 繪制結果
plt.figure(figsize=(14, 7))
plt.plot(df_sun_diff, label='原始數據')
# 繪制模型在歷史數據上的擬合值
plt.plot(arima_result.fittedvalues, color='orange', label='模型擬合值')
# 繪制未來預測值
plt.plot(pred_mean, color='red', label='未來預測值')
# 繪制置信區間
plt.fill_between(conf_int.index,conf_int.iloc[:, 0],conf_int.iloc[:, 1], color='pink', alpha=0.5, label='95%置信區間')
plt.title('ARIMA(8,1,0)模型擬合與預測')
plt.legend()
plt.show()
#核心看點:AIC 和 BIC。當你在比較不同模型時(比如 ARIMA(2,0,0) vs ARIMA(1,0,1)),這兩個值是選擇“最佳”模型的重要依據。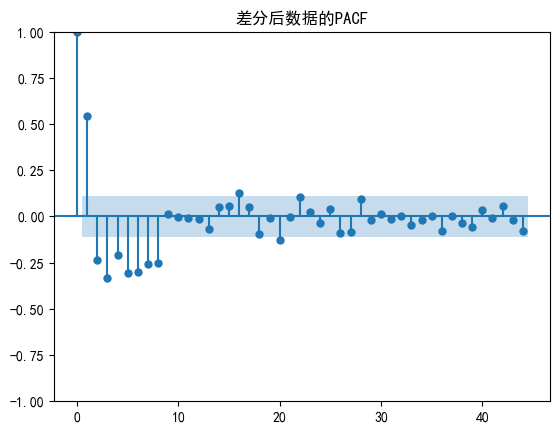









)


)






