文章目錄
- 現象描述
- 開始分析
- 1.初步分析dump文件
- 2.AI分析引用關系
- 分析方向2.1 flink BlobServer bug
- 分析方向2.2 和運行環境有關
- 分析方向2.3 和任務有關
- 回到問題本身,思考一下
- 1. seatunnel到底有沒有問題
- 2.再次分析zipfile對象
- 3.分析seatunnel es connector 源碼
- 4 懷疑EsRestClient(seatunnel里的對象) 對象沒有被close
- 5 懷疑es 自帶的RestClient 有問題
- 6 繼續觀察RestClient
- 7 觀察有沒有CloseableHttpAsyncClient 和這相關的file bug
- 總結
現象描述
使用seatunnel 同步es數據到clickhouse,多次提交批任務后,flink jobmanager 報heap oom
jobmanager 是session 模式,jobmanager 會常駐,不是第一次使用seatunnel同步數據
開始分析
1.初步分析dump文件
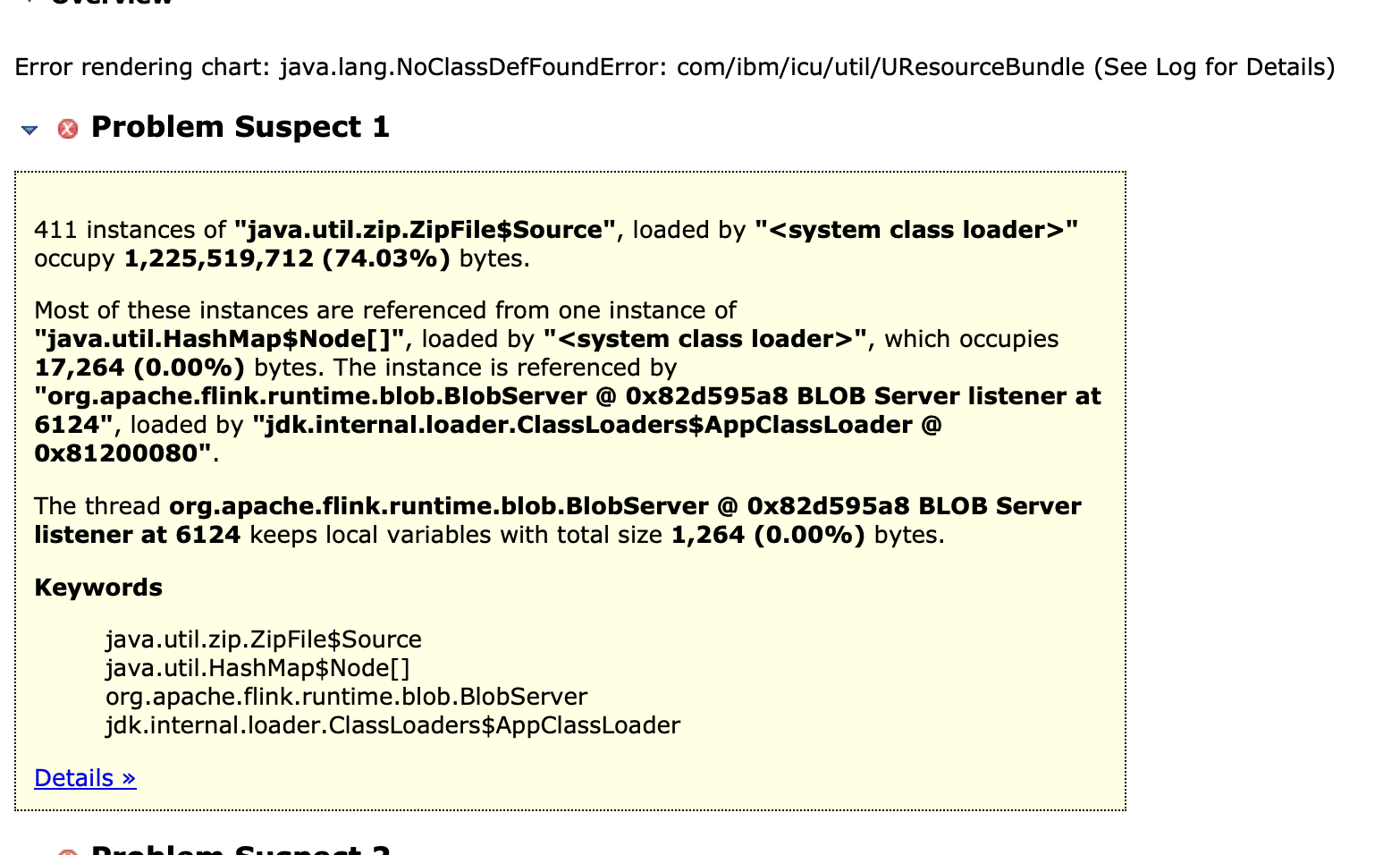
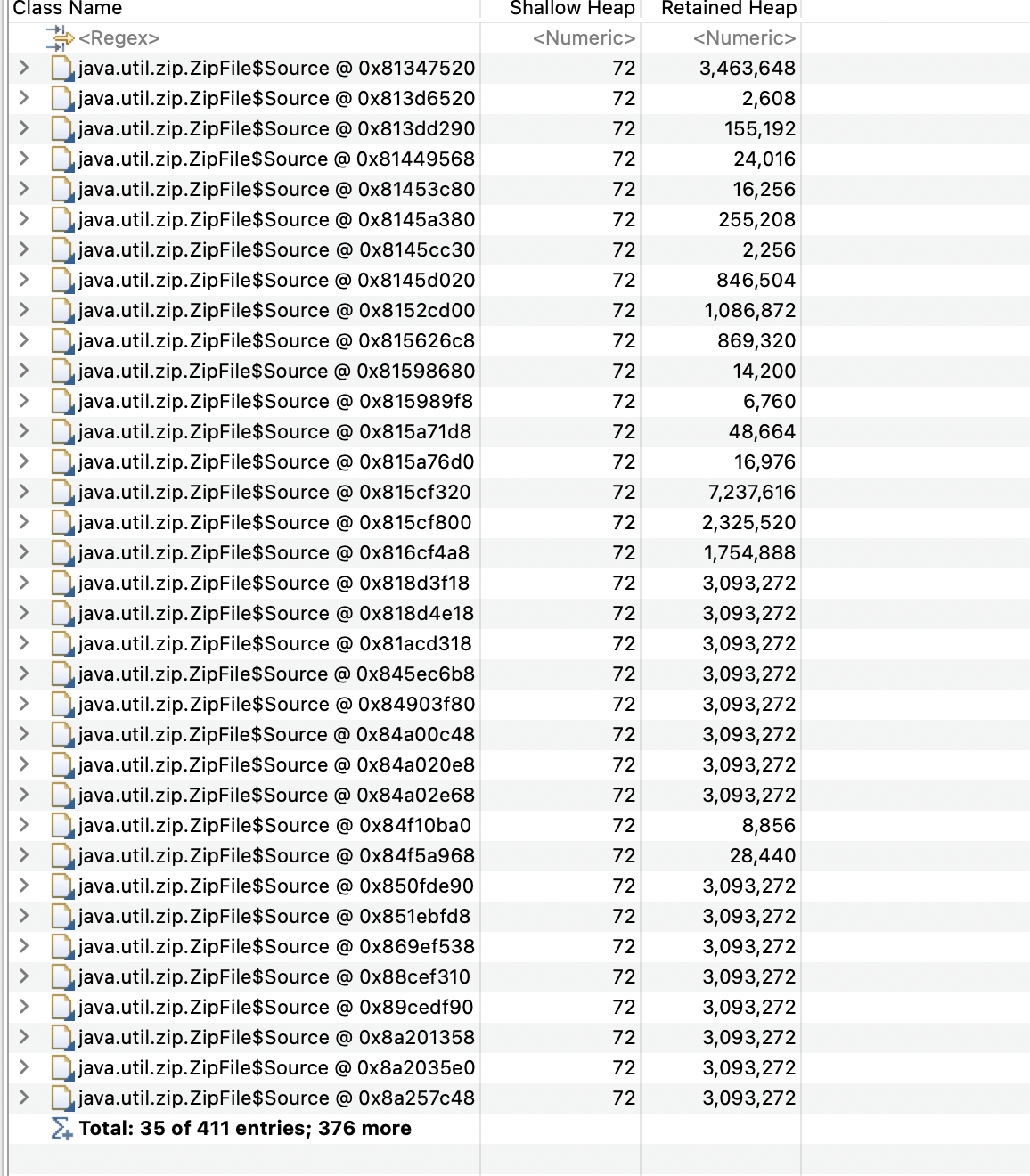
通過MAT工具把dump 文件打開,發現,提示和zipfile文件相關,zipfile 確實有很多對象,沒有被回收,最終導致heap 內存使用完,報oom
2.AI分析引用關系
把上面的信息交給deepseek后得到結論
問題現象: 383 個 ZipFile$Source 實例占用 1.1GB 內存(72.52%)。
這些實例被 HashMap$Node[] 引用,根源為 Flink 的 BlobServer。
根本原因: BlobServer 的 BLOB 緩存泄漏 Flink 的 BlobServer 負責管理用戶上傳的二進制對象(如 JAR
文件、配置文件)。如果 BLOB 未被及時清理(如臨時文件未刪除或緩存未釋放),會導致 ZipFile$Source 實例(關聯已打開的
ZIP 文件句柄)堆積,占用大量內存。資源未正確關閉 在讀取 ZIP 文件時未正確關閉 ZipFile 或 InputStream,導致文件句柄和內存無法釋放
分析方向2.1 flink BlobServer bug
由deepseek得出來的結論指向flink 的BlobServer
首先我找了BlobServer 所有的提交歷史記錄,沒有找到和這個有關的提交,一度我懷疑是這個變量里的內容沒有被定時任務清除導致,因為這個變量是在thread里的,通過arthas 也不好實時分析,于是我下載了源碼,加上日志,重新編譯,生成jar 包,重新運行觀察。發現這里運行是正常的。
我把同樣的dump內容交給qwen 和chatgpt 都指向這里,于是我只有向社區提交了jira ,看看有沒有人遇到過這個問題,搞完上面這些,3天時間已經過去,沒找到明確的方向
private final ConcurrentHashMap<Tuple2<JobID, TransientBlobKey>, Long> blobExpiryTimes =new ConcurrentHashMap<>();
分析方向2.2 和運行環境有關
于是我把相同的任務換到一個沒有這個問題的環境里,多次測試任務后,問題復現,看來和環境沒有關系
分析方向2.3 和任務有關
任務讀es還要寫clickhouse ,于是我把任務sink修改成console,多次測試后,問題復現,看來和任務本身沒有關系
回到問題本身,思考一下
為啥之前使用seatunnel沒有問題
為啥問題發生在jobmanager
為啥會有這么多zipfile 對象
1. seatunnel到底有沒有問題
鑒于之前使用seatunnel是沒有問題的,這里我先認為seatunnel 框架本身應該是沒有問題的
2.再次分析zipfile對象
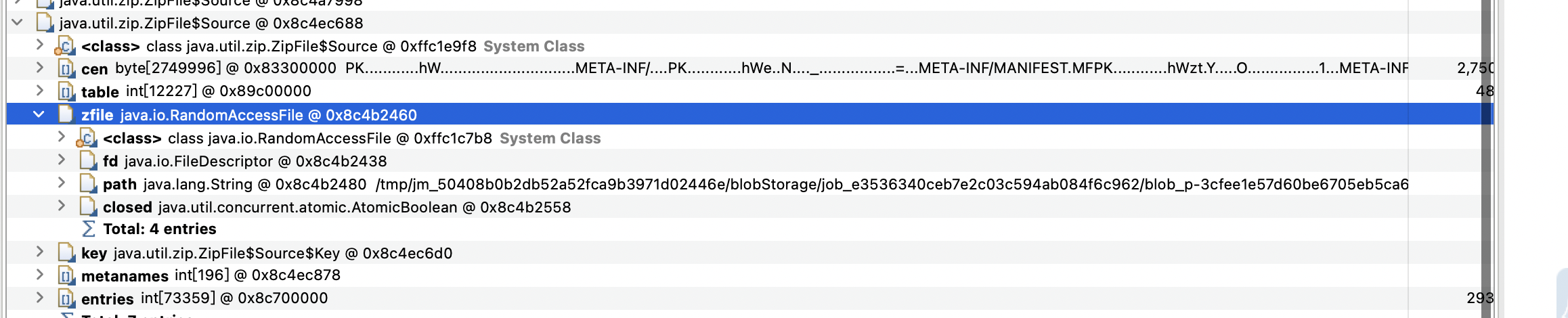
多次分析分析無果后,突然靈機一動,既然有這么多zipfile對象,那為啥不分析下這些對象具體是指的哪些對象,路徑里的/tmp/jm_xx/xx里的東西引起了我的注意,這些文件都是運行任務時的臨時文件交由blobserver管理的,之前也去這些目錄看了,也沒有這些文件,但是這里依然顯示還有線程持有這個文件的句柄。具體來看(deleted) 這個顯得不正常,于是我對比其它環境發現不會有這種文件,多次提任務后,此種類型的文件一直增加,經過對比我發現只要是讀es任務就會有此問題。

3.分析seatunnel es connector 源碼
經過之前的一系列信息
1.讀es會有問題
2.問題發生成在jobmanager
幸好有對flink source 知識的積累,讓我快速的把目標放在了ElasticsearchSourceSplitEnumerator類里
public class ElasticsearchSourceSplitEnumeratorimplements SourceSplitEnumerator<ElasticsearchSourceSplit, ElasticsearchSourceState> {
EsRestClient esRestClient}
4 懷疑EsRestClient(seatunnel里的對象) 對象沒有被close
EsRestClient(seatunnel里的對象,對es restClient 的一些封裝)
加上日志后,本地編譯seatunnel對象后,運行發現close 已經生效,好像又沒有思路了,代碼也不多
都是正常運行的。
5 懷疑es 自帶的RestClient 有問題
第一步EsRestClient 直接注釋掉,多次運行沒有問題,相當于沒有讀數據,就空運行
看來問題肯定在es自帶的RestClient 上
觀察這個對象在這里的作用,就是一個請求去得到索引信息
String endpoint =String.format("%s/_cat/indices/%s?h=index,docsCount&format=json", hosts.get(0), index);
于是我把代碼重寫,直接通過CloseableHttpClient 去請求這部分,現象消失,問題解決,
問題進一步定位到RestClient上
String endpoint =String.format("%s/_cat/indices/%s?h=index,docsCount&format=json", hosts.get(0), index);HttpClientUtil httpClientUtil = new HttpClientUtil();CloseableHttpClient httpClient = httpClientUtil.getHttpClient(connConfig);HttpGet httpGet = new HttpGet(endpoint);
6 繼續觀察RestClient
CloseableHttpAsyncClient 引起了我的注意,我是用的CloseableHttpClient 沒問題
public class RestClient implements Closeable {private static final Log logger = LogFactory.getLog(RestClient.class);private final CloseableHttpAsyncClient client;
}
于是我用CloseableHttpAsyncClient 單獨驗證,問題復現,看來問題在這里
7 觀察有沒有CloseableHttpAsyncClient 和這相關的file bug
根據關鍵詞一找,還真找到有這個問題,觀察下版本修復情況在5.0.1 版本,再看下es 里引用的版本還是4.x, 到這問題找到。
file leak
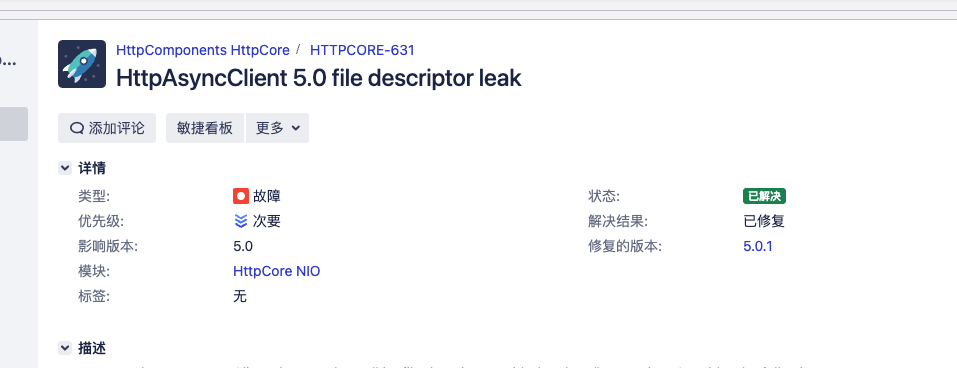
總結
1.從最后的結論來看,是最底層組件所引發的問題,最后一步步暴露成flink 的heap oom
2.從問題分析的思路來看,還是要抓住問題的核心點,就是變化的是哪部分,包括環境,版本信息,任務信息。
3.要對所用的組件要有深入的了解,這里對flink source 有比較深入的了解,不然我沒法直接定位到是ElasticsearchSourceSplitEnumerator 這個類的問題。
4.對MAT使用的分析還是要加深入了解。


)



消耗過多電量,導致用戶投訴。你會如何分析和優化后臺任務的執行?)






)





